 Il
normale flusso dell'informazione da sorgente a destinazione può essere
alterato fraudolentemente, secondo uno dei quattro casi illustrati in
figura:
Il
normale flusso dell'informazione da sorgente a destinazione può essere
alterato fraudolentemente, secondo uno dei quattro casi illustrati in
figura:Lo strato applicativo di Internet
Questa sezione fornisce una panoramica sugli aspetti di sicurezza che intervengono nelle architetture di telecomunicazione Internet, senza per questo affrontare tutti gli aspetti della sicurezza informatica.
Prima di tutto, forniamo alcune definizioni dei concetti inerenti gli aspetti di sicurezza, come i tipi di attacchi alla sicurezza, i servizi che la sicurezza può offrire, i meccanismi con cui si attua, e la localizzazione di questi servizi.
Il
normale flusso dell'informazione da sorgente a destinazione può essere
alterato fraudolentemente, secondo uno dei quattro casi illustrati in
figura:
Questi attacchi possono essere condotti in forma passiva, come nel caso della intercettazione, o della analisi del traffico, oppure in forma attiva, secondo le categorie
Per prevenire e/o ostacolare gli attacchi di sicurezza, vengono messi in opera un serie di espedienti, che realizzano una o più delle seguenti funzioni, o servizi di sicurezza:
Non esiste un singolo meccanismo, od algoritmo, capace di fornire in un colpo solo tutti i servizi di sicurezza elencati, ma si tratta sempre e comunque di ricorrere a funzioni sviluppate nel campo della crittografia, e utilizzate in modo da cooperare alla realizzazione di un modello di architettura di sicurezza, molto sinteticamente descritto da questa figura.

Una terza parte fidata si occupa di distribuire alle parti principali in comunicazione una informazione segreta, usata per operare una trasformazione di sicurezza, tale proteggere il canale di comunicazione dall'intervento di un opponente, intenzionato a portare un attacco.
Le trasformazioni di sicurezza possono essere localizzate sia agli estremi (ellissi nere) delle due parti in comunicazione, sia presso gli estremi dei singoli collegamenti (ellissi grigie) che vengono attraversati dalla comunicazione. Il primo caso tipicamente avviene ad opera dello strato applicativo in esecuzione presso le parti in comunicazione, come ad esempio nel caso di TLS, S/MIME, PGP, o dei meccanismi di autenticazione di utente, mentre il secondo è quanto avviene in base alla collezione di protocolli IPSec.

Si basa sull'esistenza di un segreto condiviso, noto alle due parti in comunicazione, e che funziona come chiave (o seme) per un algoritmo crittografico reversibile (per questo detto simmetrico), e tale da rendere molto difficile risalire alla chiave, anche venendo in possesso del testo in chiaro, oltre che della sua versione crittografata.
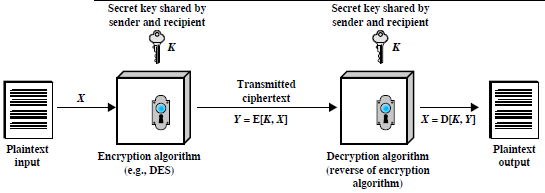
Gli algoritmi crittografici in uso sono denominati:
Nella crittografia convenzionale i rischi di sicurezza aumentano, quanto più materiale viene crittografato usando sempre la medesima chiave, rendendo sempre meno complicato per un intercettatore, tentare di scoprire la chiave usata. La tipica soluzione contro questo problema passa dall'utilizzo di una chiave di sessione, la cui validità si protrae per la durata di un solo collegamento, dopodiché viene distrutta, in modo da non dare ad un intercettatore il tempo di forzare il codice. Nella figura che segue è illustrato uno schema di principio in cui si postula l'esistenza di una entità di distribuzione, che viene contattata dall'entità che intende generare il messaggio, e che fornisce la chiave di sessione, trasmettendola in forma crittografata mediante una chiave permanente, nota sia al distributore che alle altre entità.
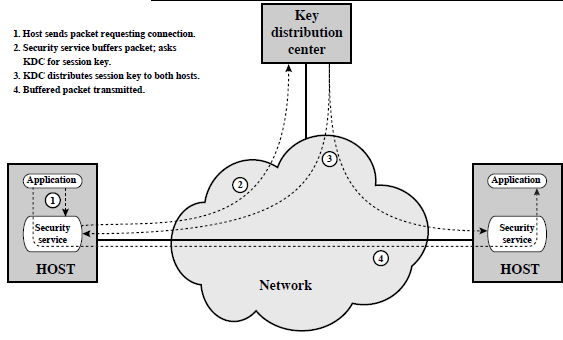
La
stessa chiave di sessione è fornita anche al destinatario, sempre in
forma crittografata, mettendolo in grado di decrittare il messaggio in
arrivo. La chiave di sessione non deve essere necessariamente
distribuita da una entità separata, ma può anche essere generata da una
delle due parti in comunicazione, come vedremo appresso.
Mentre
la crittografia (in generale) protegge dagli attacchi di tipo passivo
(ad es, l'intercettazione), la garanzia che il messaggio ricevuto è
autentico, sia nel contenuto (integrità) che nel mittente
(autenticità), ricade nei compiti delle procedure di autenticazione. In
linea di principio, impiegando tecniche di crittografia convenzionale,
in cui mittente e destinatario condividono la stessa chiave segreta e
la comunicazione viagga crittografata, la corretta decrittazione di un
messaggio ricevuto, oltre a garantirne l'integrità, garantirebbe anche
a riguardo della sua provenienza (dato che solo il mittente possiede il
segreto condiviso), realizzando così la funzione di autenticazione
mediante la stessa tecnica usata per la confidenzialità.
Viceversa, sussistono dei buoni motivi per mantenere il messaggio in chiaro, tralasciando quindi la confidenzialità, e ottemperare ai requisiti di integrità e autenticità mediante la spedizione, assieme al messaggio, di un Message Authentication Code (MAC). Come buoni motivi, citiamo i casi in cui
 Un algoritmo MAC
accetta in ingresso un messaggio da autenticare ed una chiave segreta K,
e produce in uscita una etichetta (detta appunto, MAC) che dipende dai
due ingressi, e che viene allegata al messaggio. Il ricevitore del
messaggio, se conosce la stessa chiave segreta, può effettuare lo
stesso calcolo a partire dal messaggio ricevuto, e se il MAC risulta
identico a quello ricevuto, vuol dire che il mittente è in possesso
della stessa chiave usata in ricezione, e che il messaggio ricevuto non
è stato modificato; per quest'ultimo motivo, l'etichetta risultante
viene anche chiamata Message Integrity Code
(MIC), anche se questo termine si riferisce ad un controllo svolto in
modo lievemente diverso. Non è necessario che l'algoritmo MAC sia
reversibile. In particolare, questo può essere basato su di una delle funzioni crittografiche convenzionali
elencate precedentemente.
Un algoritmo MAC
accetta in ingresso un messaggio da autenticare ed una chiave segreta K,
e produce in uscita una etichetta (detta appunto, MAC) che dipende dai
due ingressi, e che viene allegata al messaggio. Il ricevitore del
messaggio, se conosce la stessa chiave segreta, può effettuare lo
stesso calcolo a partire dal messaggio ricevuto, e se il MAC risulta
identico a quello ricevuto, vuol dire che il mittente è in possesso
della stessa chiave usata in ricezione, e che il messaggio ricevuto non
è stato modificato; per quest'ultimo motivo, l'etichetta risultante
viene anche chiamata Message Integrity Code
(MIC), anche se questo termine si riferisce ad un controllo svolto in
modo lievemente diverso. Non è necessario che l'algoritmo MAC sia
reversibile. In particolare, questo può essere basato su di una delle funzioni crittografiche convenzionali
elencate precedentemente.
 Si
tratta di una trasformazione in grado di generare, in modo semplice,
una breve etichetta identificativa a partire da un generico messaggio,
anche molto più lungo. Un suo utilizzo è attinente alla costruzione di tabelle hash per l'accesso rapido ad
una raccolta di dati, ma quello è un altro discorso.
Per i nostri fini, ci basta dire che una funzione
Hash produce una uscita H(M) di
lunghezza fissa a partire da una stringa M di
lunghezza variabile di ingresso, ed il valore di uscita è chiamato valore
di hash, checksum crittografico o message digest. Le
proprietà di questa funzione si possono riassumere in
Si
tratta di una trasformazione in grado di generare, in modo semplice,
una breve etichetta identificativa a partire da un generico messaggio,
anche molto più lungo. Un suo utilizzo è attinente alla costruzione di tabelle hash per l'accesso rapido ad
una raccolta di dati, ma quello è un altro discorso.
Per i nostri fini, ci basta dire che una funzione
Hash produce una uscita H(M) di
lunghezza fissa a partire da una stringa M di
lunghezza variabile di ingresso, ed il valore di uscita è chiamato valore
di hash, checksum crittografico o message digest. Le
proprietà di questa funzione si possono riassumere in
Alcune funzioni hash usate nelle applicazioni di sicurezza sono
Dato che diverse stringhe di ingresso possono produrre lo stesso digest, la trasformazione non è reversible. Inoltre, a differenza del MAC, la funzione hash non usa una chiave segreta. Per questi motivi, una funzione hash, da sola, si presta ad applicazioni del tipo
Per il motivo illustrato nel secondo esempio, il calcolo di un MAC può far uso di una funzione hash, purchè la si associ all'uso di un segreto condiviso, alla crittografia convenzionale, od alla crittografia a chiave pubblica, secondo uno dei seguenti schemi.
Il messaggio da autenticare viene concatenato con un segreto (condiviso tra le due parti in comunicazione), e viene quindi usata una funzione hash (anch'essa nota ad entrambe le parti) per calcolare un MAC. Il segreto non viene trasmesso, mentre il MAC è concatenato al messaggio e trasmesso con esso. Da parte sua, il ricevitore concatena lo stesso segreto con la sola parte di messaggio di quanto ricevuto, e confronta il risultato con Il MAC ricevuto. Il segreto usato viene a volte indicato con il termine di sale (salt), o seme (seed), o vettore di inizializzazione (IV).

Il vantaggio principale di questa tecnica è che non viene usata nessuna funzione crittografica, riducendo il carico computazionale dei dispositivi. Inoltre, le funzioni crittografiche sono spesso ottimizzate per lunghi testi, mentre questa soluzione di presta bene anche nel caso di messaggi particolarmente brevi. Una variazione di questa tecnica è nota con il nome di HMAC.
In questo caso, il valore dell'hash viene calcolato a partire dal solo messaggio da trasmettere, e da questo viene generato un MAC mediante crittografia convenzionale, usando una chiave nota anche al destinatario. Il MAC viene quindi concatenato al messaggio, e trasmesso. Il ricevente, usando la stessa chiave, decritta il MAC, in modo da poterlo confrontare con l'hash che a sua volta ha calcolato, a partire dalla conoscenza del messaggio.

Quest'ultimo caso è simile al precedente, tranne per l'uso della crittografia asimmetrica, in cui il mittente usa la propria chiave privata per crittografare l'hash e generare il MAC, e chi riceve usa la chiave pubblica del mittente per effettuare la decrittazione.

Il metodo di generare un MAC a partire da una funzione hash e da un segreto condiviso, ha dato origine ad una tecnica particolare di autenticazione, detta HMAC, in cui una funzione hash (SHA-1 o MD5) è usata congiuntamente ad una chiave (la cui conoscenza è nota al destinatario), per generare una etichetta MAC. Se la stessa operazione eseguita a destinazione, fornisce lo stesso risultato, il destinatario ritiene che il messaggio sia autentico, perchè ha verificato la conoscenza della chiave da parte del mittente. Il metodo non fa uso di funzioni crittografiche, e quindi presenta un basso carico computazionale. La tecnica è utilizzata in IPsec, in TLS, e in tecniche di autenticazione client-server come ad esempio CRAM-MD5.
Questa metodologia, detta anche crittografia asimmetrica, e proposta da Diffie e Hellman nel 1976, è stato il primo vero rivoluzionario progresso dopo millenni. In questo caso non occorre più che le due parti si trovino d'accordo nell'usare una medesima chiave per crittografare, e recuperare la versione in chiaro del testo. Infatti:
L'esistenza di due diverse chiavi, di cui una pubblica, evita il problema della crittografia convenzionale, di dover trovare il modo di comunicare in modo sicuro anche il segreto condiviso.
Illustriamo ora come un sistema di crittografia a chiave pubblica possa essere usato per offrire un servizio di confidenzialità, di autenticazione, o di scambio di chiavi.
Una
simpatica analogia è quella di pensare alla chiave pubblica come ad una
specie di lucchetto, di cui solo il proprietario possiede la chiave
(privata). Quindi, se Bob intende spedire un messaggio ad Alice,
prima di tutto, si fa spedire da Alice un suo lucchetto aperto. Quindi,
usa la chiave pubblica (il lucchetto) di Alice, e con quella
crittografa (sigilla) il messaggio, che solo Alice, con la sua chiave
privata, potrà aprire.
Una diversa simbologia utilizza la metafora del portachiavi (keyring) mostrata sotto, per rappresentare il modo con cui vengono conservate e recuperate le chiavi pubbliche dei nostri corrispondenti, da usare per crittografare i messaggi che solo il destinatario designato può decifrare, usando la sua chiave privata.

Questo è il caso in cui Bob vuole che chiunque sia in grado di verificare che un suo messaggio è autentico, e prodotto proprio da lui. Stavolta quindi Bob esegue l'algoritmo crittografico usando la propria chiave privata, di cui è l'unico possessore, mentre chiunque (e quindi anche Alice) potrà usare la chiave pubblica di Bob, per decifrare il messaggio. Dato che, se il messaggio si apre con la chiave pubblica di Bob, vuol dire che è stato chiuso usando la rispettiva chiave privata (sempre di Bob), e che Bob ne è l'unico possessore, allora il messaggio, è sicuramente di Bob.

Spesso, si preferisce non crittografare l'intero messaggio, ma solamente un hash dello stesso, ottenendo un MAC (chiamato in questo caso firma digitale) che ognuno potrà verificare essere stato generato da Bob.
Anche
se la crittografia a chiave pubblica può essere usata a scopi di
confidenzialità, la sua maggiore complessità computazionale le rende
preferibile per questo scopo un algoritmo crittografico convenzionale,
basato su di un segreto condiviso temporaneo
già indicato con il termine di chiave
di sessione. In tal caso, la chiave di sessione può essere
trasmessa assieme al messaggio, crittografata
con una algoritmo a chiave pubblica.
Un diverso aspetto riguarda la modalità con cui vengono generate le coppie di chiavi pubblica e privata, che spesso sono calcolate a partire da un numero casuale. Per alcuni algoritmi (ad esempio, Diffie-Hellman) se entrambe le parti conoscono, oltre alla chiave pubblica del corrispondente, anche il numero casuale di partenza, è possibile che entrambe calcolino (indipendentemente) anche un medesimo segreto condiviso, da usare poi nell'ambito di una trasmissione basata sulla crittografia convenzionale, evitando così il problema della comunicazione del segreto condiviso stesso.
La seguente tabella indica gli usi più idonei per quattro algoritmi di crittografia a chiave pubblica
| algoritmo | confidenzialità | firma digitale | scambio chiavi |
| RSA | si | si | si |
| DSS | no | si | no |
| Diffie-Hellman | no | no | si |
| Curve Ellittiche | si | si | si |
Questo acronimo non ha un significato particolare, se non di essere formato dalle iniziali dei suoi tre autori, ossia Ron Rivest, Adi Shamir e Len Adleman del MIT, che lo hanno formalizzato nel 1977. Al di là dei dettagli tecnici del suo funzionamento, a fronte della sua discreta complessità computazionale, l'algoritmo si presta ad essere usato per scambiarsi una chiave di sessione crittografata con RSA, e poi proseguire la trasmissione sicura utilizzando quella, mediante un algoritmo di crittografia simmetrica.
Il Digital Signature Standard è stato proposto nel 1991 da una agenzia governativa statunitense (NIST), per offrire dei servizi di firma digitale sulla base del Digital Signature Algorithm (DSA), che utilizza SHA-1. L'ultima revisione è avvenuta nel 2000. Non viene invece usato per fornire servizi di crittografia e scambio di chiavi.
Pubblicato per la prima volta nel 1996, permette a due entità di scambiarsi in modo sicuro le reciproche chiavi pubbliche, e quindi proseguire con quelle.
Il metodo funziona a partire dalla conoscenza comune di due numeri, q che è un numero primo, e alfa che è una radice primitiva di q. Alice può allora scegliere un intero qualunque XA<q, e calcolare YA = alfaXA mod q, che costituiscono rispettivamente le sue chiavi privata (XA) e pubblica (YA). Allo stesso modo Bob, partendo dalla conoscenza degli stessi due numeri alfa e q, ottiene la sua chiave privata (XB) e pubblica (YB) scegliendo casualmente XB<q, e calcolando YB = alfaXB mod q. In linea di principio, non è necessario che i due numeri di partenza, q e alfa, siano gli stessi per le due entità, e dopo che le chiavi pubbliche ottenute sono state scambiate, si può procedere ed utilizzarle ai fini della crittografia e della autenticazione basate sugli algoritmi a chiave pubblica.
Se invece le due parti determinano il valore delle chiavi a partire dagli stessi numeri iniziali q ed alfa, è possibile calcolare, da entrambi i lati, un medesimo segreto K, che potrebbe essere poi utilizzato come chiave di sessione, nell'ambito di un contesto di crittografia simmetrica. Si può infatti dimostrare che se Alice effettua il calcolo di K = (YB)XAmod q, utilizzando la sua chiave privata XA e quella pubblica YB di Bob, quest'ultimo può pervenire allo stesso risultato calcolando K = (YA)XB mod q, ovvero utilizzando la sua chiave privata XB, e quella pubblica YA di Alice. Infatti, semplificando un pò, osserviamo che (YA)XB = ( alfaXA )XB è uguale a (YB)XA=(alfaXB)XA.
La figura seguente riassume i passi dello scambio di Diffie-Hellman: le due entità Alice e Bob, a partire dalla comune conoscenza di q e di alfa, calcolano le proprie coppie di chiavi pubblica e privata. Quindi, scambiandosi le chiavi pubbliche, mettono l'altra parte in grado di calcolare il medesimo segreto K. In assenza di un accordo a priori, i valori di q ed alfa possono essere scelti da Alice, e comunicati a Bob assieme alla propria chiave pubblica YA.

Resta ora il fatto che il segreto condiviso K potrebbe non essere idoneo ad essere usato in un algoritmo di crittografia simmetrica. Per questo motivo, anziché usare direttamente K come chiave di sessione, una delle due parti (in genere Alice, che ha iniziato lo scambio) sceglie una differente chiave di sessione (indichiamola con M), ed usa quindi K per crittografare M mediante un algoritmo simmetrico. La chiave di sessione M così crittografata viene ora trasmessa a Bob, che a sua volta usa K per recuperarla, e da quel punto in poi, proseguire la comunicazione mediante crittografia simmetrica, basata su M.
Un eventuale Man in the Middle (Eva) che assiste al primo scambio tra Alice e Bob, pur venendo a conoscenza di q, alfa e YA, ma non sapendo nulla della scelta fatta da Bob a riguardo di XB, né della chiave privata XA di Alice, non sa come calcolare K. Però, dato che la trasmissione dei numeri iniziali e delle chiavi pubbliche non è autenticata (e per questo, il metodo ora illustrato è detto anonimo), Eva potrebbe modificare i valori q, alfa e YA, inviati da Alice a Bob, con altri valori da lei impostati, e sostituirsi a Bob nel completare lo scambio di Diffie-Hellman con Alice. Quindi, Eva inizia un nuovo scambio con Bob, stavolta fingendosi Alice. Infine, intercetta tutti i messaggi tra le parti, transcodificandoli durante il transito.
Sebbene entrambe le alternative rendono di fatto non più necessario procedere con uno scambio di D&H, questo può ora essere comunque svolto in sicurezza.
Alcuni aspetti già accennati nella discussione dello scambio di Diffie-Hellman rientrano esattamente in questa definizione, che riguarda i problemi di:
La soluzione più generale, in buona analogia con i casi della vita reale, passa per la presenza di una terza parte, con cui le due parti in comunicazione hanno un rapporto di fiducia.
Come evidenziato nella discussione dell'attacco MITM per l'algoritmo D&H, nella crittografia asimmetrica sussiste il problema di come ottenere la chiave pubblica di un altro utente in modo fidato. Infatti se durante la trasmissione della chiave pubblica di Alice a Bob, un man in the middle (Eva) intercettasse il messaggio e lo sostituisse con un altro, contenente la propria chiave pubblica, Eva potrebbe poi spacciarsi per Alice, e leggere i messaggi destinati a lei.
Per risolvere questo problema, si ricorre all'esistenza di una terza
parte, una sorta di garante, detta Certification
Autority (CA), e di cui è possibile procurarsi con un elevato
grado di affidabilità la chiave pubblica, ad esempio, per averla ricevuta
di persona.
Una entità che desidera che la propria identità sia certificata dalla
CA, gli consegna a sua volta la propria chiave pubblica, in modo
affidabile, come ad esempio affidandogliela di persona, e mostrando un
documento di identità.
La CA associa quindi alla chiave pubblica dei singoli individui l'identità del legittimo proprietario, mediante l'emissione di un Certificato Digitale, che asserisce tale associazione, e che viene firmato utilizzando la chiave privata della CA come mostrato in figura, ovvero

Chi riceve il certificato firmato può verificare l'autenticità dello stesso, e quindi fidarsi che la chiave pubblica presente nel certificato sia veramente quella della entità a cui il certificato è intestato, svolgendo le operazioni previste per l'autenticazione mediante funzioni Hash associate alla crittografia a chiave pubblica, ovvero
Poco sopra abbiamo illustrato come lo scambio
di Diffie-Hellman
consente a due parti il calcolo di uno stesso segreto condiviso, senza
la necessità che lo stesso venga trasmesso, ma è esposto ad attacchi di
tipo MITM, che possono essere sventati ricorrendo ad una Certification
Authority. Infatti, se Alice è intestataria di un certificato firmato
da una CA, che attesta il possesso da parte di Alice di una chiave
pubblica a lungo termine, può usare la chiave
privata associata per firmare
i dati iniziali dello scambio, e trasmettere assieme a questi anche il
certificato, in modo che Bob, dopo aver verificato autenticità e
integrità del certificato usando la chiave pubblica della CA, possa
usare la chiave pubblica presente nel certificato di Alice per
verificarne l'autenticità della firma apposta sui valori di alfa
e di q.
Ma, nel caso in cui esista una CA la cui chiave pubblica è distribuita in modo affidabile alle parti in comunicazione, le quali hanno altresì provveduto a certificarsi presso la CA stessa, decade la necessità di effettuare uno scambio di Diffie-Hellman completo! Infatti, è possibile crittografare con un algoritmo simmetrico il messaggio da inviare, e spedirlo assieme alla chiave necessaria ad aprirlo, crittografando quest'ultima con la chiave pubblica del destinatario, che viene letta dal certificato (firmato) del destinario, e noto al mittente; in questo modo, il ricevente può decrittare la chiave dell'algoritmo simmetrico, facendo uso della propria chiave privata.
Una Infrastruttura di Chiave Pubblica (Public Key Infrastructure) permette ad individui ed utenti di asserire la propria identità e verificare quella degli altri, e si basa sulla accessibilità di certificati digitali firmati da una Certificate Authority, abilitando in tal modo le entità a procedere allo sviluppo di una comunicazione sicura facente uso di tecniche crittografiche qualsiasi.
 E'
uno
standard ITU-T che definisce, fra le altre cose, formati standard
per i certificati a chiave pubblica, i loro meccanismi di revoca, e la gerarchia delle CA. Nasce nel 1988 in
relazione al servizio di directory X.500,
ed assume l'esistenza di una rigida organizzazione gerarchica delle CA,
tale da prevedere per ognuna di esse la firma del proprio certificato
da parte di una CA più importante, su su fino
ad una unica CA radice.
Viene definita una architettura (vedi fig. a lato) in cui le CA hanno
il solo compito di firmare i certificati, mentre l'emissione degli
stessi è delegata ad una diversa entità, indicata come Registration
Autority (RA), e la loro conservazione è delegata ad un Certificate
Repository
(CR). Anche dopo diverse revisioni, questa architettura non si è mai
realizzata, mentre il servizio di directory X.500 si è evoluto nel Lightweight Directory Access Protocol (LDAP).
Attualmente per certificato X.509 si intende quello definito nell'ambito
del profilo formalizzato nella RFC
5280 prodotta dal gruppo di lavoro IETF PKIX,
che sta per Public Key Infrastructure (X.509).
E'
uno
standard ITU-T che definisce, fra le altre cose, formati standard
per i certificati a chiave pubblica, i loro meccanismi di revoca, e la gerarchia delle CA. Nasce nel 1988 in
relazione al servizio di directory X.500,
ed assume l'esistenza di una rigida organizzazione gerarchica delle CA,
tale da prevedere per ognuna di esse la firma del proprio certificato
da parte di una CA più importante, su su fino
ad una unica CA radice.
Viene definita una architettura (vedi fig. a lato) in cui le CA hanno
il solo compito di firmare i certificati, mentre l'emissione degli
stessi è delegata ad una diversa entità, indicata come Registration
Autority (RA), e la loro conservazione è delegata ad un Certificate
Repository
(CR). Anche dopo diverse revisioni, questa architettura non si è mai
realizzata, mentre il servizio di directory X.500 si è evoluto nel Lightweight Directory Access Protocol (LDAP).
Attualmente per certificato X.509 si intende quello definito nell'ambito
del profilo formalizzato nella RFC
5280 prodotta dal gruppo di lavoro IETF PKIX,
che sta per Public Key Infrastructure (X.509).
Perché il certificato di Alice, emesso da CA1, sia di di qualche utilità per Bob, questi deve conoscere con certezza la chiave pubblica di CA1, in modo da poter verificare la sua firma. In caso negativo, se Bob conosce invece la chiave pubblica di una diversa autorità, ad esempio di CA2, può tentare di trovare un certificato di CA1 che sia firmato da CA2, perché in tal caso può usare la chiave pubblica di CA2 per verificare l'autenticità della chiave pubblica di CA1, e quindi finalmente usare questa, per verificare il certificato di Alice. Nel caso in cui CA1 e CA2 non si siano certificate a vicenda, lo stesso processo può essere ripetuto attraversando un numero qualunque di CA.
Un certificato X.509 contiene le informazioni riportate in figura, ossia

Per avere una idea del risultato finale, possiamo osservare alcuni esempi di certificati, oppure scoprire i certificati delle root CA che troviamo preinstallati nel nostro browser.
Può capitare che ci si ritrovi per le mani un certificato, senza avere a disposizione la chiave pubblica della CA che l'ha firmato, oppure, un certificato auto-firmato, e si abbia la necessità di usare la chiave pubblica che vi compare, senza però voler correre il rischio di rimanere vittima di una impersonificazione frudolenta. Allora, la cosa più semplice che si può fare è tentare di contattare la persona/entità a cui è intestato il certificato, e chiedergli se la chiave pubblica scritta nel certificato è veramente la sua. Dato però che una chiave pubblica può essere molto lunga, si è diffuso il costume di calcolare un hash della versione codificata (ad es DER) del certificato X.509, in genere di lunghezza ridotta (ad es, 32 cifre esadecimali), e di chiamarlo fingerprint (impronta digitale). In questo modo la fingerprint può ad esempio essere facilmente letta a voce al telefono, o facilmente verificata perché scritta su di un sito web, e può essere presa con sufficiente affidabilità come la prova che il certificato in proprio possesso è conforme a quello posseduto dall'intestatario.
Per ottenere un proprio certificato occorre generare una coppia di
chiavi, compilare una richiesta di firma certificato in cui
compaiono gli elementi che concorrono a formare il proprio Distinguished
Name, allegare alla richiesta la propria chiave pubblica, e firmare la richiesta utilizzando la propria chiave
privata, che d'ora in poi dovrà essere custodita con la massima cura.
Se ad es. gestiamo un sito Web e vogliamo utilizzarne il certificato per autenticarci verso altre entità, con cui non abbiamo nessun rapporto preesistente, dobbiamo sottoporre la richiesta del certificato ad una CA la cui chiave pubblica è già ampiamente distribuita, come ad esempio avviene per quelle preinstallate con il browser. In questo caso la CA (o, più correttamente, la RA) può (e deve) svolgere alcune verifiche formali, come ad esempio accertarsi (mediante il comando whois e/o host) che il richiedente corrisponda all'intestatario del dominio citato nella registrazione, e/o che il richiedente abbia accesso all'indirizzo email che risulta dai comandi di ispezione. Pertanto, la visita con successo di un sito web sicuro, ci garantisce unicamente che esiste un qualche rapporto tra lo sviluppatore del sito e il manutentore del dominio che compare nella sua URI.
I browser web sono distribuiti con preinstallati i certificati autofirmati di diverse CA, con cui i produttori del browser hanno stretto un accordo, in modo da semplificare la verifica di autenticità dei siti che inviano un loro proprio certificato. Per visionare i certificati preinstallti, ad es. su Firefox entrare in Modifica/Preferenze/Avanzate. Per un esempio di sito sicuro, si visiti ad es. https://addons.mozilla.org/it/firefox/.
Una volta che la CA, in base alle informazioni presenti nella richiesta, ha generato un nuovo certificato intestato al richiedente, e l'ha firmato, il risultato di queste operazioni viene salvato in un file, che può essere consegnato al richiedente, e/o a quanti potranno richiederlo. Prima di distribuirlo, però, questo file viene sottoposto ad una tra diverse possibili modalità di codifica, che determinano altresì il tipo di estensione usato per salvarlo, come ad esempio
Ad ogni certificato è associato un periodo di validità, e prima che questo scada, il certificato deve essere rinnovato, e prodotta una nuova copia. Ma anche se il certificato non è ancora scaduto, può essere revocato in anticipo, perché ad esempio la chiave privata del proprietario è stata compromessa, il proprietario non è più certificato, o si pensa che il certificato sia stato compromesso. Ogni CA mantiene quindi una lista (CRL, Certificate Revocation List), firmata, contenente l'elenco dei certificati emessi, ancora nominalmente validi, ma revocati. Quando si riceve un certificato, sarebbe bene richiedere alla CA che l'ha emesso, l'invio della CRL, in modo da poter verificare se questo non sia stato revocato. A fronte della evidente complicazione di questo modo di operare, nella RCF 2560 è stato definito un Online Certificate Status Protocol (OCSP) che opera tramite messaggi codificati in ASN.1 e trasmessi via HTTP, e che permette le verifiche di revoca di certificato in modo molto più veloce dello scaricamento ed elaborazione della intera CRL.
Per quanto illustrato, chiedere il rilascio (a pagamento) del certificato
per il proprio sito ad una
CA
la cui chiave pubblica è preinstallata nel browser, consente di avere
il proprio certificato immediatamente riconosciuto come valido; dato
però che queste CA sono tutte root, i loro
certificati risulteranno auto-firmati. In
alternativa, ci si può rivolgere ad esempio a CaCert,
che offre certificati gratuiti, ed il cui certificato autofirmato può
essere importato
in modo facile dal browser. Oppure, se non ci si vuol rivolgere ad una
CA esterna, è sempre possibile assolvere a tale funzione in proprio, ad
esempio usando gli strumenti offerti dal progetto OpenSSL.
Una volta creato
il certificato autofirmato dalla propria auto-CA,
questo deve essere esportato presso i clients (ad esempio, di una
stessa azienda) che poi lo useranno per verificare i certificati che
firmeremo. L'esportazione può avvenire sia mediante un diverso canale
fisico (consegna fisica di un dischetto, od un CD), oppure
creando in
proprio
una distribuzione Linux installabile da CD, e contenente il certificato,
oppure ancora via
rete
mediante una email sicura, una rete WiFi sicura, o una pagina web sicura,
descrivendo
il certificato
mediante un header MIME Content-Type:
application/x-x509-ca-cert.
L'uso di certificati autofirmati espone chi li accetta per la prima volta al rischio di un attacco di tipo man-in-the-middle, perché un attaccante potrebbe sostituire il suo certificato a quello ritenuto legittimo, e poi continuare ad impersonificare l'interlocutore. Ma se il certificato è corretto, ed è salvato dal client, gli scambi successivi avvengono senza ulteriori rischi di sicurezza.
Una web of trust
(rete di fiducia) è un concetto utilizzato da PGP,
GnuPG, e altri sistemi compatibili con OpenPGP,
per stabilire l'autenticità dell'associazione chiave pubblica-utente,
alternativa all'uso delle Certificate Authority.
In questo caso l'autenticità di una chiave pubblica è sottoscritta
(firmata) direttamente da altre persone, in occasione di incontri
fisici appositamente
organizzati,
in cui ognuno firma la chiave pubblica degli altri presenti convenuti;
le chiavi pubbliche così firmate, possono quindi essere distribute
individualmente, oppure essere messe a disposizione su di un keyserver.
Quando si viene in possesso di una chiave pubblica altrui, è possibile impostare l'affidabilità da attribuire ai suoi diversi firmatari considerando massimamente fidate le firme apposte da persone (chiamiamoli amici) che ci hanno consegnato la loro chiave pubblica di persona, e via via meno fidate, le firme apposte da persone che sono solo amici di amici (la cui chiave è firmata da amici), o amici di amici di amici (di amici di amici...). A partire dalla versione 3, anche X.509 ha previsto la possibilità di costruire una rete di fiducia, ma orientata solamente a far firmare alle CA, i certificati di altre CA.
LDAP è un protocollo standard per l'interrogazione e la modifica dei servizi di directory, ovverosia di meccanismi per il recupero di una serie di informazioni relative ad un oggetto che sia possibile specificare in modo univoco, come ad esempio una password associata ad un account email. A questo proposito, il CCITT creò lo standard X.500 nel 1988, che divenne ISO 9594 Data Communications Network Directory Recommendations X.500-X.521 nel 1990. A quel punto lo IETF intraprese un lavoro di semplificazione dell'X.500, adattandone la modalità di accesso al TCP. Mentre la RFC 1487 originale (X.500 Lightweight Directory Access Protocol) è del 1993, la sua ri-definizione più recente avviene nel 2006 ed è descritta dalla RFC 4510 e seguenti.
 Anche
se, a prima vista, un servizio di directory appare molto simile a quello
offerto da un DataBase,
in realtà quest'ultimo è ottimizzato sia per le operazioni di lettura
che di scrittura, mentre si presume che le informazioni presenti sul Directory Server varino molto più raramente.
Inoltre, X.500 organizza le informazioni come una struttura rigidamente ad
albero, detto Directory Information Tree o
DIT. Ogni nodo dell'albero è associato ad un Relative
Distinguished Name (RDN) che è un attributo
definito da un tipo ed uno o più valori che lo
distinguono dai nodi fratelli
posti allo stesso livello della gerarchia. Concatenando tutti gli RDN
dal nodo in questione, su su fino alla radice dell'albero, si ottiene
il Distinguished Name (DN) (vedi RFC4514)
dell'elemento, che lo rappresenterebbe in modo
globalmente unico. La figura a lato esemplifica l'individuazione
dell'oggetto
Anche
se, a prima vista, un servizio di directory appare molto simile a quello
offerto da un DataBase,
in realtà quest'ultimo è ottimizzato sia per le operazioni di lettura
che di scrittura, mentre si presume che le informazioni presenti sul Directory Server varino molto più raramente.
Inoltre, X.500 organizza le informazioni come una struttura rigidamente ad
albero, detto Directory Information Tree o
DIT. Ogni nodo dell'albero è associato ad un Relative
Distinguished Name (RDN) che è un attributo
definito da un tipo ed uno o più valori che lo
distinguono dai nodi fratelli
posti allo stesso livello della gerarchia. Concatenando tutti gli RDN
dal nodo in questione, su su fino alla radice dell'albero, si ottiene
il Distinguished Name (DN) (vedi RFC4514)
dell'elemento, che lo rappresenterebbe in modo
globalmente unico. La figura a lato esemplifica l'individuazione
dell'oggetto
| cn=Barbara Jenson, ou=Sales, o=Acme, st=California, c=US |
nell'ambito di una tale organizzazione, come pensata nelle intenzioni originarie, in cui sarebbe dovuta esistere una unica radice universale per tutti gli alberi X.500. Nella pratica attuale, è più comune il caso in cui ai livelli dell'albero si fanno corrispondere i livelli del FQDN presso il quale è localizzata la risorsa, delegando al DNS il compito di mantenere una gerachia globale, e individuando un oggetto mediante la sintassi del tipo uid=babs, ou=People, dc=example, dc=com che rappresenta l'utente (uid) babs presso l'Unità Organizativa (ou) People a cui è intestato il nome a dominio (dc) example.com. In entrambi i casi, nel livello inferiore a quello che individua una persona, si trovano i nodi associati alle diverse informazioni ad esso associate, come indirizzo email, telefono, numero di stanza, eccetera.
LDAP definisce operazioni per interrogare e aggiornare la directory,
aggiungere, modificare e rimuovere elementi; ma principalmente è usato
per cercare, nell'ambito di una porzione dell'albero, le informazioni
associate agli elementi il cui DN verifica criteri specificati da un
filtro di ricerca. Inoltre, LDAP supporta un meccanismo che permette ai
clients di autenticarsi, facendo eventualmente uso anche di un canale
di comunicazione sicuro.
Nel 2010 è stata sperimentata l'installazione e la configurazione di un server LDAP, allo scopo di mantenere le credenziali di chi frequenta il laboratorio del corso, e da usare per scopi diversi. Di seguito, alcuni links a siti che mi hanno aiutato:
A volte le informazioni di autenticazione memorizzate da un server LDAP sono interrogate non in modo diretto, ma per il tramite di un protocollo (RADIUS) più direttamente legato al processo di autenticazione, e implementato da tutti i dispositivi (ad es. un access point WiFi) che lo richiedono. In tal caso, il server RADIUS può essere configurato per interrogare a sua volta un server LDAP.

Infine, vale la pena citare la possibilità di creare tunnel sicuri mediante SSH.
IPsec è l'abbreviazione di IP Security ed è uno standard (RFC 4301) per realizzare connessioni basate su reti IP sicure. La sicurezza viene raggiunta attraverso la cifratura e l'autenticazione dei pacchetti IP, e quindi a livello di rete, rendendo la trasformazione trasparente alle applicazioni, che non devono essere modificate. IPsec definisce
Mediante IPSec/ESP si può realizzare una Virtual Private Network (VPN), configurando opportunamente le interfacce esterne dei router che interconnettono, le sedi distaccate di una stessa organizzazione. In tal modo, è come se le sedi facessero parte di una medesima LAN, in quanto i pacchetti IP scambiati sono incapsulati (realizzando dei tunnel) in nuovi pacchetti IP, che ne permettono l'instradamento geografico e la confidenzialità.

Sia AH che ESP possono operare in queste due modalità, che differiscono per il fatto che mentre in transport mode le funzioni crittografiche sono realizzate direttamente dai singoli host in comunicazione, con il tunnel mode queste sono realizzate dai router di accesso per conto di tutti gli host della LAN. Illustriamo ora come operano i due metodi AH e ESP facendo riferimento ad pacchetto IP originario rappresentato nella forma seguente
In questo caso la PDU di trasporto viaggia inalterata, mentre viene aggiunta una intestazione al livello di rete, in cui si inserisce un HMAC calcolato (in base ad un segreto condiviso) su tutto il pacchetto, meno quei campi che possono essere modificati in transito, come ad esempio il TTL IP. Nel caso del transport mode, l'intestazione AH è inframmezzata tra quella TCP e quella IP, lasciando quest'ultima inalterata, come raffigurato dallo schema seguente, in cui la zona celeste rappresenta i dati che sono autenticati:
| Header IP | Header AH | Header TCP | Dati | AH in transport mode |
| dati autenticati | ||||
La modalità tunnel invece inserisce l'intestazione AH esternamente a quella IP, ed il risultato è incapsulato dentro un nuovo pacchetto IP, in modo da poterlo instradare sulla Internet pubblica
| Header IP esterno | Header AH | Header IP | Header TCP | Dati |
AH in tunnel mode |
| dati autenticati | |||||
Dato che gli indirizzi IP e le porte di trasporto entrano a far parte di ciò che viene autenticato, se queste quantità sono modificate da un dispositivo NAT, il processo di autenticazione fallisce, e devono essere intrapresi degli accorgimenti particolari, descritti nella RFC 3947.
In questo caso non è distinguibile un nuovo header ESP, in quanto questa tecnica incapsula l'intero pacchetto originario, ad esclusione dell'header IP nel caso transport mode:
| Header IP | Header ESP | Header TCP | Dati | Trailer ESP | ESP auth | ESP in transport mode |
| dati autenticati | ||||||
Come prima, la zona celeste identifica i contenuti autenticati mediante l'apposizione di un HMAC, mentre quella verde delimita i contenuti che vengono crittografati e per i quali è garantita l'integrità. Nel caso del modo tunnel, viene invece crittografata anche l'intestazione IP, ed una nuova viene posta in testa.
| Header IP | Header ESP | Header IP interno | Header TCP | Dati | Trailer ESP | ESP auth | ESP in tunnel mode |
| dati autenticati | |||||||
Il Transport Layer Security è definito nella RFC 5246, rappresenta la formalizzazione da parte IETF del Secure Socket Layer definito da Netscape, ed ha lo scopo di realizzare comunicazioni sicure su Internet per applicazioni come il browsing Web e l'email, in modo da evitare intercettazioni (eavesdropping), sabotaggi (tampering) e falsificazioni (forgery). Tra SSL e TLS sussistono differenze minime.
L'uso di una connessione resa sicura via SSL/TLS può avvenire su
iniziativa del processo applicativo soprastante, come nel caso di STARTTLS,
oppure può avvenire fin dall'inizio della connessione, riservando una
porta diversa da quella standard (ad esempio, l'HTTP sicuro prende il
nome di HTTPS, e
risponde sulla porta 443 anziché la 80).
Un ulteriore uso di TLS è quello di creare dei tunnel sicuri nella infrastruttura Internet pubblica, realizzando delle Virtual Private Network (VPN), come ad esempio avviene con OpenVPN, senza necessità di intervenire sui singoli dispositivi di rete, come invece avviene nel caso di IPSec.
 Il
Record Protocol di TLS offre i servizi di
sicurezza allo strato applicativo, così come a tre protocolli ausiliari (Handshake, Change Chiper
e Alert) necessari alla gestione della
connessioni che fanno uso di TLS.
Il
Record Protocol di TLS offre i servizi di
sicurezza allo strato applicativo, così come a tre protocolli ausiliari (Handshake, Change Chiper
e Alert) necessari alla gestione della
connessioni che fanno uso di TLS.
Il Record protocol offre confidenzialità, autenticazione e (opzionalmente) compressione, in accordo alle modalità operative mostrate nella figura che segue

Il MAC è generato mediante funzione hash SHA-1 oppure MD5, usate assieme ad un segreto MAC, in modo del tutto simile all'HMAC. La crittatura può usare uno tra gli algoritmi IDEA, RC2, DES, 3DES, RC4, ed opera anche sul MAC già calcolato.
 L'aggiunta
finale
di una intestazione SSL dà luogo al formato mostrato al lato. Il
campo Content Type (8 bits) codifica il protocollo di strato superiore,
ed i numeri di versione permettono di tener traccia delle evoluzioni
delle specifiche. Infine, viene inserito un campo che descrive la
dimensione del pacchetto risultante.
L'aggiunta
finale
di una intestazione SSL dà luogo al formato mostrato al lato. Il
campo Content Type (8 bits) codifica il protocollo di strato superiore,
ed i numeri di versione permettono di tener traccia delle evoluzioni
delle specifiche. Infine, viene inserito un campo che descrive la
dimensione del pacchetto risultante.
Il Record Protocol, oltre a incapsulare informazioni provenienti dallo strato applicativo, può invece trasportare le informazioni prodotte da uno dei tre protocolli specifici del TLS (Change Cipher, Handshake e Alert), identificati dal contenuto del campo Content type, e corrispondenti ciascuno al formato mostrato nelle figure che seguono:

L'handshake protocol si occupa di creare una sessione TLS, ossia definire il valore di un insieme di parametri crittografici, da utilizzare nell'ambito di una o più connessioni. Tra questi, menzioniamo
Lo stato di una specifica connessione è invece identificato da
L'handshake protocol viene eseguito all'inizio di una sessione TLS, e permette a client e server di autenticarsi vicendevolmente, di negoziare un algoritmo di crittografia, un algoritmo per il calcolo del MAC, e le chiavi crittografiche da usare. Tutti i messaggi scambiati mediante l'handshake protocol, precedenti alla trasmissione di qualsiasi altro dato, hanno il formato mostrato sopra, con i campi:
Nel suo funzionamento, l'handshake protocol può pensarsi come suddiviso in una successione di 4 fasi.

La prima è iniziata dal client, che invia il messaggio client_hello, con associati i parametri mostrati in figura. La risposta server_hello costituisce la negoziazione dei parametri, e contiene un numero di sessione valido, e la scelta della cipher suite. Il primo elemento di quest'ultima codifica il metodo di scambio chiave, tra cui
La cipher suite prosegue quindi con lo specificare, tra l'altro, l'algoritmo crittografico simmetrico scelto, l'algoritmo hash per il calcolo del MAC, e la sua dimensione.
Inizia quindi una seconda fase, in cui (se necessario) il server invia il proprio certificato X.509 e la propria chiave (inviando i parametri di Diffie-Hellman, oppure adottando RSA). Nel calcolo dell'hash necessario a generare la firma di autenticazione, oltre ai parametri del server, sono utilizzati anche i nonce di client e server, inviati con i messaggi di hello, a protezione di attacchi replay.
Nella terza fase,
il client può verificare l'autenticità del certificato ricevuto,
utilizzando la chiave pubblica della CA che ha firmato il certificato
del server; se questo ha buon esito, procede con l'inviare un PreMasterSecret
crittografato con la chiave pubblica del server, oppure i parametri di
Diffie-Hellman. La chiave segreta vera e propria verrà poi calcolata da
entrambe le parti, a partire dalla versione Pre-,
e da entrambi i nonce.
Infine, nella quarta fase il messaggio change_chiper-spec segna l'inizio della crittografia di ciò che segue.
Anziché inframmezzare le funzioni di sicurezza tra due strati funzionali preesistenti, a volte si preferisce isolare queste primitive all'interno di librerie richiamabili dai programmi applicativi che le linkano, e contenenti entry points di subroutines che implementano i diversi servizi crittografici di cui l'applicazione può avere bisogno.
Il Simple Authentication and Security Layer (SASL) è definito dalla RFC 4422 come una infrastruttura capace di offrire alle applicazioni basate su TCP servizi di autenticazione e di sicurezza dati, e fornisce uno strato di astrazione che, per mezzo di una interfaccia strutturata, permette a diversi protocolli di far uso di meccanismi crittografici sviluppati indipendentemente.

Presso lo IANA è pubblicato un
registro
che elenca i protocolli applicativi che prevedono modalità di
interazione con SASL, e fornisce i riferimenti alle specifiche che
definiscono questi aspetti. Tra i protocolli che possono utilizzare
SASL, troviamo IMAP,
LDAP,
POP,
SMTP,
FTP, NFS, NNTP,
e XMPP.
| SMTP LDAP XMPP Other protocols ... \ | | / \ | | / SASL abstraction layer / | | \ / | | \ EXTERNAL GSSAPI PLAIN Other mechanisms ... |
I meccanismi supportati sono anch'essi registrati presso lo IANA, e tra questi troviamo
| GSSAPI - Generic Security Service Application Program Interface, Kerberos | RFC4752 |
| EXTERNAL - l'autenticazione è ottenuta con altri meccanismi (es. TLS) | RFC4422 |
| ANONYMOUS - accesso non autenticato, come ospite | RFC4505 |
| OTP - One Time Password | RFC2444 |
| PLAIN - usa una password di tipo plaintext | RFC4616 |
| DIGEST-MD5 - Integrazione dell'HTTP Digest Access in SASL | RFC2831 |
| CRAM-MD5 - Challenge-Response Authentication Mechanism basato su HMAC MD5 | RFC2195, draft |
Esistono implementazioni libere di librerie che offrono il supporto a SASL, come ad esempio quelle di Cyrus e GNU. Altre fonti di informazioni, si trovano presso l'autore delle RFC, e SASL e Sendmail.
Questo acronimo sta per Challenge-Response
Authentication Mechanism ed è definito dalla RFC
2195. Si basa sull'algoritmo HMAC-MD5
che calcola un Message Authentication Code (MAC) utilizzando una funzione crittografica hash
in combinazione con una chiave
segreta. La funzione Hash utilizzata è il Message-Digest
algorithm 5 (MD5),
standardizzato nella RFC 1321, e qui utilizzato nella variante keyed
illustrata in RFC 2104,
e che usa una password nota sia al client che al server come chiave per
generare un digest di 16 bytes, rappresentato
da 32 caratteri esadecimali.
Nel CRAM-MD5 il server invia al client, con una codifica di trasferimento base64, una sfida (challenge) generata ex-novo per l'occasione, e che tipicamente consiste in una stringa di tipo msg-id, come ad esempio <1896.697170952@postoffice.reston.mci.net>, e che contiene un timestamp sempre diverso.

Il client, dopo aver decodificato lo challenge dalla sua rappresentazione base64, ne calcola un digest HMAC applicando l'algoritmo hash MD5, ossia usa lo challenge come messaggio, ed una password segreta associata all'utente che intende autenticarsi, e nota anche al server, come chiave. I 16 bytes del digest vengono quindi rappresentati come 32 caratteri esadecimali, e dato che ogni diverso utente possiede una diversa password, il nome dell'utente che desidera autenticarsi viene prefisso al digest, separato da questo da uno spazio. Quest'ultimo risultato viene quindi trasformato base64, e finalmente inviato come response al server, il quale dopo aver recuperato dalla propria memoria la password associata all'utente, calcola anch'esso il digest, e lo confronta con quello contenuto nella risposta ricevuta. Un esempio di scambio reale, può essere trovato nella sezione relativa alle esercitazioni.
L'utilizzo di MD5-keyed per il calcolo del digest permette di non memorizzare la password in chiaro presso il server, ma solo una sua versione già crittografata, che compare come calcolo intermedio in MD5, e indicata come contesto. Il protocollo di sfida difende da attacchi di tipo replay, dato che anche se intercettato, il messaggio di risposta alla sfida non può essere riusato successivamente, perché nel frattempo è cambiata la parola di sfida. Dato che ogni sfida è diversa, questa viene a volte indicata con il termine di nonce, ossia di nome utilizzato una sola volta.
La Pretty Good Privacy è una iniziativa imputabile ad una unica persona, Phil Zimmermann, e deve molta della sua popolarità all'approccio del tutto aperto con cui è stato impostato il lavoro, che può essere definito come l'applicazione di crittografia più diffusa al mondo, e che è formalizzato come standard IETF nella RFC 4880. Nella figura che segue riportiamo uno schema di firma e crittografia di un messaggio, ad esempio di una email.

Osserviamo che innanzitutto viene calcolato un hash del messaggio, il quale viene crittografato (asimmetricamente) con la chiave privata del mittente, ed il risultato (ossia la firma del messaggio) viene concatenato al messaggio stesso. La chiave privata usata, è stata prelevata (selezionandola in base alla sua identità IDA) da un keyring di chiavi private, dov'era conservata in forma crittografata (PGP consente agli individui, di possedere più coppie di chiavi pubblica/privata). Questa chiave privata viene decrittata usando una passphrase, che viene chiesta ogni volta all'utente, mentre la sua identità è anch'essa concatenata a messaggio + firma. Il risultato complessivo viene crittografato usando un algoritmo simmetrico, e che opera in base ad una chiave di sessione prodotta da un generatore di numeri casuali (RNG), e che pure viene trasmessa assieme al messaggio, dopo averla crittografata (asimmetricamente) usando una delle chiavi pubbliche del destinatario, la cui identità (IDB) viene pure concatenata al messaggio uscente. Con l'ausilio della figura seguente, descriviamo ora il processo di ricezione.

L'identità della chiave privata del ricevente viene usata per
individuarne in forma crittografata all'interno suo del keyring
privato. La passphrase
necessaria a decrittare questa sua chiave privata viene chiesta
all'utente, dopodiché il ricevente è in grado di decrittare
(asimmetricamente) la chiave di sessione, grazie alla quale decrittare
il messaggio ricevuto. Quindi, l'identificativo della chiave privata
del mittente permette di recuperare, dal keyring
pubblico, la chiave pubblica del mittente stesso, e con questa,
decrittare l'hash del messaggio, e verificare così la firma digitale
apposta appunto dal mittente.
Il PGP attribuisce un grado di fiducia alle chiavi pubbliche altrui in accordo alle relazioni che definiscono un Web of Trust, spesso coadiuvato dalla esistenza di alcuni keyserver che mantengo un deposito di chiavi pubbliche firmate da altri utenti. Per il PGP esistono applicazioni sia commerciali, che libere, descritte nella apposita sezione delle esercitazioni.
Lo standard S/MIME non offre nulla di più o di meglio del PGP, ossia dei servizi crittografici di sicurezza per le applicazioni di messaggistica elettronica: autenticazione, integrità e non-repudiabilità, mediante firme digitali, e confidenzialità usando la crittografia. E' stato prima sviluppato presso RSA come PKCS #7, e quindi il controllo della definizione dello standard è passato a IETF, che attualmente lo supporta come Cryptographic Message Syntax definito nella RFC 5652, nell'ambito del WG S/MIME di IETF. I messaggi elaborati in accordo a tali specifiche, sono identificati da un header MIME-Type: application/pkcs7-mime (o "enveloped-data"). La differenza più sostanziale tra PGP e S/MIME risiede nel formato dei certificati e nella loro codifica, che rende i due sistemi tra loro incompatibili. S/MIME infatti esige che i suoi utilizzatori usino certificati X.509, rilasciati da una qualche CA, di cui il client possieda (in modo sicuro) la rispettiva chiave pubblica.
ASN.1 non è la prima, ma neanche l'ultima sintassi incontrata in questo testo: lo scopo è sempre quello di rappresentare tipi di dato strutturati e di trasmetterne il valore in modo indipendente dalla architettura hardware, dal protocollo e dal linguaggio di programmazione adottato. È uno standard congiunto tra ISO, IEC e ITU, la cui prima definizione risale al 1984, mentre l'ultima revisione del 2008 è formalizzata nelle serie ITU-T X.680 e X.690, che dettagliano rispettivamente la notazione astratta con cui sono descritte le informazioni, e la sintassi di trasferiento (o rappresentazione concreta) con cui queste sono effettivamente codificate e trasmesse.
Per quanto riguarda la notazione astratta,
procediamo con un esempio, tratto da wikipedia.
Supponiamo di voler definire il protocollo Foo,
in modo che il suo funzionamento si basi sullo scambio di messaggi di
richiesta e risposta che possiamo descrivere in notazione ASN.1 in
questo modo:
| FooProtocol DEFINITIONS ::= BEGIN FooQuestion ::= SEQUENCE { trackingNumber INTEGER, question IA5String } FooAnswer ::= SEQUENCE { questionNumber INTEGER, answer BOOLEAN } END |
Come questo scambio possa avvenire non è descritto da ASN.1, ma spetta alla descrizione testuale del protocollo. Come osserviamo, viene creato il contesto delle definizioni dei tipi di dato (FooQuestion e FooAnswer) che corrispondono al tipo elementare SEQUENCE, (altri tipi elementari sono ad es. BOOLEAN, INTEGER, REAL, BIT STRING, CHARACTER, STRING, TIME, ...), composta in entrambi i casi da due elementi di diverso tipo. Ad un certo punto, l'applicazione genera un messaggio (o PDU) da inviare, espresso come
| myQuestion FooQuestion ::= { trackingNumber 5, question "Anybody there?" } |
che per essere effettivamente trasmesso, deve dare luogo ad una sequenza di bit: ANS.1 definisce diverse procedure per realizzare questa trasformazione, chiamate
La definizione testuale del protocollo Foo deve dichiarare esplicitamente quali regole utilizzare per co-decodificare i propri messaggi. Le regole più semplici sono indicate come Distinguished Encoding Rules (DER), che adottano una codifica basata su triplette type-length-value, e che per l'esempio di messaggio su indicato, producono
| 30 -- tag indicating SEQUENCE 13 -- length in octets 02 -- tag indicating INTEGER 01 -- length in octets 05 -- value 16 -- tag indicating IA5String 0e -- length in octets 41 6e 79 62 6f 64 79 20 74 68 65 72 65 3f -- value ("Anybody there?" in ASCII) |
in modo che il risultato finale sarà
| 30 13 02 01 05 16 0e 41 6e 79 62 6f 64 79 20 74 68 65 72 65 3f |
e l'ambito di competenza di ASN.1 finisce qui. Il bitstream risultante potrà essere trasmesso nel modo preferito (ad es. TCP), e l'entità ricevente dovrà essere in grado, applicando le DER, di ri-generare il messaggio trasmesso. L'elenco completo delle encoding rules risulta:
Buona parte delle illustrazioni utilizzate in questa sezione sono tratte (in modo non autorizzato) dal testo "Network Security Essentials: Applications and Standards, 3/E" di William Stallings, Ed. Prentice Hall, di cui consiglio a tutti la lettura, in virtù della sua estrema chiarezza. Tuttavia, solo ora mi avvedo che tali figure (ed altro interessantissimo materiale) sono comunque già disponibili in rete, in formato pdf, presso il sito mantenuto dall'autore. Inoltre, mi sento di segnalare i seguenti riferimenti

Dal TCP al VoIP, dal DNS all'Email alla crittografia, tutto ciò che accade
dietro le quinte di Internet, completo di cattura del traffico.
Scopri
come effettuare il download,
ricevere gli aggiornamenti,
e contribuire!
