Lo strato applicativo di Internet
Questa sezione esplora le caratteristiche salienti di una delle più diffuse applicazioni di rete, l'e-mail, il cui funzionamento è completamente dipendente da sui servizi offerti dagli strati protocollari inferiori (TCP/IP e DNS), acceduti rispettivamente tramite l'interfaccia socket e la resolver library. L'esposizione si articola nella descrizione di come i messaggi email siano formattati, e come vengano inoltrati; quindi, si illustrano le caratteristiche descrittive offerte dalle estensioni MIME. La sostanza di una email è il testo del messaggio che veicola, e quindi vengono discussi gli alfabeti di rappresentazione dei caratteri usati dai vari idiomi della terra. Dopo aver trattato del prelievo dell'email, e degli aspetti di sicurezza legati ad invio e ricezione, sono elencate le possibili alternative di comunicazione testuale.
La posta elettronica (electronic mail) è un servizio di comunicazione Internet basato sulla consegna asincrona di PDU contenenti testo, e/o altri file allegati. I soggetti mittente e destinatario di una email sono individuati da URI applicative dal formato
| mailto:alef@infocom.uniroma1.it |
che rappresentano la domiciliazione dell'utente alef presso un dominio internet. Sebbene la consegna delle email sia attuata mediante applicazioni client-server, non accade praticamente mai che il mittente comunichi direttamente con il destinatario. Invece, sono dislocati in rete dei nodi intermedi detti server di posta, che dialogano tra loro mediante un protocollo applicativo denominato SMTP, e tramite i quali viene inoltrato il messaggio. Il primo server della catena è concettualmente simile al default gateway dello strato IP, ed è quello a cui il mittente consegna (fiducioso) il messaggio da spedire. Questo primo server, una volta chiusa la conessione TCP su cui avviene la prima transazione SMTP, può a sua volta inviare (trasformandosi in client) il messaggio verso un altro server SMTP di sua scelta, oppure direttamente verso il server che gestisce la posta per il dominio presso il quale risiede l'utente destinatario. Il messaggio rimarrà li in giacenza, finchè l'intestatario della URI di destinazione non lo preleverà, ricorrendo ad un diverso protocollo.
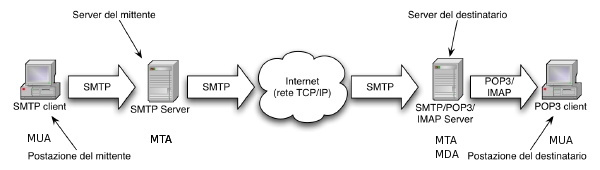
Il Simple Mail Transfer Protocol (SMTP) viene definito nel 1982 dalla RFC 821, scritta da John Postel, e da allora aggiornata da altri documenti (RFC 2821 e molti altri, fino a RFC 5321). Il protocollo SMTP è attuato da una applicazione-demone, in ascolto delle connessioni TCP sulla porta 25. La consegna a destinazione di un messaggio avviene secondo uno schema di immagazzinamento e rilancio, ad opera dei server di posta indicati anche come agenti, ovvero intermediari, detti Mail Transfer Agent (MTA). Questi dialogano tra loro in SMTP, e possono rivestire sia il ruolo di server, che quello di client, occupandosi di inoltrare il messaggio in direzione della destinazione. Il caso dell'intervento di due soli agenti è descritto dalla figura seguente, trovata presso Liverani:
Il mittente (umano) compone il messaggio da spedire mediante un Mail User Agent (MUA), che si comporta come un client SMTP, ed invia l'email ad un primo MTA di transito, o di uscita, o Outbound: l'SMTP server dell'ISP di partenza. Questo a sua volta, assumendo ora il ruolo di client, inoltra il messaggio verso l'SMTP server situato presso il destinatario, che (attuando la funzione di Mail Delivery Agent, o MDA) salva localmente il messaggio ricevuto, in attesa che il destinario (umano) lo prelevi (con il suo MUA) per mezzo del protocollo POP3 o IMAP, e lo legga.
Tipicamente il MUA usato dal mittente è lo stesso applicativo usato anche
per la ricezione,
e spesso deve essere configurato manualmente, inserendo l'indirizzo del
server SMTP a cui inoltrare l'email in uscita: nella pratica, questo
dovrà essere proprio il server SMTP disponibile presso l'ISP tramite il
quale ci si collega ad Internet. Infatti, per limitare il fenomeno
dello spamming, ogni ISP
configura il proprio server SMTP in modo che questo accetti la posta da
recapitare, solo se proveniente da computer collegati tramite la
propria stessa rete. Non solo: sempre per il controllo dello spam, i
server SMTP che operano dal lato di destinazione
del collegamento SMTP, verificano che l'IP del mittente non sia segnalato
in una DNSBL, oppure
che non appartenga a lotti di indirizzi che gli ISP assegnano
dinamicamente (ad es., via DHCP)
ai loro utenti.
D'altra parte, esistono casi in cui il Server SMTP usato da un mittente casalingo non è quello del proprio ISP: ad esempio, si tratta del caso di una email inviata tramite una interfaccia webmail come Gmail, oppure qualora il computer mittente usi un server SMTP residente sul mededimo computer (rischiando però di vedersi l'email bloccata dai meccanismi anti-spam), oppure anche nel caso in cui il server SMTP accetti mittenti remoti purché in grado di autenticarsi.
Allo scopo di individuare l'MTA di destinazione di una email, il server SMTP interroga il DNS (vedi figura) per conoscere i record MX relativi al dominio di destinazione; quindi, intrattiene una transazione SMTP con il server di destinazione, del tipo di quella riportata in quest'esempio.

Notiamo che come misura antispam, il ricevente può verificare (tramite DNS) che il nome a dominio dell'SMTP mittente si risolva effettivamente nell'indirizzo da cui risulta provenire la connessione, e in caso contrario, chiuderla. Poi, dopo alcune verifiche sull'effettiva esistenza dei destinatari, la transazione procede citando il mittente, i destinatari, e quindi il corpo del messaggio, eventualmente preceduto da altri header testuali, e terminato da una linea isolata, contenente un solo punto.
Il colloquio SMTP si svolge sia tra il MUA del mittente (che svolge un
ruolo di client SMTP) ed il suo server SMTP di uscita,
sia tra il server SMTP dell'ISP del mittente (trasformato in client), e
quello del destinatario.
| S: 220
smtp-out4.libero.it ESMTP Service (7.3.120) ready C: EHLO [192.168.120.40] S: 250-smtp-out4.libero.it S: 250-DSN S: 250-8BITMIME S: 250-PIPELINING S: 250-HELP S: 250 SIZE 30000000 C: MAIL FROM:<aalef@libero.it> SIZE=358 S: 250 MAIL FROM:<aalef@libero.it> OK C: RCPT TO:<alef@infocom.uniroma1.it> S: 250 RCPT TO:<alef@infocom.uniroma1.it> OK C: DATA S: 354 Start mail input; end with <CRLF>.<CRLF> C: Message-ID: <45EC3FFC.9010803@libero.it> C: Date: Mon, 05 Mar 2007 17:06:20 +0100 C: From: alef <aalef@libero.it> C: User-Agent: Mozilla Thunderbird 1.5.0.9 (X11/20070103) C: MIME-Version: 1.0 C: To: alef@infocom.uniroma1.it C: Subject: test di capture dell'SMTP C: Content-Type: text/plain; charset=ISO-8859-15 C: Content-Transfer-Encoding: 7bit C: C: salute a tutti C: C: Ale C: . S: 250 <45D9993D01232796> Mail accepted C: QUIT S: 221 smtp-out4.libero.it QUIT |
Notiamo le seguenti cose.
La RFC 5321 distingue tra envelope e content. L'envelope è inviato come una serie di unità di protocollo SMTP, e consiste dell'origine (MAIL FROM, a cui possono essere inviati messaggi di errore), di uno o più recipienti (RCPT TO), e di eventuali riferimenti ad estensioni. Il contenuto è quello inviato mediante l'unità di protocollo DATA, definito invece dalla RFC 5322, e consiste di due parti, le intestazioni (header) ed il corpo (body), la cui definizione è spesso integrata in accordo alle specifiche MIME (RFC 2045). Sia header che body sono trasmessi usando caratteri a 7 bit, inseriti in byte con il bit più significativo a zero, ed appartenenti all'alfabeto US-ASCII, tranne per l'eccezione prevista dall'estensione 8BITMIME per il body, e dalla sintassi Encoded Word per gli headers. Il messaggio è composto da linee terminate dalla sequenza CR/LF (0D 0A in esadecimale, 13 10 in decimale), e di lunghezza massima di 1000 bytes.

Ogni risposta del SMTP server è del tipo reason-code reason-phrase, ovvero un numero seguito da una frase. I codici numerici possono essere usati da un programma per capire la risposta, mentre la frase è a beneficio della leggibilità, per l'operatore umano. Il significato dei codici di risposta può essere classificato nell'ambito di 5 categorie, individuate dalla prima cifra del corrispondente codice numerico, in accordo allo schema
| reason code | categoria | significato |
| 1xx | Positive Preliminary Reply | seguirà una risposta ulteriore, prima che il comando richiesto sia completato |
| 2xx | Positive Completion Reply | il comando è stato eseguito, e si può iniziare una nuova richiesta |
| 3xx | Positive Intermediate Reply | ci si aspetta altro input da parte del client |
| 4xx | Transient Negative Completion Reply | manifestano un errore temporaneo, offrendo la possibilità di ripetere il comando che ha causato l'errore |
| 5xx | Permanent Negative Completion Reply | il comando non è stato accettato, l'azione non è stata intrapresa, ed il client è scoraggiato a ritentare |
L'Extended SMTP è definito dalle RFC 1869 e RFC 2821, ed il server ne annuncia il supporto, mediante la sua risposta iniziale. Se in questa, infatti, compare la stringa ESMTP anziché SMTP, allora vuol dire che il server supporta le estensioni. Il client a sua volta, può manifestare l'intenzione di tentare di sfruttare qualcuna delle estensioni disponibili, asserendo a sua volta la stringa EHLO, a cui il server risponde con l'elenco delle estensioni disponibili, ognuna definita in una diversa RFC, come riportato presso IANA. Altrimenti, nel caso in cui il client si presenti con un semplice HELO, si procede con un comportamento strettamente conforme alla RFC 821. Tra le estensioni presenti nell'esempio sopra riportato, notiamo
| C: MAIL FROM:<ned@ymir.claremont.edu> BODY=8BITMIME |
Nel caso in cui uno stesso messaggio sia destinato a più recipienti (RCPT), questi vengono tutti elencati dall'SMTP mittente, e poi viene inviata una unica copia del messaggio. Un server SMTP intermedio, se ha ricevuto un messaggio con destinatari molteplici, alcuni dei quali co-locati presso uno stesso dominio di destinazione, a sua volta invia al server SMTP di quel dominio una unica copia del messaggio, con tutti i RCPT (in quel dominio) raggruppati assieme.
Le opzioni dei protocolli analizzati finora (ARP, UDP, TCP, ICMP, DNS...), sono sempre state codificate in formato binario, e poste all'interno delle intestazioni delle PDU prodotte da quei protocolli: queste intestazioni sono esaminate direttamente dagli apparati di rete, oppure dal kernel o dalle librerie dei computer di destinazione. Nel caso attuale invece, l'SMTP è un protocollo di strato applicativo che opera direttamente tra entità pari, non più integrate dentro ad Internet, ma concettualmente disposte ai bordi della rete, ed in esecuzione nello User Space dei computer in comunicazione. Questa profonda differenza fa sì che l'SMTP adotti una diversa modalità di rappresentazione delle proprie intestazioni di protocollo, così come accadrà anche nel caso dei diversi protocolli applicativi che esamineremo in seguito, e che prevede che le intestazioni di strato applicativo siano rappresentate in forma umanamente leggibile. Tali intestazioni sono state inizialmente definite in RFC 822, e quindi in RFC 2822: sono disposte una per linea, e composte da un nome, seguito da due punti, e quindi un valore; inoltre, sono separate dal body del messaggio vero e proprio mediante una linea vuota. Le uniche due intestazioni obbligatorie, sono
Sembra strano che non sia richiesto obbligatoriamente almeno un destinatario? ...il fatto è che questo può essere espresso mediante tre diversi header (To:, Cc:, e Bcc:), nessuno dei quali è di per sé obbligatorio. Ma proseguiamo, esaminando alcuni altri header che possono essere presenti:
Le seguenti tre intestazioni hanno a che fare con l'alfabeto usato per scrivere il contenuto della email, e con il modo in cui tale testo viene rappresentato, come descritto di seguito
esistono poi delle ulteriori intestazioni, che possono essere aggiunte dai server SMTP di transito, e che troviamo dal lato di ricezione del messaggio dell'esempio soprastante, come
in cui
Infine, una famiglia molto importante di ulteriori intestazioni sono definite dalle specifiche MIME, che saranno descritte dopo aver approfondito gli aspetti legati alla ricezione ed alla codifica delle email.
Una volta che l'email è giunta presso il computer indicato dal RR MX relativo al dominio di destinazione, questa può essere letta dal destinatario (la cui autenticazione stavolta è obbligatoria) sia in locale, se ha accesso fisico al computer di destinazione, sia da remoto, utilizzando una applicazione come ad es. Outlook, Thunderbird, Evolution, Opera, Eudora, KMail, Pine, Mutt (vedi confronto). In questo secondo caso, si utilizza uno di due procolli, POP3 od IMAP, entrambi di tipo client-server, le cui differenze sostanziali sono illustrate nella figura che segue.

Il Post Office Protocol, definito nella RFC 1939, essenzialemente è nato per permettere di scaricare sul proprio computer le email ricevute, ed anche se è prevista una opzione del tipo lascia sul server, questa è molto inefficiente nel caso di utilizzo di tipo nomadico. In origine, permetteva solo l'invio della password in chiaro, mentre le successive estensioni, permettono l'uso dei metodi SASL, e di TLS.
L'Internet Message Access Protocol è definito dalla RFC 3501, ed offre diversi vantaggi rispetto all'uso del POP, come
 E' la contrazione di Web-based
email,
e consiste in un portale web da cui si può accedere alla propria
casella di posta elettronica, in modo da poterla leggere anche da una
postazione occasionale, tipicamente pubblica, permettendo inoltre di
spedire posta. In questo caso l'unico protocollo che sembrerebbe essere
in gioco, è il dialogo HTTP che si svolge tra il nostro browser, ed il
server web che ci mostra le pagine del portale. In effetti, le pagine
sono generate da un CGI,
ossia un programma in esecuzione presso il computer che ospita il server
web, e che a sua volta opera in modalità client
nei confronti dei procolli email, ossia SMTP per spedire, ed IMAP per
ricevere.
E' la contrazione di Web-based
email,
e consiste in un portale web da cui si può accedere alla propria
casella di posta elettronica, in modo da poterla leggere anche da una
postazione occasionale, tipicamente pubblica, permettendo inoltre di
spedire posta. In questo caso l'unico protocollo che sembrerebbe essere
in gioco, è il dialogo HTTP che si svolge tra il nostro browser, ed il
server web che ci mostra le pagine del portale. In effetti, le pagine
sono generate da un CGI,
ossia un programma in esecuzione presso il computer che ospita il server
web, e che a sua volta opera in modalità client
nei confronti dei procolli email, ossia SMTP per spedire, ed IMAP per
ricevere.
Il concetto che ad un byte corrisponda univocamente un carattere stampabile, e viceversa, non è per nulla corretto. Dai tempi in cui venne definito il primo insieme di caratteri per telecomunicazioni (il codice Morse del 1840), l'associazione tra codici numerici e simboli linguistici si è via via estesa, fino alla definizione di un insieme (Universal Caracter Set, o UCS, o Unicode) che possa rappresentare in modo congiunto i simboli previsti da tutte le lingue del mondo, in modo da poter essere utilizzato per i contenuti da scambiare a livello planetario, come avviene in Internet. Ma andiamo con ordine.
L'insieme di caratteri più universalmente noto è il codice ASCII, standardizzato come X3.4-1986 da ANSI, come ISO 646 da ISO, e come US-ASCII da IANA, che definisce una tabella di corrispondenza tra i codici numerici 0-127 (e dunque rappresentabili con 7 bit) ed i caratteri stampabili. Questi codici rappresentano, per le prime 32 posizioni, i cosiddetti caratteri di controllo, e sono una eredità dell'epoca delle telescriventi. I restanti codici, sono invece associati ai cosidetti caratteri stampabili. Tra questi però non compaiono (ad esempio) le lettere accentate, cosicchè ci fu un periodo in cui a tale scopo vennero definite diverse mappature (dette codepage) dei restanti 128 caratteri ancora disponibili, settando ad 1 il bit più significativo di un byte.
Una Codepage
è una tabella che stabilisce una corrispondenza tra i codici a 8 bit
aventi il bit più significativo posto ad uno (che non rientrano nella
tabella ASCII), e i simboli
di un certo alfabeto, compresi anche i caratteri semi-grafici
(mediante i quali si poteva produrre una qualche forma di disegno sullo
schermo dei terminali
di allora).
Una codepage di largo uso in Europa, è stata la numero 850, indicata come Multilingual (Latin-1), poi sostituita con windows-1252, e quindi con la sua evoluzione ISO 8859-1, detto anche alfabeto Latin-1, definito da ISO e IEC, e mostrato nella tabella sottostante, in cui notiamo che i codici 00–1F, 7F, e 80–9F non sono assegnati a caratteri.
| ISO/IEC 8859-1 | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x0 | x1 | x2 | x3 | x4 | x5 | x6 | x7 | x8 | x9 | xA | xB | xC | xD | xE | xF | |
| 0x | unused | |||||||||||||||
| 1x | ||||||||||||||||
| 2x | SP | ! | " | # | $ | % | & | ' | ( | ) | * | + | , | - | . | / |
| 3x | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 4x | @ | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O |
| 5x | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ^ | _ |
| 6x | ` | a | b | c | d | e | f | g | h | i | j | k | l | m | n | o |
| 7x | p | q | r | s | t | u | v | w | x | y | z | { | | | } | ~ | |
| 8x | unused | |||||||||||||||
| 9x | ||||||||||||||||
| Ax | NBSP | ¡ | ¢ | £ | ¤ | ¥ | ¦ | § | ¨ | © | ª | « | ¬ | SHY | ® | ¯ |
| Bx | ° | ± | ² | ³ | ´ | µ | ¶ | · | ¸ | ¹ | º | » | ¼ | ½ | ¾ | ¿ |
| Cx | À | Á | Â | Ã | Ä | Å | Æ | Ç | È | É | Ê | Ë | Ì | Í | Î | Ï |
| Dx | Ð | Ñ | Ò | Ó | Ô | Õ | Ö | × | Ø | Ù | Ú | Û | Ü | Ý | Þ | ß |
| Ex | à | á | â | ã | ä | å | æ | ç | è | é | ê | ë | ì | í | î | ï |
| Fx | ð | ñ | ò | ó | ô | õ | ö | ÷ | ø | ù | ú | û | ü | ý | þ | ÿ |
Questa è divenuta la codifica di default anche per le pagine distribuite
dai server Web, e supporta: Africano,
Basco, Catalano, Danese, Olandese, Inglese, Faeroese, Finlandese,
Francese, Galizio, Tedesco, Islandese, Irlandese, Italiano, Norvegese,
Portoguese, Scozzese, Spagnolo, e Svedese. Successivamente, l'ISO
8859-1 si è ancora evoluto in ISO
8859-15, o Latin-9, che sostituisce
ad alcuni simboli molto poco usati (¤, ¦, ¨, ´, ¼, ½, e ¾) alcuni
rari caratteri francesi e finlandesi, e il simbolo di valuta dell'euro
€.
In tutti gli alfabeti ISO 8859-x, la codifica dei primi 127 caratteri (non di controllo) è la stessa dell'US-ASCII, quindi i files scritti con il secondo alfabeto, sono automaticamente validi anche nel primo.
Nel
2004 il gruppo di lavoro di ISO/IEC responsabile della manutenzione
delle codifiche di carattere ad 8 bit si è sciolto, e tutti gli sforzi
si sono indirizzati verso lo Universal
Character Set del consorzio
Unicode, noto anche come ISO/IEC 10646,
che contiene centinaia di migliaia di caratteri di tutte le
lingue del mondo, ognuno identificato in modo non ambiguo da un nome, e
da un numero chiamato il suo Code Point.
Ogni carattere Unicode viene rappresentato con la sequenza "U+", seguita da un numero esadecimale che indica il codepoint del carattere. I primi 256 caratteri, indicati come il blocco latin-script, coincidono con quelli dell'alfabeto ISO 8859-1, e ne condividono l'ordinamento, e quindi la rappresentazione numerica.
Sono definiti 17 piani di caratteri, ognuno comprendente 65,536 (= 216) possibili code points. Pertanto, un codepoint che compare in uno dei 17 piani può essere rappresentato da (16 + log217=) 21 bits. Ma come vedremo subito, sono definite della regole di trasformazione allo scopo di usare un numero variabile di bits, in modo da rendere la dimensione dei testi americani ed europei comparabile a quella "classica" che usava 1 byte per carattere.
I CodePoints da U+0000 a U+FFFF costituiscono il piano 0, noto anche come Basic Multilingual Plane (BMP), contenente la maggior parte delle assegnazioni eseguite finora, come risulta dalla mappa riportata qui sotto, in cui sono evidenziati gli utilizzi per tutti i singoli blocchi da 256 codepoints.
|
 |
Consiste in un insieme di regole che consentono di rappresentare i caratteri associati alle sequenze numeriche identificate dai codepoint mediante un numero variabile di byte, allo scopo di minimizzare l'occupazione di memoria necessaria, e massimizzare la compatibilità con i testi preesistenti. Lo standard de facto è indicato come UTF-8, che usa da uno a quattro bytes per rappresentare un carattere Unicode. Altri formati di trasformazione sono l'UTF-16, anch'esso a lunghezza variabile, a multipli di 16 bit, e l'UTF-32, con lunghezza fissa pari a 32 bit. Dato che l'SMTP, come più volte ricordato, si basa su caratteri a 7 bit (a meno che il server non supporti l'estensione 8BITMIME), le trasformazioni citate, se utilizzate come valore del parametro charset della intestazione MIME Content-Type, devono subire un ulteriore processo di trasformazione, indicando un Content-Transfer-Encoding di tipo quoted-printable oppure base64, come ad esempio
| Content-Type: plain/text; charset=UTF-8 Content-Tranfer-Encoding: quoted-printable |
Onde evitare trasformazioni, è stato definito (ma sembra poco usato) un ulteriore formato di trasformazione, l'UTF-7, che rappresenta il testo Unicode come una stringa di caratteri ASCII.
Questo formato di trasformazione per l'Unicode, definito nella RFC
3629,
è del tutto consistente con l'alfabeto US-ASCII, in quanto i primi 128
codepoint da U+0000 a U+007F sono rappresentati da un unico byte, in
cui i sette bit diversi da zero rappresentano esattamente gli stessi
simboli dell'alfabeto ASCII. Pertanto, tutti i files di testo ASCII
sono perfettamente validi anche se interpretati come UTF-8. Per le
lettere accentate ed i caratteri Latin-1, associati all'intervallo da
U+0080 a U+07FF, corrispondente ai primi 2048 codepoint, occorrono due
bytes, mentre ne occorrono tre per il resto del Basic
Multilingual Plane
(da U+0800 to U+FFFF); per caratteri appartenenti a qualunque altro
piano di Unicode, occorrono 4 bytes. Passiamo quindi a descrivere
questo schema di codifica.
Per i primi 127 codepoints UTF-8 utilizza un solo byte, con il bit più significativo posto a zero. Altrimenti, se occorre utilizzare N bytes per uno stesso codepoint, il primo byte ha il bit più significativo posto ad uno, seguito da N-1 bits posti anche essi ad uno, seguiti da uno zero (alla N+1-esima posizione), seguiti dai bit più significativi del codepoint. I bytes successivi, hanno una coppia di bit pari a 10 nella posizione più significativa, seguiti da 6 bit presi in sequenza dalla rappresentazione binaria del codepoint. Lo schema è riassunto nella tabella seguente, in cui la lettera x indica i bit disponibili per codificare il codepoint:
| Char. number range | n. of | UTF-8 octet sequence (hexadecimal) | bits | (binary) ----------------------+--------------------------------------------- 0000 0000 - 0000 007F | 7 | 0xxxxxxx 0000 0080 - 0000 07FF | 11 | 110xxxxx 10xxxxxx 0000 0800 - 0000 FFFF | 16 | 1110xxxx 10xxxxxx 10xxxxxx 0001 0000 - 0010 FFFF | 21 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
La RFC 3629 riporta alcuni esempi di codifica. Proviamo qui ora ad individuare la codifica per la parola cioè. Le prime tre lettere, che appartengono all'alfabeto ascii, producono un byte ciascuna, pari a 0x63 0x69 0x6F. Alla lettera è compete un codepoint pari a U+00E8, lo stesso che risulta per ISO 8859-1, e che in binario si rappresenta come 11101000. In accordo alla seconda riga della tabella soprastante, occorrono due bytes, ed i bit che compaiono nel codepoint vengono riscritti da destra a sinistra al posto delle x, ponendo a zero le tre x più significative, ottenendo il risultato 110(00011) 10(101000), ossia 0xC3 0xA8. Pertanto, esprimendo in esadecimale il risultato finale della codifica UTF-8 di cioè, si ottiene 0x63 0x69 0x6F 0xC3 0xA8.
Il Multipurpose Internet Mail Extensions (MIME) estende il formato delle email, permettendo
Queste specifiche sono usate anche in ambiti diversi dal traffico email, come per i protocolli HTTP e SIP, e sono descritte dai documenti RFC 2045, RFC 2046, RFC 2047, RFC 4288, RFC 4289, RFC 2077, RFC 2231, RFC 3676.
L'intestazione
| MIME-Version: 1.0 |
indica allo User Agent di ricezione che il messaggio aderisce alle specifiche MIME, e viene semplicemente ignorato da uno UA non aggiornato, e non in grado di interpretarlo correttamente.
La presenza di
| Content-Type: text/plain; charset=ISO-8859-15 |
indica il tipo di contenuto presente, nel formato tipo/sottotipo; parametro=valore, e fornisce allo UA un suggerimento su come visualizzare o riprodurre correttamente il contenuto ricevuto. Il parametro permette di specificare una particolare caratteristica del tipo/sottotipo indicato, ed in questo esempio, stabilisce che il body dell'email contiene caratteri appartenenti all'insieme ISO-8859-15. Nel caso invece in cui si tratti di un contenuto non direttamente visualizzabile da parte del lettore di email, ossia non testuale, occorre eseguire un applicativo idoneo (ad es., un player multimediale per contenuto audio o video), associato al MIME-Type che lo descrive. La lista dei tipi e sottotipi possibili è registrata presso IANA, comprendendo tra gli altri i seguenti casi particolari:
A meno che non sia disponible l'estensione ESMTP di tipo 8BITMIME, le email devono contenere solamente caratteri US-ASCII, con il bit più significativo di ogni byte posto a zero. Questo contrasta con l'uso di set di caratteri esteso, come gli alfabeti ISO-8859-x, e con l'invio di allegati contenenti dati binari qualsiasi. Per questo, lo standard MIME prevede l'uso della intestazione Content-Transfer-Encoding, come ad esempio
| Content-Transfer-Encoding: 7bit |
che stabilisce un metodo di codifica del body tale da convertire il suo vero contenuto, qualsiasi, in una diversa rappresentazione, tale che nel flusso di byte risultante il bit più significativo sia posto a zero. Il lato trasmittente, una volta noto il formato accettabile dal server SMTP, converte al volo l'email, ed aggiunge questo header, per indicare la trasformazione effettuata. Il lato ricevente, noto il Transfer-Encoding utilizzato, provvede quindi ad invertirne la rappresentazione, in modo da ristabilire il flusso binario originario. La RFC 2045 definisce i valori che possono essere assunti dalla intestazione Content-Transfer-Encoding:, che sono:
| 1 2 3 00000001 00000010 00000011 / \ / \ / \ 000000 01 0000 0010 00 000011 |----| |------| |-----| |----| 000000 010000 001000 000011 0 16 8 3 A Q I D |
In particolare, la trasformazione dell'ultima riga avviene interpretando il valore 0-63 dei gruppi di 6 bit riportati nella penultima riga, come un indice nella tabella di conversione riportata qui sotto, in cui compare un sottoinsieme di 64 caratteri stampabili dell'alfabeto US-ASCII.
| NUM
ASCII NUM ASCII
NUM ASCII NUM ASCII 0 A 16 Q 32 g 48 w 1 B 17 R 33 h 49 x 2 C 18 S 34 i 50 y 3 D 19 T 35 j 51 z 4 E 20 U 36 k 52 0 5 F 21 V 37 l 53 1 6 G 22 W 38 m 54 2 7 H 23 X 39 n 55 3 8 I 24 Y 40 o 56 4 9 J 25 Z 41 p 57 5 10 K 26 a 42 q 58 6 11 L 27 b 43 r 59 7 12 M 28 c 44 s 60 8 13 N 29 d 45 t 61 9 14 O 30 e 46 u 62 + 15 P 31 f 47 v 63 / |
Nel caso in cui il testo di partenza non abbia un numero complessivo di byte multiplo di 3, si aggiungono a destra tanti zeri, quanti ne servono per completare l'ultimo gruppo di 6 bit in entrata. Quindi, se il numero di simboli BASE64 ottenuti non è un multiplo di quattro, si aggiungono alla codifica fino a tre simboli di uguale (=), in numero pari al numero di simboli mancanti, in modo da segnalarlo al ricevitore.
Ad esempio, mostriamo la codifica della parola cioé, quando inizialmente rappresentata in ISO-8859-1. In tal caso, la parola si esprime mediante la sequenza esadecimale 0x63 0x69 0x6F 0xE8 (eseguire man ascii e man iso_8859_1 per verificarlo), che in binario diviene 01100011 01101001 01101111 11101000, e che si suddivide in gruppi di 6 bit come 011000 110110 100101 101111 111010 000000, in cui gli ultimi 4 bit sono stati aggiunti, e posti a zero. Riscrivendo l'ultima sequenza in decimale, otteniamo 24 54 37 47 58 00, che in accordo alla tabella precedente, fornisce una rappresentazione BASE64 pari a Y2lv6A==, dove i due simboli = finali sostituiscono i due gruppi di 6 bit mancanti nella penultima sequenza.
Esistono alcuni siti che calcolano la trasformazione on-line, come quelli qui indicati; inoltre su Linux è disponibile il comando base64.
Le intestazioni MIME Content-Type e Content-Transfer-Encoding stabiliscono alfabeto e codifica del body della email, ma per usare un alfabeto diverso da US-ASCII nel valore di una intestazione, come ad esempio nel Subject, si ricorre ad un diverso espediente, noto come Encoded Word (RFC 2047), che definisce una sintassi tale da indicare, in un sol colpo
La sintassi è
=?charset?encoding?encoded
text?= |
Q", ossia quoted-printable, oppure "B",
ossia base64Per esempio,
| Subject: =?utf-8?Q?=C2=A1Hola, se=C3=B1or!?= |
è interpretabile come Subject: ¡Hola, señor!. Notiamo, in questo caso, che avendo adottato come charset utf-8, la codifica per i caratteri ¡ (punto esclamativo rovesciato) e ñ utilizza due bytes, che con il transfer-encoding di tipo quoted-printable, divengono 6 caratteri US-ASCII.
Un messaggio MIME multiparte è il formato tipico in cui sono realizzate le email che contengono allegati, o contenuti di tipo diverso dal text/plain. In questo caso, il body del messaggio è suddiviso mediante una stringa speciale detta confine (boundary), definita nella intestazione Content-type:, e che non deve comparire in nessuna delle parti: per questo motivo, il confine tipicamente assume l'aspetto di una sequenza di simboli casuali. Il confine è inserito oltre che tra le diverse parti, allo scopo di demarcare la loro separazione, anche all'inizio ed alla fine del corpo del messaggio, come segue:
| Content-type: multipart/mixed; boundary="frontier" MIME-version: 1.0 This is a multi-part message in MIME format. --frontier Content-type: text/plain This is the body of the message. --frontier Content-type: application/octet-stream Content-transfer-encoding: base64 PGh0bWw+CiAgPGhlYWQ+CiAgPC9oZWFkPgogIDxib2R5PgogICAgPHA+VGhpcyBpcyB0aGUg Ym9keSBvZiB0aGUgbWVzc2FnZS48L3A+CiAgPC9ib2R5Pgo8L2h0bWw+Cg== --frontier-- |
Ogni parte inizia con una sua propria intestazione Content-type, seguita da una eventuale Content-transfer-encoding, seguita dal corpo della parte. I client dei destinatari che aderiscono alla specifica MIME ignorano (non visualizzano) quanto è presente prima del primo confine, che contiene un messaggio rivolto appunto ai possessori di client che non aderiscono a MIME. Questi ultimi infatti visualizzano il messaggio per intero, così come l'abbiamo mostrato sopra, ed in cui compare in testa l'avvertimento rivolto loro.
Il Content-type multipart può essere di diversi sottotipi, che specificano la natura delle parti, e le loro relazioni reciproche. I sottotipi più comuni sono:
Illustriamo l'uso di questa intestazione nell'ambito dei commenti al seguente capture, in cui le risposte delserver SMTP sono visualizzate in corsivo, e che corrisponde all'invio di una email contenente in allegato una immagine jpeg, codificata con il metodo base64.
| 220 smtp-out2.libero.it ESMTP
Service (7.3.120) ready EHLO [192.168.120.40] 250-smtp-out2.libero.it 250-DSN 250-8BITMIME 250-PIPELINING 250-HELP 250 SIZE 30000000 MAIL FROM:<aalef@libero.it> SIZE=11599 250 MAIL FROM:<aalef@libero.it> OK RCPT TO:<alef@infocom.uniroma1.it> 250 RCPT TO:<alef@infocom.uniroma1.it> OK DATA 354 Start mail input; end with <CRLF>.<CRLF> Message-ID: <45EC6FC4.808@libero.it> Date: Mon, 05 Mar 2007 20:30:12 +0100 From: alef <aalef@libero.it> User-Agent: Mozilla Thunderbird 1.5.0.9 (X11/20070103) MIME-Version: 1.0 To: alef@infocom.uniroma1.it Subject: prova invio con allegato Content-Type: multipart/mixed; boundary="------------060708020103050401060503" This is a multi-part message in MIME format. --------------060708020103050401060503 Content-Type: text/plain; charset=ISO-8859-15 Content-Transfer-Encoding: 7bit vediamo come parte l'allegato --------------060708020103050401060503 Content-Type: image/jpeg; name="logoalef.jpg" Content-Transfer-Encoding: base64 Content-Disposition: inline; filename="logoalef.jpg" /9j/4AAQSkZJRgABAQEASABIAAD/4QAWRXhpZgAATU0AKgAAAAgAAAAAAAD//gAXQ3JlYXRl ZCB3aXRoIFRoZSBHSU1Q/9sAQwADAgIDAgIDAwMDBAMDBAUIBQUEBAUKBwcGCAwKDAwLCgsL DQ4SEA0OEQ4LCxAWEBETFBUVFQwPFxgWFBgSFBUU/9sAQwEDBAQFBAUJBQUJFA0LDRQUFBQU FBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQUFBQU/8AAEQgAZAGk AwEhAAIRAQMRAf/EABwAAQADAQEBAQEAAAAAAAAAAAABCAkHBgUEA//EAFUQAAAEBAMEBwIH CQsMAwAAAAABAgMEBhRhBQcRCBITFwkhMVFWldIVcRkiQYGUtNQWIzJVZGWRssQYM0JEYpKh oqOz0yVDRlJTV2Nyc4KTpabB5P/EABwBAQACAgMBAAAAAAAAAAAAAAABBQQGAgMHCP/EADsR AAEDAwECCwYFBAMBAAAAAAABAhEDBBIFIZEUFUFRUlRhcZKx0QYTMTIzwSIjYoHwcqGy8RYk . ..... molte linee omesse . DaSHCT3AMlHCSHCTqIkSo4Se4TwkhIlRwk9wjhJCRKjhJDhJ7gkSo4SQ4adOwSMlHCT3Bwkh IlRwkhw06dgCVHCT3Bwk9XUEiVBNJ7gNtPcAlRw09wnhJ7hEiVINtJBwk9wkSo4ST+QDbSAl Rwkhwk9wgSo4SQ4aQJlQbaSLsAmk9wSRKjhJ17A4aevqEkyo4adOwOEnXsAjJRwk9wcJIiRk o4SQ4adOwJEqfsgiJLR6d4DivxMV3zH/2Q== --------------060708020103050401060503-- . 250 <45D997EE01267F19> Mail accepted QUIT 221 smtp-out2.libero.it QUIT |
Notiamo che quando, come in questo caso, l'intestazione Content-Disposition (RFC 2183) assume il valore inline, il client di posta ricevente è istruito a visualizzare l'immagine subito di seguito alla prima parte testuale. Viceversa, una intestazione Content-Disposition: Attachment avrebbe determinato l'attesa di una esplicita decisione umana su cosa fare. Di seguito all'intestazione Content-Disposition possono essere presenti diversi parametri, come ad esempio il nome del file, da usare come suggerimento qualora si voglia salvare la parte su disco, ma anche eventualmente, data di creazione e di modifica, e dimensione.
Questo concetto si applica a diverse fasi dell'invio delle email, e cioè
Ognuno
dei passi elencati può essere svolto in accordo ad uno o più
protocolli, che si basano su concetti e algoritmi che sono discussi in
una sezione apposita.
Nel seguito, illustriamo direttamente le soluzioni adottate, rimandando
alla sezione sulla sicurezza per gli approfondimenti. Infine,
dedichiamo la prossima sezione al tema
dello spam.
Osserviamo subito che verificare l'autenticità di qualcuno/qualcosa, è diverso dall'accordare allo stesso soggetto il potere di fare qualcosa, ovverosia, autorizzarlo. Ma in ciò che segue, i due concetti si fondono, in quanto lo scopo dell'autenticazione è ristretto alle necessità della applicazione che la richiede, e quindi l'autenticazione implica il permesso ad operare. Ma in generale, si può dire soltanto il viceversa, e cioè che un processo di autorizzazione, sottintende un prerequisito di autenticazione. Wikipedia dedica una categoria a parte sull'argomento della autenticazione delle email.
Il processo di autenticazione viene realizzato con l'ausilio dei meccanismi offerti dalla libreria SASL, sia nel momento dell'invio della email (punto 1), abilitatandolo presso il server SMTP di Outbound, sia nel momento della ricezione della stessa (punto 4), abilitandolo presso il server POP3 o IMAP dell'ISP del destinatario. Nel primo caso (opzionale), ci si avvale della estensione SMTP-AUTH, e può essere aggiunto un header che dichiara l'avvenuta autenticazione. Nel secondo, si ricade nella definizione standard del protocollo di prelievo email. Una variante si ha quando la lettura della email avviene mediante una interfaccia di tipo Webmail: in tal caso, l'utente viene autenticato dalla applicazione web, che poi opera in veste di agente, usando le credenziali dell'utente per autenticarsi al suo posto, ed accedere alle email giacenti presso un server IMAP, impersonando l'utente.
La RFC 2554 definisce una estensione di SMTP, indicata come SMTP-AUTH, che permette di ottemperare ai primi tre punti espressi nell'elenco di cui sopra. Infatti, consente di condizionare l'accettazione di un nuovo messaggio al buon esito di un processo preliminare di autenticazione, in cui il server di partenza si accerta della reale identità del soggetto che invia il messaggio. Ciò permette agli utenti abilitati di usare questo server SMTP anche quando si collegano (in roaming) da una postazione esterna alla rete del proprio provider; al tempo stesso, però, si introduce un rischio di sicurezza, perchè un attaccante, indovinando (ad esempio, mediante un metodo di forza bruta) la password di un utente autorizzato, potrebbe poi usare il server SMTP per inoltrare SPAM. Inoltre, sebbene mediante SMTP-AUTH il server SMTP di partenza può informare quello di arrivo che il mittente è stato correttamente autenticato, in generale non esiste un rapporto di fiducia tra i due server, e così il destinatario non sarà mai rassicurato con certezza in tal senso. Per questi motivi, l'estensione SMTP-AUTH non è molto usata. Ad ogni modo, esaminiamo come appare una sessione che fa uso di questa estensione:
| S: 220 smtp.example.com ESMTP server ready C: EHLO jgm.example.com S: 250-smtp.example.com S: 250 AUTH CRAM-MD5 DIGEST-MD5 C: AUTH FOOBAR S: 504 Unrecognized authentication type. C: AUTH CRAM-MD5 S: 334 PENCeUxFREJoU0NnbmhNWitOMjNGNndAZWx3b29kLmlubm9zb2Z0LmNvbT4= C: ZnJlZCA5ZTk1YWVlMDljNDBhZjJiODRhMGMyYjNiYmFlNzg2ZQ== S: 235 Authentication successful. |
Dopo che il server ESMTP ha annunciato la disponibilità della estensione AUTH, assieme ad una lista dei meccanismi SASL supportati (nell'esempio, CRAM-MD5 e DIGEST-MD5), il client manifesta l'intenzione di usarne uno. Il CRAM-MD5 è tra quelli supportati, ed il server risponde inviando lo challenge, che viene però (reversibilmente) codificato come base64. Il client da parte sua, dopo aver calcolato l'HMAC-MD5 concatenando lo challenge alla password dell'utente, ed avere prefisso il risultato con l'identificativo dell'utente stesso, codifica la stringa risultante in base64, e reinvia il tutto al server. La trasformazione via base64 viene prescritta dalla RFC 4422 (SASL), in modo che se challenge e/o password contengono caratteri non ASCII, per questi venga usata la codifica Unicode, con trasformazione UTF-8, e quindi poi il tutto sia rappresentato con caratteri a 7 bit, appunto mediante codifica base64.
Gli ultimi tre punti dell'elenco posso essere soddisfatti appieno solo se le trasformazioni crittografiche avvengono da estremo ad estremo del collegamento, adottando uno degli standard noti come PGP ed S/MIME. Tuttavia, esiste la possibilità di effettuare ogni singolo trasferimento dal mittente al primo server SMTP, e poi tra server SMTP intermedi fino a quello di destinazione, su collegamenti resi sicuri mediante TLS, come permesso in base alla estensione STARTTLS dell'SMTP.
Il Transport Layer Security (TLS) è definito nella RFC 4346, ed offre alle applicazioni una modalità di comunicazione sicura. L'estensione STARTTLS di SMTP, descritta nella RFC 3207, permette ad un client SMTP di negoziare con il server i servizi di crittografia ottenibili via TLS, tali da impedire la lettura (da parte di un intercettatore) dei contenuti in transito, ottemperando quindi ai requisiti di confidenzialità. Questo però avviene solo di tratta in tratta, sempre che tutte le tratte lo permettano, e scelgano di usarlo: questa variabilità ne vanifica in parte gli scopi, per quanto rimane comunque un valido meccanismo di protezione nella comunicazione tra il client, ed il server SMTP del proprio provider. Inoltre, dato che l'attivazione di TLS precede l'autenticazione basata su SASL (vedi esercitazioni), l'uso di TLS si dimostra una soluzione valida, per utilizzare il meccanismo plaintext, dato che la password non viene inviata in chiaro, ma crittografata dal TLS.
Il fenomeno dello spamming della posta elettronica è noto a tutti, e consiste nell'invio di una grande quantità di posta elettronica a destinatari sparsi in tutto il mondo, e che non la vogliono ricevere. Meno nota, è l'origine di questo termine: SPAM è una marca di carne in scatola, la cui invadenza è stata oggetto di uno schetch televisivo dei Monty Pyhton (video).
Il fenomeno dello spamming si basa sull'uso di OpenRelay e OpenProxy, ovvero host che rilanciano i messaggi email ricevuti mediante il protocollo SMTP, senza discriminare la loro provenienza. Mentre la configurazione di un server SMTP ufficiale come OpenRelay può, ai giorni nostri, avvenire solo a causa di una grave disattenzione del suo amministratore, spesso gli OpenProxy sono ospitati da host di utenti connessi ad Internet, inconsapevolmente infetti da un virus, che appunto fa da intermediario tra lo spammer, e il server SMTP che l'utente stesso utilizza di diritto.
Il contrasto di questo fenomeno può avvenire dal lato ricevente, mediante filtri e regole usati per analizzare le email arrivate, ed eventualmente decidere per il loro spostamento nella cartella dello spam; tali filtri possono essere di tipo euristico, nel caso vadano a cercare particolari parole contenute nella email (ad es., Viagra), o di tipo statistico o Bayesiano, nel caso in cui il risultato del filtraggio sia una valore di probabilità che l'email sia spam. D'altra parte, il filtraggio può avvenire più vicino al mittente, o presso il server SMTP di transito o di destinazione, in modo da evitare completamente che l'email di spam raggiunga il destinatario.
Alcune applicazioni antispam in esecuzione sull'MTA di ricezione, come ad esempio SpamAssassin, applicano più strategie in parallelo, come ad esempio i filtri descritti sopra, assieme alle tecniche spiegate appresso, in modo da avere più basi su cui prendere una decisione. L'esito delle verifiche produce l'aggiunta di un ulteriori header email, come ad esempio Authentication-Results: definito nella RFC 7001, in base ai quali lo User Agent ricevente può decidere come classificare ogni messaggio.
Questa tecnica di difesa dallo spam molto efficace fa uso del DNS per distribuire in rete una lista nera (detta Blackhole List o DNSBL) di indirizzi IP da cui è stato ripetutamente segnalato prevenire spam, come ad esempio realizzato da SpamHaus. Le segnalazioni che pervengono a carico di quei server SMTP che sono origine di spam sono spesso relative ad un OpenProxy, ma possono anche riguardare server SMTP legittimamente usati da utenti malevoli dell'ISP che lo gestisce. Tale tecnica si basa sul fatto che quando un server SMTP riceve una connessione TCP, può interrogare il socket per conoscere l'indirizzo IP mittente, ed interrogare la DNSBL per sapere se il mittente è tra i cattivi oppure no. L'interrogazione avviene mediante una richiesta di risoluzione DNS, nel seguente modo:
Le risposte a tali interrogazioni vengono salvate nei DNS intermedi
che effettuano la ricorsione, in modo che le email di spam successive,
e provenienti dallo stesso OpenProxy, vengono rifiutate senza
interrogare di nuovo il DNS autorevole di chi gestisce il servizio di
DNSBL. Qualora il server SMTP di uscita di un provider finisca elencato
nella DNSBL, probabilmente a causa di un suo utente che ha prodotto un
volume di spam tale
da provocarne la segnalazione, dovrà prima eliminare la causa di spam
(ovvero sospendere l'account dello spammer, o correggere la
configurazione dei propri server SMTP di uscita)e quindi contattare gli
amministratori della lista richiedendo
la propria rimozione.
Molto spesso le email di spam arrivano con una intestazione From: falsa, nel senso che lo spammer non usa un proprio indirizzo mittente, ma uno inventato, oppure preso a prestito da un qualunque altro utente Internet. Il controllo denominato Sender Policy Framework (SPF) e descritto nella RFC 4408 viene svolto a carico dell'indirizzo email dichiarato dall'SMTP mittente nell'envelope come argomento del MAIL FROM, detto anche bounce address, e che nella maggior parte delle volte ricalca il From: delle intestazioni del contenuto. L'SPF consiste nella verifica che l'IP origine della email rientri tra quelli che l'intestatario del dominio del mittente ha pubblicamente dichiarato come ammissibili, mediante l'inserimento di un apposito Resource Record di tipo SPF (o TXT) nel file di zona relativo al proprio dominio. Ad esempio, se nel MAIL FROM viene dichiarata l'email pippo@topolinia.com, la verifica inizia con il richiedere il RR SPF presso topolinia.com, a cui potrebbe corrispondere la risposta
| topolinia.com. IN SPF "v=spf1 ip4:192.0.2.0/24 ip4:198.51.100.123 a -all" |
in cui si dichiara che l'indirizzo IP 198.51.100.123 e quelli nella sottorete 192.0.2.0/24 sono autorizzati ad inviare posta per mittenti @topolinia.com: in tal caso, se l'IP dell'SMTP di origine non ricade tra i casi ammessi, l'email dovrebbe essere rifiutata. In realtà il programma antispam che effettua questa verifica ne usa il risultato assieme agli altri controlli che esegue, per poi prendere una decisione complessiva. Di fatto, il responso delle verifiche SPF permette di realizzare un sistema di reputazione relativo al dominio mittente, mentre nel caso delle DNSBL la reputazione è quella dell'IP di origine.
In effetti questo metodo presenta degli svantaggi, come ad esempio
l'obbligo per gli utenti di un ISP di utilizzare come SMTP di uscita
quello del provider, rendendone problematico l'utilizzo in caso nomadico,
anche
se questo aspetto è controbilanciato dalla diffusione di interfaccie di
tipo Webmail, per le quali l'SMTP di invio è
sempre quello del provider stesso.
Chi riceve spam e vuol protestare, può scrivere al servizio di gestione degli abusi del proprio provider, o del provider intestatario del dominio da cui sembra provenire il traffico di spam. E' quindi interesse dei provider aderire a strumenti di controllo che permettano loro di dimostrare la propria estraneità al traffico spam, anche se in apparenza proveniente dal proprio dominio. Anche per questo, la RFC 6376 descrive la tecnica DKIM che consiste nella possibilità per il MTA di orgine di aggiungere alla email in partenza l'header DKIM-Signature: in cui inserire, tra le altre cose, la firma digitale del messaggio inviato, o almeno di alcune sue intestazioni come From: e Subject:, e dell'inizio del body. Chi riceve il messaggio può verificare tale firma disponendo della chiave pubblica del dominio che ha apposto la firma, reperita mediante una interrogazione al DNS usando come chiave, appunto il dominio firmatario.
In questo modo il provider che invia le email si dimostra come il vero
autore di questa operazione di firma,
mentre le email di spam che sembrano provenire dal dominio, ma sono
state inviate mediante altri server, non disponendo di tale firma,
possono essere scoperte più facilmente, e le segnalazioni al team anti
abuso evitate, in quanto evidente che sono uscite da altri provider.
D'altra parte, nessuno impedisce ad un utente legittimo del provider
che implementa DKIM di produrre spam, regolarmente firmato: in tal caso
sarà il team anti abuso a doversi attivare, pena la perdita
di reputazione del provider intestatario del dominio.
Prima della definizione del World Wide Web, il mondo di Internet funzionava principalmente in formato testo, ed anche così, molte persone scoprivano un mondo del tutto nuovo, e delle formidabili potenzialità di telecomunicazione con gli altri individui in rete. Probabilmente a quei tempi, gli individui che si affacciavano ad Internet erano effettivamente i più progressisti ed aperti ai cambiamenti, oppure era solo un effetto generato dalla curiosità per la novità e per la cosa che sta crescendo, oppure ancora gli utenti erano accomunati dallo stesso spirito pionieristico, ma fatto sta che la comunicazione era più ricca ed entusiasta. Citiamo nel seguito, cinque architetture di comunicazione testuale, di gruppo (e non): Mailing list, Newsgroup, BBS, Internet Relay Chat, e Instant Messenger.
Le mailing list non sono altro che liste di indirizzi email, usate in congiunzione ad un meccanismo, tale che uno stesso messaggio email venga distribuito automaticamente a tutti gli indirizzi che compaiono nella lista. Questo può avvenire in modo molto banale, configurando staticamente un server SMTP in modo da associare un singolo nome di utente fittizio (detto alias, o riflettore) alla lista, facendo si che le email dirette all'alias vengano in realtà ricevute da tutti. Il problema in questo caso, è che se nella lista si verificano avvicendamenti frequenti, diventa oltremodo noioso modificare a mano la lista dei componenti.
Per questo, sono sviluppati dei programmi appositi, detti anche mail
robot, o mailbot, che vengono
eseguiti a seguito della ricezione di una email diretta a speciali indirizzi
di gestione, grazie alla modifica del file aliases,
in modo da redirigire il contenuto delle email, verso lo standard input
dei mailbot. Se nella email sono individuati comandi
particolari,
come ad esempio la richiesta di iscrizione, o il desiderio di visionare
l'elenco degli iscritti, questi comandi sono eseguiti dal mailbot,
e l'esito inviato via email al richiedente.
Un esempio celebre di questo genere di meccanismo è majordomo, così chiamato inspirandosi al latino major domus, ossia maestro della casa. Ora che Internet è quasi sinonimo di Web, diventa poco sensato amministrare una mailing list via email, e l'applicazione in assoluto più diffusa per la gestione delle mailing list, è Mailman, scritta in Python, e che permette una personalizzazione molto spinta sia da parte dei singoli iscritti, che da parte dell'amministratore della lista. E' appena il caso di menzionare il fatto che tutto il lavoro preparatorio di discussione per quanto riguarda lo sviluppo degli standard Internet da parte di IETF, avviene per mezzo di mailing lists.
E' possibile archiviare la mailing list, in modo che i messaggi che vi transitano siano accessibili tramite interfaccia web. Ciò può essere realizzato o dallo stesso programma che gestisce la ML (come in effetti fa Mailman), oppure utilizzando un servizio di terze parti. Se poi l'interfaccia web all'archivio permette a chi legge anche di scrivere, allora si ottiene un risultato simile a quello del Newsgroup, a partecipazione aperta. Esempi di questo approccio sono Gmane, MARC, Nabble, Google Groups, Yahoo Groups.
E' una parola derivata dalla contrazione del vocabolo inglese net (rete) e quello di lingua francese étiquette (buona educazione), e descrive un insieme di regole di buona condotta, che dovrebbero disciplinare il comportamento di un utente di Internet nel rapportarsi agli altri, mediante meccanismi quali newsgroup, mailing list, forum, e-mail, o in genere, mediante qualunque tipo di comunicazione scritta. In questo contesto, assume significato l'uso degli emoticon, (compresi quelli in stile asiatico) per veicolare in modo esplicito il proprio stato d'animo, e disambiguare le circostanze in cui il lettore può equivocare che una frase scherzosa, possa invece essere ritenuta offensiva.
Anzichè discutere mediante lo strumento delle mailing list, permettendo solo agli aderenti di partecipare, perché non permettere anche a terze persone di visionare ciò che è descritto dagli altri, e prendere parte alla discussione? Probabilmente per soddisfare questo desiderio, fu definito il protocollo NTTP (Network News Transfer Protocol, RFC 3977, che aggiorna la RFC 977), che ha dato vita al servizio indicato come Usenet, a significare il possesso della rete da parte degli utenti: in effetti, partecipare a Usenet è l'equivalente virtuale dello scendere in piazza e discutere liberamente con gli altri dei fatti e dei temi che si desidera, e ciò rappresenta inequivocabilmente un elemento di democrazia.
Tecnicamente, i diversi server NNTP comunicano tra loro secondo il
principio di mantenere sincronizzato
l'insieme dei messaggi che ogni server riceve da parte degli utenti che
vi si connettono, con quello degli altri server NNTP. Presso i server
sono definiti i diversi argomenti di discussione, detti newsgroup,
organizzati in gerarchie
che categorizzano gli argomenti stessi in sotto-argomenti, e
sotto-sotto argomenti. Considerando che Usenet ha una propagazione
mondiale, e che ogni popolo ha pur sempre il diritto di discutere nella
propria lingua, possiamo restringere il campo alla gerarchia
in lingua italiana.
Per partecipare ad Usenet, la maggior parte dei lettori email offre la possibilità di definire un nuovo account news (anzichè email), configurando il newsserver a cui ci si desidera collegare, che in generale, corrisponde a quello ospitato presso il proprio provider. Infatti, come avviene per i server SMTP, anche i server NNTP negano l'accesso ai client esterni alla propria rete. In alternativa, esistono svariate iniziative che, in analogia al servizio di webmail, offrono una interfaccia web ai newsgroup, come a esempio Google e Roar, o Mailgate, che è stato un caso storico, ma poi venne chiuso. Anche se l'utilizzo dei newsgroup mediante client personale è più completo, e privo della pubblicità inserita dal portale, l'accesso web ha il vantaggio di non dipendere dalla conoscenza del proprio server NNTP, e può aiutare a farsi una idea.
 I
Bullettin
Board Services
si sono sviluppati parallelamente ai Newsgroup, e sono ormai quasi del
tutto tecnologicamente superati, ma rappresentato tuttora un ottimo
esempio di comunicazione assolutamente autogestita. Si tratta infatti,
ancora una volta, di una rete di computer che mantengono sincronizzate
le rispettive basi di messaggi, ma i collegamenti tra computer non si
avvalevano della rete Internet, ma del modem su rete telefonica
commutata, rimuovendo qualunque forma di dipendenza da fornitori di
connettività dati. Attualmente, molte BBS oltre a fornire ai propri
utenti un accesso via modem, sono altresì accessibili (per ironia) via
Internet, che spesso usano anche per sincronizzarsi con gli altri nodi.
Sebbene diverse BBS si possano accordare per mettersi in rete tra di
loro in modo del tutto autonomo, esiste una rete mondiale di BBS che
cooperano a mantenere viva una distribuzione globale alternativa,
chiamata FidoNet.
I
Bullettin
Board Services
si sono sviluppati parallelamente ai Newsgroup, e sono ormai quasi del
tutto tecnologicamente superati, ma rappresentato tuttora un ottimo
esempio di comunicazione assolutamente autogestita. Si tratta infatti,
ancora una volta, di una rete di computer che mantengono sincronizzate
le rispettive basi di messaggi, ma i collegamenti tra computer non si
avvalevano della rete Internet, ma del modem su rete telefonica
commutata, rimuovendo qualunque forma di dipendenza da fornitori di
connettività dati. Attualmente, molte BBS oltre a fornire ai propri
utenti un accesso via modem, sono altresì accessibili (per ironia) via
Internet, che spesso usano anche per sincronizzarsi con gli altri nodi.
Sebbene diverse BBS si possano accordare per mettersi in rete tra di
loro in modo del tutto autonomo, esiste una rete mondiale di BBS che
cooperano a mantenere viva una distribuzione globale alternativa,
chiamata FidoNet.
Le chat offerte da siti web e da applicazioni di Instant Messaging sono tutte evoluzioni delle chat con cui chi si collegava via modem ad una BBS, poteva dialogare con il gestore (sysop) della BBS stessa. Queste ultime forme di comunicazione, hanno a loro volta tratto ispirazione dal comando talk, in cui lo schermo del terminale viene suddiviso in due zone, ed i caratteri immessi dall'interlocutore, appaiono uno alla volta.
 L'IRC
(Internet Relay Chat) è la standardizzazione Internet dello stesso
concetto, ed è basato su di un network di server chat, interconnessi a
formare uno spanning
tree,
in modo da propagare in modo efficiente i messaggi che ogni server
riceve dagli utenti connessi allo stesso. La formalizzazione IETF del
protocollo di IRC è la RFC
1459,
a cui sono da affiancare le successive evoluzioni, anche se le diverse
implementazioni del server IRC tendono sempre a divergere un pò. Ad
esempio, fin dall'inizio non si è previsto alcun supporto per i
caratteri non-ASCII, con il risultato che possono coesistere clients
che usano contemporaneamente codifiche diverse ed incompatibili (ad es.
ISO 8859-1 e UTF-8).
L'IRC
(Internet Relay Chat) è la standardizzazione Internet dello stesso
concetto, ed è basato su di un network di server chat, interconnessi a
formare uno spanning
tree,
in modo da propagare in modo efficiente i messaggi che ogni server
riceve dagli utenti connessi allo stesso. La formalizzazione IETF del
protocollo di IRC è la RFC
1459,
a cui sono da affiancare le successive evoluzioni, anche se le diverse
implementazioni del server IRC tendono sempre a divergere un pò. Ad
esempio, fin dall'inizio non si è previsto alcun supporto per i
caratteri non-ASCII, con il risultato che possono coesistere clients
che usano contemporaneamente codifiche diverse ed incompatibili (ad es.
ISO 8859-1 e UTF-8).
La comunicazione su IRC avviene nell'ambito dei cosiddetti canali, che possono essere locali ad un certo server, oppure propagati a tutti i server che fanno parte delle rete IRC. Di reti IRC, al mondo ne esistono migliaia, e quella italiana più diffusa, è Azzurra, mentre quella con più utenti è IRCnet, a distribuzione mondiale; infine, Freenode offre principalmente supporto ai progetti OpenSource. Ci si collega con una vasta scelta di client.
Le applicazioni di Messaggistica istantanea hanno guadagnato una grande popolarità in virtù della visibilità di cui godono i service provider a cui fanno riferimento i rispettivi programmi client, ed i cui maggiori esponenti sono
Ognuna di queste applicazioni consta di una popolazione di utenti, e tutti assieme individuano una community di utilizzatori, la cui numerosità stimata complessiva ammonta a diverse centinaia di milioni di individui.
 La
maggior parte di queste applicazioni opera con una modalità
client-server, in cui ogni client fa capo ad unico server
centralizzato, che implementa il protocollo di comunicazione nei
confronti di tutti i client. Inoltre, la politica più diffusa, è quella
di ostacolare lo sviluppo di prodotti di terze parti che si possano
connettere a queste reti, tentando di fidelizzare i propri utenti
all'uso del proprio client, tramite il quale si possono più facilmente
introdurre estensioni e nuove caratteristiche. Solo da poco, alcuni di
questi provider stanno seguendo un approccio di "apertura" reciproca
(come Yahoo e MSN, oppure AIM e ICQ), comunque sempre dettato da
motivazioni commerciali.
La
maggior parte di queste applicazioni opera con una modalità
client-server, in cui ogni client fa capo ad unico server
centralizzato, che implementa il protocollo di comunicazione nei
confronti di tutti i client. Inoltre, la politica più diffusa, è quella
di ostacolare lo sviluppo di prodotti di terze parti che si possano
connettere a queste reti, tentando di fidelizzare i propri utenti
all'uso del proprio client, tramite il quale si possono più facilmente
introdurre estensioni e nuove caratteristiche. Solo da poco, alcuni di
questi provider stanno seguendo un approccio di "apertura" reciproca
(come Yahoo e MSN, oppure AIM e ICQ), comunque sempre dettato da
motivazioni commerciali.
 Cionostante, vi sono applicazioni tipicamente
dell'Open Source, come ad esempio
Cionostante, vi sono applicazioni tipicamente
dell'Open Source, come ad esempio
che a seguito di una operazione di reverse engineering, permettono il collegamento contemporaneo su diverse di queste reti.
In contrapposizione alle reti proprietarie sopra descritte, i servizi di messaggistica possono essere realizzati anche in accordo a specifiche pubbliche.

Lo IETF ha pubblicato come RFC 3920, 21, 22 e 23, le specifiche dell'Extensible Messaging and Presence Protocol (XMPP), alla base del funzionamento della piattaforma Jabber, e che offre una gamma veramente molto vasta di estensioni, sia stabili, che in via di sviluppo, che allo stadio di proposte.
La rete Jabber non prevede un unico server centralizzato, ma ogni utente è individuato da una URI del tipo di quelle previste per l'email, ed i messaggi che gli sono diretti, transitano per il server associato alla parte dominio della proprio indirizzo, proprio come avviene per le e-mail.
La architettura XMPP prevede l'esistenza di Gateway che interfacciano la rete Jabber con quelle basate sui diversi protocolli di Messagging, come ad es. MSN o ICQ, permettendo ad un client Jabber, di comunicare con tutti gli altri. Una volta che un client Jabber si connette ad un server che implementa il gateway verso la rete di messaggistica desiderata, deve comunicare al server jabber l'identità e le credenziali con le quali può accedere all'altra rete; a quel punto, il server Jabber si connetterà alla diversa rete impersonando l'identità del client, comportandosi come un proxy, e convertendo le primitive del protocollo di un lato del gateway, in quelle del protocollo dell'altro versante.
Il WG IETF SIMPLE (SIP for Instant Messaging and Presence Leveraging Extensions) definisce come il protocollo SIP, progettato per il VoIP, possa offrire il supporto alle funzioni di Presenza e Messaggistica Istantanea, a loro volta definite nella RFC 2778. In particolare, nelle RFC 3265 e 3856, viene descritto il supporto a queste funzioni, mentre in un recente Draft, si riassume l'intreccio delle specifiche di cui tenere conto. Piuttosto che addentrarci in dettagli, esponiamo i concetti base coinvolti.
La funzione di Presenza è definibile come la gestione di una informazione di stato, relativa ad una entità definibile come Presentity, che viene resa nota ad un insieme di altre entità, definibili come Watchers.
| +---------------------------+ | PRESENCE SERVICE | +---------------------------+ ^ | | | | v +------------+ +------------+ | PRESENTITY | | WATCHER | +------------+ +------------+ |
Tipicamente una Presentity,
di propria volontà, mentiene informato il gestore del servizio di
presenza a riguardo dei propri cambiamenti di stato, mentre un Watcher
può interrogare periodicamente il servizio di presenza, oppure
(preferibilmente) sottoscrivere (Subscribe) il
servizio, e ricevere delle notifiche (Notify)
ogni qualvolta l'informazione sia cambiata.
La derivazione di queste definizioni, a partire dal tradizionale comportamento di una applicazione di messaggistica, in grado di mostrarci lo stato dei nostri contatti, è più che evidente. La possibilità di trasmettere a distanza, oltre ai propri scritti, oltre alla propria voce e/o immagine, anche la propria propensione alla comunicazione, apre un nuovo modo di intendere le telecomunicazioni, che meriterebbe senz'altro una approfondita analisi psico-sociale.
Rimanendo invece sul piano tecnico, notiamo come la formalizzazione delle funzioni di Presenza e Messaggistica Istantanea espressa nel contesto della RFC 2778, ha consentito di definire nella RFC 3859 un Common Profile for Presence (CPP), in modo tale che le applicazioni che aderiscono al CPP, abbiano buone possibilità di poter interoperare, e scambiarsi questo tipo di informazione.
Di
diffusione piuttosto recente, i loro punti di forza possono essere
individuati nella possibilità di mantenere in contatto gruppi di
persone legate da interessi comuni, e nella capacità di integrare in
uno stesso contesto comunicativo contenuti mutuati da altre fonti
Internet (come fa ad es. Facebook). Allo stesso tempo, i servizi di
social network inglobano anche altre teconologie particolari come la
chat multiutente e l'informazione di stato, che se aggiornata molto
frequentemente diviene essa stessa una sorta di chat, come per Twitter.
All'aumentare del numero di utenti di una piattaforma di social network, crescono le tariffe proposte agli inserzionisti pubblicitari, replicando così un business model nato con la stampa, ed evolutosi con la televisione, in cui il bene venduto dell'editore è l'attenzione catturata ai propri lettori. Con la differenza che ora gli inserti pubblicitari possono non essere gli stessi per tutti gli utenti, ma possono invece essere differenziati in base alle caratteristiche presunte o desunte per ogni singolo utente.
Effettivamente, il lavoro sviluppato del WG SIMPLE aderisce al CPP, così come vi aderiscono le specifiche emesse dall'Open Mobile Alliance (OMA), che definisce standard aperti per l'industria della telefonia mobile. Vi fanno parte tutti i maggiori produttori di telefonini e loro derivati, operatori mobili, e produttori di software, ed intrattiene relazioni con le altre organizzazioni di standardizzazione, come 3GPP, 3GPP2, IETF, W3C. E cosa dire, allora, di Open Handset Alliance? (video)
Senza dover necessariamente ricorrere a tutti i costi al telefonino, le
stesse applicazioni di messaggistica supportano funzioni audio-video del
tutto equivalenti, se non superiori, a quelle offerte dagli operatori
telefonici, ad un costo assai inferiore, al punto che i telefonini stessi,
sono in procinto di saltare
sul carro dell'accesso WiFi
ad Internet. Infatti, oltre alle applicazioni storicamente ed
esplicitamente nate per il Voice over IP (VoIP)
come H.323, SIP
o Skype, anche i
messenger nati per il solo supporto alla comunicazione testuale si stanno
dotando di funzionalità di comunicazione audio e video, al punto da
coniare per questi il termine di Voice
over Instant Messaging (VoIM), mentre qualcuno prova ad usare il
termine di CoIP-Communication over IP (video),
a rimarcare la funzione di collante tra testo, voce e dati, svolta dalle
applicazioni di messaggistica.
Mentre MSN, Yahoo, AIM e ICQ, al solito, adottano soluzioni proprietarie, Gtalk adotta libjingle, una estensione di XMPP. Inoltre, è da segnalare l'iniziativa di Gtalk2VoIP, che offre un gateway per le chiamate audio tra le reti MSN, Yahoo, AIM, ICQ, Gtalk, SIP e PSTN.

Dal TCP al VoIP, dal DNS all'Email alla crittografia, tutto ciò che accade
dietro le quinte di Internet, completo di cattura del traffico.
Scopri
come effettuare il download,
ricevere gli aggiornamenti,
e contribuire!

{kind=link}