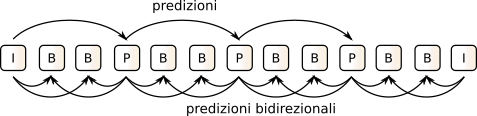10.3 Codifica video
In accordo al metodo di realizzazione dei segnali video analogici, in cui i singoli quadri sono codificati indipendentemente gli uni dagli altri, la codifica video digitale può essere realizzata semplicemente applicando tecniche di codifica di immagine (come
jpeg) ad ognuno dei quadri che costituiscono la sequenza video: questo tipo di approccio prende il nome di
moving jpeg o
mjpeg.
D’altra parte, i quadri relativi ad istanti temporali vicini sono spesso molto simili tra loro, anche se quanto siano simili, e per quanto tempo, dipende dal tipo di filmato. La presenza di
memoria nella sorgente determina quindi la possibilità di ridurre il tasso informativo prodotto dalla codifica ricorrendo a tecniche predittive, tentando quindi di
stimare il movimento presente in quadri contigui, e trasmettere solo l’informazione necessaria a
compensare l’errore di predizione. Nella parte destra di fig.
10.36 è mostrata l’immagine differenza
ΔY tra la componente di luminanza di due quadri consecutivi, consentendo di apprezzarne la relativa semplicità.
Considerando poi che alcune regioni si sono mosse più di altre, il quadro da codificare è scomposto in sottoimmagini, per ognuna delle quali si ha un diverso spostamento, e viene calcolata una specifica differenza rispetto alla sotto-immagine precedente (e spostata); questa tecnica prende il nome di compensazione del movimento.
Come abbiamo fatto notare al §
9.2.2, le tecniche di codifica predittiva sono particolarmente sensibili agli errori di trasmissione, che possono causare una perdita di sincronismo tra i predittori di trasmissione e ricezione, e quindi l’impossibilità di ricostruire la restante parte di segnale. Per questo nella codifica video sono presenti dei quadri
di riferimento in corrispondenza biunivoca con un unico quadro di partenza, detti
intracoded frames o
I-frames, che permettono al ricevitore di ri-partire da una condizione nota. Tra due quadri
I sono poi presenti un certo numero di quadri
P (
predicted) come in fig.
10.37-a, oltre che quadri
B (
bidirectional) come in fig.
10.37-b, e che corrispondono rispettivamente alla codifica della compensazione del movimento calcolato a partire da un unico quadro precedente, o da una coppia di quadri passato e futuro.
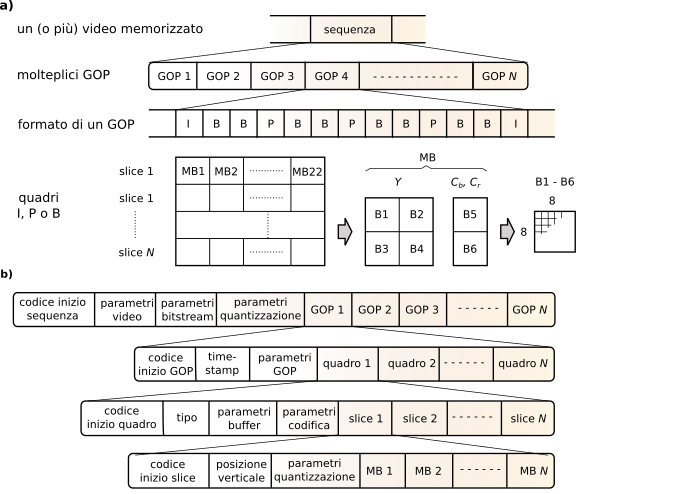
I quadri
I sono codificati mediante l’algoritmo
jpeg, usando lo stesso coefficiente di quantizzazione per tutti i pixel delle DCT, conseguendo un rapporto di compressione relativamente basso, e sono inseriti a cadenza fissa con un periodo
N tipicamente compreso tra 3 e 12: la sequenza di quadri compresi tra due quadri
I è detta
group of pictures o
gop. Come mostrato in figura
10.37, la codifica di quadri
P può dipendere dal quadro
I immediatamente precedente, o dalla ricostruzione di un precedente quadro
P, ottenendo un fattore di compressione maggiore che per i quadri
I; la distanza temporale tra
P e l’originale
I è detta
intervallo di predizione, indicato con
M.
Per realizzare la compensazione del movimento, ogni regione del nuovo quadro è confrontata con regioni limitrofe del quadro precedente, riducendo così la complessità di ricerca. Nel caso dei quadri B la ricerca delle regioni simili è invece svolta rispetto ai quadri I (o P) situati sia nel passato che al futuro, migliorando la precisione della stima di movimento, e conseguendo rapporti di compressione ancora maggiori, a patto di subire un aumento del ritardo di codifica, legato al dover attendere un quadro futuro.
Allo scopo di ridurre il ritardo di decodifica la sequenza di quadri viene trasmessa con un ordine diverso da quello dei quadri originali, consentendo ai quadri
B di essere riprodotti non appena ricevuti, e non dopo la ricezione del quadro
futuro da cui dipendono. Pertanto, se la sequenza originale è ad esempio
essa verrà trasmessa nell’ordine
Stima di movimento
e compensazione
Specifichiamo innanzitutto cosa intendere con il termine
regione prima usato per definire il dominio dell’operazione di confronto necessaria alla stima di movimento. Come mostrato in fig.
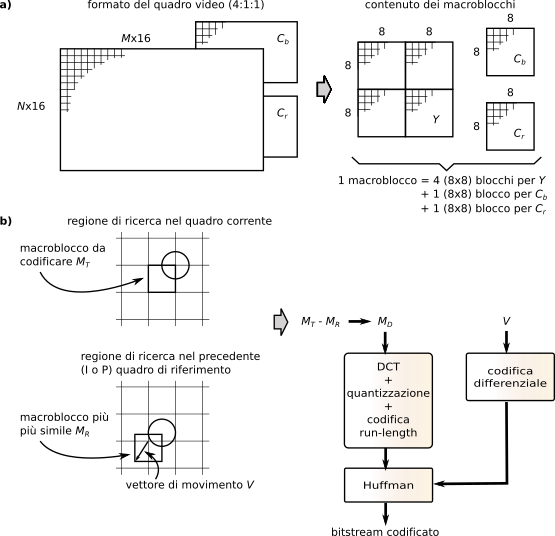
10.38a, considerando una suddivisione in componenti
Y Cb Cr ed un sottocampionamento 4:1:1, il quadro originale è suddiviso in
N righe e
M colonne di
macroblocchi di 16x16 pixel, ed ogni macroblocco è rappresentato da sei blocchi 8x8 pixel, di cui quattro blocchi per la luminanza, più due blocchi per le componenti di crominanza; ogni blocco 8x8 corrisponde quindi ad un equivalente numero di coefficienti
dct, ed è individuato all’interno del quadro, in base al suo indirizzo di riga e colonna.
Nella codifica dei quadri
P, ogni macroblocco
MT del quadro corrente (
target) è confrontato pixel per pixel con il corrispondente macroblocco
MR del quadro
di riferimento, e nel caso sia riscontrata una sufficiente similitudine complessiva, viene trasmesso solo l’indirizzo del blocco. Altrimenti, il confronto viene ripetuto per tutti i possibili spostamenti del macroblocco target nell’ambito dei macroblocchi contigui, e qualora sia individuata una buona corrispondenza, il macroblocco viene codificato dal
vettore di movimento V e dall’
errore di predizione MD. Con riferimento alla fig.
10.38-b in cui l’immagine è simboleggiata da un cerchio,
V rappresenta lo spostamento da applicare a
MT per portarlo a coincidere al meglio con il quadro precedente, ed è codificato come una coppia
(x, y) corrispondente ad una
risoluzione di un pixel. Al contrario
MD è composto dalle tre matrici (
Y Cb Cr) dei valori differenza tra quelli di
MT spostato di
V, ed
MR. I valori di
V e di
MD relativi ai diversi macroblocchi di un quadro seguono poi due diversi percorsi di codifica, come specificato appresso.
Nel caso in cui la regione di ricerca sia estesa, i valori V possono risultare relativamente grandi; d’altra parte è probabile che macroblocchi vicini esibiscano vettori di spostamento molto simili tra loro. Per questi motivi, la sequenza dei V calcolati per macroblocchi contigui viene prima sottoposta ad un processo di codifica differenziale, e quindi i valori di differenza sono rappresentati da codeword a lunghezza variabile di Huffman. D’altra parte, le tre matrici differenza sono invece sottoposte alla stessa sequenza di operazioni dei quadri I (dct, quantizzazione, codifica entropica), conseguendo però un fattore di compressione più elevato, essendo il macroblocco differenza con valori quasi tutti molto piccoli.
Nel caso in cui la stima di movimento fallisca (o a causa di una estensione di ricerca insufficiente, oppure per un reale cambio di scena), il macroblocco è codificato in modo indipendente come avviene per i quadri I.
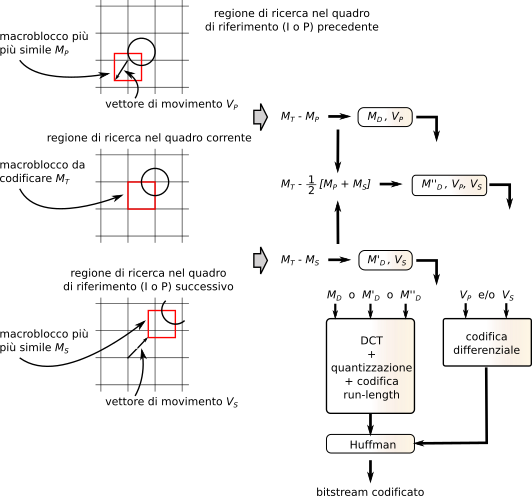
I macroblocchi dei quadri B (vedi fig.
10.39) sono invece confrontati sia con il
precedente quadro
MP che con il
successivo MS, ottenendo due possibili insiemi di matrici differenza
MD e
M’D ed associati vettori
VP e
VS; viene inoltre calcolato un ulteriore insieme
M’’D come differenza tra
MR e la media dei macroblocchi (spostati) di riferimento, e determinato infine quale delle tre possibilità fornisca il minimo errore di predizione. In base a questa scelta, si individua quale macroblocco differenza codificare, assieme ai rispettivi vettori di movimento. Nel caso prevalga la predizione basata sulla media tra macroblocchi di riferimento, il vettore di movimento complessivo può determinare un potere di risoluzione a livello di
sub-pixel.
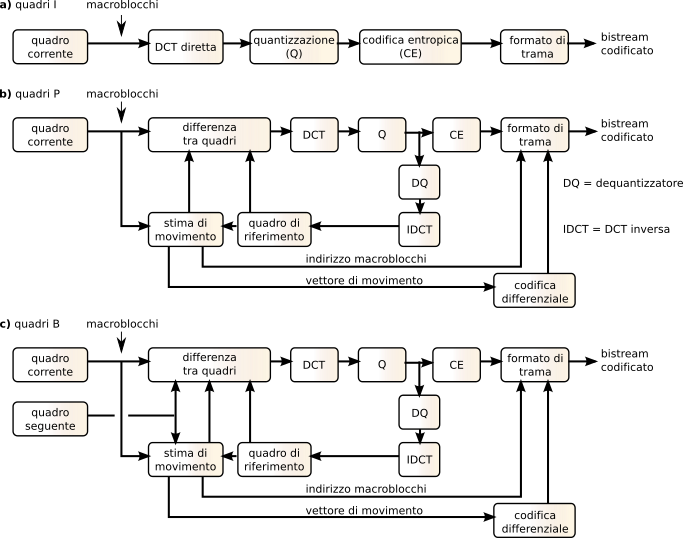
La fig.
10.40 riassume la sequenza di operazioni applicate alle tre tipologie di quadro
I,
P e
B. Mentre nel primo caso queste seguono lo schema previsto dalla codifica
jpeg, i quadri
P meritano qualche commento: allo scopo di alimentare correttamente il componente di stima di movimento, il codificatore mantiene memoria del quadro di riferimento, all’inizio posto pari ad un quadro
I, e quindi sostituito da una copia dell’ultimo quadro
P, ottenuto risommando il quadro differenza al precedente quadro di riferimento. Lo stesso schema di calcolo è svolto nel caso di quadri
B, tenendo ora conto anche del quadro successivo.
Rimarchiamo ora il fatto che, in funzione dell’esito del processo di stima di movimento, esistono tre diverse possibilità di rappresentazione per ogni macroblocco dei quadri P e B:
- se non vi è movimento, viene trasmessa solo la sua posizione;
- se vi è movimento e si trova un riferimento abbastanza simile, sono trasmessi il vettore di movimento e le matrici differenza;
- se non si è trovato un riferimento abbastanza simile, viene effettuata una codifica inter come per il caso dei quadri I.
Ciò determina l’esigenza di disporre di un formato di trama di dimensione (e velocità) variabile, come realizzato nell’esempio mostrato in fig.
10.41, in cui ad ogni macroblocco è associato un tipo (
I,
P o
B), il suo indirizzo nell’ambito del quadro, il coefficiente di quantizzazione relativo ai termini della
dct, ed il vettore di movimento (se presente). Quindi si dichiara l’identità dei blocchi presenti (che potrebbero essere assenti in caso di immagini statiche), e per questi viene infine prodotta la sequenza di informazioni previste dalla codifica
jpeg.
10.3.1 Standard video
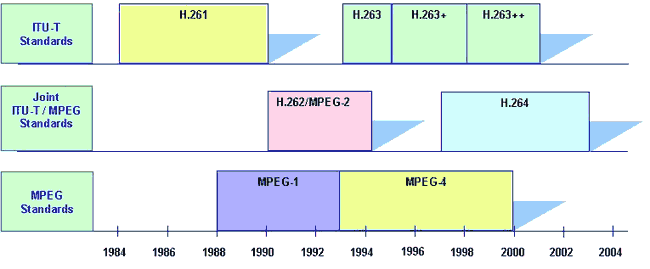
Come per l’audio, anche il numero dei codec video è elevato, ed è istruttivo prenderli in esame secondo l’ordine cronologico con cui si sono sviluppati, dato che in pratica ognuno prende il precedente come base di partenza.
E’ lo standard di codifica video definito da itu-t a fine anni ’80 per le applicazioni di videotelefonia su isdn, ed anche se oggi tecnicamente superato, resta comunque un valido sistema di riferimento che consente la retro-compatibilità tra apparati. Il suo principale limite è il vincolo di dover produrre una velocità ridotta e comunque quantizzata a multipli di 64 kbps.
| Formato |
Y |
Cb, Cr |
| cif |
352 x 288 |
176 x 144 |
| qcif |
176 x 144 |
88 x 72 |
La scelta del formato di immagine è limitata a quanto mostrato in tabella, mentre la scansione è non interallacciata e la velocità di rinfresco di 30 quadri/secondo per
cif oppure 15 o 7.5 per
qcif. Sono usati solo quadri di tipo
I e
P, con un
gop di 4 (ossia 3
P ogni
I), e sono usate le procedure descritte alla sezione precedente per rappresentare ogni quadro nei termini di macroblocchi composti da 16x16 pixel (4 blocchi di 8x8) di luminanza e 2 blocchi 8x8 per ogni componente di colore
Cb,
Cr.
Ogni macroblocco segue la tipica formattazione mostrata in fig.
10.42-a; tre file di 11 macroblocchi sono poi raggruppati in una nuova struttura sintattica detta
gob (
Group of (macro)Blocks), che si articola in un contenuto (fig.
10.42-b) ed una intestazione (fig.
10.42-c), in cui troviamo un
codice di inizio scelto in modo da non poter essere presente nella sequenza di codici di Huffman che seguono, e che permette la risincronizzazione nel caso di
gob mancanti (vedi appresso), in modo da poter tornare a riprodurre un quadro in corrispondenza del primo
gob disponibile.
L’intero quadro è quindi realizzato con il formato di fig.
10.42-d), in cui compare un
codice di inizio quadro, un
riferimento temporale necessario alla sincronizzazione con la traccia audio, e l’indicazione del tipo di quadro (
I o
P); a cui segue la sequenza dei
gob, in numero di 3 oppure 12 a seconda se il quadro rappresenti una immagine
qcif o
cif, in modo da permettere l’interoperabilità tra formati come mostrato in fig.
10.42-e.
Dato che la codifica video produce una velocità di trasmissione variabile
, questa può eccedere la capacità del canale a disposizione, ed un modo
drastico per risolvere il problema è di scartare alcuni
gob. Il campo
Group number dell’intestazione dei
gob permette quindi di collocare il nuovo
gob anche in mancanza dei suoi predecessori.
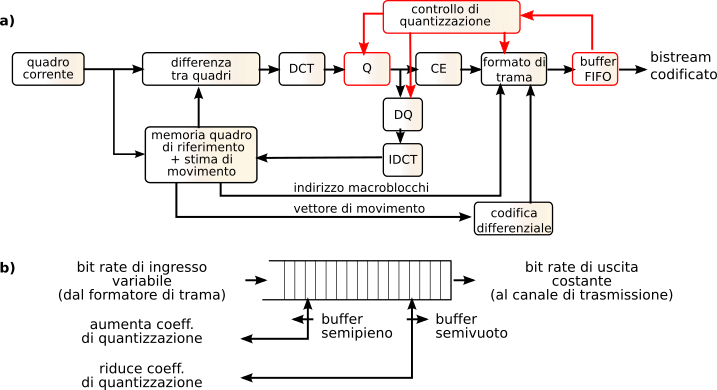
Un approccio più articolato è quello mostrato dalla figura
10.43-a, che ripercorre le tappe già discusse e relative al calcolo del vettore di movimento ed alla codifica degli errori di predizione, ma pone in evidenza il campo di intervento di un componente di
controllo quantizzazione, che variando l’entità dei coefficienti di quantizzazione della
dct, permette di ridurre e/o aumentare la velocità di codifica complessiva. In particolare, il controllo di quantizzazione opera in base allo stato di riempimento del
buffer fifo mostrato in fig.
10.43-b, alimentato dal risultato del processo di codifica e formattazione video, e da cui sono prelevati i dati da inviare a velocità costante.
Nel caso in cui la velocità media di codifica ecceda quella disponibile, l’aumento della occupazione del buffer determina l’aumento del coefficiente di quantizzazione, e quindi una riduzione della qualità ma anche della velocità media di codifica; ovviamente, anche l’inverso è possibile, ossia un miglioramento di qualità mediante riduzione del coefficiente di quantizzazione, nel caso in cui la scena sia statica, e la codifica produca un basso bit rate che consente alla
fifo di svuotarsi.
Nel caso di un aumento improvviso di velocità, come anticipato si possono addirittura
scartare alcuni
gob, mentre per i successivi si adottano coefficienti di quantizzazione ridotti, comunicati anche al lato ricevente per mezzo dell’apposito campo della intestazione
gob, come mostrato in fig.
10.42-c.
Anche questo definito da
itu-t a partire dal 1995, nasce per risolvere i problemi di bassa qualità dell’
h.261 a velocità molto ridotte, come quelle offerte dai collegamenti modem
dial-up precedenti all’introduzione dell’
adsl, ovvero per migliorare la gestione delle possibili condizioni di errore sia sul canale
dial-up che
wireless. Le specifiche originarie si sono in seguito arricchite di estensioni, favorendo l’adozione del codec da parte di altre applicazioni (inclusi i filmati di
youtube), ed aggiungendo il supporto oltre che ai formati nativi
cif e
qcif, anche a
s-qcif,
4cif,
16cif,
sif e 4
sif. A partire dal 2003 si è formato un gruppo di lavoro congiunto tra
itu-t vceg (
Video Coding Expert Group) e
iso/iec mpeg (
Moving Pictures Experts Group), che segue la definizione del suo successore, l’
h.264 detto anche
avc (Advanced Video Coding) o MPEG-4
part 10, determinando l’arresto dello sviluppo di
h.263, che resta comunque (assieme all’
h.261) supportato da un gran numero di applicazioni multimediali. Sebbene la struttura generale del codificatore e del bitstream ricalchi quella vista per l’
h.261, sono state introdotte alcune novità significative, che tentiamo di elencare appresso.
In h.263 sono usati, oltre ai quadri di tipo I e P, anche quelli bidirezionali B, consentendo di ottenere fattori di compressione maggiori, a parità di qualità percepita.
I gob sono ridefiniti come singole strisce di macroblocchi, quindi ad esempio per i formati cif e qcif un gob è ora formato da 11 macroblocchi in fila, anziché 33 come avveniva per l’h.261.
Vettori di movimento estesi
La stima di movimento dell’h.261 si arresta in corrispondenza dei bordi del quadro, per cui anche se un oggetto è solo parzialmente uscito di scena, il macroblocco corrispondente viene codificato in modalità intra. Al contrario h.263 permette di estendere la ricerca anche a vettori di spostamento che cadono al di fuori del quadro, alla ricerca di una corrispondenza parziale, consentendo al contempo maggiore efficienza e minor distorsione.
Anziché determinare il vettore di movimento in base al confronto di un intero macroblocco, i 4 blocchi 8x8 che lo costituiscono sono confrontati in modo indipendente con il quadro di riferimento, permettendo una migliore compensazione del movimento anche per l’immagine di oggetti che non solo traslano, ma si deformano. In definitiva, sono prodotti 4 diversi vettori di movimento per ogni macroblocco.
La presenza di un errore nella ricezione di un gob, oltre ad impedire la corretta riproduzione dello stesso, ostacola la riproduzione anche dei quadri successivi che dipendono dai pixel presenti nel gob, e peggio ancora l’errore finisce per estendersi anche ad altri gob, in virtù degli effetti dell’errore sulla ricostruzione dei macroblocchi predetti in presenza di movimento.
Per ridurre l’estensione temporale dell’effetto dell’errore, e non dover attendere fino alla ricezione del successivo quadro I, si può usare il canale di ritorno presente nei collegamenti punto-punto, consentendo al decodificatore di inviare dei nack che notificano al mittente la coppia (quadro, gob) per la quale si è rilevato un errore. Il codificatore è quindi in grado di valutare esso stesso le conseguenze sui quadri successivi, e può provvedere a fornire una codifica intra per tutti i blocchi che necessitano di essere rapidamente risincronizzati.
Il
Moving Pictures Expert Group di
iso emette una serie di standard ognuno orientato ad un particolare dominio applicativo di segnali multimediali, come
- mpeg-1 adotta un formato sif di 352x288 pixel inteso per la memorizzazione audio-video a qualità vhs su cdrom, a velocità fino a 1.5 Mbps;
- mpeg-2 è orientato alla memorizzazione e trasmissione audio-video secondo quattro livelli di risoluzione, per ognuno dei quali diversi profili individuano tecniche alternative di codifica;
- mpeg-4 è stato inizialmente concepito per applicazioni simili a quelle dell’h.263, ma il suo uso si è successivamente esteso ad un’ampia gamma di applicazioni Internet.
Anche mpeg-1 adotta tecniche del tutto simili a quelle dell’h.261, con una scansione dell’immagine progressiva ed un sottocampionamento delle componenti di colore 4:1:1, una frequenza di quadro di 25 Hz, l’adozione di quadri di tipo I, P e B, la rappresentazione dei quadri in termini di macroblocchi composti da 16x16 pixel di luminanza, più due blocchi 8x8 per ciascuna componente di colore. Le principali differenze sono che
- possono essere inseriti riferimenti temporali all’interno di un quadro, permettendo al decodificatore di sincronizzarsi più rapidamente. L’intervallo tra due marche temporali è chiamato slice e comprende una sequenza orizzontale di macroblocchi, tipicamente che copre una intera riga, o meno, ma non di più;
- l’uso dei quadri di tipo B aumenta la distanza temporale tra i quadri di tipo P ed il loro riferimento, e quindi determina una maggiore distanza coperta dalle porzioni di immagine in movimento, cosicché l’ampiezza della finestra di ricerca adottata dal componente di detezione di movimento è stata estesa.
La figura
10.46-a) illustra la
struttura gerarchica del bitstream risultante, secondo il quale l’intero filmato (
sequenza) è costituito da una successione di
gop, ed ogni
gop da una sequenza di quadri, ognuno costituito da una successione di
slice che comprendono ognuno 22 macroblocchi, ognuno con 6 blocchi. La sezione
-b) di fig.
10.46 entra più nel dettaglio del formato del bitstream.
| Livello |
formato |
bit rate |
applicazione |
| mpeg-2 |
|
(Mbps) |
|
| Low |
sif |
< 1.5 |
registrazione |
|
|
|
qualità vhs |
| Main |
4:2:0 |
< 15 |
dvb - mp@ml |
|
4:2:2 |
< 20 |
|
| High 1440 |
4:2:0 |
< 60 |
hdtv 4/3 |
|
4:2:2 |
< 80 |
|
| High |
4:2:0 |
< 80 |
hdtv 16/9 |
|
4:2:2 |
< 100 |
|
Allo scopo di poter usare questo stesso standard per diversi contesti applicativi, sono stati definiti i quattro
livelli qualitativi mostrati alla tabella seguente, e per ogni livello sono quindi definiti cinque profili (
simple, main, spatial resolution, quantization accuracy, high) in modo da permettere lo sviluppo di nuove tecnologie. Il livello
Low è compatibile con
mpeg-1. Affrontiamo ora la descrizione di ciò che è offerto dal profilo
Main al livello
Main (MP@ML).
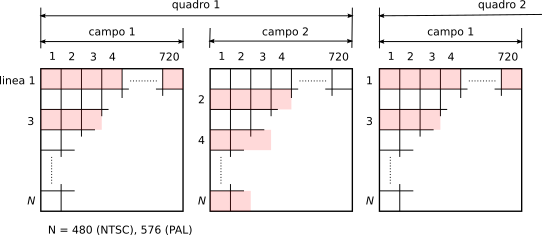
L’obiettivo è la diffusione televisiva
dvb, con scansione interallacciata, risoluzione 720x576 a 25 quadri/secondo (
pal), sottocampionamento 4:2:0 per una velocità risultante tra i 4 ed i 15 Mbps. La principale differenza rispetto all’
mpeg-1 è legata alla modalità di scansione
interallacciata, in modo che come mostrato in fig.
10.47,
ogni quadro è costituito da due sottoquadri (o
campi) con le righe rispettivamente dispari e pari, ponendo la questione: come comporre i blocchi da 8x8 pixel su cui eseguire la
dct? Sono possibili due alternative:
- la modalità campo (fig. 10.48-a) in cui i 16x16 pixel di un macroblocco sono ripartiti tenendo assieme prima le sole righe dispari del primo campo, e quindi le sole righe pari del secondo campo, oppure
- la modalità quadro (fig. 10.48-b) in cui si usa la stessa suddivisione già vista per il caso non interallacciato, mescolando i due campi in ognuno dei blocchi.
La scelta migliore su quale tra le due modalità adottare dipende dal tipo di scena che si sta rappresentando. Se è presente molto movimento, è meglio adottare la modalità campo: essendo infatti i pixel di uno stesso blocco collezionati in un tempo pari a metà dell’intervallo di quadro (mentre nella seconda metà si collezionano i pixel della seconda serie di blocchi), si ottiene un fotogramma meno mosso; viceversa in presenza di una scena con poco movimento, può essere adottata la modalità quadro.
Per quanto riguarda la stima di movimento, sono ora previste tre possibilità: la modalità campo prevede che i campi dispari usino come riferimento i campi pari del quadro precedente, ed i campi pari quelli dispari dello stesso quadro: in tal modo l’intervallo temporale su cui è valutato il movimento è metà del periodo di quadro. Nella modalità quadro invece, i campi pari e dispari usano come riferimento i rispettivi campi pari e dispari del quadro precedente, ed è più idoneo nel caso di movimenti lenti. Il meglio di entrambi i modi si ottiene con la modalità mista, in cui sono attuati entrambi gli approcci, e viene scelto per la trasmissione quello in grado di dar luogo alla distorsione minore.
Sono definiti tre standard, atv, dvb e muse, rispettivamente per il Nord America, l’Europa ed il Giappone, a cui si aggiunge la specifica hdtv di itu-r relativa a studi di produzione e scambio internazionale, e che definisce un rapporto di aspetto 16/9 con 1920 colonne per 1152 righe (di cui solo 1080 visibili), con scansione interallacciata e sottocampionamento 4:2:2. atv include le specifiche di itu-r, oltre che un formato ridotto, sempre con aspetto 16/9 ma risoluzione 1280x720, e che adotta la codifica video mpeg-2 mp@ml e quella audio ac-3. Il dvb è basato su di un rapporto di aspetto 4/3 con 1440x1152 pixel (di cui 1080 visibili), pari cioè al doppio della risoluzione pal di 720x576. La codifica video è mpeg-2 ssp@h1440 (Spatially Scaleable Profile at High 1440), simile all’mp@ml, mentre la codifica audio è mpeg audio layer 2.
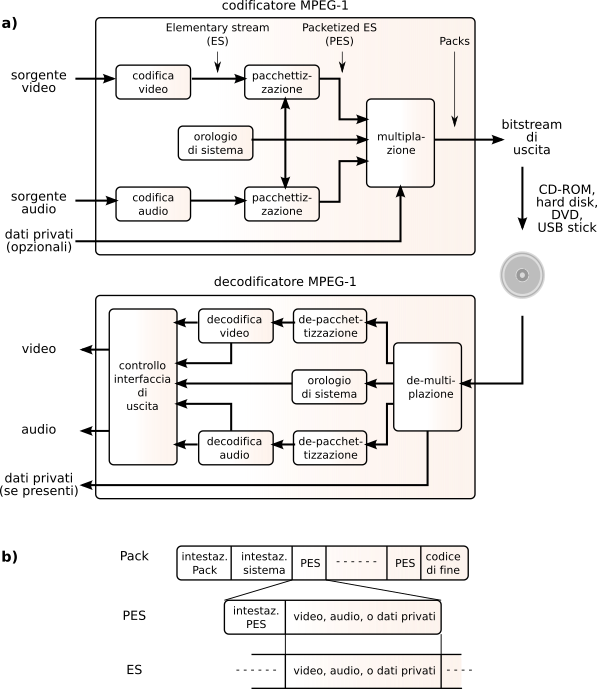
I flussi binari prodotti dai diversi codificatori (audio, video) prendono il nome di
Elementary Stream (
es), e possono essere multiplati assieme per produrre un nuovo formato idoneo alla registrazione di un contenuto multimediale completo, eventualmente arricchito da un flusso di
dati privati, come mostrato in fig.
10.49a per il caso di
mpeg-1.
Prima di effettuare la multiplazione, gli
es sono suddivisi in
pacchetti di dimensione variabile denominati
Packetized es (
pes) in cui trova posto un
payload contenente il risultato della codifica (ad es. un intero quadro), preceduto da una
intestazione contenente un codice univoco di inizio
pes ed un codice che individua il tipo di payload del pacchetto (audio, video o dati). L’intestazione
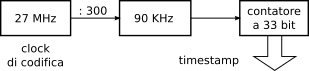
pes può inoltre contenere un riferimento temporale necessario alla sincronizzazione audio-video, con risoluzione
33 bit, prodotto dal clock a 90 kHz descritto in fig.
10.49 come
orologio di sistema, e ottenuto a partire da un oscillatore a 27 MHz come mostrato alla figura a pagina precedente.
Nel momento in cui un
es è pacchettizzato, viene inserito un
presentation timestamp (
pts) che ne individua l’istante di riproduzione; per i flussi video è inserito anche un
decode timestamp (
dts) perché come anticipato a pag.
1 l’ordine di trasmissione (e quindi di decodifica) può differire dall’ordinamento naturale.
I pes derivanti da diversi es possono essere quindi inseriti in una struttura di trama detta Pack, che può infine essere memorizzata ai fini di una successiva riproduzione.
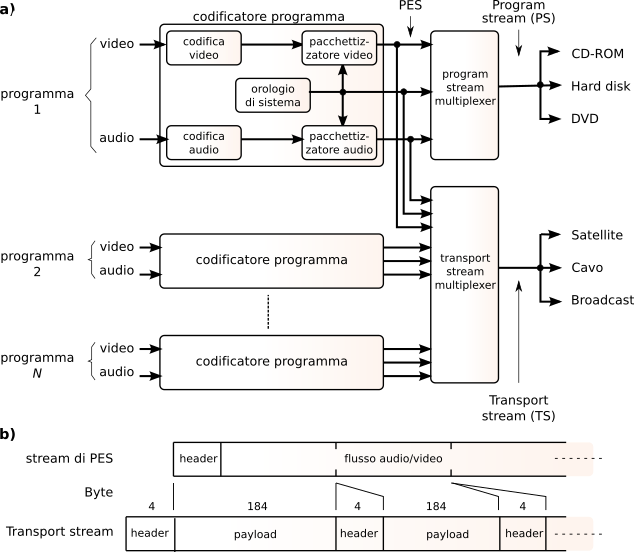
10.3.2.1 Transport Stream
Nel caso di trasmissione dei contenuti mediante un sistema broadcast, tipicamente il singolo
Program Stream ps (equivalente a quello prima indicato come
Pack) viene ulteriormente multiplato assieme ad altri, in modo da realizzare un
Transport Stream (
ts), come mostrato in fig.
10.51. In particolare, la parte b) della figura mostra come i
pes siano ora suddivisi in segmenti di lunghezza fissa e pari a 184 byte, intestati con 4 byte, producendo una struttura di trama con pacchetti di 188 byte; l’ultimo pacchetto del
ts che origina da uno stesso
pes è riempito con uni fino a raggiungere i 188 byte. L’intestazione contiene, oltre ad un byte di inizio con pattern unico, un
Packet IDentification code (
pid) di 13 bit, che identifica il
pes a cui appartiene il pacchetto, permettendo al decoder di recuperare il programma a cui è interessato.
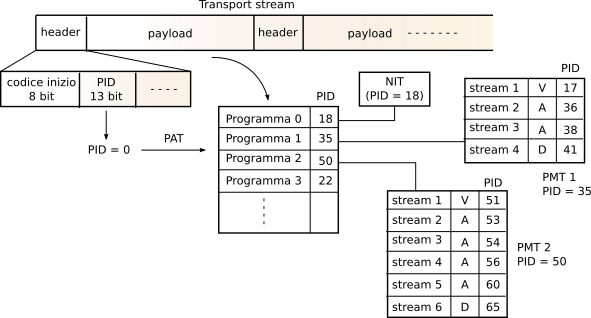
Alcuni
pid sono riservati, come il
pid 8191 che indica assenza di payload, ed il
pid 0, che annuncia l’inserimento nel payload della
Program Association Table (
pat), la cui ricezione permette al decoder di conoscere quali
pid sono utilizzati per individuare i diversi
pes (audio, video) di uno stesso programma. Questo avviene per mezzo delle
Program Map Table (
pmt) rappresentate in fig.
10.52: ogni riga della
pat individua infatti un nuovo
pid, alla ricezione del quale viene estratta dal payload la
pmt che descrive i
pid dei flussi che compongono il programma. Pertanto, quando uno spettatore seleziona un programma, il decodificatore cerca nella
pat il
pid della
pmt associata, e quindi inizia a prelevare i pacchetti intestati con ognuno dei
pid trovati nella
pmt, per ricostruire i relativi
pes, sincronizzarli, ed iniziare la riproduzione.