Prev Indice AnaliticoSu Copertina Note di copertina Next
Note a piè di pagina
Sono qui raccolte le più
di 1500 note presenti nell'intero testo, e per questo la pagina è eccezionalmente lunga,
lenta a caricarsi ed ancor più ad essere visualizzata, a maggior ragione sui telefonini.
Se sei capitato/a qui per errore torna pure indietro senza problemi,
altrimenti... abbi pazienza.
In tutti i modi, all'inizio di ogni nota c'è il link per andare alla pagina che la referenzia.
[1]In realtà il mondo universitario di afflizioni ne ha diverse, come ad esempio il fatto che un lavoro come questo ha valore zero per quanto riguarda la carriera accademica. Si, perché il mestiere del docente, a quanto pare, non é insegnare bene, ma scrivere tanti articoli, da far vendere alle riviste scientifiche, ovviamente a carico delle biblioteche universitarie.
[2]Presso https://teoriadeisegnali.it/libro/ è disponibile il download del testo in PDF, il formato HTML che viene indicizzato dai motori di ricerca, gli esercizi di esame svolti, e... molto altro!
[3]Nella copia a stampa, dopo l’ultimo capitolo viene fornito il link al download del pdf completamente navigabile.
[5]Precedentemente indicata come copia di cortesia, traduzione letterale di courtesy copy, termine usato con lo stesso significato.
[6]La maggior parte dei pdf reperibili in rete non dispone di un indice navigabile, e personalmente trovo questo diffuso costume particolarmente antipatico.
[7]Alcuni lettori di pdf dispongono di uno stack di navigazione che consente di tornare indietro al punto in cui ci si trovava prima di aver cliccato un link interno. Su Linux posso consigliarvi qpdfview, leggero e presente in molte distribuzioni.
[9]Precedentemente erano tre, ora la modulazione ha acquisito lo status di parte a sé, dato che è un argomento che non necessariamente occorre spiegare (ad esempio) a studenti di (bio)informatica.
[10]Mentre per i campioni di segnale nel tempo la topologia associata è definita dalla relazione di vicinanza unidirezionale uno contro l’altro, e per le immagini la topologia corrisponde a quella di una mappa spaziale bidimensionale, per i dati sui grafi la topologia è definita a partire dalla matrice di adiacenza, che si fa beffe di mappe e sequenze.
[11]La distinzione tra significato e significante esprime la differenza che passa, ad esempio, tra l’immagine mentale che ognuno può avere di un cavallo, e la parola “cavallo” (scritta o pronunciata), in cui entrambi partecipano a definire un segno linguistico, vedi https://it.wikipedia.org/wiki/Significante. In tale contesto, i due aspetti del segno rimandano ad un referente, che nel nostro esempio corrisponde ad un cavallo in carne ad ossa, mentre dal punto di vista dei segnali individua una specifica forma d’onda.
[12]Approfondiremo nel seguito (cap. 8) il senso di questi concetti, limitandoci per ora ad associarli ad una generica diversità tra il segnale trasmesso e quello ricevuto.
[13]Un classico esempio di trasduttore è quello dell’antenna, nel caso di trasmissione radio, ovvero di microfono ed altoparlante qualora ci si ponga dal punto di vista dello studio e degli ascoltatori.
[14]Come vedremo al cap, 11, un segnale a valori complessi è il risultato di una particolare rappresentazione, detta inviluppo complesso, utile nell’analisi dei segnali modulati.
[15]Una sequenza prodotta da una sorgente numerica si presta facilmente ad essere trasformata in un’altra, con un diverso alfabeto ed una differente frequenza di simbolo. Per fissare le idee, consideriamo i simboli di una sequenza numerica sn ad L valori (ovvero A = 1, 2, ⋯, L): questi possono essere presi a gruppi di M, producendo nuovi simboli qk a velocità M volte inferiore, ma con LM valori distinti. Se si dispone di un alfabeto di uscita ℬ ad H valori (ovvero ℬ = 1, 2, ….H), i gruppi di M simboli L-ari originari possono essere rappresentati con gruppi di N simboli H-ari purché LM ≤ HN. Esempio: per codificare in binario (H = 2) simboli con L = 26 valori, occorrono almeno N = 5 bit/simbolo, ottenendo così 25 = 32 > L = 26. E’ un ragionamento confuso? Si e no. Basta fare degli esempi.
[16]Nelle trasmissioni unidirezionali, sorgente e destinazione non si scambiano i ruoli. La trasmissione stessa viene anche indicata con il termine di half-duplex.
[17]Si parla in questo caso di codifica FEC, ovvero di Forward Error Correction.
[18]Pensiamo per similitudine ad un imballaggio, il cui contenuto è prima disposto in modo da occupare il minimo volume (codifica di sorgente), ed a cui viene poi aggiunto del materiale antiurto (codifica di canale).
[19]Nei collegamenti numerici non occorre specializzare il metodo di trasmissione al mezzo a disposizione, anzi quest’ultimo è totalmente "mascherato" dal fornitore del collegamento numerico stesso, e dal modem che viene utilizzato.
[20]La notazione M = ⌈log2L⌉ individua l’intero superiore del valore racchiuso tra le semiparentesi ⌈⌉. Ad esempio se L = 21 allora log221 = 4, 3923.. e dunque M = ⌈4, 3923⌉ = 5, ovvero occorrono 5 bit/campione.
[21]L’utilizzo di dispositivi di conversione digitale-analogico è molto comune nella realtà odierna, un esempio tra tutti è quello dei CD audio, vedi https://it.wikipedia.org/wiki/CD_Audio
[22]Infatti M = ⌈log2L⌉ aumenta all’aumentare del numero L di possibili valori per i campioni quantizzati, e ciò corrisponde ad una maggiore fedeltà, ossia ad una minore distorsione. Inoltre, al cap. 4 verrà illustrato come l’aumento di fc corrisponda ad un maggiore intervallo di frequenze che possono essere riprodotte dal DAC, ovvero anche il valore di fc è direttamente legato ad un concetto di fedeltà di riproduzione.
[23]I termini colorato e bianco hanno origine da una similitudine con l’energia luminosa, per cui se la luce bianca indica l’indiscriminata presenza di tutte le lunghezze d’onda, così uno spettro bianco indica la presenza in egual misura di tutte le frequenze; viceversa, come una luce colorata dipende dal prevalere di determinate frequenze nella radiazione elettromagnetica, così uno spettro colorato indica la prevalenza di alcune frequenze su altre.
[24]L’importanza e la specificità di tali trasformazioni assume un rilievo sempre maggiore con l’evoluzione (in termini di miniaturizzazione e potenza di calcolo) dei dispositivi di elaborazione, in special modo per ciò che riguarda le trasmissioni numeriche.
[25]Discuteremo al cap. 9 come l’informazione consista nella sorpresa di conoscere qualcosa che prima era ignoto, e dunque un segnale perfettamente noto non trasporta informazione.
[26]Ad esempio, il calcolo dell’integrale di una funzione viene svolto per via numerica quando è ottenuto senza conoscerne la primitiva, per mezzo di un programma che ne calcola l’approssimazione secondo la definizione di Riemann https://it.wikipedia.org/wiki/Integrale_di_Riemann, vedi
da cui si riconosce che sp(t) = 12(s(t) + s(−t)) e sd(t) = 12 (s(t) − s(−t)).
[28]Si tratta di segnali che non si annullano, ma che neanche divergono, ed in questo caso possono rientrare i fenomeni naturali come il rumore del vento o delle onde del mare, ma anche segnali la cui durata eccede l’intervallo effettivo di osservazione, come un battito cardiaco, o perché no, l’audio di un televisore lasciato acceso giorno e notte!
[30]Ad esempio si compie un lavoro quando si solleva un oggetto, aumentando la sua energia potenziale, o gli si imprime una accelerazione, aumentandone l’energia cinetica.
[31]Perché l’integrale (1.2) converga occorre che per t → ∞ il segnale s(t) tenda a zero più velocemente di 1√t, e perciò |s(t)|2 vi tende più in rapidamente di 1t. In altre parole, un segnale di energia s(t) è quadraticamente sommabile; infatti sappiamo dall’analisi che una funzione è detta sommabile (o integrabile) nell’intervallo ( −∞, ∞) se il suo integrale è finito, ed una condizione sufficiente perché ciò avvenga è che limt → ∞s(t) sia un infinitesimo di ordine superiore a 1, ovvero che limt → ∞t ⋅ s(t) = 0.
[32]Vedi ad es. https://it.wikipedia.org/wiki/Funzione_a_quadrato_sommabile. La L che dà il nome allo spazio sta per Lebesgue, mentre il 2 individua un caso particolare (di Hilbert) di spazio Lp che corrisponde a tutte le funzioni per le quali ∫∞−∞|s(t)|pdt converge, noto come spazio di Banach, per il quale l’integrale costituisce una misura (norma) per i suoi elementi, il che induce una metrica, e quindi una topologia; per approfondimenti https://en.wikipedia.org/wiki/Lp_space
[33]La parola spettro deriva dal latino specĕre (guardare) e viene utilizzato in molti campi della scienza per indicare la gamma dei costituenti di un qualcosa, vedi https://it.wiktionary.org/wiki/spettro
[36]Il coefficiente angolare m è pari alla derivata di v(t) calcolata per t = 0, dunque v’(t) = ddt V0e − t ⁄ τ = − V0τe − t ⁄ τ che fornisce appunto v’(t)|t = 0 = − V0τ. Inoltre come noto m = tanα dove α è l’angolo tra la retta tangente e l’asse delle ascisse come mostrato in figura, ma a sua volta tanα = sinαcosα = V0τ.
[40]Ciò si può dimostrare tenendo conto della formula di Eulero (§ 2.1.2) ejy = cosy + jsiny, che permette di scrivere |w| = |ex ⋅ ejy| = ex ⋅ √cos2y + sin2y = ex.
[41]Anche questo è un comportamento atteso, sempre alla luce della formula di Eulero in base alla quale se z è solamente immaginario ejy = cosy + jsiny.
[42]Tale fattore è pari al logaritmo naturale di a, in accordo alla serie di potenze che recita az = ∑∞n = 0(zln a)nn!
[43]In base all’osservazione di cui alla nota precedente, si ha ajy = cos(yln a) + jsin(yln a)
[45]In realtà nulla vieta ad un filtro di modificare la propria risposta impulsiva nel tempo, ma in tal caso in uscita compaiono componenti frequenziali non presenti in ingresso, e viene dunque persa la linearità.
[46]Qualcuno, non a torto, mi ha scritto chiedendo se non intendessi dire pesati. No, ho scritto così immaginando come se la risposta impulsiva fosse una sorta di rete a strascico che pesca i valori di ingresso passati. Effettivamente questo concetto diviene chiaro solo a seguito della costruzione grafica riportata alla sezione citata e che illustra l’operazione di convoluzione, di cui si raccomanda la comprensione.
[47]Un operatore si dice senza memoria quando ogni valore dell’uscita dipende da un unico valore di ingresso.
[48]Una funzione y(x) è lineare quando il suo sviluppo in serie di potenze si arresta al primo ordine, ed è quindi esprimibile in forma y = ax + b, che è l’equazione di una retta.
[49]L’insieme dei numeri reali è indicato con ℝ, vi fanno parte i numeri interi, razionali, irrazionali e trascendenti, e può essere messo in corrispondenza biunivoca con gli infiniti punti su di una retta.
[50]L’unità immaginaria trae origine dalla teoria dei numeri come la quantità √ − 1, in modo da poter esprimere nel campo complesso ℂ tutte le radici di un’equazione polinomiale. Mentre in analisi matematica è indicata dalla lettera i, nel seguito viene indicata con la lettera j in accordo alla notazione di teoria dei circuiti, in modo da evitare confusione con il simbolo utilizzato per la corrente elettrica. Risulta j2 = − 1, j3 = − j, j4 = 1, j5 = j e così via ciclicamente.
Sommare tra loro le parti reali e quelle immaginarie equivale a realizzare una somma vettoriale tra x e y come mostrato a lato. Per il prodotto si applica invece la regola del prodotto tra binomi, ovvero (a + jb)(c + jd) = ac + jad + jbd + jbjd da cui il risultato, ricordando che j2 = − 1.
[52]Mentre l’espressione del modulo è una diretta conseguenza del teorema di Pitagora, quella della fase discende dall’osservare che ba = |x|sinφx|x|cosφx = tanφx, per cui φx = arctanba. Con l’avvertenza che, qualora risulti a < 0, al risultato φx va aggiunto il termine π in quanto la funzione arctanφ è definita per valori dell’argomento − π⁄2 < φ < π⁄2, vedi https://www.geogebra.org/m/Enf5AEbT. Nei linguaggi di programmazione esiste in genere la funzione atan2(b,a) che effettua automaticamente tale considerazione, vedi https://it.wikipedia.org/wiki/Arcotangente2.
[54]Più in generale, il valore ex con x = a + jb è ancora un numero complesso, con fase b e modulo ea. Infatti ex = ea + jb = eaejb = ea(cosb + jsinb).
[55]Osserviamo infatti che e jφ ed e −jφ sono tra loro coniugati, e quindi applicando la (10.3) per la loro somma si ha e jφ + e −jφ = 2ℜ{ e jφ} = 2cosφ mentre la differenza produce e jφ − e −jφ = 2jℑ{e jφ} = 2jsinφ.
[56]L’affermazione nasce dalla relazione eαeβ = eα + β. Ad esempio quindi, il prodotto cosα ⋅ sinβ diviene
14j(e jα + e −jα)(e jβ − e −jβ) = 14j[e jαe jβ − e jαe −jβ + e −jαe jβ − e −jαe −jβ] =
= 14j[e j(α + β) − e j(α − β) + e −j(α − β) − e −j(α + β)]
= 14j [e j(α + β) − e −j(α + β) − (e j(α − β) − e −j(α − β))] =
e sviluppare il calcolo facendo uso delle relazioni cosαcosβ = 12[cos(α + β) + cos(α − β)] e sinαsinβ = 12[cos(α − β) − cos(α + β)], ma avremmo svolto molti più passaggi.
[58]Da un punto di vista etimologico, la serie armonica è definita come ∑∞n = 11⁄n, mentre gli armonici di
una corda di chitarra sono i suoni prodotti dopo averne bloccato la vibrazione in corrispondenza di 1⁄n − esimo della sua lunghezza. Dal punto di vista della teoria musicale le armoniche di una nota sono altre note a frequenza multipla della prima. In particolare la seconda armonica corrisponde ad un intervallo di ottava, mentre la quarta a due ottave. E la terza armonica? Partendo ad esempio dal la4, e sapendo che ogni semitono della scala temperata corrisponde ad un rapporto di frequenze pari a 21⁄12 rispetto al semitono precedente, determiniamo il numero di semitoni Ns tra il la4 e la sua la terza armonica. Ad un rapporto di frequenze pari a 2Ns⁄12 = 3 corrisponde Ns12 = log23 ≃ 1.5849 e quindi Ns = 19 semitoni, ovvero un intervallo di dodicesima, cioè il mi5 che viene dopo il la5 dell’ottava successiva. Procedendo allo stesso modo si trova che la quinta, sesta e settima armonica corrispondono rispettivamente a do#6, mi6 e sol6: pertanto, con le prime sette armoniche si compone un accordo di settima di dominante.
[59]Per una discussione relativa alla convergenza della serie (10.7) si veda il § 2.5.1.
[61]Notiamo infatti che se x(t) è (reale) pari, allora il termine x(t)sin2πnFtdt che compare nel secondo temine della (10.9)è dispari, ed il suo integrale esteso ad un intervallo simmetrico rispetto all’origine è nullo, e pertanto ℑ{Xn} = 0. Se invece x(t) è (reale) dispari, allora è x(t)cos2πnFtdt nel primo termine ad essere dispari, e dunque per lo stesso motivo si annulla l’integrale che esprime ℜ{Xn} = 0.
[65]Il termine duty cycle si traduce ciclo di impegno, ed è definito come il rapporto percentuale tra il tempo per cui l’onda quadra è diversa da zero, ossia duty cycle = τT*100 %.
[66]Oppure a sinistra, qualora n sia negativo e quindi − nT positivo.
[67]Sappiamo infatti che ∂∂xef(x) = ef(x) ⋅ ∂f(x)∂x, e quindi ∫baef(x)dx = 1⁄∂f(x)∂x ⋅ ef(x)|ba
[68]Si può mostrare che le armoniche pari risultano nulle per tutti i segnali periodici alternativi, ovvero per i quali (a parte una eventuale componente continua) un semiperiodo eguaglia l’altro, cambiato di segno.
[70]In generale risulta, con la notazione di prodotto scalare ⟨a, b⟩ tra vettori-segnali a e b introdotta al § 2.4: ⟨x + y, x + y⟩ = ⟨x, x⟩ + ⟨y, y⟩ + ⟨x, y⟩ + ⟨y, x⟩.
[71]Uno spazio vettoriale è la generalizzazione del ben noto spazio euclideo, i cui elementi sono descritti da una n − pla di numeri reali detto vettorex = x1x2 ⋯ xn, e che estende quello mono-, bi- o tri-dimensionale rispettivamente legato a retta, piano e spazio in senso geometrico. Le quantità xi costituiscono dunque le coordinate di un punto, ovvero dove si colloca la testa di un vettore che parte dall’origine, ed individuano quanto di quel vettore è dovuto al contributo di ciascuna delle componenti associate ai versori della base di rappresentazione.
[73]La definizione analitica di completezza consiste nell’affermare che tutte le successioni di Cauchy (o successioni fondamentali) sono convergenti, in cui una successione è di Cauchy se, comunque fissato un ε > 0, da un certo punto in poi tutti i suoi elementi sono tra loro più vicini di ε, e dunque la loro distanza tende ad annullarsi; se poi la successione converge ad un elemento dello spazio stesso, allora lo spazio è completo. Pertanto una successione convergente è di Cauchy, ma non è detto l’inverso. Vedi anche https://it.wikipedia.org/wiki/Spazio_metrico_completo
[74]K può essere il campo dei numeri reali ℝ, o quello dei numeri complessi ℂ, vedi anche https://it.wikipedia.org/wiki/Campo_(matematica). Qualora il campo sia complesso, anche le componenti del vettore lo sono; d’altra parte, le relazioni sviluppate per il caso complesso continuano a valere anche nel caso di vettori a componenti reali.
[75]I perfezionisti possono volersi sentir anche dire che deve esistere l’elemento neutro (zero) rispetto alla somma, che quest’ultima deve essere commutativa, associativa, e distributiva rispetto al prodotto, e che ogni elemento x deve avere il suo opposto − x. Vedi anche https://it.wikipedia.org/wiki/Spazio_vettoriale
[76]L’indipendenza lineare tra vettori comporta che ∑ni = 1λiui = 0 solo se λi = 0 per tutti gli i.
[81]In genere il termine prodotto interno si riferisce al caso in cui lo spazio sia di natura complessa, mentre si dice prodotto scalare qualora sia definito sul campo dei numeri reali. Nel seguito potrà essere usato prodotto scalare anche nel caso complesso.
[83]Le proprietà 0 ≤ ∥x∥ < ∞ e ∥λx∥ = λ∥x∥ che definiscono una norma sono facilmente verificate, mentre per dimostrare che ∥x + y∥ ≤ ∥x∥ + ∥y∥ ovvero √⟨x + y, x + y⟩ ≤ √⟨x, x⟩ + √⟨y, y⟩ occorre utilizzare il risultato (10.20). Scriviamo infatti
in quanto ℜ{⟨x, y⟩} ≤ |⟨x, y⟩| ≤ ∥x∥ ⋅ ∥y∥ dove la seconda disuguaglianza è appunto la (10.20). Dunque, dato che in base alla (10.19) si ha ∥x + y∥ = √⟨x + y, x + y⟩, si ottiene ∥x + y∥ ≤ ∥x∥ + ∥y∥.
[84]Ogni spazio di Hilbert è quindi anche di Banach, ma il viceversa è vero solo se la metrica è indotta da un operatore di prodotto interno, che rispetti le proprietà su indicate; vedi ad es. https://it.wikipedia.org/wiki/Spazio_di_Hilbert
[85]Innanzitutto osserviamo che deve risultare x, y ≠ 0, altrimenti la (10.20) è banalmente 0 = 0. Applichiamo quindi la relazione ⟨x, x⟩ ≥ 0 ad un vettore x − λy con un qualunque λϵK (sia per K = ℝ che per K = ℂ), scrivendo
dato che α2⟨y, y⟩ = αα*⟨y, y⟩ = ⟨αy, αy⟩ = ⟨x, x⟩.
[87]Come fatto notare si ottiene cosθ = 1 quando x e y sono paralleli per cui la (10.20) è un’uguaglianza. Dal canto suo ⟨x, y⟩ è un numero (complesso o reale a seconda se K = ℂ o ℝ), e dunque l’operazione di modulo |⟨x, y⟩| limita il risultato a − π⁄2 ≤ θ ≤ π⁄2. Quindi θ è un angolo un po’ per modo di dire; ciononostante, il concetto di parallelismo e ortogonalità che ne deriva è molto utile.
[88]E sufficiente eseguire il prodotto scalare di ambo i membri di x = ∑ni = 1xiui per ciascuno dei vettori uj per ottenere ⟨x, uj⟩ = ⟨∑ni = 1xiui, uj⟩ = ∑ni = 1xi⟨ui, uj⟩ = xj⟨uj, uj⟩ = xj∥uj∥2 dato che ⟨ui, uj⟩ = 0 per i ≠ j e che ⟨uj, uj⟩ = ∥uj∥2.
[89]Scriviamo infatti ⟨x, y⟩ = ⟨∑ni = 1xiui, ∑nj = 1yjuj⟩ = ∑ni = 1∑nj = 1⟨xiui, yjuj⟩ ma, essendo ui e uj ortogonali la doppia sommatoria si riduce ad una sola, ovvero ⟨x, y⟩ = ∑ni = 1⟨xiui, yiui⟩ = ∑ni = 1xiy * i∥ui∥2.
[91]A chi si sta chiedendo dove siano finiti gli indici negativi, rispondo che gli indici sono stati riorganizzati alterandone la numerazione, tanto rimangono comunque di una infinità numerabile.
[92]La L usata per definire tali insiemi sta per Lebesgue, legata cioè al modo di calcolare l’integrale che prende nome da tale matematico, e che assegna uguale valore all’integrale di due funzioni che differiscono in un insieme di punti a misura nulla, dette funzioni uguali quasi ovunque, vedi https://it.wikipedia.org/wiki/Integrale_di_Lebesgue e https://it.wikipedia.org/wiki/Spazio_Lp
[93]Ad esempio, la componente continua X0 = 1T∫T⁄2 − T⁄2x(t)e −j0dt = 1T∫T⁄2 − T⁄2x(t)dt rappresenta il prodotto scalare tra x(t) ed un segnale costante pari ad uno.
[98]Infatti vi(θ) = Tφt, θ[ui(t)] = ⟨ui(t), φ(t, θ)⟩. Ma è anche vero che ⟨ui(t), φ(t, θ)⟩ = ⟨φ(t, θ), ui(t)⟩* = (Tui[φ(t)])* e dunque i segnali vi(θ) sono anche coniugati alla proiezione di φ(t) lungo il vettore della base ui(t).
[99]E dunque poter esprimere ogni suo vettore come y(θ) = ∑ni = 1yiũi(θ) in cui yi = ⟨y(θ), ũi(θ)⟩ è la proiezione di y(θ) lungo ũi(θ).
[100]La relazione che lega zj(t) alle altre grandezze dovrebbe risultare zj(t) = ∑ni = 1⟨ũj(θ), vi(θ)⟩ui(t), ma il testo Signal Theory di L.E. Franks che ho utilizzato per questa parte forse ha saltato qualche passaggio, o non ho avuto la pazienza di ricostruirli.
[104]Da un punto di vista mnemonico, cerchiamo di ricordare che l’esponenziale sotto il segno di integrale prende il segno meno nel passaggio t → f, ed il segno più passando da f a t.
[105]Indicando 1⁄T con F in modo da uniformare la notazione a quella del § 2.2 otteniamo infatti
[106]Nei testi anglofoni la (10.35) è indicata come cross-energy, a volte tradotta letteralmente come energia incrociata, ma qui invece più propriamente intesa come in comune, ovvero mutua.
[108]Ovvero che mette in corrispondenza coppie di vettori-segnale x(t) e X(f) appartenenti allo spazio vettoriale dei segnali di energia definito rispettivamente sul dominio del tempo e della frequenza. Dato che gli esponenziali complessi {ej2πft} costituiscono una base ortonormale per i segnali di energia (§ 3.8.5), osserviamo come la (10.31) valuti il prodotto interno tra il vettore x(t) e un vettore della base, mentre la (10.32) rappresenta l’equivalente continuo della formula di ricostruzione (10.7).
[109]Infatti X*(f) = [∫x(t)e −j2πftdt]* = ∫x*(t)ej2πftdt = X(−f) dato che x(t) è reale.
[110]Iniziamo dall’espressione dell’antitrasformata x(t) = ∫∞−∞X(f)ej2πftdf in cui scambiamo tra loro le variabilif e t ottenendo x(f) = ∫∞−∞X(t)ej2πftdt; operando quindi un cambio di variabile f → − f si ha x(−f) = ∫∞−∞X(t)e −j2πftdt che coincide con il risultato mostrato alla prima riga nel testo.
[111]La dimostrazione si basa sul semplice cambio di variabile θ = t − T: Z(f) = ∫x(t − T) e −j2πftdt = ∫x(θ) e −j2πf(T + θ)dθ = e −j2πfT∫x(θ) e −j2πfθdθ = X(f)e −j2πfT
[112]Tali condizioni corrispondono a quelle descritte a pag. 1 come quelle di un canale perfetto.
[113]Nel seguito (§ 15.1.2.2) illustreremo come il risultato discusso determini la sensibilità delle trasmissioni numeriche alle distorsioni di fase.
[119]La (10.43) si dimostra esprimendo δ(t) come limT → 01TrectT(t) in modo da scrivere il primo membro come x(t)limT → 01TrectT(t − τ). Al tendere di T a zero il rettangolo di ampiezza 1T converge ad un impulso, la cui area resta moltiplicata per il valore che x(t) assume per t = τ, dove è centrato il rettangolo.
[120]Senza voler entrare nei dettagli analitici, diciamo che la (10.44) rappresenta l’equivalente della formula di ricostruzione (10.16) per uno spazio a cardinalità infinita, in cui δ(τ − t) al variare di τ costituisce una base di rappresentazione ortonormale, ed i cui coefficienti x(τ) sono calcolati come prodotto scalare x(τ) = ∫∞−∞x(t)δ(t − τ)dt.
[121]Adottando il cambio di variabile t − τ = θ, si ottiene
Infatti il cambio di variabile determina quello degli estremi di integrazione, che vengono poi scambiati ripristinando il segno, vedi ad es. https://it.wikipedia.org/wiki/Convoluzione
[122]Per convincerci dell’operazione, verifichiamo che per τ < t l’argomento t − τ di h è positivo, e infatti il valore di h(t − τ) è ≠ 0.
[126]Nel caso dell’esempio il rettangolo è costante e dunque l’ampiezza del coseno non varia, ma il termine modulazione si riferisce al prodotto di una sinusoide per un segnale dall’andamento qualsiasi.
[127]La dimostrazione viene svolta per segnali di energia, applicando in modo diretto la regola di integrazione per parti ∫[f′(t)g(t)]dt = f(t)g(t) − ∫[f(t)g′(t)]dt: F⎧⎩dx(t)dt⎫⎭ = ∫∞−∞dx(t)dte −j2πftdt = x(t)e −j2πft|∞−∞ + j2πf∫∞−∞x(t)e −j2πftdt = j2πfX(f)
in quanto il termine x(t)e −j2πft|∞−∞ si annulla, dato che se x(t) è un segnale di energia, tende a zero per t → ∞.
Se infatti valutiamo ∫t−∞⎡⎣δ⎛⎝θ + τ2⎞⎠ − δ⎛⎝θ − τ2⎞⎠⎤⎦dθ con t > τ2, otteniamo due gradini u⎛⎝t + τ2⎞⎠ − u⎛⎝t − τ2⎞⎠, che combinati assieme, riproducono il rectτ di partenza.
[129]Essendo x(t) = ddt y(t), ed applicando la (10.54) otteniamo X(f) = j2πfY(f), da cui la (10.55).
[130]Si può giungere ad un risultato anche nel caso in cui X(0) ≠ 0, ricorrendo all’impulso δ(t). Occorre scrivere l’integrale di x(t) nella forma di una convoluzione con un gradino unitariou(t), cioè y(t) = ∫t−∞x(θ)dθ = ∫∞−∞x(θ)u(t − θ)dθ (si pensi alla costruzione grafica del § 3.4.3). Al § 3.8.6 si ricava che la trasformata del gradino vale U(f) = 1j2πf + 12δ(f), ed applicando la proprietà della trasformata della convoluzione si ottiene Y(f) = X(f)U(f) = X(f)j2πf + δ(f)2X(0) che è la formula più generale per l’integrazione, ed in cui l’ultimo termine scompare per segnali ad area nulla, riottenendo la (10.55).
[134]La derivata di una discontinuità di prima specie è pari ad un impulso di Dirac, di area uguale all’altezza della discontinuità. Infatti l’integrale dell’impulso ∫t−∞δ(θ)dθ è proprio un gradino. Questa considerazione consente di risolvere in modo semplice le trasformate di segnali in cui è presente una discontinuità.
[135]Queste durate corrispondono quindi ad utilizzare 20 cicli di cosinusoide, oppure 5, oppure due e mezzo.
[136]Nel tempo sono state definite un elevato numero di finestre temporali, ognuna migliore sotto certi aspetti, e peggiore sotto altri. Consultando Wikipedia http://en.wikipedia.org/wiki/Window_function, possiamo elencare le finestre di Hamming, Hann, Cosine, Lanczos, Bartlett, Gauss, Blackman, Kaiser, Nuttall, Bessel, Dolph-Chebyshev, Exponential, Tukey....
[138]Ciò è vero purché si consideri il metodo di calcolo dell’integrale noto come valore principale di Cauchy , in quanto cos2πftj2πf tende a 10 per f → 0, con valori opposti per 0+ e 0−, vedi https://it.wikipedia.org/wiki/Valore_principale_di_Cauchy.
[140]Al termine campione è associato il valore di un segnale ad un determinato istante, e può essere considerato come sinonimo di esemplare, o esempio, ovvero sample in inglese; da non confondere con champion, o primatista!
[141]Digits in inglese, che a sua volta deriva dal latino digitus, da cui il termine digitale come sinonimo di numerico. In effetti il dito era una unità di misura utilizzata prima che nell’impero Romano, in Grecia, Egitto e Mesopotamia.
[142]Questo teorema è stato derivato indipendentemente e in tempi diversi da Borel, Whittaker, Kotelnikov e Shannon. Il contributo di Nyquist è in realtà relativo al problema di determinare la massima velocità di segnalazione fs su di un canale limitato in banda, vedi § 15.2.2.2.
[143]Al § 4.2.2 troveremo che in realtà la formula (10.66) non è l’unica possibile.
[145]Il risultato ottenuto replica in frequenza quello della trasformata di segnali periodici nel tempo: ad un segnale periodico in frequenza con periodo fc corrisponde una antitrasformata di Fourier costituita da impulsi nel tempo distanziati dall’inverso Tc = 1⁄fc del periodo fc.
in cui l’esponenziale complesso sotto integrale compie un numero intero di oscillazioni a media nulla per f ∈ [ − fc⁄2, fc⁄2] se k ≠ h, e dunque in tal caso l’integrale è nullo; al contrario, l’esponenziale vale 1 se k = h, ed il suo integrale definito vale fc, determinando il risultato mostrato, in cui δ(h, k) è il simbolo di Kronecker, che vale uno quando h = k e zero altrimenti.
[149]Non entriamo nei dettagli del funzionamento del buffer (vedi ad es. https://it.wikipedia.org/wiki/Amplificatore_separatore) qui esemplificato dall’amplificatore operazionale a controreazione unitaria: è sufficiente dire che agisce come un adattatore di impedenza, consentendo al condensatore di caricarsi in modo pressoché istantaneo, e di non scaricarsi prima che s2 sia chiuso, in quanto il secondo amplificatore presenta una impedenza di ingresso pressoché infinita.
[154]Per effetto della massa virtuale dell’amplificatore operazionale, in ciascuno dei resistori per cui bM − i = 1 scorre una corrente Ii = Vr2iR, la cui somma IT scorre anche nella R di controreazione, per cui
Vu = − R ⋅ IT = − R ∑Mi = 1bM − iVr2iR = − Vr ∑Mi bM − i2 − i
e moltiplicando e dividendo per 2M si ha Vr = − Vr2M∑Mi = 1bM − i2M − i, ossia compresa tra 0 e − Vr2M − 12M.
[156]Se invece gli intervalli hanno ampiezze differenti il quantizzatore è detto non uniforme, vedi il § 4.3.2.
[157]Il caso di L pari, diretta conseguenza dell’essere L = 2M una potenza di due, è detto mid-rise in quanto il grafico x = Q(x)sale per x = 0, mentre ad L dispari (caso mid-tread) corrisponde una regola di quantizzazione basata sull’arrotondamento di x, ed esiste un valore quantizzato che esprime un valore nullo. Per approfondimenti, vedi ad es. https://www.tutorialspoint.com/digital_communication/digital_communication_quantization.htm
[158]La notazione ⌊xΔq⌋ individua un troncamento, ovvero il numero intero subito inferiore ad xΔq. Ad esempio, se − 4 < x < 4, allora avremo xq = − 3.5, − 2.5, − 1.5, − 0.5, 0.5, 1.5, 2.5, 3.5.
[159]Nel seguito della sezione sono usati i concetti definiti al capitolo 6, a cui si rimanda per le definizioni mancanti.
[160]Questa ipotesi, come anche quella delle v.a. uniformi, sono manifestamente non vere in generale, ma permettono di giungere ad un risultato abbastanza semplice, e che può essere molto utile nei progetti di dimensionamento.
[161]Assumendo che il processo sia ergodico, la potenza (media temporale) eguaglia (eq. (10.125)) la corrispondente media di insieme, ovvero il momento di secondo ordine m(2)x, che a sua volta è pari alla varianza σ2x , essendo mx = 0. Vedi § 6.2.3 per il calcolo di σ2x = Δ2x⁄12.
[162]Una discussione relativa alla misura delle grandezze in decibel, è fornita al § 8.1. Qui ci limitiamo ad usare i dB come misura relativa di un rapporto, ossia
in cui le grandezze espresse in dBV2 rappresentano potenze di segnale di tensione, in unità logaritmiche.
[163]In alcuni testi alla (10.72) viene aggiunto un termine costante di 1.76 dB, derivante dall’adozione di un segnale sinusoidale con dinamica Δ, anziché un processo uniforme. Ma non ho mai afferrato il senso di un SNR positivo con M = 0 bit/campione.
[165]Il metodo è iterativo, ed inizia suddividendo l’intervallo Δx in modo uniforme. Per ogni iterazione:
si determinano i valori quantizzati xk (detti centroidi) come xk = E{x ∈ Ik} = ∫Ikx ⋅ pX(x ⁄ k)dx = ∫IkxpX(x)dxpk in cui pk = ∫IkpX(x)dx. In tal modo, i valori xksi spostano (internamente a Ik) verso la regione in cui pX(x) ha un valore più elevato, ovvero dove la v.a. si addensa;
si ri-calcolano i confini di decisione θk come θk = xk + xk + 12, seguendo lo spostamento degli xk.
Le iterazioni si arrestano quando non si riscontrano cambiamenti apprezzabili.
[166]La sigla pcm sta per Pulse Code Modulation, e trae origine dalla tecnica di quantizzazione di un segnale vocale di qualità telefonica (§ 11.1.2), anche se è stato poi adottato per indicare l’intera gerarchia di multiplazione plesiocrona (§ 24.3.1). Etimologicamente il termine deriva dall’onda pam (§ 7.7.4) in cui degli imPulsi sono Modulati in Ampiezza, mentre in questo caso le ampiezze degli impulsi sono Codificate.
[167]L’andamento esatto della curva segue uno di due standard, denominati legge μ (per USA e Giappone) e legge A (per gli altri), lievemente diverse nella definizione, ma sostanzialmente equivalenti.
[168]Per motivi grafici, nella parte sinistra della figura sono mostrate solo 5 regioni, divise in 4 intervalli.
[169]A prima vista può sembrare ardito accettare che i coefficienti di Fourier (10.74) siano pari ai campioni di segnale xn, ma se proviamo a calcolare
[170]Condizione sufficiente per la convergenza della serie (10.73) è che risulti ∑∞n = −∞|xn| < ∞, in quanto
|X•(f)| = |∑∞n = −∞xn e −j2πfnTc| ≤ ∑∞n = −∞|xn|
[171]Infatti se applichiamo la (10.73) per calcolare X•(f + fc) si ottiene
∑∞n = −∞xn e −j2π(f + fc)nTc = ∑∞n = −∞xn e −j2πfnTce −j2πfcnTc = X•(f)
dato che, essendo fc = 1Tc, risulta e −j2πfcnTc = e −j2πn = 1 per qualsiasi n.
[172]Proprio come ai coefficienti della serie di Fourier per segnali periodici, intervallati di F Hz, corrisponde un segnale periodico nel tempo, di periodo T = 1F.
[173]I chip progettati appositamente per svolgere calcoli di elaborazione numerica del segnale sono detti dsp (Digital Signal Processor), che tipicamente eseguono somme di prodotti; Nel caso di dati multidimensionali, sono invce adottate le GPU nate per scopi di accelerazione grafica, vedi ad es. https://en.wikipedia.org/wiki/Multidimensional_DSP_with_GPU_Acceleration
[174]La (10.75) può essere fatta discendere dalla (10.73) vincolando f ad assumere i soli valori discreti f = mN1Tc, e limitando l’indice della sommatoria ad un insieme finito di campioni, vedi fig. 4.24.
[175]Una prima fonte di approssimazione deriva dall’operazione di finestratura legata all’uso di un numero finito di campioni, operando quindi su xw(t) = x(t)w(tc) anziché su x(t). Per analizzare le altre fonti di approssimazione, iniziamo a scrivere l’espressione di Xw(f) = F{xw(t)} per f = mNfc:
in cui la seconda eguaglianza utilizza l’interpolazione cardinale x(t) = ∑∞n = −∞xn ⋅ sinc(fc(t − nTc)) fornita dalla (10.66), ed introduce una seconda fonte di approssimazione legata all’intervallo finito di variazione per n: infatti, benché l’integrale abbia estensione limitata, i valori di x(t) che cadono entro tale estensione, dovrebbero dipendere da tutti i suoi campioni. L’ultimo integrale è a sua volta una approssimazione (a causa degli estremi di integrazione limitati, e peggiore per i sinc centrati in prossimità dei confini della finestra) della trasformata (calcolata in f = mNfc) di sinc(fc(t − nTc)), pari quest’ultima a Tc rectfc(f)e −j2πfnTc, che quando valutata per f = mNfc, fornisce il risultato Xw⎛⎝f = mNfc⎞⎠ ≃ Tc∑N− 1n = 0xne −j2πmNn per valori |m| ≤ N2, a causa della estensione limitata (in frequenza) di rectfc(f). E’ però facile verificare che Xw⎛⎝mNfc⎞⎠ è periodica in m con periodo N, cosicché i valori assunti per m = N2 + 1, N2 + 2, … sono uguali a quelli per m = − N2 + 1, − N2 + 2, ….
[176]Come osservato al § 4.1.1, lo spettro X•(f) di un segnale campionato a frequenza fc è costituito dalle repliche del segnale originario, distanziate di multipli di fc: X•(f) = ∑∞n = −∞X(f − nfc), e coincide con X(f) per − fc ⁄ 2 < f < fc ⁄ 2, se X(f) è limitata in banda tra ± W ed fc ≥ 2W. Al contrario, se fc < 2W, allora le repliche X(f − nfc) si sovrappongono, e la (10.76) si riscrive come Xm ≃ fcX•⎛⎝f = mNfc⎞⎠.
[177]Il metodo esposto di porre a zero i campioni fino al raggiungimento di una potenza di due è detto zero padding. Il calcolo della DFT su di un numero di punti pari ai campioni di segnale disponibili non avrebbe dato luogo all’effetto finestra, ma avrebbe fornito in tutti i casi andamenti simili a quello osservabile per 256 punti. Infine, notiamo che nelle figure sono mostrati solo i primi 128 valori, essendo i rimanenti speculari.
[178]Con la ovvia condizione che sia M > 2 per rispettare il vincolo fc > 2⁄T
[179]Sostituendo infatti la (10.75) nella (10.78), otteniamo
ma, dato che ∑N− 1m = 0 e j2πmN(n − k) = ⎧⎨⎩N se k = n 0 altrimenti , nella sommatoria esterna sopravvive solo il termine xn, dimostrando l’uguaglianza.
[180]La relazione (10.79) si dimostra combinando le relazioni (10.34) e (10.76):
[181]Il risultato si ottiene ricordando che ∑∞n = 0αn = 11 − α qualora |α| < 1.
[182]Infatti e −j2πm + NNn = e −j2πmNne −j2πn, ed il secondo termine vale 1 per qualsiasi n. Indichiamo qui ed al prossimo §, una sequenza periodica mediante la tilde .̃.
[183]Infatti, sostituendo la (10.83) in (10.84), otteniamo x̃n = 1N∑N− 1k = 0∑∞h = −∞xhe −j2πkNhe j2πkNn. Scambiando ora l’ordine delle sommatorie risulta
x̃n = ∑∞h = −∞xh⎛⎝1N∑N− 1k = 0 e −j2πkN(h − n)⎞⎠
Dato che 1N∑N− 1k = 0 e −j2πkN(h − n) = ⎧⎨⎩ 1 se h = n + rN 0 altrimenti , con r intero, si ottiene il risultato (10.85).
Xm = N − 1⁄2⎲⎳n’ = − N + 1⁄2xn’ − 1⁄2 e −j2πn’2Nm = N − 1⁄2⎲⎳n’ = − N + 1⁄2xn’ − 1⁄2cos⎛⎝2πn’2Nm⎞⎠ − jN − 1⁄2⎲⎳m’ = − N + 1⁄2xn’ − 1⁄2sin⎛⎝2πn’2Nm⎞⎠ = = 2N − 1⁄2⎲⎳n’ = 1⁄2xn’ − 1⁄2cos⎛⎝2πn’2Nm⎞⎠ = 2N− 1⎲⎳n = 0xncos⎛⎝2πn + 1⁄22Nm⎞⎠ = 2N− 1⎲⎳n = 0xncos⎡⎣πN⎛⎝n + 12⎞⎠m⎤⎦
in cui xn’ è quella disegnata per seconda in fig. 4.31. La quarta eguaglianza tiene conto del fatto che il termine immaginario si annulla, in quanto sommatoria bilatera di una funzione dispari (ottenuta come prodotto di xn’ − 1⁄2 pari e sin⎛⎝2πn’2Nm⎞⎠ dispari), e del fatto che essendo i termini coseno pari, la sommatoria può essere ristretta ai soli indici positivi, raddoppiati. La penultima eguaglianza rappresenta il semplice cambio di variabile n = n’ − 1⁄2, mentre l’ultima è (a parte il fattore 2) la definizione della DCT data in (10.86).
[187]Infatti, esprimendo l’integrale di convoluzione x(t) * h(t) nei termini dei campioni di x(t) e h(t) (eq. 10.66), e sfruttando la proprietà di ortogonalità dei segnali sinc(fc(t − kTc)) (vedi § 4.1.2), per i campioni dell’uscita possiamo scrivere
in cui alla seconda uguaglianza si è applicata la formula di ricostruzione cardinalex(t) = ∑∞k = −∞x(kTc) ⋅ sinc(fc(t − kTc)) e dunque h(t − τ) = ∑∞j = −∞h(jTc) ⋅ sinc(fc(t − τ − jTc)), quest’ultima valutata per t = nTc; alla terza uguaglianza si è considerato che sinc(x) è una funzione pari, permettendo di scrivere sinc(fc((n − j)Tc − τ)) = sinc(fc(τ − (n − j)Tc)), ed alla quarta si è applicata la proprietà di ortogonalità tra sinc(fct) traslati di multipli di Tc = 1⁄fc (vedi § 4.1.2), per cui l’integrale vale Tc = 1⁄fc solo quando k = n − j, ovvero j = n − k.
[188]Infatti, ad xn ed hn corrispondono le DFT periodiche X̃m ed H̃m, che hanno per antitrasformata x̃n ed h̃n. Il prodotto X̃mH̃m, espresso in termini di x̃n ed h̃n, risulta pari a Ỹm = X̃mH̃m = ∑N− 1p = 0∑N− 1q = 0x̃ph̃qe −j2πmN(p + q), ed applicando a questo la IDFT (10.78) , otteniamo:
Dato che ∑N− 1m = 0 e j2πmN(n − p − q) = ⎧⎨⎩N se q = (n − p) + lN 0 altrimenti , con l intero, risulta allora ỹn = ∑N− 1p = 0x̃ph̃n − p, come espresso dalla (10.89).
[189]La normalizzazione per Tc discende dalla (10.88)
[190] In effetti, questo è ciò che succede nel caso di modulazione in banda laterale unica o blu, vedi § 12.1.2
[195]Ad esempio, applicando la trasformata di Laplace alle equazioni differenziali che descrivono la relazione ingresso-uscita di un circuito rlc.
[196]Difatti se s = jπ2f la definizione di trasformata di LaplaceH(s) = ∫∞−∞h(t)e − stdt diviene identica a quella di Fourier, ed equivale a calcolare la H(s) lungo l’asse immaginario. Questa equivalenza è valida solo se il filtro è stabile, che nel dominio di Laplace significa richiedere che tutti i poli di H(s) siano a sinistra di tale asse.
[199]La descrizione della maschera in figura avviene nei termini della specifica di
una banda passante f < fp che individua la regione di frequenze da lasciar passare;
il valore percentuale δ1 entro cui H(f) può oscillare nella banda passante;
una banda soppressaf > fs in cui vorremmo che le corrispondenti componenti frequenziali in ingresso fossero attenuate di almeno il δ2% rispetto a quelle della banda passante;
una banda di transizionefs − fp in cui la risposta in frequenza varia;
se sia richiesta o meno al filtro la proprietà di linearità di fase (vedi § 13.1.3).
[201]Un polinomio P(s) = ∑Nj = 0bjsj si azzera per gli N valori s = βj, noti come gli zeri di P(s). Lo stesso polinomio può quindi essere scritto come P(s) = ∏Nj = 1(s − βj), oppure raggruppando gli zeri a coppie (eventualmente coniugate) si ottiene uno sviluppo in termini di secondo grado P(s) = ∏N⁄2j = 1(s2 + cjs + dj) a cui, se N è dispari, va aggiunto un fattore di primo grado.
[202]Tradizionalmente di tipo rlc, oppure realizzata mediante amplificatori differenziali.
[203]Mnemonicamente possiamo ricordare il passa-basso come quello “con il condensatore in basso”; d’altra parte un filtro rc passa-alto presenta la posizione di r e c scambiate, ovvero con cin alto.
[204]Sappiamo che le tensioni ai capi di R e C valgono vR(t)) = R ⋅ i(t) e vC(t) = vu(t) = 1C∫t−∞i(τ)dτ che, trasformate con Fourier forniscono VR(f) = R ⋅ I(f) e Vu(f) = 1C1j2πfI(f). Per la legge di Kirkoff alle maglie si ha Vi(f) = VR(f) + Vu(f) = R ⋅ I(f) + 1j2πfC I(f); la risposta in frequenza sarà pertanto H(f) = Vu(f)Vi(f) = 1j2πfC I(f)R ⋅ I(f) + 1j2πfC I(f) = 11 + j2πfRC.
[208]Ad esempio l’acustica di un ambiente (del bagno di casa, come di un teatro) è il risultato dei contributi legati alle diverse riflessioni dei suoni su pareti ed altri elementi, ognuna più o meno attenuata, e con un diverso ritardo di propagazione tra sorgente e ascoltatore. Un fenomeno simile avviene anche alle onde radio di WiFi e telefonia mobile, vedi § 20.3.3.
[210]Uso questo termine per tradurre il termine taps (rubinetti) utilizzato nei testi inglesi per indicare i coefficienti cn: come se i sommatori in basso in fig. 5.7 raccogliessero l’acqua (o la birra!) spillata dai rubinetti cn, e proveniente dai serbatoi di ritardoT. La cosa buffa è che può accadere di trovare in letteratura riferimenti ai rubinetti o taps come a dei... tappi!
[212]Ricordando i risultati del § 3.8.4, a seguito della finestratura la reale risposta in frequenza risulterà Ĥ(f) = H(f) * W(f). Per questo, si sono individuate alcune finestre migliori della rettangolare, vedi ad es. http://www.labbookpages.co.uk/audio/firWindowing.html. E’ chiaro che adottando invece una finestra rettangolare, la finestratura equivale a calcolare la (10.97) solo per gli indici n necessari; l’effetto di tale troncamento sarà la comparsa di oscillazioni in prossimità della regione di transizione di H(f), del tutto analoghe a quelle evidenziate al § 2.2.2.
[213]In pratica, questa h(t) è quella che dà origine alla h•(t) = h(t) ⋅ ∑Nn = 0δ(t − nT) espressa dalla (10.95), vedi anche nota 169 a pag. 4.4.
[214]A prima vista la realizzazione numerica del passa-banda non sembrerebbe possibile, dato che per ottenere una H•(f) con periodo in frequenza di fc⁄2 come in figura il ritardo T tra i rubinetti dovrebbe essere T = 2⁄fc cioè il doppio del massimo periodo di campionamento Tc = 1⁄fc necessario ad un segnale di ingresso con frequenza massima fc⁄2. Ma in realtà è molto semplice: basta che il filtro fir adotti un ritardo T = Tc = 1⁄fc in modo da soddisfare il requisito per il segnale in ingresso, ma raggruppi i ritardi a due a due, ossia inserisca un rubinetto ogni due ritardi.
[215]In questo caso H(f) risulta a simmetria coniugata (H(f) = H*(−f)), ma è complessa. Pertanto i coefficienti ck ottenibili dalla (10.97) sono reali, ma non necessariamente pari. Svolgendo i calcoli:
Il primo integrale è nullo per k ≠ 0, mentre il secondo per k ≠ 1, in quanto le funzioni integrande hanno media nulla sull’intervallo 1 ⁄ T; pertanto c0 = 1 e c1 = α, esattamente come è definita la (10.99).
[216]Per ogni valore di f, H(f) è pari ad un valore complesso z con H(f) = z = a + jb, e dunque il suo quadrato è pari a |z|2 = a2 + b2, in cui a e b sono le parti reale ed immaginaria di H(f), pari rispettivamente a 1 + αcos2πfT e − αsin2πfT.
[218]Con questa espressione si intende un array lineare di dimensione N ed un puntatore che si incrementa modulo N e che ne indicizza l’ultima posizione. Dopo aver utilizzato l’ultimo campione, questo viene sovrascritto da quello nuovo, ed il puntatore incrementato.
[219]In questo caso si parla di filtro ricorsivo, o filtro infinite impulse response (iir).
[231]E’ sufficiente applicare la definizione H(z) = ∑∞n = −∞hn z − n = ∑∞n = −∞(δn + αδn − 1) z − n = 1 + αz−1, dato che Z{δn} = 1 e che un ritardo di m indici ha trasformata
Z{xn − m} = ∑∞n = −∞xn − m z − n = ∑∞k = −∞xk z − k − m = z−m∑∞k = −∞xk z − k = z−mX(z)
(si è posto n − m = k). In particolare, un ritardo unitario corrisponde al prodotto per z−1 della sequenza trasformata, e dunque Z{δn − 1} = z−1.
[232]Si dicono zeri di un polinomio P(z) = ∑Nk = 0βkzk di grado N le radici z = cn (n = 1, 2, ⋯, N) dell’equazione P(z) = 0. La (10.105) può essere riscritta come H(z) = z−N∑Nk = 0akzN − k = ∑Nk = 0akzN − kzN e dunque si azzera per N(z) = ∑Nk = 0akzN − k = 0, che è un polinomio a potenze positive. Una volta trovate le sue radici cn possiamo scrivere N(z) = a0∏Nn = 1(z − cn) o equivalentemente H(z) = N(z)zN = a0∏Nn = 1(1 − cnz−1).
[234]Ossia una radice del denominatore D(z) di H(z), che scritta come H(z) = zz − α vale D(z) = z − α, e si azzera in z = α.
[235]Il rapporto tra polinomi viene normalizzato in modo da far risultare b0 = 1.
[236]I passaggi iniziano con lo scrivere Y(z)(1 − ∑Nk = 1bkz−k) = X(z)∑Mk = 0akz−k ovvero Y(z) − ∑Nk = 1bkz−kY(z) = ∑Mk = 0akz−kX(z); dato ora che Z− 1{z−kX(z)} = xn − k, si arriva al risultato mostrato.
[238]Per ridurre le possibilità di confusione, adottiamo il pedice a per riferirci al mondo analogico.
[239]Nel senso che alimentando il filtro numerico con i campioni di un segnale si ottiene circa lo stesso risultato che campionando l’uscita del filtro analogico di partenza.
[243]Seppur limitata alla sola corrispondenza per la posizione dei poli, in quanto gli zeri di H(s) non si mappano nel piano z allo stesso modo di come fanno i poli, vedi nota precedente.
[244]Infatti scrivendo s come s = σ + jΩ si ottiene z = esT = eσTejΩT, e dunque i poli dk = σk + jΩk di Ha(s) che giacciono nel semipiano negativo del piano s, ovvero con σk < 0, vengono mappati all’interno del cerchio unitario nel piano z, in quanto ad essi corrispondono poli per H(z) in z = zk = eσkTejΩkT, per i quali |zk| = eσkT < 1.
[249]E’ una proprietà che si applica solamente a filtri la cui risposta impulsiva hn contiene L − 1 elementi nulli tra due non nulli e la cui f.d.t. è quindi esprimibile nella forma H(zL); può essere enunciata come H(zL)(L) = (L)H(z). Per verificarne la veridicità, pensiamo ad un impulso δn che entra in H(zL) producendo in uscita la sequenza h0, 0, ⋯, 0, L − 1 voltehL, ⋯, h2L, ⋯ che, dopo decimazione, diviene h0, hL, h2L, ⋯. Nel caso in cui invece δn attraversi prima il decimatore (L) la sequenza δn non muta, ed il successivo passaggio per H(z) produce nuovamente la stessa h0, hL, h2L, ⋯. Vedi anche http://www.ee.ic.ac.uk/hp/staff/dmb/courses/DSPDF/01100_Multirate.pdf#slide.5
[250]Da non confondere con il filtro di restituzione (§ 4.2.2) che è di natura analogica.
[251]E’ la duale di quella espressa alla nota 249 e come quella si applica a filtri la cui risposta impulsiva hn contiene K − 1 elementi nulli tra due non nulli e la cui f.d.t. è quindi esprimibile nella forma H(zK); consiste nella uguaglianza (K)H(zL) = H(z)(K).
[255]Utile per scrivere la probabilità di un evento come “1 meno” quella dell’evento complementare.
[256]Lanciando un dado, la probabilità Pr(pari ∪ > 2) di ottenere un numero pari, oppure più grande di due, è la somma delle probabilità dei singoli eventi Pr(pari) = 36 e Pr( > 2) = 46, meno quella che si verifichino assieme Pr(pari ∩ > 2) = 26. Pertanto: Pr(pari ∪ > 2) = 36 + 46 − 26 = 56.
La relazione può essere verificata ricorrendo al diagramma in figura, ed interpretando Pr(A ⁄ B) come il rapporto tra la misura di probabilità dell’evento congiunto, rispetto a quella dell’evento condizionante.
[258]Il risultato è pari alla probabilità Pr(A, B) = Pr(pari, > 2) che i due eventi si verifichino contemporaneamente, divisa per la probabilità PR(B) = PR( > 2) che il numero sia >2.
Si rifletta sulla circostanza che la probabilità del pari PR(A) = 12, quella PR(B) = 46, o quella congiunta di entrambi PR(A, B) = 26, sono tutte riferite ad un qualunque lancio di dado, mentre Pr(pari ⁄ > 2) è relativa ad un numero ridotto di lanci, solo quelli che determinano un risultato > 2. Pertanto, essendo Pr(B) ≤ 1, si ottiene Pr(A ⁄ B) ≥ Pr(A, B); infatti per l’esempio del dado si ottiene Pr(pari ⁄ > 2) = Pr(pari, > 2) ⁄ Pr( > 2) = 26 ⁄ 46 = 12, che è maggiore di Pr(pari, > 2) = 13.
Si ottiene invece Pr(A ⁄ B) = Pr(A, B) solo se Pr(B) = 1, ossia se B corrisponde all’unione di tutti gli eventi possibili.
[259]La probabilità marginale di fuori servizio si calcola applicando il teorema delle probabilità totali
Si noti come la probabilità a priori che piova (3 %) venga rimpiazzata dal suo valore a posteriori (23,6 %) grazie alla nuova informazione di cui disponiamo (collegamento fuori servizio). Per una definizione più precisa delle probabilità a priori ed a posteriori si veda il § 17.1.
[260]E’ pari al prodotto delle probabilità marginali, essendo i lanci statisticamente indipendenti, visto che il dado è “senza memoria”. Pertanto il risultato è (16)3 = 1216 ≃ 4.6296 ⋅ 10 − 3.
[261]Anche l’urna è senza memoria, ma non l’esperimento aleatorio, visto che dopo la prima estrazione le biglie restano in 4! Pertanto ora il prodotto delle probabilità marginali risulta 25 ⋅ 14 = 110.
[263]Un esempio classico di v.a. discreta è quello del lancio di un dado, un altro sono i numeri del lotto. Una v.a. continua può essere ad esempio un valore di pressione atmosferica in un luogo, oppure l’attenuazione di una trasmissione radio dovuta a fenomeni atmosferici.
[264]In realtà, l’ordine storico è quello di definire prima FX(x) come la probabilità che X sia non superiore ad un valore x, ovvero FX(x) = Pr{X ≤ x}, e quindi pX(x) = dFX(x)dx. Il motivo di tale “priorità” risiede nel fatto che FX(x) presenta minori “difficoltà analitiche” di definizione (ad esempio presenta solo discontinuità di prima specie, anche con v.a. discrete).
A fianco è mostrata la FD(x) relativa al lancio di un dado: ricordiamo infatti che la derivata di un gradino è un impulso di area pari al dislivello, e dunque applicando la (10.115) alla (10.114) si ottiene il risultato illustrato.
[266]Infatti la probabilità che X cada tra x0 e x0 + Δx vale ∫x0 + Δxx0pX(x)dx ≃ pX(x0)Δx.
[267]Ricavate ad esempio da basi di dati anagrafici, sanitari, meteorologici o quant’altro, oppure effettuando una apposita campagna di misura basata su di un campione statistico di adeguata numerosità (vedi anche § 6.6).
[268]Un esempio di funzione di v.a. potrebbe essere il valore della vincita associata ai 13 in schedina, che dipende dalla v.a. rappresentata dai risultati delle partite, una volta noto il montepremi e le giocate. Infatti, per ogni possibile vettore di risultati, si determina un diverso numero di giocate vincenti, e quindi un diverso modo di suddividere il montepremi. Essendo i risultati improbabili giocati da un ridotto numero di schedine, a queste compete un valore maggiore in caso di vincita, ben superiore al suo valore atteso, indicativo invece della vincita media.
[269]Per insieme ci si riferisce allo spazio campioneΩ, costituito dai possibili valori assunti dalla v.a. X.
[270]In effetti, la E simboleggia la parola Expectation, che è il termine inglese usato per indicare il valore atteso.
Si è preferito usare la notazione E{x}, più compatta rispetto all’indicazione degli integrali coinvolti; i passaggi svolti si giustificano ricordando la proprietà distributiva degli integrali (appunto), ed osservando che il valore atteso di una costante è la costante stessa.
[272]Anziché calcolare σ2X per la pX(x) data, calcoliamo m(2)X per una v.a. uniforme a media nulla, ovvero con mX = 0, sfruttando il fatto che in base alla (10.119) in tal caso risulta m(2)X = σ2X. Si ottiene:
[273]Disponendo di un insieme {xn} di N realizzazioni di una variabile aleatoria X, possiamo effettuare le stime ^mx = 1N∑Nn = 1xne^m(2)x = 1N∑Nn = 1x2n, il cui valore tende asintoticamente a quello delle rispettive medie di insieme, come N (la dimensione del campione statistico) tende a ∞. Al proposito, vedi § 6.6.3.1.
[274]Tanto che la (10.120) è anche detta Normale, e per questo è indicata anche come N(m, σ2).
[275]Questa condizione è anche detta di v.a. indipendenti e identicamente distribuite, ovvero i.i.d.
[276]Il teorema viene dimostrato al§ 6.7.2, ma può essere divertente ed utile sperimentarne la validità ricorrendo alla applet presente presso http://www.randomservices.org/random/apps/DiceExperiment.html Inoltre, considerando che al § 6.2.5 si mostra come la d.d.p. di una somma di v.a. indipendenti sia pari alla convoluzione tra le rispettive d.d.p., osserviamo che la convoluzione ripetuta di una stessa d.d.p. con se stessa, la gaussianizza.
[278]Il termine erfc sta per funzione di errore complementare, e trae origine dai risultati della misura di grandezze fisiche, in cui l’errore di misura, dipendente da cause molteplici, si assume appunto gaussiano. Vedi anche https://it.wikipedia.org/wiki/Funzione_degli_errori.
[279]Ricordando che eα eβ = eα + β possiamo scrivere Φx(ω) = 1√2πσ∫∞−∞e jωx − x22σ2dx; riformuliamo quindi l’esponente jωx − x22σ2 come
avendo effettuato il cambio di variabile y = xσ − jωσ che dà luogo agli stessi estremi di integrazione, mentre dx = σdy, ed avendo notato come l’integrale ora calcoli l’area di una gaussiana con varianza unitaria, pari a ad uno.
[280]Chiaramente, la maggioranza dei segnali trasmessi da apparati di tlc sono di questo tipo.
[281]Per fissare le idee, conduciamo parallelamente al testo un esempio “reale” in cui il processo aleatorio è costituito da.... la selezione musicale svolta da un dj. L’insieme T sarà allora costituito dall’orario di apertura delle discoteche (dalle 22 all’alba ?), mentre in θ faremo ricadere tutte le caratteristiche di variabilità (umore del dj, i dischi che ha in valigia, la discoteca in cui ci troviamo, il giorno della settimana...).
[282]Nell’esempio, x(t0, θ) è il valore di pressione sonora rilevabile ad un determinato istante (es. le 23.30) al variare di θ (qualunque dj, discoteca, giorno...).
[283]Ad esempio, se in tutte le serate il volume aumenta progressivamente nel tempo, la pX(x(tj)) si allargherà per tj crescenti.
[284]x(t, θi) rappresenta, nel nostro esempio, l’intera selezione musicale (detta serata) proposta da un ben preciso dj, in un preciso locale, un giorno ben preciso.
[285]m(2)X(θi) in questo caso rappresenta la potenza media con cui è suonata la musica nella particolare serata θi.
[286]La “serata in discoteca” stazionaria si verifica pertanto se non mutano nel tempo il genere di musica, il volume dell’amplificazione... o meglio se eventuali variazioni in alcune particolari discoteche-realizzazioni sono compensate da variazioni opposte in altrettanti differenti membri del processo.
[287]In questo caso la pX(x(t)) non è nota, oppure non è stazionaria, ma le maggiori applicazioni della proprietà di stazionarietà dipendono solo da mX(t) e m(2)X(t), che possono essere misurati (o per meglio dire stimati, vedi § 6.6.3.1), e risultare stazionari anche se pX(x(t)) non lo è.
[288]Infatti la d.d.p. gaussiana è completamente definita qualora siano noti i valori di media e (co)varianza, vedi §§ 6.2.4 e 6.5.
[289]Questo accade se la selezione musicale di una particolare serata si mantiene costante (es. solo raggamuffin) oppure variata ma in modo omogeneo (es. senza tre “lenti” di fila).
[290]Volendo pertanto giungere alla definizione di una serata ergodica in discoteca, dovremmo eliminare quei casi che, anche se individualmente stazionari, sono decisamente “fuori standard” (tutto metal, solo liscio...).
[291]La (10.127) non è frutto di un calcolo, bensì di un ragionamento: l’impulso gT(t) triangolare non “passa più tempo” su di un valore o su di un altro, ma passa lo stesso tempo su un qualunque valore tra 0 ed A. Pertanto i diversi membri del processo, ognuno relativo ad un diverso θ, qualora valutati ad un medesimo istante t, assumono uno qualsiasi dei valori tra 0 ed A con d.d.p. uniforme.
[292]Verifichiamo per esercizio che il valore (10.128) corrisponda a quello calcolato come media temporale. Calcoliamo innanzitutto l’energia Eg di g(t):
Eg = 2 − T⁄2⌠⌡0[g(t)]2dt = 2 − T⁄2⌠⌡0⎡⎣1 − 2tT⎤⎦2dt = 2 − T⁄2⌠⌡0⎡⎣1 + 4t2T2 − 4tT⎤⎦2dt = = 2⎛⎝T2 + 4T2t33||T⁄20 − 4Tt22||T⁄20⎞⎠ = T + 8T2T33 ⋅ 8 − 8TT22 ⋅ 4 = T + T3 − T = T3
da cui la potenza di x(t) si ottiene come PX = A2Eg⁄T = A23.
[293]In assenza del parametro θ, e considerando la sequenza aleatoria degli an stazionaria ed ergodica, x(t, θ = 0) costituisce un processo ciclostazionario in senso stretto (vedi https://en.wikipedia.org/wiki/Cyclostationary_process), ossia per il quale le medie di insieme di qualsiasi ordine sono periodiche di periodo T. La presenza della v.a. uniforme θ rende x(t, θ) un processo stazionario, ed anche ergodico.
[294]In una futura edizione, potrei calcolare le ddp corrispondenti ai diagrammi ad occhio di fig. 15.23
La dimostrazione segue le medesime linee guida del caso precedente, ed è impostata sulla base della considerazione che la funzione di distribuzione di Y, calcolata in un generico punto ỹ = (ỹ1, ỹ2, …, ỹn), rappresenta la probabilità che Y appartenga alla regione (dominio) delimitata dal punto ỹ, indicata con Dỹ:
FY(ỹ) = Pr{Y ≤ ỹ} = Pr{Y ∈ Dỹ}
Alla stessa regione Dỹ, ne corrisponde una diversa Dx̃ nello spazio X, tale che per ogni valore x◇ ∈ Dx̃ risulti y◇ = F(x◇) ∈ Dỹ. Con queste posizioni, la FY(ỹ) = Pr{Y ∈ Dỹ} si calcola a partire dalla d.d.p. pX(x), integrata sul dominio Dx̃:
[297]Si verifichi per esercizio che nel caso di una coppia di v.a. congiuntamente gaussiane, a media nulla ed uguale varianza, si ottiene l’espressione (14.99) di pag. 1.
[298]Infatti, potendo scrivere xi = ∑nj = 1bjiyj, l’elemento i, j della matrice J risulta pari a jij = ∂xi∂yj = bji.
[299]Infatti risulta (BΣ− 1xB⊤)− 1 = ( B⊤)− 1 ΣxB− 1 che, essendo B− 1 = A, fornisce il risultato per Σy.
[301]Un modello del genere si applica tanto al caso di detezione di un bersaglio radar, che può essere presente o meno, quanto ai casi di una diagnosi medica a partire dai risultati degli esami clinici, a quello di attuare o meno un investimento finanziario a partire dall’andamento delle borse, a quello se prendere o meno l’ombrello prima di uscire di casa a partire dallo scrutare il cielo...
[304]Dall’inglese unbiased, ove con bias si intende una forma di errore sistematico. Diversi testi usano il termine non distorto, che qui non è adottato onde evitare confusioni concettuali con il cap. 8.
[306]Ad esempio, il teorema centrale del limite (§ 6.7.2) fa si che la media campionaria(10.138)^mx = 1N∑Ni = 1xi, in quanto somma di v.a. indipendenti e identicamente distribuite, tenda ad una v.a. gaussiana per N → ∞.
[311]In questo caso riscriviamo m̂x come m̂x = ∑Ni = 1xiN, consideriamo che la varianza di una somma di v.a. i.i.d. è la somma delle varianze (vedi § 7.5.2), e che σ2aX = a2σ2X: pertanto si ottiene σ2m̂x = ∑Ni = 1σ2xN2 = σ2xN.
[312]Occorre innanzitutto riscrivere xi − m̂x come xi − mx + mx − m̂x = (xi − mx) − (m̂x − mx), in modo da ottenere (xi − m̂x)2 = (xi − mx)2 − 2(xi − mx)(m̂x − mx) + (m̂x − mx)2. Eseguendo ora la sommatoria su i si ottiene
[315]Ossia a media nulla e varianza unitaria come a pag. 1, mentre la normalizzazione del § 6.2.4.1 prevede σ2 = 1⁄2.
[316]Anche grazie a fatto che la gaussiana è simmetrica, dando luogo ad intervalli centrati rispetto a θ̂.
[317]Il percentile η per una v.a. gaussiana normalizzataz è definito come il valore zη tale che Pr{z ≤ zη} = η e quindi corrisponde alla inversa zη = F− 1Z(η) della funzione di distribuzione della v.a. FZ(zη) = ∫η−∞1√2πe− 12z2dz = η. Alternativamente, è definito come 1 − Q{zη} = η (vedi pag. 1). Il termine percentile scaturisce dall’essere η ⋅ 100% pari alla percentuale delle volte che una determinazione della v.a. z risulta inferiore a zη.
[321]Vedi https://it.wikipedia.org/wiki/Distribuzione_t_di_Student. La v.a. t = θ̂ − mxσθ̂ è definita come il rapporto di due v.a.: il numeratore θ̂ − mx si comporta come una gaussiana centrata in quanto la media di insieme è una somma di v.a. gaussiane, mentre il denominatore σθ̂ = √σ̂2x⁄N dipende da σ̂2x che è una somma di quadrati di gaussiane, e dunque assume d.d.p. chi quadro o χ2, vedi § 6.6.5.
[322]Oppure dalla tabella presente nella pagina Wikipedia citata prima.
[323]Ad esempio, per la d.d.p. esponenziale (§ 22.2.1) e per quella poissoniana (§ 22.2), vedi Papoulis.
[325]Infatti, calcoliamo prima E{x2} = p ⋅ 12 + (1 − p) ⋅ 02 = p e dunque troviamo σ2x = E{x2} − (E{x})2 = p − p2 = p(1 − p); inoltre, tuttora risulta σ2p̂ = σ2xN.
[326]Effettivamente è richiesto anche un numero di osservazioni ki maggiori di 5-10 per qualunque i; se ciò non fosse vero, è possibile ridurre il numero m degli intervalli Ii, raggruppando tra loro quelli meno popolati.
[327]In realtà essendo ki il numero di casi favorevoli xϵIi rispetto al totale N, esso ha una d.d.p. binomiale (§ 22.1) per la quale mki = Npi e varianza σ2ki = Npi(1 − pi). Al crescere di N, e dunque degli intervalli m, i termini 1 − pi divengono circa unitari, e la binomiale viene approssimata da una poissoniana (§ 22.2), per la quale appunto σ2 = Npi. Tale approssimazione è descritta come test di Pearson, vedi https://it.wikipedia.org/wiki/Test_chi_quadrato_di_Pearson
[332]Al § 7.4 si mostra come l’autocorrelazione Rnn(τ) di un processo n(t) che attraversa un filtro divenga pari a Rνν(τ) = Rnn(τ) * Rhh(τ), in cui Rhh(τ) è l’autocorrelazione della risposta impulsiva del filtro.
in cui la terza eguaglianza è conseguenza della proprietà distributiva dell’integrale (10.117) che definisce il valore atteso, e la quarta discende dal fatto che l’indipendenza statistica implica incorrelazione (§ 7.1.2).
[337]Facciamo uso del prodotto Hermitiano definito come ⟨x, y⟩ = x⊤y = ∑ni = 1xiyi, in cui la sopralineatura rappresenta l’operazione di coniugazione. In generale per matrici e vettori reali risulta ⟨Ax, y⟩ = (Ax)⊤y = x⊤A⊤y = ⟨x, A⊤y⟩, ma se oltre a ciò A è simmetrica si ha A⊤ = A e dunque ⟨Ax, y⟩ = ⟨x, Ay⟩. Indicando ora con λ il coniugato di un autovalore di A (per assurdo) complesso, possiamo scrivere λ⟨x, x⟩ = ⟨λx, x⟩ = ⟨Ax, x⟩ = ⟨x, Ax⟩ = ⟨x, λx⟩ = λ⟨x, x⟩, ma dato che ⟨x, x⟩ è positivo, dovrebbe essere λ = λ, il che è impossibile: dunque tutti gli autovalori sono reali.
[338]Gli autovettori si considerano normalizzati, ovvero γ⊤γ = 1, altrimenti ad uno stesso autovalore ne corrisponderebbero infiniti. Gli autovettori sono inoltre definiti a meno di un termine di fase, dato che se γ è un autovettore, lo è anche γejθ con 0 < θ < 2π.
[340]La prima relazione è conseguenza dell’ortogonalità, la seconda discende dalla prima, e la terza deriva dalla premoltiplicazione di ambo i membri della (10.147) per γ⊤j, che produce ⎧⎨⎩γ⊤iΣxγi = λisei = jγ⊤jΣxγi = 0 sei ≠ j
[341]In quanto det(Σx) = det(Γ)det(Λ)det(Γ⊤), e det(Γ) = det(Γ⊤) = det(Γ− 1) = 1.
[344]Ossia nessuna tra le v.a. xi presenta dipendenza lineare da una o più altre.
[345]Tenendo infatti conto che dalla (10.148) si ottiene Σx = ΓΛΓ⊤, possiamo scrivere Q(c) = c⊤Σxc = c⊤ΓΛΓ⊤c, che ponendo d = Γ⊤c riscriviamo ancora come Q(c) = d⊤Λd = ∑pi = 1λid2i. Se qualche λi fosse negativo o nullo, si potrebbe trovare un vettore d nullo tranne per l’unica componente corrispondente al λi ≤ 0, e produrre una Q(c) ≤ 0, in contrasto con l’ipotesi. Pertanto è vero anche il viceversa, cioè Σx è definita positiva se λi > 0 ∀i.
[348]Il termine correlazione risale a studi sull’ereditarietà genetica, e via via è stato adottato da tutte le discipline (economiche. cliniche, sociologiche...) che analizzano da un punto di vista statistico la dipendenza (co-relazione) tra due o più grandezze, vedi ad es. https://it.wikipedia.org/wiki/Correlazione_(statistica).
[349]Come intuitivamente verificabile pensando m(1, 1)X1X2 come media pesata in probabilità dei possibili valori del prodotto x1x2; i termini di eguale ampiezza e segno opposto possono elidersi se equiprobabili.
[352]I grafici A, D ed F sono realizzati con 100 punti, mentre B, C ed E con 700.
[353]Ovvero ottenuti a partire dal campione statistico, per cui ad es. m̂(1, 1)X1X2 = 1N∑Ni = 1x1(i)x2(i).
[354]Omettiamo per brevità di indicare la variabile aleatoria a pedice della densità di probabilità, così come gli istanti temporali.
[355]Ancora una semplificazione di notazione, da intendersi ricordando che un valore atteso è in realtà un integrale che pesa l’argomento per la rispettiva d.d.p., a cui si applica la proprietà distributiva del prodotto per una somma.
[356]Notiamo immediatamente che il termine più corretto sarebbe “incovarianzate”; l’uso (ormai storico e consolidato) dell’espressione incorrelate deriva probabilmente dal considerare usualmente grandezze a media nulla, per le quali le due espressioni coincidono.
[357]Vedi ad esempio il caso F) di fig. 7.3, in cui le variabili aleatorie risultano incorrelate, ma non sono per nulla indipendenti, dato che le coppie di valori si dispongono su di un cerchio. Ciò rappresenta un caso di dipendenza non lineare, in quanto l’equazione che descrive la circonferenza è quadratica.
[358]In effetti in base alle definizioni date al § 61 risulta ⟨a(t), b(t)⟩ = ∫∞−∞a(t)b*(t)dt in cui è il secondo segnale ad essere coniugato, e non il primo come per la (10.156): dunque quest’ultima espressione corrisponde (in termini di prodotto scalare) a
equivalente alla (10.156) in quanto anziché anticipare y(t), viene ritardato x(t). Si preferisce comunque la definizione (10.156) per la sua somiglianza formale a quella di una convoluzione.
[359]Il risultato (10.157) si basa sul cambio di variabile θ = t + τ che permette di scrivere
[362]Iniziamo con il riscrivere l’espressione Rx(τ) = ∫∞−∞x*(t)x(t + τ)dt operando il cambio di variabile t + τ = α, da cui t = α − τ e dt = dα, ottenendo
[364]In tal caso una stima della densità di potenza può essere ottenuta mediante periodogramma (§ 7.3.1) calcolato su di un segmento di segnale xT(t) di durata T estratto da x(t), e facendo tendere T → ∞, ovvero Px(f) = limT → ∞1T|XT(f)|2. Dato che |XT(f)|2 è proprio la densità di energia ExT(f) di xT(t), per il teorema di Wiener la sua anti-trasformata corrisponde alla funzione di autocorrelazione RxT(τ) = F−1{ExT(f)} di xT(t), come definita dalla (10.155). Operando il passaggio al limite, si ottiene che
corrispondente alla autocorrelazione Rx(τ) dell’intero segnale, come espressa dalla (10.154).
[365]La dimostrazione del caso dei processi viene svolta al § 7.7.3; la sua validità è vincolata a processi per i quali ∫|τ ⋅ m(1, 1)XX(τ)|dτ < ∞, ed è basata sulla considerazione che se la Pθx(f) di un particolare membro θ è valutabile come Pθx(f) = limT → ∞1T|XθT(f)|2, allora la sua media di insieme può scriversi come Px(f) = limT → ∞1TEΘ{|XθT(f)|2}.
[366]Partendo dalla (10.158)Rx(τ) = 1T∫T ⁄ 2 − T ⁄ 2x*(t)x(t + τ)dt possiamo scrivere
Rx(τ) = 1TT ⁄ 2⌠⌡ − T ⁄ 2∞⎲⎳n = −∞X * n e −j2πnFt∞⎲⎳m = −∞Xm e j2πmF(t + τ)dt = = ∞⎲⎳n = −∞∞⎲⎳m = −∞X * nXm1T e j2πmFτT ⁄ 2⌠⌡ − T ⁄ 2 e j2π(m − n)Ftdt = ∞⎲⎳n = −∞|Xn|2 e j2πnFτ
in cui l’ultima uguaglianza è frutto della proprietà di ortogonalità degli esponenziali (2.3).
[367]Infatti le diverse realizzazioni (10.161) al variare di θ differiscono solo per una traslazione temporale, a cui in frequenza corrisponde un termine di fase lineare, che non incide sulla Px(f).
[368]Il risultato si ottiene applicando la (10.160) all’unica armonica presente, e considerando che la potenza totale Px = A22 si distribuisce per metà a frequenza positiva e per metà negativa.
[369]Media mA e varianza σ2A sono qui riferite ai valori multilivello ak (con k = 1, 2, ⋯, L) che un generico simbolo an può assumere, pesati con le rispettive probabilità pk, ossia
mA = ∑Lk = 1pkak e σ2A = ∑Lk = 1pk(ak − mA)2
[370]Un esempio può essere un segnale sonoro, ad esempio una voce recitante, per il quale vogliamo studiare le caratteristiche spettrali dei diversi suoni della lingua (i fonemi), per confrontarle con quelle di un altro individuo, o per ridurre la quantità di dati necessaria a trasmettere il segnale in forma numerica (vedi § 10.1.2), o per realizzare un dispositivo di riconoscimento vocale.
[371]Nel caso contrario in cui x(t, θ) non sia ergodico, la sua densità spettrale può essere definita come Px(f) = limT → ∞E{|XT(f)|2T}.
[372]Per una determinata frequenza f0, il valore PxT(f0) = |XT(f0)|2T è una variabile aleatoria (dipende infatti da θ), il cui valore atteso mT = Eθ{PxT(f0)} vorremmo fosse pari alla vera densità Px(f0)), e la cui varianza σ2T = Eθ{(PxT(f0) − Px(f0))2} vorremmo che diminuisse al crescere di T. Per verificare se tali proprietà siano soddisfatte, valutiamo innanzitutto il valore atteso del periodogramma, a partire dalle relazioni fornite dal teorema di Wiener applicato ad XT(f), e cioè |XT(f)|2 = ExT(f) = F{RxT(τ)}:
Osserviamo quindi come una finestra di segnale rettangolare ne produca una triangolare sull’autocorrelazione. Ma c’è comunque di buono che all’aumentare di T lo stimatore tende al valore vero, dato che limT → ∞T( sinc(fT))2 tende ad un impulso.
[373]Quando il valore atteso di uno stimatore tende al valore vero si dice (vedi § 6.6.3) che lo stimatore è non polarizzato (o unbiased); se poi aumentando la dimensione del campione, la varianza della stima tende a zero, lo stimatore è detto consistente. Ci consola verificare che, come commentato alla nota precedente, per T → ∞ la polarizzazione tende a scomparire, rendendo la stima asintoticamente non polarizzata.
[374]La risoluzione spettrale in questo caso dipende dalla larghezza del lobo principale della densità di energia della funzione finestra applicata a Rx(τ), che nel caso del tri2T(τ) risulta ( sinc(fT))2, il cui lobo principale è appunto ampio 1⁄T. Anche la risoluzione, quindi, migliora all’aumentare di T.
[376]Esistono diverse soluzioni a questo problema, tutte legate ad una riduzione della risoluzione spettrale. La prima è quella di smussare il ^Px(f) ottenuto, mediando i valori su frequenze vicine: tale operazione corrisponde ad un filtraggioin frequenza. Un secondo metodo prevede di suddividere l’intervallo di osservazione in diversi sottointervalli, calcolare il periodogramma su ciascuno di essi, e mediare i risultati.
[377]La quarta uguaglianza sussiste in virtù del teorema di Parseval associato a quello di Wiener, mentre l’ultima è valida se RH(τ) è reale, ossia se h(t) è idealmente realizzabile e dunque reale, vedi il § 1.6.
[378]Tenendo conto della natura lineare e permanente del filtro, l’uscita è la combinazione degli effetti degli ingressi, che per un segnale periodico corrispondono alle armoniche.
[379]Essendo h(t) reale sappiamo che Rh(τ) è reale pari (pag. 1), dunque è sufficiente calcolarla solamente per τ ≥ 0; inoltre, essendo h(t) = 0 per t < 0 l’estremo inferiore di integrazione parte da zero, ottenendo
[381]Infatti in tal caso ∫W − W|H(f)|2df è proprio pari all’energia della h(t); se viceversa W > B una parte di |H(f)|2 cade al di fuori degli estremi di integrazione ( − B, B), e non contribuisce al risultato.
[382]Questo risultato può essere analizzato ricordando che l’integrale di convoluzione calcola i singoli valori in uscita da un filtro, come dipendenti da tutti gli ingressi passati, ognuno pesato con il valore della risposta impulsiva relativo al ritardo tra ingresso passato ed uscita presente (vedi § 3.4.3). Pertanto, anche se i singoli valori in ingresso sono statisticamente indipendenti, quelli di uscita (distanti tra loro per meno della durata della risposta impulsiva) condividono una porzione di storia comune, e quindi i loro valori non sono più incorrelati.
[383]Questo risultato è una diretta conseguenza della proprietà di invarianza dei processi gaussiani rispetto alle trasformazioni lineari discussa al § 6.5.2. Infatti, riscrivendo l’operazione di convoluzione y(t) = ∫x(τ)h(t − τ)dτ in forma approssimata come una somma di infiniti termini y(t) = ∑ix(τi)h(t − τi)Δτi appare evidente come, nel caso in cui x(t) sia un processo gaussiano, l’uscita sia costituita da una combinazione lineare di v.a. gaussiane, e dunque anch’essa gaussiana.
[387]La proprietà di ergodicità congiunta corrisponde a verificare le condizioni ergodiche anche per i momenti misti m(1, 1)XY(x, y) relativi a coppie di valori estratti da realizzazioni di due differenti processi.
[388]Dimostriamo la (10.170) con un ragionamento forse poco ortodosso ma efficace. Dalla definizione di d.d.p. abbiamo che z = x + y risulta compresa tra z e z + dz con probabilità pZ(z)dz, ma affinché ciò accada è necessario che, per ogni possibile valore di x, risulti y = z − x; per l’ipotesi di indipendenza statistica tra x ed y ciò avviene con probabilità congiunta pX(x)dx ⋅ pY(z − x)dz. Per ottenere pZ(z)dz occorre quindi sommare la probabilità congiunta su tutti i possibili valori di x, ovvero pZ(z)dz = ∫ΩXpX(x)pY(z − x)dxdz in cui ΩX è lo spazio campione per la v.a. x. Pertanto in definitiva si ottiene pZ(z) = ∫ΩXpX(x)pY(z − x)dx che corrisponde alla convoluzione espressa nel testo.
[389]Dimostriamo la (10.171) ricorrendo al metodo illustrato al § 6.4.2, scrivendo il sistema (10.134) come ⎧⎨⎩z = xyw = y in modo che la trasformazione inversa risulti ⎧⎨⎩x = z ⁄ wy = w. A questo punto si ottiene la matrice Jacobiana J = ⎡⎢⎣∂x∂z∂x∂w∂y∂z∂y∂w⎤⎥⎦ come ⎡⎢⎣1⁄wz⁄w2 0 1 ⎤⎥⎦ a cui corrisponde il modulo del determinante (jacobiano) |det(J)| = 1|w|. Dunque la d.d.p. congiunta di z e w si ottiene come pZW(z, w) = |det(J)| ⋅ pXY(x, y = f(z, w)) = 1|w| ⋅ pXY⎛⎝zw, w⎞⎠ = 1|w| ⋅ pX⎛⎝zw⎞⎠pY(w) in virtù della indipendenza statistica tra x e y. Non resta quindi che saturare la pZW(z, w) rispetto a w, ovvero pZ(z) = ∫1|w| ⋅ pX⎛⎝zw⎞⎠pY(w)dw, che corrisponde alla (10.171) qualora avessimo posto θ = x anziché w = y.
[390]Si tratta di una stima (vedi § 6.6.3) in quanto l’intervallo di integrazione T è limitato.
[391]Sfruttando le analogie tra integrale di convoluzione e calcolo dell’intercorrelazione, vedi § 7.1.4.
[392]Indicando rispettivamente con Pe0 e Pe1 i due tipi di errore, pari a (vedi fig. 7.16)
Pe0 = ∫∞λpZ(z ⁄ H0)dz e Pe1 = ∫λ−∞pZ(z ⁄ H1)dz
la probabilità di errore complessiva vale Pe = Pe0P0 + Pe1P1, in cui Po = Pr(H0) e P1 = Pr(H1).
[393]Potendo scrivere G * T(f)e −j2πfT = (G(f)e j2πfT)* e ricordando la proprietà (10.41) espressa a pag. 1F−1{X*(f)} = x*(−t), dalla (10.172) otteniamo
[397]Infatti, ora risulta mH1z(T) = E{RG(0) + RGN(0)} = EG + E{RGN(0)} in cui il secondo termine è nullo come già osservato, mentre il primo è un valore certo, pari all’energia EG = RG(0) dell’impulso g(t).
Per ciò che riguarda σ2z(T), osserviamo che zH1(T) = EG + zH0(T), dunque le v.a. centrate sono le stesse, e così la varianza σ2zH1(T) = σ2zH0(T) = N02EG : infatti la componente aleatoria dell’uscita è dovuta al solo n(t).
[398]Il rapporto mH1z(T)⁄σz(T) confronta l’uscita attesamH1z(T) = E{RGHR(0)} di HR per t = T nell’ipotesi H1, che dipende dall’energia mutua tra g(t) ed hR(t), con la sua deviazione standard σz(T) = N02RHR(0) dovuta al rumore.
[399]Consideriamo il caso di avere una HR(f) generica. In presenza di solo segnale, si ottiene
A questa espressione può essere applicata la diseguaglianza di Schwartz (a pag. 1 si enuncia la relazione |∫∞−∞a(θ)b*(θ)dθ|2 ≤ ∫∞−∞|a(θ)|2dθ ⋅ ∫∞−∞|b(θ)|2dθ, con l’eguaglianza solo se a(θ) = k ⋅ b(θ)), qualora si faccia corrispondere HR(f) ad a(θ), e G(f)e j2πfT a b*(θ), ottenendo così
con l’eguaglianza solo se HR(f) = kG*(f)e −j2πfT, ovvero se hR(t) = kg(T − t) (eqq. (10.172) e (10.173)), ossia se HR(f) è adattata a G(f). Scegliendo k = 1, i due integrali a prodotto hanno lo stesso valore, pari a EG, e dunque (mH1z(T))2 = |z(T)|2 = E2G.
[400]In effetti la (10.174) non è adimensionale ma è esprimibile come [sec], dunque non è un vero e proprio SNR, ma dato che il termine rende l’idea, questa accezione è entrata nell’uso comune.
[403]La condizione (10.175) si ottiene anche in questo caso imponendo la massimizzazione di SNR = (mH1z(T))2⁄σ2z(T) = |∫∞−∞Hr(f)G(f)e j2πfTdf|2∫∞−∞|HR(f)|2 PN(f)df il cui denominatore tiene conto che σ2z(T) = ∫∞−∞PZ(f)df è dovuta al solo rumore. Applichiamo ora a SNR la diseguaglianza di Schwartz posta nella forma
e identifichiamo a(θ) con HR(f)√PN(f) e b*(θ) con G(f)e j2πfT⁄√PN(f). Imponendo di nuovo la condizione a(θ) = k ⋅ b(θ) con k = 1, otteniamo il massimo SNR come SNR = ∫∞−∞|b(θ)|2dθ = ∫∞−∞|G(f)|2 PN(f)df, e quindi scrivendo a(θ) = b(θ) ossia HR(f)√PN(f) = G*(f)e −j2πfT⁄√PN(f) si ottiene il risultato (10.175).
[406]Anche se nel caso di banda base il segnale trasmesso è reale, volendo applicare la teoria esposta ad un inviluppo complesso (§ 11.2.1) si rende necessario tener conto dell’operazione di coniugato.
[411]L’analogia non è poi troppo peregrina, considerando che se x è estratta da un processo ergodico a media nulla, la sua varianza σ2x coincide con la potenza del segnale da cui è estratta, mentre se x ed y sono estratte da segnali congiuntamente ergodici, la covarianza σxy coincide con la funzione di intercorrelazione (eq. (10.156)), ovvero con la loro potenza mutua.
[412]Tratta da D. Leon, W. Couch,Fondamenti di telecomunicazioni, 2004 Apogeo
[413]Per quanto riguarda i nuovi estremi di integrazione, osserviamo che se τ = t2 − t, allora per t2 = ±T⁄2, τ vale ± T⁄2 − t. Inoltre, la somma degli esponenti risulta pari a − j2πf(t2 − t) = − j2πfτ.
[414]In tal caso i valori degli an corrispondono ai punti di una costellazione nel piano dell’inviluppo complesso, vedi cap. 16.
[415]Considerando gli an come elementi di una sequenza aleatoria stazionaria ergodica A, con valori ai appartenenti ad un alfabeto finito di cardinalità L, ovvero i = 1, 2, ⋯, L, si definisce per essi
in cui pi rappresenta la probabilità dell’i-esimo valore. Qualora mA = 0, si ottiene σ2A = EA{(ai)2}.
[416]Risultando dθ = − du, gli estremi di integrazione si invertono; quando poi θ = T⁄2 si ha u = t − nT − T⁄2, mentre a θ = − T⁄2 corrisponde u = t − nT + T⁄2.
[417]Se la sequenza an è stazionaria ed a simboli indipendenti, per k ≠ 0 si ottiene
[419]Elaborazione di segnale è la traduzione di signal processing, e così il segnale risultante viene anche detto processato.
[420]Nella pratica, i valori a e τ non si conoscono, mentre invece possiamo disporre di coppie di segnali (x(t), y(t)). Tali valori vengono quindi valutati come quelli che rendono SNR massimo ovvero Pε minimo. Considerando segnali di potenza reali, ossia processi stazionari ergodici, si ha
in cui si è operata la sostituzione E{y(t)x(t − τ)} = Ryx(−τ) = R * xy(τ) = Rxy(τ). Il valore di a che rende minimo Pε(a, τ) si ottiene eguagliandone a zero la derivata: ∂∂a Pε(a, τ) = 2aPx − 2Rxy(τ) = 0 e dunque aopt = Rxy(τ)Px, che sostituita nell’espressione di Pε fornisce
Il valore di Pε evidentemente è minimo per quel valore di τ = τopt che rende massima (Rxy(τ))2, ovvero per quella traslazione temporale che rende “più simili” i segnali di ingresso ed uscita.
[421]Una volta individuati i valori di a e τ, è possibile valutare Pu = E{(ax(t − τ))2} = a2 Px, mentre per Pε è valido il risultato di cui alla precedente nota, fornendo in definitiva
[423]Dunque un decibel, per come è definito, è la decima parte del Bel, ovvero αBel = log10α. Chissà, forse dopo che definirono il Bel, si accorsero che era troppo grande ? :-)
[425]Al cap. 18 verrà approfondita la differenza tra potenza di segnale, espressa in volt2 o ampere2, e potenza assorbita, dissipata o trasmessa, espressa in watt.
[426]Il secondo caso per φh(f) nella (10.204) tiene conto del fatto che la formula di Eulero (10.3) permette di scrivere − 1 = ej±π, ed il prodotto per sgn(f) rende la fase una funzione dispari di f.
[427]Anche se, tenendo conto che un angolo α è indistinguibile da un altro β = α±2π, per convenzione quando |φh(f)| > π, la stessa viene fatta ruotare di 2π.
[430]L’espressione di |H(f)|2 è stata ricavata al § 5.2.3. La fase si ottiene come φ(f) = arctanℑ{H(f)}ℜ{H(f)}, in cui H(f) = 1 + ae −j2πfT.
[431]In questo caso l’uscita sembra precedere l’ingresso, tranne qualora il segnale di ingresso presenti una brusca discontinuità temporale, e quindi non sia più predicibile, In tal caso, l’effetto torna ad essere conseguenza della causa: vedi https://inst.eecs.berkeley.edu/~ee123/sp14/NegativeGroupDelay.pdf
[437]Le relazioni alla nota 436 definiscono i fattori μ2 e μ3 come ⎧⎨⎩μ22≐ PIIP2I = 1G2α22μ23 = PIIIP3I = 1G4β24 da cui si ottengono i valori riportati nel testo, purché sia verificata la condizione β ≪ 4⁄3A2. In caso contrario decade la possibilità di risalire in modo semplice ad α e β a partire dai fattori di intermodulazione, che restano dunque una misura oggettiva (in quanto ottenuti mediante una misurazione) dell’entità della distorsione non lineare.
[439]La valutazione della potenza Pu della componente perfetta in uscita dal canale trasmissivo viene affrontata nella seconda parte del testo, applicando alla potenza Px del segnale in ingresso al canale le relazioni di trasferimento energetico discusse al capitolo 18 e dipendenti dalla tipologia del mezzo trasmissivo, come descritto al capitolo 19.
[440]Infatti al § 7.5.2 si mostra come il risultato della somma di processi indipendenti ed a media nulla abbia potenza pari alla somma delle potenze.
[441]Possiamo pensare che gli elettroni, qualora si trovino in maggior misura in una metà della resistenza, producano una differenza di potenziale negativa in quella direzione. Allo zero assoluto (- 273 oC) il moto caotico degli elettroni cessa, e si annulla così la tensione di rumore. Di qui l’aggettivo termico per descrivere il fenomeno.
[442]Si tratta di una forma della legge di Plank, vedi
[443]Espandendo ex = 1 + x + x22 + x33! + ⋯ si ottiene che per x≪1 risulta ex ≃ 1 + x, e quindi eℏfkT ≃ 1 + ℏfkT. Inoltre per T = T0 = 290 °K si ottiene ℏfkT = 1.65 ⋅ 10 − 13 ⋅ f, e almeno finché f < 50 GHz si ottiene ℏfkT < 0.01 e dunque Pn(f) = 2Rℏf1 + ℏfkT − 1 = 2Rℏf ⋅ kTℏf = 2kTR.
[444]Ovvero rappresentativa delle stadio di uscita del dispositivo o mezzo, a cui è connesso lo stadio di ingresso del ricevitore. L’argomento viene approfondito al cap. 18.
[445]Come sarà illustrato al § 18.1.1, si parla di carico adattato quando il suo valore determina un effetto desiderato, come il massimo trasferimento di potenza in questo caso, o l’assenza di distorsione lineare qualora Zc(f) = αZg(f).
[446]Mentre la potenza di segnale (o a vuoto) è il quadrato di una tensione, quella assorbita dal carico è misurata in Watt, e per questo viene d’ora in poi indicata con W.
[447]Notiamo che lo stesso valore di SNRg è esprimibile anche come rapporto tra le potenze di segnale anziché disponibili: infatti
[448]Si intende dire che il filtro non introduce altro rumore oltre a quello di natura termica. Al § 18.2 sarà illustrato come mediante il fattore di rumoreFdB si possa tenere conto dal rumore introdotto da una o più reti due porte in cascata, sia di tipo passivo come nei collegamenti radio o su rame, sia di tipo attivo come per amplificatori e mixer.
[451]Le permutazioni si definiscono equivalenti se accoppiano con ordine diverso o in posizione diversa le stesse v.a.. Ad esempio, per quattro v.a. si ha
mentre per un momento di ordine 6 si ottengono 15 termini. Se il momento misto coinvolge un numero di v.a. inferiore al suo ordine, come per le (10.215), le permutazioni intendono indicare la posizione di ogni v.a., e non il suo pedice.
[452]Per calcolare il logaritmo in base 2, sussiste la relazione log2α = log10αlog102 ≃ 3.322 ⋅ log10α. O più in generale, log2α = logβαlogβ2
[453]La notazione ⌈α⌉ indica l’intero superiore ad α: ad esempio con L = 10 occorrono M = ⌈log210⌉ = ⌈3.322⌉ = 4 binit/simbolo, come se fosse stato L = 16.
[454]Si noti la differenza: la ridondanza della codifica di sorgente indica la frazione di binit/simbolo che eccedono il valore dell’entropia, mentre la ridondanza della codifica di canale (pag. 1) indica il rapporto tra binit di protezione e quelli di effettivamente emessi dalla sorgente.
[455]Mettere in corrispondenza i diversi simboli di sorgente con una loro codifica binaria è detta codifica per blocchi, discussa al § 9.1.4, dove si mostra anche la possibilità di produrre ogni parola di uscita in corrispondenza non di un unico simbolo di sorgente alla volta, ma come equivalente di più simboli. Raggruppando ad esempio M simboli binari si ottiene una nuova sorgente equivalente con L’ = 2M simboli.
[456]Essendo biunivoca la corrispondenza tra il simbolo xk ed il gruppo di Nk binit, non vi è perdita o aggiunta di informazione.
[458]In effetti la (10.225) sussiste qualora il codificatore non operi indipendentemente su ogni simbolo di sorgente, ma più in generale possa emettere i binit in corrispondenza di sequenze di xkvia via più lunghe. Torneremo su questo aspetto al § 9.1.4, dove il teorema sarà dimostrato.
[459]Ad esempio, un valore η = 0.33 indica che ogni binit trasporta solo 1⁄3 di bit di informazione.
[460]Sebbene la (10.222) esprima la ridondanza come D = 1 − HsM, dopo la codifica i simboli di sorgente sono rappresentati (in media) da N binit anziché M, dunque otteniamo η + D = HsN + 1 − HsN = 1.
Pertanto in entrambi i casi la disuguaglianza di Kraft K ≤ 1 è soddisfatta, e per valori intermedi si ottengono valori intermedi.
[468]Pari al numero di disposizioni con ripetizione di n oggetti estratti dagli elementi di un insieme di cardinalità L. Ad esempio, raggruppando due (n = 2) cifre decimali (L = 10), si ottiene un numero da 0 a 99, ovvero un simbolo ad L2 = 100 valori.
[469]Indicando con y la v.a. aleatoria discreta in uscita dalla sorgente a blocchi, essa risulta di tipo multivariato (§ 6.2.6), le cui le v.a. marginali sono i simboli x emessi dalla sorgente originale. L’indipendenza statistica di questi ultimi consente di scrivere Pr{y} = Pr{x1}Pr{x2}⋯Pr{xn} in cui i valori xi sono quelli dei simboli originali che compongono y. L’entropia Hbloccos della sorgente a blocchi è definita come valore atteso dell’informazione I(y) = − log2Pr(y), e in base alla proprietà del logaritmo di un prodotto possiamo scrivere log2Pr(y) = log2Pr(x1) + log2Pr(x2) + ⋯ + log2Pr(xn), ottenendo cioè che I(y) è pari alla somma dell’informazione legata ad ogni valore x che partecipa a comporre y. Pertanto si ottiene
ovvero l’entropia della sorgente equivalente è esattamente pari alla somma di quella dei simboli che rappresenta.
[470]In realtà, nel caso specifico del fax le cose non stanno esattamente in questi termini: infatti, anziché usare una parola di lunghezza fissa di n binit, l’ITU-T ha definito un apposito codebook http://www.itu.int/rec/T-REC-T.4-199904-S/en che rappresenta un codice di Huffman a lunghezza variabile, in modo da codificare le run length più frequenti con un numero ridotto di bit.
[471]Il lettore più curioso si chiederà a questo punto, come è fatto il predittore. Molto semplicemente, scommette sul prossimo simbolo più probabile, in base alla conoscenza di quelli osservati per ultimi, ed ai parametri del modello markoviano: se il prossimo simbolo viene predetto in base ad una sua probabilità condizionata > 0.5, allora la maggior parte delle volte la predizione sarà corretta, ed il metodo consegue una riduzione di velocità. Nel caso di sorgenti continue, al § 9.5.4 troveremo invece alcune particolarità aggiuntive.
[472]Ad esempio con L = 96 simboli si ha n = 7, ed un dizionario iniziale con 128 posizioni, di cui 96 occupate e 32 libere.
[474]Il realtà il dizionario non viene aggiunto, ma ri-generato durante il processo di decodifica, come illustrato al link di cui alla nota precedente.
[477]In effetti esiste una misura di entropia assoluta per sorgenti continue, che però ha la sgradevole caratteristica di risultare sempre infinita. Infatti, approssimando la (10.234) come limite a cui tende una sommatoria, e suddividendo l’escursione dei valori di x in intervalli uguali Δx, possiamo scrivere
in cui h(x) è proprio la (10.234) mentre h0 = − limΔx → 0log2Δx∫∞−∞p(x)dx = − limΔx → 0log2Δx = ∞. D’altra parte, la differenza tra le entropie assolute di due sorgenti z e x risulta pari a habs(z) − habs(x) = h(z) − h(x) + h0(z) − h0(x), in cui la seconda differenza tende a − log2ΔzΔx che, se z ed x hanno la medesima dinamica, risulta pari a zero.
[479]Vedi anche la trattazione al § 17.1.3 e seguenti nel caso in cui X ed Y siano le grandezze in ingresso ed in uscita da un canale di comunicazione.
[484]Questo limite può essere causato da una insufficiente capacita di canale (§ 17.3), o da una limitata disponibilità di risorse, come ad es. nella archiviazione dei dati in memoria.
[485]La perdita di informazione per messaggi discreti determina la corruzione del messaggio, come la mancanza di parti di testo, di un’immagine, o di un video. Ma nel caso di trasmissione dati si preferisce impiegare più tempo per la trasmissione, piuttosto che perdere informazione.
[486]Al § 17.3 si mostra come la massima intensità di informazione R (associata ad un segnale x(t) di potenza S ricevuto dopo aver attraversato un canale ideale con banda W ed alla cui uscita è presente un rumore n(t) gaussiano bianco di potenza N) non può superare un limite C noto come capacità di canale, pari a C = Wlog2⎛⎝1 + SN⎞⎠ bit per secondo.
[487]Per sorgenti continue d(x̂, x) può ad es. corrispondere ad un valore quadratico medio (o varianza, o potenza) dell’errore di quantizzazione dei suoi campioni (§ 4.1), mentre p(x̂ ⁄ x) dipende dalla caratteristica di quantizzazione f(x) (§ 4.3), e fornisce prob. pari ad uno al valore quantizzato x̂k (o centroide) associato all’intervallo Ik in cui cade il campione x (vedi anche §§ 4.3.2 e 10.1.2.4). Prevedere anche per x̂ un valore probabilistico generalizza sia il concetto che la trattazione.
[491]Ciò è conseguenza del fatto che, come osservato a pag. 1, l’entropia differenziale di una v.a. dipende dal suo valore medio, che in questo caso è X̂.
[492]Ciò deriva dal considerare x = x̂ + e con x̂ ed e v.a. gaussiane statisticamente indipendenti, di varianza rispettivamente e σ2x − D e D: in tali condizioni si ottiene E{(X − X̂)2} = D e I(X;X̂) = 12log2σ2xD.
. ⇒ 22h(X)2πe = Q = limn → ∞( det(Rx))1⁄n. Per la seconda uguaglianza della (10.252), si veda il § 9.6.3.
[497]Vedi https://en.wikipedia.org/wiki/Spectral_flatness, o meglio N.S. Jayant, P. Noll, Digital Coding of Waveforms, 1984 Prentice Hall. Si può mostrare che γ2x può essere interpretato come il rapporto tra la media geometrica e la media aritmetica della densità spettrale di potenza Px(f) del processo x(t) limitato in banda ± W: indicando con Sk = Px(fk), k = 1, 2, ⋯, N, i campioni equispaziati della densità spettrale valutati a frequenze positive fk tra zero e la massima frequenza , si ha
Nel caso di un processo bianco, per il quale i valori Sk sono tutti uguali, le due medie coincidono, e γ2x = 1. Altrimenti, γ2x risulta tanto più piccolo quanto più i valori Sk si discostano dal loro valore medio.
[498]Di questo non viene fornita dimostrazione, di cui trovo indicazione essere presente in T. Berger, Rate distortion theory, Prentice-Hall 1971, che non trovo pubblicamente disponibile in rete.
[499]I risultati indicati sono derivati al § 9.6.4
[500]Infatti la (10.257) può essere riarrangiata come D⁄σ2x = 1 − α1 + α mentre dalla (10.256) si ottiene D⁄σ2x = 2 − 2R(1 − α2); dunque 1 − α1 + α = 2 − 2R(1 − α2) ⇒ 2 − 2R = 1 − α1 + α11 − α2 = 1(1 + α)2 e quindi infine R = − 12log21(1 + α)2 = log2√(1 + α)2 = log2(1 + α)
[502]La matrice Jacobiana J{g(x)} (associata ai vincoli gi(x)) è stata introdotta al 6.4.2, ed essendo la sua i − esima riga riga ottenuta come la sequenza delle derivate parziali ∂gi∂xj, si ottiene impilando i vettori gradiente ∇xgi(x) calcolati per ciascun vincolo.
[508]La trattazione segue quella fornita in N.S. Jayant, P. Noll, Digital Coding of Waveforms, 1984 Prentice Hall.
[509]In base a quanto riportato presso https://en.wikipedia.org/wiki/Szego_limit_theorems il teorema si applica quando gli autovalori sono quelli di una matrice di Toeplitz, i cui elementi sono coefficienti di Fourier di una funzione definita sul cerchio unitario, esattamente come nel nostro caso.
[510]Infatti indicando il secondo membro di (10.261) con α otteniamo limn → ∞ln ⎡⎢⎣∏ni = 1λi⎤⎥⎦1⁄n = limn → ∞ln ( det(Rxx)1⁄n) = α e dunque eα = limn → ∞ det(Rxx)1⁄n
[514]Si applica in pratica la stessa teoria valida per le linee elettriche, in cui al posto di tensione e corrente, ora si considerano rispettivamente pressione p e velocità u
[515]Si tratta di un fenomeno in qualche modo simile a quello che si verifica soffiando in una bottiglia, e producendo un suono che dipende dalla dimensione della stessa.
[516]I diversi suoni vocalici e/o consonantici (detti fonemi) sono prodotti mediante diverse posture articolatorie (la posizione di lingua, mascella e labbra), ovvero diversi profili d’area del tratto vocale, nonché l’attivazione o meno del tratto nasale. Presso https://www.youtube.com/watch?v=6dAEE7FYQfcè mostrato il video di una risonanza magnetica effettuata durante l’eloquio. In definitiva ai diversi fonemi corrispondono differenti frequenze formanti, e dunque una diversa risposta in frequenza.
[519]Una finestra di 10 msec ha durata comparabile con il periodo di pitch, e ciò produce l’effetto a striature verticali del primo diagramma, meno pronunciato verso la fine, dove il pitch è più elevato. Una finestra di 40 msec si estende su più periodi di pitch, e determina una migliore risoluzione in frequenza, cosicché nel diagramma inferiore si possono notare delle striature orizzontali che corrispondono alle armoniche della frequenza di pitch.
[520]Una sillaba può estendere la sua durata tra 10-15 msec per le vocali ridotte, fino a più di 100 msec per quelle accentate.
[521]Sottintendendo una ipotesi di stazionarietà ed ergodicità non vera, ma molto comoda per arrivare ad un risultato.
[522]La (10.265) è effettivamente una stima della autocorrelazione del segnale a durata limitata che ricade nella finestra di analisi, mentre l’inclusione nella sommatoria di un numero di termini pari al numero di campioni disponibili porta ad un diverso tipo di risultato, detto metodo della covarianza, ed un diverso modo di risolvere il sistema (10.266).
[524]In base alle assunzioni adottate, Ryy(j) risulta una funzione pari dell’indice j, e la corrispondente matrice dei coefficienti viene detta di Toeplix, consentendone l’inversione mediante il metodo di Levinson-Durbin (vedi https://en.wikipedia.org/wiki/Levinson_recursion), che presenta una complessità O(n2) anziché O(n3), come sarebbe necessario per invertire la matrice dei coefficienti.
[525]Una breve analisi della relazione tra dft e trasformata zeta è svolta al § 4.5.1, ma vedi anche § 5.3.2.2.
[526]Il pitch varia durante la pronuncia di una frase in accordo alla sua semantica, alla lingua, ed all’enfasi emotiva impressa dal parlatore. Da un punto di vista musicale, la dinamica dei valori (da metà al doppio) si estende quindi su di un intervallo di due ottave. L’intera gamma dei registri dell’opera si differenzia per 22 semitoni, dal Mi2 del basso al Do4 del soprano, ovvero un rapporto di frequenze pari a 3,6.
[527]In realtà prima del calcolo della autocorrelazione il segmento di segnale è stato moltiplicato per una finestra di Hamming, che provoca lo smussamento visibile ai bordi.
[528]In questo modo si evita anche di dover operare una esplicita decisione sonoro/sordo, visto che in realtà le due fonti di eccitazione posso essere presenti contemporaneamente, come per i cosiddetti suoni affricati.
[529]Generato per tentativi, oppure da scegliere in un dizionario di sequenze di eccitazione già codificate.
[530]Il filtro di pesatura percettiva si ottiene a partire dagli stessi coefficienti di predizione ai che descrivono l’andamento spettrale della finestra di segnale, definendo la sua trasformata zeta come W(z) = A(z⁄α1)A(z⁄α2) = H(z⁄α2)H(z⁄α1) in cui, se α1, 2 sono numeri reali, i poli di W(z) si trovano alle stesse frequenze di quelli di H(z) ma con raggio α2 volte maggiore, così come gli zeri di W(z) hanno modulo α1 volte maggiore. Scegliendo 0 < α1, 2 < 1 e α1 > α2 per la W(z) si ottiene l’effetto desiderato, e mostrato in fig. 10.16
[531]La procedura di minimizzazione determina una eccitazione tale da rendere bianco il residuo al suo ingresso; dato però che questo ha subito il filtraggio da parte di W(z), significa che le frequenze attenuate da W(z) sono in realtà enfatizzate nel segnale di errore reale.
[532]In effetti, mentre i coefficienti spettrali (denominati parcor in questo caso) sono determinati a partire dall’analisi dell’intera finestra di 20 msec, l’eccitazione rpe ed i parametri ltp sono ottenuti a partire da sottofinestre di 40 campioni, pari a 5 msec.
[550]Notiamo incidentalmente come le dimensioni definite nella tabella di pag 1 siano multipli interi di 8. Se questo non è il caso, i blocchi ai bordi destro ed inferiore vengono riempiti con pixel scelti in modo da minimizzare le distorsioni risultanti.
[551]Potremmo tentare comunque di estendere le considerazioni svolte al § 4.5.3 al caso bidimensionale...
[552]La nuova sequenza di coppie corrisponde ad una sequenza di coefficienti ac pari a 6 7 0 0 0 3 − 1 0 0 …… 0
[553]Il confronto è svolto considerando i soli valori di luminanza, e la similitudine valutata come media tra i valori assoluti delle differenze di luminanza.
[554]l’effettiva estensione dell’area di ricerca non è oggetto di standardizzazione, mentre lo è la rappresentazione del risultato della ricerca.
[555]Viene decretato il fallimento quando anche la migliore compensazione di movimento possibile non determina una riduzione della quantità di bit, rispetto ad una codifica jpeg.
[557]Il Common Intermediate Format (cif) è stato pensato per facilitare la compatibilità con pal e ntsc; il Quarter-cif ha una superficie di 1⁄4. Sono poi stati anche definiti il 4cif e 16cif, oltre che il sif (352 x 240) che interopera con flussi mpeg.
[558]First in First out, è la disciplina di coda del primo arrivato primo servito, opposta a lifoLast In First Out, realizzata come uno stack.
[559]Nel 1998 viene rilasciato l’H.263v2, noto anche come H.263+ o H.263 1998, e nel 2000 è emesso l’H.263v3 noto anche come H.263++ o H.263 2000; inoltre l’MPEG-4 Part 2 è compatibile con l’H.263, in quanto un bitstream H.263 di base viene correttamente riprodotto da un decodificatore MPEG-4.
[560]Qualcuno potrebbe aver notato che nella definizione degli standard fin qui discussi, non sono previsti controlli di tipo checksum nel bitstream prodotto. D’altra parte essendo le informazioni codificate di natura auto-sincronizzante, la presenza di errori determina presto presso il ricevitore una condizione di disallineamento, e la decodifica di valori non previsti, come ad esempio la ricezione di vettori di movimento o coefficienti dct fuori dinamica, o codeword di Huffman non valide, od un numero eccessivo di coefficienti. Per tale via, il ricevitore diviene in grado di accorgersi che si è verificato un errore.
[564]In realtà pts e dts non sono inseriti in tutti i pacchetti, ma una volta ogni tanto (con intervalli fino a 700 msec per i ps e 100 msec per i ts): il decoder rigenera infatti localmente il clock, ed i timestamp ricevuti servono a mantenerlo al passo con quello trasmesso.
[565]in realtà le intestazioni dei pacchetti del ts possono essere estese e contenere più di 4 byte: in questo caso, la dimensione del payload si riduce, in modo che il totale sia ancora 188.
[566]Un payload vuoto è in realtà comunque riempito di 184 bytes inutili, e viene inserito da parte del multiplatore che realizza il ts per mantenere una riserva di banda che consenta di assecondare le fluttuazioni di velocità dei tributari.
[567]Altri pid riservati sono l’uno, che annuncia la presenza di una Conditional Access Table (cat) contenente i parametri crittografici per visualizzare contenuti a pagamento, ed il pid 18, che annuncia la presenza della Network Information Table (nit), che descrive altri ts disponibili. Per approfondimenti, vedi http://en.wikipedia.org/wiki/Program-specific_information.
[568]Ma non sempre questo impedisce la comunicazione, vedi § 16.9.
[569]Un minimo di approfondimento (per il gsm) può essere trovato al § 26.1...
[570]Un altro fattore rilevante è la limitazione della potenza che è possibile immettere su di un singolo collegamento telefonico e che, associato al precedente, caratterizza il canale telefonico come limitato sia in banda che in potenza, e dunque con capacità (§ 17.3) C = Wlog2⎛⎝1 + PsN0W⎞⎠ dipendente solo dal livello di rumore. La limitazione in potenza è motivata storicamente da problemi di diafonia (pag. 1) dovuti a fenomeni di induzione elettromagnetica, mentre attualmente è determinata dalla limitata dinamica del segnale che viene campionato e trasmesso in forma numerica (§ 4.3.2).
[571]Questo valore massimo nominale determina che la frequenza di campionamento del PCM telefonico è pari a 2*4000 = 8000 campioni al secondo. Utilizzando 8 bit/campione, si ottiene la velocità binaria fb = 64000 campioni/secondo. Velocità inferiori si possono conseguire adottando metodi di codifica di sorgente per il segnale vocale, vedi § 10.1.
[572]L’ibrido telefonico è un trasformatore con quattro porte, che realizza la separazione tra le due vie di comunicazione che viaggiano sullo stesso cavo (vedi § 24.9.1). Nel caso di una linea ISDN, invece, il telefono stesso effettua la conversione numerica, ed i campioni di voce viaggiano nei due sensi (tra utente e centrale) secondo uno schema a divisione di tempo (vedi § 24.9.2).
[573]Nel secolo scorso venne definita una vera e propria gerarchia di multiplazione, i cui livelli detti di gruppo, super gruppo, gruppo master e gruppo jumbo accolgono rispettivamente 12, 60, 600 e 3600 canali voce, per essere trasmessi su doppino, cavo coassiale, o ponte radio. Un approfondimento presso https://www.vialattea.net/content/883/ e https://en.wikipedia.org/wiki/L-carrier.
[574]Antenne più corte di λ hanno una efficienza ridotta, ma sono ancora buone. Altrimenti la radio AM (540 - 1600 KHz) avrebbe bisogno di 3 ⋅ 1081000 ⋅ 103 = 300 metri ! Al § 20.5.3 è riportata una tabella dei valori di λ per i diversi servizi di tlc.
[575]Per brevità, qui e nel seguito adottiamo a volte la notazione 2πf0 = ω0.
[576]Si faccia uso della relazione cos(α + β) = cosαcosβ − sinαsinβ.
[577]Indicata anche come am (amplitude modulation).
[579]Le modalità di sincronizzazione della portante utilizzata al ricevitore rispetto a quella usata in trasmissione sono esposte al § 12.2.1.
[580]Il simbolo rappresenta un filtro passa-basso, poiché viene cancellata l’ondina superiore. Nello stesso stile, possono essere indicati un passa-alto ed un passa-banda .
[581]Si fa uso delle relazioni cos2α = 12(1 + cos2α) e sinαcosα = 12sin2α
[582]Utilizzando stavolta le relazioni sinαcosα = 12sin2α e sin2α = 12(1 − cos2α), ed eseguendo il prodotto − sinω0t[xc(t)cosω0t − xs(t)sinω0t] .
[584]Mostriamo che una matrice di coefficienti della forma ⎛⎜⎝ cosφ − sinφ sinφ cosφ⎞⎟⎠ individua una rotazione.
Esprimiamo infatti un numero complesso x = xc + jxs in forma polare x = ρejα, sussistendo l’uguaglianza xc = ρcosα e xs = ρsinα; con riferimento alla figura, immaginiamo ora che x ruoti in senso antiorario di un angolo (positivo) φ, ottenendo il nuovo numero complesso y = xejφ = ρejα + φ = yc + jys, in cui
ovvero la matrice dei coefficienti corrisponde a quella preannunciata. Alternativamente, le nuove coordinate yc , ys corrispondono a quelle di un vettore fisso, ma riferito ad un sistema di assi ortogonali che ruotano in senso orario dello stesso angolo φ.
[585]Verifichiamo che il prodotto tra le matrici dei coefficienti di (14.10) e (14.11) fornisca la matrice identità
⎛⎜⎝ cos −sin sin cos ⎞⎟⎠⎛⎜⎝ cos sin −sin cos ⎞⎟⎠ = ⎛⎜⎝ cos2 + sin2 cos sin − cos sin − cos sin + cos sin sin2 + cos2⎞⎟⎠ = ⎛⎜⎝ 1 0 0 1 ⎞⎟⎠
[586]Dato che i coefficienti cosω0t, sinω0t del sistema (14.11) sono funzione del tempo, le equazioni relative rappresentano una rotazione oraria di x(t) che “ruota” con velocità angolare ω0, ossia con un angolo ω0t che aumenta linearmente nel tempo. Pertanto le coppie di segnali (xc(t), xs(t)) e (x(t), ^x(t)) rappresentano entrambe l’evoluzione dell’inviluppo complesso x(t) = a(t)e jφ(t): mentre i segnali di banda base xc(t) e xs(t) sono ℜ e ℑ di x(t), i segnali in banda traslata x(t) e ^x(t) sono ℜ e ℑ di x(t)e jω0t, ovvero di x(t)rotante, vedi le eq. (14.4) e (14.10).
[587]Ricordiamo che la somma di due numeri complessi coniugati è pari al doppio della loro parte reale.
[591]L’eguaglianza (14.17) si può dimostrare sia nel dominio del tempo che in quello della frequenza. Partendo dalla prima delle (14.14) si ottiene infatti
Nel dominio della frequenza si applica invece la definizione di filtro di Hilbert (in cui lo sfasamento di ± π2 equivale al prodotto di X(f) per e±jπ2 = ±j) alla trasformata di (14.17), ottenendo
dato che a frequenze negative il prodotto j ⋅ j = − 1 costituisce uno sfasamento di π radianti per tutte le frequenze, provocando l’elisione tra X(f) e -X(f) per tutti i valori f < 0.
[592]Infatti Hfp(f) può essere scritta come Hfp(f) = 12 + 12 sgn(f) = 12(1 + jHH(f)) (vedi eq. (14.25)) , e dunque Hfp(f)X(f) = 12 (X(f) + jX̂(f)), da cui la (14.17).
[593]Scriviamo infatti Ex(f) = |X(f)|2 = X(f)X*(f) da cui otteniamo
Ex(f) = 1⁄4(X(f − f0) + X*( − f − f0))(X*(f − f0) + X( − f − f0)) = = 1⁄4(X(f − f0)X*(f − f0) + X*( − f − f0)X( − f − f0)) = 1⁄4(Ex(f − f0) + Ex( − f − f0))
in quanto i prodotti X(f − f0) ⋅ X( − f − f0) e X*( − f − f0) ⋅ X*(f − f0) sono nulli, dato che in entrambi i casi i fattori risiedono in regioni di frequenza disgiunte,
[594]La (14.20) può essere motivata seguendo le stesse linee guida indicate alla nota 364 a pag. 7.2.
[595]Approfittiamo dell’occasione per notare che, pur potendo scrivere X(f) = Xc(f) + jXs(f), non è assolutamente lecito dire che ℜ{X(f)} = Xc(f) e ℑ{X(f)} = Xs(f); infatti sia Xc(f) che Xs(f) possono a loro volta essere complessi (mentre xc(t) e xs(t) sono necessariamente reali).
[596]In realtà si ottiene Rxcxs(τ) = 0 ogni volta che Px(f) ha simmetria pari rispetto ad f0.
H{x(t) = x0} = 0: una costante ha trasformata di Hilbert nulla, e la trasformata di Hilbert è definita a meno di una costante. Il valore medio di x(t) non si ripercuote su ^x(t);
H{H{x(t)}} = ^^x(t) = − x(t): infatti una rotazione di fase pari a π radianti per tutte le frequenze è equivalente ad una inversione di segno;
∫∞−∞x(t)^x(t)dt = 0: ortogonalità tra un segnale e la sua trasformata di Hilbert;
H{x(t) * h(t)} = ^x(t) * h(t) = x(t) * ^h(t): la trasformata di Hilbert di una convoluzione (cioè dell’uscita di un filtro) è la convoluzione tra un operando trasformato e l’altro no.
[598]Come illustrato al § 6.3.7, il processo risultante diviene ergodico qualora al coseno sia aggiunta una fase aleatoria uniformemente distribuita.
[599]Infatti (eq. (14.33)) Rxcxs(τ) = ^Rx(τ)cosω0τ − Rx(τ)sinω0τ, in cui Rx(τ) = F−1{ Px(f)} è pari e sinω0t è dispari, mentre ^Rx(τ) è dispari (non è stato dimostrato, ma vale per le trasformate di Hilbert di segnali pari) e cosω0τ è pari. Inoltre, essendo xc(t) ed xs(t) reali, Rxcxs(τ) è reale.
[600]Per i segnali numerici si usano tecniche peculiari, esposte al capitolo 16.
[601]Qualora xc(t) e xs(t) siano due segnali indipendenti, la forma di modulazione di ampiezza risultante viene detta segnale qam (quadrature amplitude modulation), vedi § 16.3.
[602]Come sarà più chiaro nel seguito, l’acronimo vsb evoca il fatto che, anziché sopprimere completamente una delle due bande laterali, se ne mantengono delle vestigia.
[603]Considerando che la portante del segnale ricevuto può avere una fase arbitraria, e che con una traslazione temporale ci si può sempre ricondurre ad usare una funzione cosω0t, tale convenzione individua il caso più generale di un segnale modulato del tipo x(t) = a(t)cos(ωot + φ) con φ costante. Infatti, introducendo un ritardo τ = φ2πfo si ottiene x(t − τ) = a(t − τ)cos(2πf0(t − τ) + φ) = a(t − τ)cos(2πf0t).
D’altra parte, risultando a(t)cos(ωot + φ) = a(t)(cos(ωot)cosφ − sin(ωot)sinφ) si ottiene che la presenza di una fase incognita φ determina la ricezione di un segnale modulato le cui c.a. di b.f. risultano pari a xc(t) = a(t)cosφ e xs(t) = a(t)sinφ, e che quindi variano in simultanea. Pertanto, in base ai risultati del § 13.1.2.4, il segnale modulato equivale a quello in cui è presente la sola componente in fase xc(t), ma al quale un errore nella fase di demodulazione imprime una rotazione di angolo φ al piano dell’inviluppo complesso.
[604]Cioè che non dipende dal messaggio modulante m(t).
[606]Il segnale PI(t) = m2(t) può essere indicato come potenza istantanea di m(t), e PMaxI indicato come la sua potenza di picco.
[607]Ad esempio, nel caso in cui m(t) sia un processo con densità di probabilità uniforme tra ± Δ2, la potenza di picco risulta essere Δ24 = 3σ2M, dato che (come mostrato al § 6.2.3) in quel caso risulta σ2M = Δ212; se invece m(t) = asin2πfMt, allora si ha una potenza di picco a2 = 2σ2M (dato che PM = σ2M = a22). Oppure ancora, se m(t) è gaussiano la potenza di picco (e dunque a2P ⁄ k2a per ottenere la portante intera) risulta infinita. E cosa accade allora? Si avrà necessariamente una portante ridotta...
[608]Nel caso ad esempio di ampie zone di immagine uniformi ed a luminosità costante, il segnale è praticamente costante.
[609]Il dispositivo fisico che effettua la moltiplicazione per una portante viene indicato in letteratura con il termine di mixer, il cui significato letterale è mescolatore. Dato che lo stesso termine è usato anche per indicare un circuito od apparato in grado di realizzare la somma di più segnali, come ad esempio avviene per il mixer audio di un sistema di amplificazione sonora, per distinguere i due casi si può parlare di mixer additivo oppure moltiplicativo, come nel nostro caso. In appendice 12.4.1 sono illustrate due tecniche di realizzazione del mixer.
[610]Dato che un qualunque canale presenta un ritardo di propagazione τ, la portante del segnale ricevuto sarà nella forma cos2πf0(t − τ) = cos(2πf0t − 2πf0τ) = cos(2πf0t − φ), ovvero sarà sempre presente una fase φ = 2πf0τincognita. Nel caso poi di un collegamento radiomobile, può anche essere presente un errore di frequenza, dovuto all’effetto doppler., vedi § 20.4.6.
[611]Le ultime due definizioni sono orientate a differenziarsi dal metodo di demodulazione eterodina, che in realtà si è affermato prima della praticabilità di quello omodina, per i motivi esposti al § 12.2.7.
[612]Realizzato mediante un amplificatore ad elevato guadagno, portato a lavorare in saturazione.
[616]Se ad esempio ε(τ) = Δ⁄kf ossia è costante, si ottiene y(t) = sin(2πf0t + 2πΔt) = sin[2π(f0 + Δ)t], ovvero la frequenza si è alterata di una quantità pari a Δ. Infatti, il vco realizza il processo di modulazione di frequenza, vedi eq. (14.7) a pag. 1.
[617]Un diverso circuito controreazionato in grado di operare anche per segnali a portante soppressa prende il nome di Costas loop, vedi https://en.wikipedia.org/wiki/Costas_loop, mentre al § 16.11.1 si discute di una realizzazione relativa ad una trasmissione a spettro espanso.
[618]Trascuriamo la presenza di eventuali modulazioni, il cui effetto si intende mediato dalla caratteristica passa-basso del pll, dovuta sia all’integratore presente nel vco, che al filtro di loop.
[619]Utilizziamo qui la relazione cosαsinβ = 12[sin(α + β) + sin(α − β)].
[620]La grandezza di controllo ε(t) proporzionale a sin(Δθ) si azzera per Δθ = kπ con k intero, positivo o negativo. Per kdispari si hanno condizioni di instabilità, in quanto ad es. per Δθ che aumenta o diminuisce rispetto a Δθ = π, il segno di ε è rispettivamente negativo e positivo, causando un ulteriore ritardo o aumento di ^θ(t) che causa un ulteriore aumento o diminuzione di Δθ, finché questo non raggiunge il valore 0 o 2π, corrispondenti a condizioni di stabilità. In altre parole, se |Δθ| < π si determina un transitorio alla fine del quale ε → 0, mentre se π < |Δθ| < 3π il transitorio converge verso ε → 2π, e così via.
[621]Notiamo che un moltiplicatore, seguito da un filtro passabasso, esegue il calcolo dell’intercorrelazione tra gli ingressi del moltiplicatore (vedi § 7.5.4), che nel nostro caso è una sinusoide.
[622]Inoltre, le prestazioni del PLL dipendono fortemente anche dalla banda e dall’ordine del filtro di loop, che limita la velocità di variazione di ε(t) e l’estensione dell’intervallo di aggancio. Lo studio teorico si basa sull’uso della trasformata di Laplace e sulla approssimazione sin(Δθ) ≃ Δθ, in quanto così il PLL può essere studiato come un sistema di controllo linearizzato, sommariamente descritto al § 12.3.2.1. Per approfondimenti, vedi http://it.wikipedia.org/wiki/Phase-locked_loop.
Anche qui i filtri passabasso eliminano le componenti centrate a 2f0, permettendo di ottenere la (14.47).
[625]La ricerca dell’emittente può essere l’azione banale di sintonizzare a mano la propria radio sul programma preferito, oppure (come si dice, in modalità ricercaautomatica), mediante un circuito del tipo di cui stiamo discutendo, con il quale vengono provate diverse portanti di demodulazione, finché non si riscontra un segnale in uscita.
In generale, la ricezione della comunicazione vera e propria viene preceduta da una fase di acquisizione della portante, svolta ad esempio come qui accennato, dopodiché la sincronizzazione è mantenuta mediante interventi automatici (ad es. via pll), necessari qualora si tratti di dover compensare le variazioni di frequenza dovute ad esempio al movimento reciproco di trasmettitore e ricevitore (effetto doppler), come per il caso delle comunicazioni con mezzi mobili, vedi § 20.4.6.
[626]Il simbolo rappresenta un diodo, costituito da un bipolo di materiale semiconduttore drogato, che ha la particolarità di condurre in un solo verso (quello della freccia).
[628]Si può dimostrare che per l’inviluppo complesso H(f) di H(f) deve risultare: H(f) + H*(−f) = cost perché in tal modo il residuo di banda parzialmente soppressa si combina esattamente con ciò che manca alla banda laterale non soppressa.
[632]A causa di fenomeni di induzione elettromagnetica che si manifestano tra conduttori presenti all’interno del circuito di demodulazione (che perdipiù aumentano con il valore delle frequenze in gioco) la portante di demodulazione omodina può appunto rientrare nella via percorsa dal segnale modulato. Se in ingresso al mixer è presente, oltre al segnale da demodulare a portante soppressa, anche un termine alla stessa frequenza portante, si verifica un fenomeno noto come self-mixing dovuto all’eguaglianza cos2α = 1⁄2(1 + cos2α) che determina la comparsa di un termine in continua, e che non può essere eliminato mediante filtraggio passa alto qualora il segnale modulato presenti componenti energetiche prossime a frequenza zero. Lo stadio di amplificazione successivo mantiene un funzionamento lineare solo per valori di ingresso compresi in uno specifico intervallo, come discusso al § 8.3, mentre il valore medio ora presente può portare il segnale di ingresso al difuori di tale dinamica.
[633]Le difficoltà nascono sia dall’esigenza di accordare il filtro attorno alla frequenza portante desiderata, sia dalla necessità di attenuare sufficientemente le trasmissioni che avvengono su frequenze limitrofe, determinando la necessità di realizzare un filtro con regione di transizione molto ripida, problema che può divenire insormontabile se il rapporto tra banda del segnale e portante (la cosiddetta banda frazionaria) è particolarmente ridotto.
[634]Il prefisso super venne scelto come contrazione di supersonic heterodyne, e dato che agli inizi del ’900 di certo non esistevano aerei supersonici, indicava il concetto di sopra i suoni, in contrapposizione al suo uso originario di traslare il segnale radiotelegrafico in banda audio.
[636]Il valore della frequenza intermedia utilizzata per le diverse bande in cui operano sistemi di radio diffusione è determinato in seno ad enti di standardizzazione, e le autorità di concessione della licenza di trasmissione evitano di assegnare alle emittenti frequenze nella stessa banda in cui è prevista l’uso di una frequenza intermedia, allo scopo di impedire interferenze nella medesima banda da parte di una diversa trasmissione. Oltre alla MF a 455 KHz del broadcast AM, abbiamo ad esempio valori di media frequenza pari a 10.7 MHz per il broadcast FM, 38.9 MHz per la televisione, 70 MHz per trasmissioni a microonde terrestri e satellitari.
[637]Nel caso di trasmissione a portante intera lo stadio eterodina finale viene rimpiazzato da un demodulatore inviluppo, oppure ancora da un demodulatore in fase e quadratura per gli usi più generali.
[638]Vedi ad es. il caso di un trasponder satellitare, § 25.3.3
[639]Si fa qui uso della espansione in serie di potenze dell’esponenziale: ex = 1 + x + x22 + x33! + ....
[640]Un altro caso di multiplex fdm è quello del downlink di un trasponder dvb-s, introdotto al § 25.3
[641]Ricordiamo che arctan2 restituisce un angolo compreso nell’intervallo ( − π, π) anziché ( − π⁄2, π⁄2).
[643]La derivata di cos[α(t)] è pari a − sin[α(t)] ⋅ α’(t), ma il segno − è ininfluente ai fini dell’elaborazione successiva.
[644]L’utilizzo del demodulatore inviluppo è possibile solo nel caso di una modulazione a portante intera, ovvero per cui f0kf + m(t) > 0 per ∀t, e dunque è necessario che risulti kf < f0maxt{|m(t)|}.
[645]Da un lato, a22 è banalmente la potenza della portante di ampiezza a. Da una altro punto vista, lo stesso risultato si ottiene a partire dalla Px(f) = 14( Px(f − f0) + Px( − f − f0)) (eq. 14.20), da cui mediante integrazione in frequenza otteniamo Px = 142 Px = a22.
[646]Si è sostituito cos con sin nel caso pm per omogeneità di formulazione, senza alterare la sostanza delle cose.
[647]Le funzioni di Bessel del primo tipo, ordine n ed argomento β sono definite come Jn(β) = 12π∫π − πe j(βsinx − nx)dx, riconducibili alla (14.53) mediante un cambio di variabile.
[652]Nel caso di modulazione sinusoidale ad alto indice la (14.56) esprime la banda entro cui è contenuto il 98% della potenza del segnale modulato. Per indici 2 < β < 10 ne fornisce invece una stima per difetto, ed una approssimazione più corretta è BC ≃ 2w(β + 2).
[653]Sinceramente non ho afferrato appieno il motivo di questa limitazione. Quel che ho trovato esprime che “ciò equivale ad avere Δf ≫ W, e quindi comporta il rispetto di una condizione detta approssimazione quasi stazionaria” e fa riferimento ad uno studio di H.E. Rowe del 1965. La tesi è che in tal caso la frequenza istantanea varia lentamente rispetto al periodo 1⁄W della massima frequenza modulante, e dunque il segnale modulato osservato per un breve periodo è approssimato ad una sinusoide non modulata ed a frequenza costante pari a fi(t) = f0 + kfγ in cui γ è il valore di m(t) praticamente costante nel periodo di osservazione. A me sembra che perché ciò avvenga, sia sufficiente che f0≫Δf. Ma forse lo capirò con il tempo.
[654]Volendo applicare la regola di Carson per calcolare la banda, si avrebbe (considerando β≫1) BC = 2W(β + 1) ≃ 2ΔfWW = 2Δf, in cui Δf = kfΔM2. Pertanto risulta BC = 2kfΔM2 = kfΔM, in accordo al risultato previsto nel caso di modulazione ad alto indice.
Qualora si fosse invece posto β = σfW (vedi 12.3.3.4) si sarebbe ottenuto BC = 2W(β + 1) ≃ 2σfWW = 2σf = 2kf√PM = 2kf√Δ2M12 = 2kfΔM2√3 = ΔMkf√3, un risultato che è circa pari a 0.58 volte quello precedente. Data le particolarità di pM(m) uniforme, in questo caso è da preferire il primo risultato.
[655]Infatti, dalla definizione fi(t) = f0 + kfm(t) si ottiene che σ2f = k2fσ2M, in cui σ2M = PM se m(t) è un processo stazionario ergodico a media nulla.
[656]Come sopra, partendo dalla relazione α(t) = kφm(t).
[658]Infatti la formula di de Moivre asserisce che (cosα + jsinα)n = cosnα + jsinnα, come confermato anche dalla formula di Eulero (cosα + jsinα)n = (e jα)n = ejnα = cosnα + jsinnα.
[660]La (14.57) si ottiene applicando l’espressione per i coefficienti Yn dello sviluppo in serie di y(t) in funzione dei campioni della trasformata di un suo periodo G(f)|f = n⁄T data dalla (10.34) ovvero Yn = 1TG⎛⎝nT⎞⎠, a quella Py(f) = ∑∞n = −∞|Yn|2δ(f − n⁄T) fornita dalla (10.160) per la densità di potenza di un segnale periodico.
[661]Infatti in base alla § 7.5.3 ad un prodotto tra processi statisticamente indipendenti corrisponde la convoluzione in frequenza delle relative densità spettrali, e la (14.58) è conseguenza della convoluzione con gli impulsi presenti nella (14.57).
[662]Dato che G(f) si annulla per f = m⁄τ, se scegliessimo τ = 1⁄hf0 avremmo G(f) = 0 per f = mhf0 impedendo il funzionamento del circuito per qualche armonica di f0 ⁄ k. In particolare, scegliendo h = 1 lo schema sarebbe del tutto inutilizzabile!
[666]Abbreviazione di parti per milione: 10 ppm equivalgono a 10 cicli ogni 106, ovvero un valore compreso tra 999.990 ed 1.000.010 per una frequenza nominale di 1 MHz.
[669]Infatti risulta ∫∞−∞X+(f)X−(f)df = 0. dato che i due termini non si sovrappongono in frequenza.
[670]Per dimostrare il risultato, mostriamo innanzitutto che il segnale analitico in uscita vale y+(t) = x+(t) * h+(t). Infatti, omettendo di indicare nei passaggi la variabile (t) per compattezza di notazione, risulta
in cui hfp(t) è la risposta impulsiva del filtro necessario ad estrarre il segnale analitico. Non resta ora che mostrare lo sviluppo per il risultato anticipato:
[671]Tralasciamo di indicare la dipendenza da t per semplicità di notazione.
[672]Una considerazione del tutto simile può essere svolta qualora sia l’inviluppo complesso del segnale modulatox(t) ad essere solo reale od immaginario, ma viene rimandata al § 13.2.
[673]Come già evidenziato al § 18.4 è preferibile realizzare l’equalizzazione operando sulle c.a. di b.f. xc(t) e xs(t)da trasmettere, in modo da evitare di rendere colorato il rumore in ingresso al ricevitore. Nel caso in cui hc(t) non sia nota, occorre che presso il ricevitore venga effettuata una sua stima, vedi § 18.4.
[675]La (14.76) si ottiene considerando W abbastanza elevato da poter assimilare 2W sinc(2Wt) → δ(t) ossia ad un impulso, in modo che la (14.67) produca y(t) = 12x(t)*2δ(t − τ) = xc(t − τ) + jxs(t − τ).
[676]Il termine tra parentesi quadre in (14.77) ha anti-trasformata
ma il termine e −j2πfτ presente in (14.77) produce un ritardo nell’antitrasformata, dunque il risultato (14.78)
[677]L’analisi che interpreta la trasformazione legata ad un sistema lineare con matrice dei coefficienti pari a cosφ − sinφ sinφ cosφ come una rotazione è stata svolta alla nota 584 di pag. 11.2.
[678]Condizione indicata anche come piccola banda frazionale, definita come B⁄f0≪1.
[679]Detta anche condizione per un fading piatto nel caso di un collegamento radio, vedi pag. 1, mentre dal punto di vista circuitale ciò corrisponde a realizzare le condizioni di adattamento di impedenza (vedi § 18.1.1.4) in forma approssimata, ponendo Zg(f) = Zi(f0) e Zc(f) = Zu(f0), dato che per frequenze |f − f0| < B2 con B ≪ f0, le impedenze Zi(f) e Zu(f) non variano di molto.
[681]Ovvero i coefficienti dello sviluppo in serie della caratteristica ingresso-uscita, vedi nota 434 a pag. 1.
[682]Infatti, ricordando le definizioni (§ 8.2.2) tp(f) = − φ(f)2πf per il ritardo della portante e tg(f) = − 12πddfφ(f) per il ritardo di gruppo, sussistono i passaggi
[684]Il pedice RF sta per radio frequency ed indica l’occupazione di banda a frequenze positive di un segnale modulato.
[685]Infatti i segnali xc(t)cosω0t e xs(t)sinω0t risultano ortogonali, e le potenze si sommano. Volendo sviluppare i calcoli, possiamo valutare Px come
Possiamo ora aggiungere ad entrambe le portanti una fase aleatoria uniforme in modo da renderle anch’esse processi, indipendenti da xc(t) ed xs(t). Al § 7.5.3 si è mostrato che il prodotto di processi indipendenti ed a media nulla ha potenza pari al prodotto delle potenze, e dunque i primi due termini sono rispettivamente pari a 12 Pxc e 12 Pxv. Per quanto riguarda il terzo termine, esso rappresenta il valore atteso del prodotto di processi indipendenti ed a media nulla, e dunque è nullo. Infine, sviluppando i calcoli a partire dalle medie temporali anziché di insieme si perviene al medesimo risultato.
[686]La tabella estende quella al § 12.1.4, rispetto alla quale si considera il termine ka ora inglobato in m(t).
[687]Riprendendo l’approccio adottato alla nota 685, consideriamo le portanti in fase e quadratura come realizzazioni di un processo armonico con potenza 1⁄2, moltiplicate per un processo statisticamente indipendente m(t)⁄√2 con potenza Pm⁄2. La potenza di ciascuna c.a. di b.f. è il prodotto di queste due, e dunque partendo dalla (14.92)
[688]Infatti, considerando nuovamente la portante in fase come un processo armonico indipendente da m(t) possiamo scrivere Px = η(a2p + Pm) ⋅ 1⁄2 = 1⁄2 ⋅ Pm dato che E{(ap + m(t))2} = a2p + Pm, in quanto E{ap ⋅ m(t)} = 0 qualora m(t) sia a media nulla.
[689]Con questa posizione, la potenza della portante risulta (√2 Px)22 = 2 Px2 = Px.
[690]Si veda il § 14.4.1 per una analisi più approfondita degli aspetti statistici della questione, che portano a definire ρ = |r(t)| una v.a. di Rice.
[691]Si noti che le potenze σ2νc e σ2νs delle c.a. di b.f. del rumore in ingresso al discriminatore sono invece relative alla banda BN, ≥ di quella BRF del segnale modulato.
[692]Dato che gli operatori di derivata ed integrale si annullano, ovvero Psd = Pot⎧⎩12πkfddtα(t)⎫⎭ = Pot⎧⎩12πkfddt2πkf∫t−∞m(τ)dτ⎫⎭ = Pot{m(t)} = Pm. In definitiva, abbiamo semplicemente demodulato!
[693]Infatti, il rapporto σfdW definito al § 12.3.3.4 come indice di modulazioneβp, rappresenta appunto una misura del rapporto tra l’occupazione di banda efficace del segnale modulato, e la massima frequenza W presente nel segnale modulante.
[694]Miglioramento che può essere sfruttato quando ad esempio il collegamento è di tipo punto-punto, come nel caso di un ponte radio con antenne direttive od una comunicazione satellitare, in modo da contenere la potenza irradiata entro il cono di emissione e non invadere lo spettro radio riservato ad altre trasmissioni.
[695]L’effetto soglia interviene prima per i valori di β più elevati, vedi fig. 14.13-b.
[696]Ovvero (§ 14.1.3) x(t) e y(t) sono processi congiuntamente gaussiani ed incorrelati con media nulla e varianza σ2 = N0BN.
[697]Vedi anche il § 6.5.1. Basta moltiplicare: pX(x)pY(y) = 1√2πσexp⎛⎝ − x22σ2⎞⎠ ⋅ 1√2πσexp⎛⎝ − y22σ2⎞⎠
[708]Un modo di ricondursi a questo caso è quello di diminuire la banda del filtro di ingresso, riducendo così σ2 = N0BN. In questo modo però, come osservato a pag. 354, si riduce l’intervallo di frequenza Δf che può essere analizzato.
[710]O equivalentemente, della distanza che è possibile coprire conoscendo la potenza trasmessa, e quella che è necessario ricevere.
[711]Ovvero lascia passare solo frequenze comprese in un intervallo che non comprende l’origine.
[712]Indichiamo Ts come periodo di simbolo, mentre il suo inverso fs = 1 ⁄ Ts è detto frequenza di simbolo, baud-rate o frequenza di segnalazione, e si misura in simboli/secondo, unità di misura indicata anche come baud, in memoria di Émile Baudot, vedi http://it.wikipedia.org/wiki/Codice_Baudot.
[713]Se non fosse preso questo provvedimento, e si trasmettesse un segnale con una occupazione spettrale maggiore della banda passante del canale, nel segnale ricevuto verrebbero a mancare alcune componenti frequenziali, e di conseguenza la forma d’onda del segnale risulterebbe modificata, causando così il fenomeno di interferenza tra simboli (vedi § 15.1.2.2).
[714]Sembra giusto sottolineare che questo campionamento non ha lo scopo discusso al cap. 4, ma si tratta piuttosto qualcosa di più simile al filtro adattato (§ 7.6), che decide in base al superamento di una soglia. D’altra parte, mentre la decisione operata dal quantizzatore introduce un errore, quella del ricevitore numerico discrimina tra informazioni già discrete.
[715]Oppure mediante una seconda linea di trasmissione.
[716]Se L risulta essere una potenza di due ovvero L = 2M, ogni diverso valore rappresenta un gruppo di M = log2L cifre binarie (bit), e la trasmissione convoglia un messaggio numerico con frequenza binaria pari a fb⎡⎣bitsecondo⎤⎦ = M⎡⎣bitsimbolo⎤⎦ ⋅ fs⎡⎣simbolisecondo⎤⎦.
[717]La modalità generale di calcolo per σ2A viene descritta alla nota 415 di pag. 1.
[718]Infatti, se i valori ak fossero tutti uguali, il segnale ∑mg(t − mT) sarebbe semplicemente periodico, come descritto a pag. 1.
[720]Estendiamo il risultato al caso noto di segnale periodico. Ponendo ak = ( − 1)k si genera un’onda rettangolare, il cui spettro (mancando la componente aleatoria) è a righe, con lo stesso inviluppo di tipo sinc2(fTb).
[721]Infatti il fattore τ2Tb passa da Tb (NRZ) a Tb4 (RZ), pari ad una riduzione di 6 dB.
Nella tabella a fianco è riportata l’occupazione di banda necessaria a contenere 10 lobi di un sinc(fTb) = 1⁄TbF{ rectTb(t)}, ovvero relativa ad una trasmissione binaria a velocità fb = 1⁄Tb per alcuni casi tipici del passato: osserviamo che un’onda rettangolare può andar bene a basse velocità di trasmissione, infatti già per 10 Msimboli/sec, velocità di una LAN, occorrono 100 MHz di banda.
[725]Proseguiamo l’esposizione riferendoci direttamente al termine livelli, indicando con questo la scelta tra L possibili valori di ampiezza per il segnale trasmesso.
[726]Si tratta di un componente di elettronica digitale noto come registro a scorrimento (vedi https://it.wikipedia.org/wiki/Registro_a_scorrimento), costituito da M celle di memoria di un bit, ciascuna delle quali (con frequenza fb) copia il contenuto della precedente, mentre la prima è caricata (in serie) con un nuovo bit; al termine di M cicli i bit vengono letti tutti assieme, appunto, in parallelo.
[727]In ricezione si effettua il procedimento inverso, ripristinando la codifica binaria originaria di M bit a cui il codificatore ha associato il valore L-ario ricevuto, e quindi serializzando gli M bit, in modo da ri-ottenere la sequenza binaria di partenza. Vedi anche fig.15.38.
[728]In realtà al § 7.7.4 si mostra come il risultato possa essere un po’ diverso nel caso di simboli statisticamente dipendenti e/o non a media nulla.
[729]La non perfetta indipendenza statistica dei simboli prodotti dal generatore di numeri casuali di un computer si può riflettere su di una ridotta generalità del risultato mostrato, che tuttavia rispecchia molto bene i casi reali.
[730]Ottenuta applicando ai dati una finestra triangolare (§ 3.8.4) e quindi valutando il periodogramma (§ 7.3.1).
[731]Viene detto sbilanciato un segnale trasmesso mediante un collegamento (ad es. su rame) in cui uno dei due conduttori è connesso a massa ad entrambe le estremità, dando luogo ad una maggiore sensibilità a fenomeni di induzione elettromagnetica relativi ad altri segnali in transito nelle vicinanze (vedi diafonia a pag. 1), e dunque ad un peggiore SNR rispetto ai segnali (e collegamenti) bilanciati - .vedi ad es. https://it.wikipedia.org/wiki/Linea_bilanciata.
[734]La densità spettrale mostrata in figura è relativa all’uso di una g(t) di tipo RZ.
[735]La codifica hdb3 è utilizzata per trasmettere il segnale pcm a 2 Mbps (vedi § 24.3.1), e l’acronimo significa High-Density Bipolar-3-zeroes. Come per ami, rappresenta gli uni con polarità alternate, ma rimpiazza le sequenze di quattro zeri consecutivi forzando una violazione della regola dell’alternanza sull’ultimo bit dei quattro, in modo che il ricevitore, rilevando la violazione, è in grado di riportare il bit a zero. Dato però che la presenza della violazione creerebbe la comparsa di una componente continua nel segnale, sono inseriti anche dei bit di bilanciamento, per rimuovere quest’ultima. Questi si collocano al posto del primo dei quattro zeri, e la loro polarità è scelta in modo che la sequenza delle violazioni abbia un polarità alternata; in definitiva, dopo la prima violazione, si usa sempre anche il bit di bilanciamento.
[736]In tal caso tutti gli zeri diventerebbero uni e viceversa, mentre con la codifica differenziale questo viene evitato.
[737]Come mostrato al § 15.1.2.2, il segnale dati filtrato è basato su impulsi ~g(t) = g(t) * h(t), con una durata pari alla somma delle durate di g(t) e h(t). Pertanto, anche se g(t) è limitato nel tempo, come nei casi descritti al § 15.2.1, l’impulso ~g(t) si può estendere a valori di t > Ts. Considerando ad esempio la trasmissione di soli due simboli a0 ed a1, si otterrebbe x(t) = a0~g(t) + a1~g(t − Ts), e dunque x(Ts) = a0~g(Ts) + a1~g(0) dipenderà da entrambi i simboli anziché solamente da a1, osservando quindi un errore pari a a0~g(Ts), detto appunto interferenza tra simboli.
[738]Il requisito di causalità h(t) = 0 per t < 0 (pag. 1) a cui deve sottostare qualsiasi sistema fisico impedisce infatti di realizzare un filtro la cui risposta impulsiva g(t) abbia una estensione temporale illimitata: per avvicinarsi al risultato desiderato occorre implementare il filtro adottando al posto di
g(t) una sua versione ritardata e limitata g’(t) = g(t − TR)con t ≥ 0 e g’(t) = 0 altrimenti, come in figura.
Se TR ≫ Ts, l’entità dell’approssimazione è accettabile, ed equivale ad un semplice ritardo pari a TR; d’altro canto, quanto maggiore è la durata della risposta impulsiva, tanto più difficile (ossia costosa) risulta la realizzazione del filtro relativo.
[739]Al contrario, se g(t) = rectTs(t), il campionamento può avvenire ovunque nell’ambito del periodo di simbolo, ma si torna al caso di elevata occupazione di banda.
[741]Ad esempio, l’impulso rettangolare è di Nyquist, in quanto rectTs(t) = ⎧⎨⎩ 1 se|t| < Ts2 0 set = kTs.
[742]La fig. 16.4 a pag. 1 mostra la stessa funzione su di una scala quadratica e in decibel.
[743]Il termine roll-off può essere tradotto come “rotola fuori “.
[744]Molto intimamente legata alla velocità di Nyquist definita al § 4.1 come la minima frequenza di campionamento fc = 2W per un segnale analogico di banda W, mentre la frequenza di Nyquist si riferisce invece a metà della massima frequenza di segnalazione fs⁄2 = B per un segnale dati che transita su di un canale limitato in banda B, per motivi presto chiari. Come evidente due aspetti dello stesso fenomeno, ma in contesti differenti, vedi https://en.wikipedia.org/wiki/Nyquist_rate.
[745]Non ho trovato questi passaggi già svolti in nessun posto, qualche lettore può aiutare? Tutto quel che sono riuscito a calcolare è relativo al caso γ = 1, per cui g(t) = F− 1⎧⎩T2[1 + cos(πTf)]⎫⎭ ⋅ rect2⁄T(f) che fornisce
che una volta graficato, conferma l’andamento di fig. 15.19. Osserviamo che per t → 1⁄2γfs il denominatore di (21.6) si annulla, ma lo stesso avviene anche per il numeratore, che in tal caso tende a cosπ2, dando luogo alla forma 00, ed il cui limite sembra tendere a poco meno di uno.
[746]Le esigenze di mantenere basso l’ordine del filtro tentando al contempo di rispondere ai requisiti sulla fase oltre che sul modulo impediscono di ottenere una sintesi perfetta di Heq(f).
[747]Vedi il § 8.4.2.1 per una descrizione della sua natura fisica.
[748]Al § 8.4.2.1 si illustra come in realtà PN(f) non è costante per qualsiasi valore di f fino ad infinito, ma occupa una banda grandissima ma limitata: altrimenti, avrebbe una potenza infinita.
[749]I due aggettivi White e Gaussian non sono per nulla inscindibili, nel senso che un processo può essere gaussiano ma non bianco, o bianco ma non gaussiano!
[750]Al § 15.5 si descrive un diverso modo di progettare HR(f), in modo da minimizzare la probabilità di errore anziché la potenza di rumore, e che di fatto realizza un filtro adattato, descritto al § 7.6. Come vedremo al § 15.5, nel caso di un impulso a banda minima i due approcci portano al medesimo risultato.
[751]Per i dettagli relativi al filtraggio di processi, ci si può riferire al § 204.
[753]La proprietà di equidistanza delle soglie dal valore di simboli deriva dalla simmetria pari della d.d.p. gaussiana rispetto al suo valor medio: in generale, le soglie sono poste in modo da rendere eguali le probabilità di falso allarme e di perdita, vedi § 6.6.1.
[754]Chiaramente, tutti i valori x minori di λ1 provocano la decisione a favore di a1, e quelli maggiori di λL − 1 indicano la probabile trasmissione di aL.
[755]Sono detti di sistema in quanto indipendenti dalla natura della trasmissione, infatti PR dipende da amplificatori e mezzi trasmissivi, Pν(f) dall’entità dei disturbi additivi presenti in uscita dal canale, mentre fb è imposta dal contratto di servizio con il produttore di contenuti, o sorgente informativa.
[756]Questi sono invece parametri negoziati allo scopo di ottemperare ai vincoli relativi alla banda occupata ed alla precisione del temporizzatore.
[757]Anche se il risultato sarà dimostrato al § 15.8.1, merita comunque un commento: osserviamo che PR diminuisce all’aumentare di γ (si stringe infatti l’impulso nel tempo); inoltre PR diminuisce al crescere di L, in quanto nel caso di più di 2 livelli, la forma d’onda assume valori molto vari all’interno della dinamica di segnale, mentre con L = 2 ha valori molto più estremi.
[758]Per completezza sviluppiamo i passaggi, piuttosto banali anche se non ovvi:
[759]Aumentando L l’argomento di (21.17) diminuisce in quanto (L2 − 1) cresce più velocemente di log2L.
[760]Perché a parità di PR gli intervalli di decisione sono più ravvicinati, le “code” della gaussiana sottendono un’area maggiore, e questo peggioramento prevale sul miglioramento legato alla diminuzione di σν conseguente alla riduzione della banda di rumore.
[761]Perché occorre aumentare la banda del filtro di ricezione e dunque far entrare più rumore. D’altra parte questo peggioramento è compensato dalla riduzione dell’ISI.
[762]Mentre in un array gli elementi sono inviduati in base alla loro posizione od indice, una memoria associativa non è ordinata e restituisce l’elemento associato alla chiave, come ad esempio colore[banana]=giallo.
[763]Infatti con γ > 0 l’argomento di erfc{.} si riduce. Ma non di molto: per γ = 1 il peggioramento risulta di 1.76 dB.
[764]Una volta scelto un valore per L è individuta la curva da usare in fig. 15.39, ed una volta imposta una Pe sulle ordinate l’EbN0|dB necessario a conseguire tale Pe con γ = 0 si ottiene sulle ascisse seguendo la curva. Aumentando γ l’argomento di erfc{.} nella 21.21 si riduce, e ciò equivale a spostarsi verso sinistra sull’asse delle ascisse della stessa quantità di dB, a cui corrisponde (seguendo la curva) un aumento della Pe. Per ristabilire la Pe desiderata non resta quindi altro da fare che aumentare EbN0|dB dello stesso numero di dB.
[765]Infatti il segnale n(t) uscente da HR(f) = rect2B(f) ha autocorrelazione RN(τ) = F−1{|HR(f)|2} = 2B sinc(2Bτ) (vedi § 7.2.4), che passa da zero per τ = 12B.
Se si utilizza una G(f) a coseno rialzato con γ > 0 occorre estendere la banda di ricezione a B = fs2 (1 + γ), a cui corrispondono campioni di rumore incorrelati se prelevati a distanza multipla di τ = 12B = 1fs(1 + γ), mentre invece il segnale è campionato con frequenza pari a quella di simbolo fs, e dunque con campioni a distanza τ = Ts = 1fs. Pertanto i campioni di rumore sono correlati, con autocorrelazione pari a RN(Ts) = 2B sinc(1 + γ).
[766]Al § 6.5.1 si dimostra come delle v.a. gaussiane incorrelate siano anche statisticamente indipendenti, mentre nel nostro caso i campioni di rumore sono correlati, e statisticamente dipendenti. In accordo alla trattazione della regressione (§ 7.7.1) e della predizione lineare (§ 10.1.2.2), osserviamo che la dipendenzastatistica tra campioni di rumore implica la possibilità di ridurre l’incertezza relativa ai nuovi valori a partire dalla conoscenza dei valori passati. Il vero valore di un campione di rumore può essere calcolato sottraendo al valore sk − 1 del segnale ricevuto all’istante di simbolo k − 1, il valore del simbolo deciso senza commettere errore; da questo risultato è possibile predire il successivo campione di rumore come n̂k = nk − 1RN(Ts)RN(0), che viene quindi sottratto al successivo valore sk osservato. In tal modo, anche se la regressione non è esatta, l’ampiezza (e la varianza) del rumore residuo sono comunque ridotte, ed altrettanto la probabilità di errore del decisore.
[767]Infatti quando G(f) è tutta al trasmettitore il segnale generato (e ricevuto) ha espressione (21.7) (vedi anche la (21.1)); indicando ora g√(t) = F−1{√G(f)}, ed eseguendo un calcolo del tutto analogo a quello svolto in § 15.1.2.2, si ottiene che il segnale ricevuto nel caso di scomposizione di G(f) ha espressione
in quanto hT(t) * hR(t) = g√(t) * g√(t) = g(t) per la proprietà di prodotto in frequenza.
[768]Il risultato si può ottenere visivamente, a partire dalla G(f) a coseno rialzato mostrata in fig. 15.19 a pag. 1 ma con altezza 1, e in base alle sue proprietà di simmetria attorno a ± fs⁄2: il risultato dell’integrale ∫∞−∞G(f)df è quindi pari all’area di un rettangolo di altezza 1 e base fs = 1⁄Ts.
[770]A meno di un contributo di fase lineare e j2πfτ necessario a garantire la causalità dell’insieme.
[771]Anche in questo caso, a meno di un termine di fase lineare, che viene omesso per non appesantire la notazione.
[772]Può essere che H(f) non sia nota a priori e che dunque debba essere stimata al ricevitore (§ 18.4), ma non sia disponibile un canale di ritorno per comunicarla al trasmettitore; oppure si tratti di una trasmissione broadcast (§ 11.1.1.1), e la H(f) è differente per ognuno dei ricevitori, oppure ancora H(f) varia nel tempo, e la sua equalizzazione deve essere modificata di continuo.
[773]Oltre al caso banale in cui la comunicazione sia effettivamente half-duplex (nota. 16), il canale deve essere considerato unidirezionale anche qualora la trasmissione a distanza riguardi informazioni generate in tempo reale e consumate immediatamente in ricezione, come nel caso televisivo o telefonico, in cui l’attesa di una ritrasmissione introdurrebbe, oltre ad una temporanea interruzione, anche un ritardo aggiuntivo a tutto ciò che viene dopo, impossibile da sostenere in una applicazione interattiva.
Un altro caso di applicazione della tecnica fec riguarda ad es. il caso di informazioni memorizzate in forma numerica su data storage, come as esempio cd/dvd, chip di memoria, hard disk.... in cui pur se possibile ri-leggere le informazioni, ciò non cambierebbe nulla, in quanto l’errore è attribuibile al supporto rovinato, e non al rumore. Per questo i dispositivi di memoria aggiungono una ridondanza ai propri dati, usata per rimediare al possibile deterioramento della loro conservazione, o per segnalare la cella di memoria come inaffidabile.
[774]L’aggettivo automatic si riferisce al fatto che spesso la gestione della ritrasmissione avviene a carico di uno strato protocollare (§ 22.5.2.3) di livello inferiore a quello che effettivamente consuma il messaggio, che in definitiva neanche si avvede della presenza del meccanismo di ritrasmissione.
[775]In generale questo raggruppamento è indipendente da quello in simboli operato dal codificatore di linea multilivello, così come non riflette altre suddivisioni come i bit di un campione quantizzato (§ 4.3) o gli intervalli temporali di una multiplazione (§ 24.2) mediante trame (§ 24.3.1) o pacchetti § 22.5.1.
[777]Dal confronto tra (21.26) e (21.27) osserviamo che l’approssimazione consiste nel considerare (1 − p)n − i ≃ 1. Per verificare che ciò sia lecito qualora np≪1, cerchiamo il valore di p tale che (1 − p)n > 0.9, da cui discende che anche (1 − p)n − i > 0.9 per qualunque i. Dato che si può scrivere (vedi nota 1306 a pag. 22.1) (1 − p)n = ∑nk = 0⎛⎜⎝nk⎞⎟⎠pk > 1 − np, otteniamo la condizione (1 − p)n > 1 − np > 0.9, da cui si ottiene np < 1 − 0.9 = 0.1: ad esempio, se n = 1000 occorre che sia almeno p = 10 − 4. Altrimenti l’approssimazione non è valida, e la (21.28) deve essere verificata; qui sotto mostriamo la d.d.p. di Bernoulli (21.26) per diversi valori di np, evidenziando come qualora np < 0.1 essa risulti monotona decrescente con i.
[778]In linea di principio, dato che la probabilità che solo il primo bit su n sia sbagliato è pari a p(1 − p)n − 1 e che lo stesso risultato si ottiene anche per gli altri n − 1 casi possibili, la probabilità P(1, n) di un solo (generico) bit sbagliato su n è pari a P(1, n) = np(1 − p)n − 1, che si approssima come np qualora si consideri (1 − p)n − 1 ≃ 1 in virtù della condizione np≪1.
[779]Così come non è opportuno aumentare di troppo la dimensione di un pacchetto dati, anche se in tal modo si riduce l’overhead, vedi § 22.5.1.
[780]Che nel caso di rivelazione richiede la ritrasmissione della parola errata.
[781]Senza pretesa di esaustività, possiamo annoverare l’esistenza dei codici di Hamming, di Hadamard, BCH, Reed-Solomon, Reed-Muller, di Golay, di Gallager, turbo, a cancellazione, a fontana, punturati...
[782]Con riferimento alla figura, 3 è il numero di vertici da attraversare, ovvero di errori da subire, per passare da una codeword all’altra.
[783]Poniamo di dover trasmettere 0110. La sequenza diventa 000 111 111 000 e quindi, a causa di errori, ricevo 000 101 110100. Votando a maggioranza, ricostruisco la sequenza corretta 0 1 1 0.
[784]Volendo essere esatti la probabilità di 2 bit errati su 3 è data dalla d.d.p. binomiale (§ 22.1) ed è pari a 3\choose2p2(1 − p) = 3p2(1 − p), a cui va sommata la probabilità di 3 bit errati, pari a p3. Pertanto Pr = 3p2(1 − p) + p3 = 3p2 − 3p3 + p3 = 3p2 − 2p3 ≃ 3p2e, approssimazione legittima se np = 3p≪1.
[785]In inglese, errori a burst (scoppio). Dovuti a rumori e disturbi di tipo impulsivo, ad esempio a causa di scintille come per motori elettrici o candele di accensione, o fenomeni di fast fading (§ 20.4.4).
[786]Letteralmente: arrampicamento, ma anche “arruffamento”, vedi scrambled eggs, le uova strapazzate dell’english breakfast.
[787]Leave = foglia, sfogliare, rastrellare, ed il termine potrebbe essere tradotto come intercalamento.
[788]Ad esempio, alla sequenza 001001 verrà aggiunto uno 0, mentre a 010101 si aggiungerà ancora un 1, perché altrimenti gli uni complessivi sarebbero stati 3, che è dispari.
[789]Il ricevitore deve comunque essere al corrente del fatto se la parità sia odd o even !
[790]La conta può essere realizzata in forma algoritmica o circuitale, eseguendo la somma modulo due di tutti i bit che compongono la parola (ovvero complementando il risultato, nel caso di parità dispari). La somma modulo due è equivalente all’operazione di or esclusivo, viene a volte indicata con il simbolo ⊕, e corrisponde alla regola 0⊕0 = 0, 0⊕1 = 1, 1⊕0 = 1, 1⊕1 = 0.
[791]Considerando parole di 3 bit, le codeword (di 4 bit, in cui l’ultimo è una parità pari) risultano: (0000, 0011, 0101, 0110, 1001, 1010, 1100, 1111). E’ facile constatare che ognuna di esse differisce da tutte le altre per almeno due bit.
[792]La somma modulo uno è l’equivalente binario dell’operazione di somma (decimale) tradizionale, comprese quindi le operazioni di riporto verso le cifre più elevate. Il riporto finale viene poi nuovamente sommato al risultato della somma.
[793]Tale denominazione indica un’azione di controllo (check) realizzata mediante l’aggiunta di una ridondanza ottenuta applicando un codice ciclico - vedi § 17.4.1.2.
[794]L’insieme di tutti i polinomi di grado minore od uguale ad n costituisce un particolare spazio algebrico, per il quale è possibile dimostrare una serie di proprietà, la cui verifica trascende dallo scopo di questo testo, e che consentono di stabilire le capacità del codice di rivelare gli errori.
[795]Per fissare le idee, consideriamo k = 8 bit a da proteggere, pari a P = 11100110, q = 4 bit di crc, ed un generatore G = 11001.
La sequenza P ⋅ 2q risulta pari a 10 0000, e la divisione modulo 2 tra P e G fornisce un quoziente Q = 10110110 (che viene ignorato) ed un resto R pari a 0110. Pertanto, viene trasmessa la sequenza T = P ⋅ 2q ⊕ R = 11100110 0110 con k + q = 12 bit. La divisione modulo 2 si realizza come mostrato nella figura a lato: considerando i bit più significativi di P ⋅ 2q e G, l’uno nell’uno ci sta una volta, e scriviamo uno come primo bit di Q. Riportiamo ora G sotto P ⋅ 2q, ed anziché sottrarre i bit, ne calcoliamo l’or-esclusivo⊕ bit-a-bit, ottenendo 00101, a cui aggiungiamo un uno abbassando il successivo bit (1) di P ⋅ 2q. Stavolta l’uno nello zero ci sta zero volte, e dunque aggiungiamo uno zero a Q, riportiamo cinque zeri (come la lunghezza di G) allineati sotto al resto parziale, eseguiamo l’exor, ed abbassiamo un’altra cifra (1) di P. Il confronto ora è tra il quinto bit da destra del resto parziale (1) ed il bit più significativo (il quinto, 1) di G, ottendo la terza cifra di Q(1). Ripetiamo il procedimento, e quando tutti i bit del divisore sono stati usati, l’ultima operazione ⊕ fornisce il resto R cercato.
[796]Dalla (21.30) sembrerebbe che il resto sia E, ma dato che E(x) può avere grado > q, esso è divisibile per G(x), e dunque il resto non èE - altrimenti, sarebbe possibile correggerlo!!
[797]Ecco quattro scelte utilizzate nei sistemi di trasmissione:
Come discusso, un polinomio di ordine q genera un crc di q bit; pertanto il crc-12, che è usato per caratteri a 6 bit, genera 12 bit di crc, mentre crc-16 e crc-ccitt, utilizzati in America ed in Europa rispettivamente per caratteri ad 8 bit, producono 16 bit di crc. In alcuni standard di trasmissione sincrona punto-punto, è previsto l’uso di crc-32.
[800]In alternativa al recupero del sincronismo da parte del ricevitore, l’informazione di temporizzazione può essere trasmessa su di una diversa linea, come avviene nel caso di dispositivi ospitati su di una stessa motherboard.
[801]Una sintassi definisce un linguaggio, prescrivendo le regole con cui possono essere costruite sequenze di simboli noti (l’alfabeto), e l’analisi delle sequenze eseguita nei termini degli elementi definiti dalla sintassi, ne permette una interpretazione semantica. Il parallelismo linguistico porta spontaneamente ad indicare i simboli trasmessi come alfabeto, gruppi di simboli come parole, e gruppi di parole come frasi, od in alternativa, trame (frame, ovvero telaio).
[802]In appendice 15.8.4 è riportata la codifica in termini di sequenze binarie dei caratteri stampabili, definita dallo standard ascii; al § 24.3.1 si mostra la struttura della trama pcm, che trasporta i campioni di più sorgenti analogiche campionate.
[803]Un dumb terminal non ha capacità di calcolo, e provvede solo alla visualizzazione di informazioni testuali. Fino agli anni ’70, è stato l’unico meccanismo di interazione (comunque migliore delle schede perforate !!!) con un computer. Per lungo tempo ogni computer disponeva di interfacce seriali rs-232 che possono funzionare sia in modalità asincrona che sincrona, oggi soppiantate dalle prese usb.
[804]In tal caso la linea “.. is marking time” (sta marcando il tempo).
[805]Ovviamente, occorre stabilire un accordo a priori a riguardo la velocità, ossia della frequenza, sia pure approssimata, della trasmissione.
[806]Per accorgersi di questa e delle altre transizioni, il ricevitore può ad esempio sfruttare un circuito che approssimi l’operazione di derivata, di cui constatare il superamento di una soglia.
[807]Una parola di M bit descrive uno spazio di 2M diversi elementi. Se le parole trasmissibili non sono tutte le 2M possibili, alcune di queste (che non compariranno mai all’interno del messaggio) possono essere usate per la sua delimitazione.
[808]Cioè, i dati trasmessi, che ora riempiono tutto lo spazio delle configurazioni possibili, contengono al loro interno la configurazione che è propria del carattere etx.
[809]In termini generali, questo circuito è assimilabile ad un circuito di controllo, in quanto il suo principio di funzionamento si basa sul tentativo di azzerare una grandezza di errore. Infatti, la sincronizzazione dell’orologio del decisore di ricezione con il periodo di simbolo del segnale ricevuto avviene effettuando un confronto tra la velocità dell’orologio locale ed un ritmo presente nel segnale in arrivo: questo segnale di errore alimenta quindi un circuito di controreazione, che mantiene il clock locale al passo con quello dei dati in arrivo. Un diverso caso particolare di questo stesso principio è analizzato al § 16.11.1, ed anche ai § 12.2.2.2 e 12.3.2.1 a proposito del pll.
[810]La dimostrazione sarà sperabilmente sviluppata in una prossima edizione... è una delle poche a mancare in questo libro! ..al momento, la fonte che trovo più in accordo con questa tesi, è ancora una volta https://en.wikipedia.org/wiki/Raised-cosine_filter
[811]Facciamo uso delle relazioni ∑Nn = 1n = N(N + 1)2 e ∑Nn = 1n2 = N(N + 1)(2N + 1)6 , che sono ovviamente ancora valide anche qualora la somma parta da n = 0.
[815]Letteralmente, slittamento di tasto a due fasi.
[816]Qui e nel seguito assumiamo di disporre di una portante di demodulazione omodina o coerente (§ 12.2.1), ossia priva di errori di fase e frequenza, così come di una perfetta temporizzazione di simbolo; le considerazioni al riguardo di quest’ultimo aspetto sono svolte all’appendice 16.11.
[817]Il segnale di banda base m(t) = ∑kak ⋅ g(t − kTb) in cui g(t) = rectTb(t) ed i simboli ak sono a media nulla ed indipendenti, ha una densità di potenza Pm(f) = σ2ATbsinc2(fTb), il cui andamento è mostrato in fig. 3.18 di pag. 1.
[818]Come ad esempio i collegamenti satellitari, vedi § 25.3.
[819]Per chi si sta chiedendo quanto valgono questi livelli, diciamo che il livello i-esimo (con i = 0, 1, ⋯, L − 1) corrisponde al valore ai = i ⋅ ΔL − 1 − 1 . Verificare per esercizio con Δ = 2 ed L = 4.
[820]Ad esempio: se L = 32 livelli, la banda si riduce di 5 volte, ed infatti con M = 5 bit si individuano L = 2M = 32 configurazioni. Dato che il numero M di bit/simbolo deve risultare un intero, si ottiene che i valori validi di L sono le potenze di 2.
[821]Notiamo che mentre per il bpsk scegliere il primo al posto del secondo comporta perdere i benefici di una ampiezza costante, nel caso multilivello l’ampiezza è intrinsecamente variabile.
[823]Ricordiamo che Px esprime la potenza ricevuta, N0 rappresenta il doppio della Pn(f) presente al decisore, e W è la banda del segnale modulante.
[824]Infatti come discusso a pag. 1Eb = Pxfb, come N0, dipende solamente da parametri di sistema (Px e fb), mentre invece non dipende dai parametri di trasmissioneL e γ e dal tipo di modulazione.
[825]Forniamo qui una contro-dimostrazione forse inutilmente elaborata. Con riferimento alla figura seguente, il calcolo della Pe per l’l-ask si imposta definendo valori di Eb ed N0 equivalenti a quelli di banda base, ma ottenuti dopo demodulazione, e cioè Eb’ = Px’Tb e N0’ = PN’ ⁄ W (infatti, PN’ = N0’22W, con W = fs2 = fb2log2L). L’equivalenza è presto fatta, una volta tarato il demodulatore in modo che produca in uscita la componente in fase xc(t) limitata in banda tra ± W.
Infatti in tal caso (vedi § 14.2.1) Px’ = Pxc = k2aPM = 2Px e quindi Eb’ = Px’Ts = 2PxTs = 2Eb; per il rumore si ottiene N0’ = PN’W in cui PN’ = Pnc = σ2nc = σ2n = N024W e quindi N0’ = 2N0. Pertanto, il valore Eb’ ⁄ N0’ su cui si basa ora il decisore è lo stesso Eb ⁄ N0 in ingresso al demodulatore.
[826]Se γ ≠ 0, valgono le considerazioni svolte al § 15.4.9.
[827]Il caso in cui L = 2 ricade nel bpsk già discusso
[828]che non è una modulazione am-blu dato che xs ≠ ^xc
[829]Infatti un rettangolo di durata Ts ha trasformata sinc(Tsf), con il primo zero in f = 1⁄Ts = fs, e la modulazione am-bld produce un raddoppio della banda occupata.
[830]Se viceversa g(t) = rectTs(t), |x| giace su di un cerchio, spostandosi istantaneamente da un punto all’altro della costellazione
[831]Nella parte superiore della figura è mostrato l’andamento delle c.a. di b.f. per 5 simboli di un qpsk realizzato adottando g(t) a coseno rialzato con γ = 0.5, e si può notare che ognuna di esse assume il valore ±1 in corrispondenza di ogni periodo di simbolo. Nella parte inferiore è riportato il corrispondente segnale modulato, che come si vede non è affatto ad ampiezza costante.
[832]In effetti, dovremmo verificare che l’attuale valore di Eb⁄N0 sia lo stesso del caso bpsk: mentre per N0 al § 14.1.3 si mostra che è vero, per quanto riguarda Eb (a prima vista) sembra che il suo valore si dimezzi. Infatti, a parità di potenza ricevuta, i punti di costellazione del bpsk giacciono all’intersezione tra l’asse cartesiano della c.a. di b.f. ed il cerchio di raggio pari all’ampiezza a del segnale ricevuto, mentre nel qpsk le fasi formano un angolo di 45o rispetto agli assi, moltiplicando per cosπ4 = √2⁄2 le coordinate cartesiane, e riducendo dunque la potenza delle c.a. di b.f. di un fattore 2, e così pure il valore di Eb. In realtà, la durata doppia del periodo di simbolo Ts = 2Tb compensa questa riduzione, e dunque anche l’E’b di ogni ramo E’b = PxTs si mantiene invariato.
[833]All’istante di decisione k su ciascun ramo si osserva una v.a. gaussiana dc, s con varianza σ2νc, s (vedi fig. 14.4 a pag. 1) e valor medio xc(kTs) = cosφk e xs(kTs) = sinφk, dove φk è la fase del punto di costellazione trasmesso all’istante t = kTs, vedi eq. (21.43). Nell’esempio di figura la decisione per il secondo dei due bit del simbolo cambia in funzione del segno di dc, e dunque si commette errore sul ramo in fase se ad es. si trasmette x1, ma il rumore su quel ramo ha un valore sufficientemente positivo da far superare lo zero in corrispondenza dell’istante di decisione.
[834]In effetti all’istante di decisione potrebbe verificarsi errore su entrambi i rami, ma tale evento avviene con probabilità Pce ⋅ Pse che si ritiene tanto più trascurabile rispetto a Pce quanto più quest’ultimo è piccolo.
[835]Ulteriore rispetto al commento alla nota 832, dove il ragionamento è svolto sull’Eb⁄N0, mentre ora sull’SNR.
[837]In pratica, l’indice n si incrementa ogni due incrementi dell’indice k.
[838]Per come si è impostata la distribuzione dei bit tra i rami L deve risultare un quadrato perfetto. Sebbene sia possibile realizzare anche costellazioni di forma non quadrata, vedi ad es. AA.VV., A Survey on Design and Performance of Higher-Order QAM Constellations presso https://arxiv.org/pdf/2004.14708.pdf, la soluzione quadrata è preferita per semplicità realizzativa.
[839]Per applicare la (21.39) dobbiamo verificare se il valore di Eb⁄N0 è lo stesso nei due casi (vedi nota 832). Mentre per N0 non vi sono dubbi, notiamo (vedi § 12.4.5 per il caso di c.a. di b.f. incorrelate) che la potenza ricevuta Px si dimezza su entrambi i rami, così come la fb, e pertanto si ottiene E’b = Px⁄2fb⁄2 = Pxfb = Eb.
[840]Il cui effetto su xc(t) è stato discusso al § 12.2.3.1. Facciamo ricadere in questa casistica l’ambiguità di fase dei sistemi di recupero portante come descritto al § 12.2.2.1, ma anche la distorsione di fase introdotta dal canale non selettivo in frequenza, vedi § 13.1.2.4. Che un errore di fase si traduca in una rotazione dell’inviluppo complesso può essere mostrato considerando che l’operazione di demodulazione
omodina corrisponde a valutare R{xe jω0t}, mentre una portante cos(ω0t + φ) corrisponde a R{xe jω0tejφ}, equivalente alla demodulazione coerente di y = xejφ ossia un inviluppo complesso ruotato. In figura, un caso per cui φ = π2.
[841]La similitudine non è per nulla casuale, dato che qualora il predittore mostrato a pag. 1 sia realizzato mediante un elemento di ritardo, i due schemi di elaborazione coincidono.
[842]A parte per il primo bit, che ha il solo scopo di stabilire il riferimento di fase per la decodifica del successivo. Da un punto di vista formale, sostituendo la (21.48) nella (21.49) e in assenza di errori (ossia ŷk = yk) si ottiene ẑk = ŷk ⊕ ŷk − 1 = xk ⊕ yk −1 ⊕ yk − 1 = xk.
[843]Tratta da Andrea Goldsmith, Wireless Communications, pag. 151.
[844]Nel caso di L > 4 la tabella si modifica molto semplicemente scrivendo accanto al codice di Gray al L livelli, la sequenza crescente delle fasi differenziali Δθk = k2πL − 1.
[845]Vedi ad es. K. Wesolowski, Introduction to Digital Communication Systems, Wiley, pag. 328.
[846]La discussione al riguardo è sviluppata al § 16.12.1, definendo anche le condizioni di demodulazione incoerente e coerente, ovvero se le portanti generate in ricezione cos[2π(f0 + Δfk)t + φk] presentino o meno una fase φk casuale rispetto a quella trasmessa. In particolare, la spaziatura Δ multipla di 12Ts garantisce ortogonalità solo nel caso di modulazione coerente, mentre nel caso incoerente occorre una spaziatura doppia, ossia Δ multiplo di 1Ts.
[847]La condizione di ortogonalità tra le forme d’onda associate ai diversi simboli corrisponde alla intercorrelazione nulla tra le forme d’onda in un periodo (§ 7.1.4), ed infatti scegliendo opportunamente Δ ed f0 (vedi § 16.12.1) l’integrale (21.53) vale Rnm = ⎧⎨⎩ .5 ⋅ Ts se n = m 0 altrimenti. Ciò si dimostra (ricordando che cos2α = 12 + 12cos2α), notando che per m = n l’uscita del correlatore vale 12∫Ts0(1 + cos(4π(f0 + mΔ)t))dt, e scegliendo opportunamente f0 e Δ (vedi § 16.12.1), il coseno che viene integrato descrive un numero intero di periodi all’interno dell’intervallo (0, Ts), fornendo quindi un contributo nullo. Se invece n ≠ m la funzione integranda non contiene il termine costante, ma di nuovo in virtù di § 16.12.1, contiene solo termini a media nulla.
[848]Infatti il vettore r ha una d.d.p. condizionata p(r ⁄ fn) gaussiana multidimensionale a componenti indipendenti, e dunque (vedi § 6.5.1) si fattorizza nel prodotto di L gaussiane monodimensionali con uguale varianza e media nulla, tranne per la componente n = m relativa all’ipotesi realmente occorsa, che presenta una media non nulla. Pertanto per ogni possibile ipotesi fn la p(r ⁄ fn) è concentrata sulla n − esima componente, e dunque decidere per n̂ = argmaxn{rn} equivale a scegliere n̂ = argmaxn{p(r ⁄ fn)}.
[849]Difatti la (21.52) può essere riscritta come la somma di L segnali xk(t), uno per ogni possibile valore di fk, costituiti da un codice di linea rz che modula la corrispondente f0 + Δfk, a cui corrisponde dunque un tono intermittente. Essendo i simboli indipendenti e (in virtù della portante) a media nulla, la (10.195) di pag. 1 si riduce alla nota forma PXk(f) = σ2ATs|Gk(f)|2 in cui Gk(f) = F{gk(t)} e gk(t) = cos[2π(f0 + Δfk)t]rectTs(t); applicando ora il risultato di fig. 3.14 a pag. 1 si ottiene la densità di potenza mostrata in fig. 16.31.
[850]tipo: Sinclair Spectrum, Commodore Vic20 e 64 ... Come noto, le cassette audio soffrono di variazioni di velocità di trascinamento del nastro (wow&flutter), ma il pll non ne risente.
[851]Tranne che, essendo ora presenti solo 2 frequenze, l’approssimazione (21.54) non è più corretta. In particolare, con riferimento alla fig. 16.31, è tanto meno corretta quanto più fs è elevata, che corrisponde ad oscillazioni del sinc2 più estese in frequenza.
[852]Ovvero qualora siano soddisfatte le condizioni per f0 e Δ valutate al §16.12.1 per il caso di demodulazione coerente, e si verifichi la sincronizzazione tra le forme d’onda in ingresso ai correlatori del banco.
[853]Ovvero tenendo conto che (vedi § 17.2) fb non può superare la capacità di canale (eq. (21.101)), che a sua volta non può superare il limite C∞ espresso dalla (21.103).
[854]Vedi la discussione seguente per una motivazione informale di questo comportamento.
[855]Ad esempio realizzato mediante un integrate and dump (pag. 1), che deve essere resettato a fine Ts.
[856]Il fattore 1⁄Ts che compare nell’espressione di h(t) rende l’energia dell’impulso complessivo g(t) * h(t) = tri2Ts(t) (vedi eq. (10.56)) normalizzata rispetto a Ts (vedi § 3.8.8).
[857]Infatti il segnale demodulato (as es.) sul ramo in fase ha ampiezza costante A1Tscosθ, che risulta moltiplicata per Ts quando integrato su tale periodo.
[858]Infatti il filtro adattato ha una |G(f)|2 = sinc2(Tsf), e dunque il rumore alla sua uscita (vedi § 14.1.3 e pag. 1) presenta una densità di potenza Pn(f) = N0sinc2(Tsf). La potenza di rumore perciò risulta pari a Pn = σ2 = N0Ts, in quanto n(t) è a media nulla, e ∫∞−∞sinc2(Tsf) = 1Ts. Quest’ultimo risultato può essere verificato considerando che sinc2(Tsf) ha antitrasformata 1Tstri2Ts(t), e che per la proprietà del valore iniziale (pag. 1) ∫∞−∞sinc2(Tsf) = 1Ts tri2Ts(t = 0) = 1Ts.
[859]La discussione a pag. 1 fa riferimento ad una sola v.a. (quella in fase) a media A, mentre nel caso attuale sia ha ρ = A ma con una fase qualsiasi. Per le proprietà di simmetria radiale del problema, la conclusione è valida anche nel nostro caso.
[860]adsl = Asymmetric Digital Subscriber Line, vedi § 24.9.4.
[861]La trasmissione numerica contemporanea su più portanti è a volte indicata con il nome di Multi Carrier Modulation (mcm) o Discrete Multi Tone (dmt). La modulazione FSK utilizza invece una portante alla volta, in quanto la sua definizione prevede la presenza di un solo oscillatore.
risulta x+(t) = 12 e jω1t, e quindi il suo inviluppo complesso x(t) calcolato rispetto ad f0 vale
x(t) = 2x+(t)e −jω0t = 212 e jω1te −jω0t = e j(ω1 − ω0)t
Allo stesso modo si ottiene che per y(t) = sinω1t risulta y(t) = 1j e j(ω1 − ω0)t. Pertanto, considerando che 1j = jj2 = − j, ad ogni termine zk(t) = aknccosωnt − aknssinωnt corrisponde un
[867]Al § 15.8.1 si è mostrato che se gli an sono v.a. indipendenti e distribuite uniformemente su L’ livelli tra ± A, si ottiene σ2a = A23L’ + 1L’ − 1. Nel caso di una costellazione qam quadrata ad L livelli si ha L’ = √L, e se le realizzazioni sui rami in fase e quadratura sono indipendenti risulta σ2an = E{(anc + jans)2} = 2σ2a = 2A23√L + 1√L − 1; volendo eguagliare tale valore a 2 Pn, occorre quindi scegliere A = √3 Pn√L − 1√L + 1.
[868]La (21.64) è in qualche modo simile alla formula di ricostruzione (10.7) (vedi pag. 1) per il segnale (complesso) periodico limitato in banda ± N2 F
x(t) = N ⁄ 2⎲⎳m = − N ⁄ 2Xme j2πmFt
che calcolata per t = hTc = hNF fornisce x(hTc) = ∑N ⁄ 2m = − N ⁄ 2Xme j2πmNh. Ponendo ora n = m + N2 e Yn = Xn − N2 otteniamo
sono chiamate Discrete Fourier Transform (dft) diretta e inversa, in quanto costituiscono la versione discreta della trasformata di Fourier (vedi § 4.5), e consentono il calcolo di una serie di campioni in frequenza a partire da campioni nel tempo e viceversa.
[869]In effetti la (21.64) fornisce un risultato periodico rispetto ad h, con periodo N, ossia con periodo N ⋅ Tc = N1fc = N1ΔN = 1Δ = T0 per la variabile temporale. Per questo motivo il preambolo dell’ofdm è detto anche estensione ciclica.
[870]Come discusso ai § 17.2 e 17.3 la teoria di Shannon asserisce che fb = C è la massima velocità di trasmissione per cui si può (teoricamente) conseguire una probabilità di errore nulla, e che il canale consegue capacità C massima a seguito di una scelta appropriata su come trasmettere il messaggio.
[871]Si consideri ad esempio il caso in cui H(f) ha origine da un fenomeno di cammini multipli, che determina un andamento di H(f) selettivo in frequenza (§ 20.4.5).
[877]Oltre che indicare un circuito integrato, la parola chip è la stessa usata per le patine fritte olandesi, e prima ancora per scheggia, frammento o truciolo.
[878] Il prodotto tra due segnali dati di tipo polare a frequenza fb e fp = Lfb, è equivalente a creare il segnale dati partendo dall’or esclusivo⊕ delle corrispondenti rappresentazioni binarie fatte da zeri ed uni, come mostrato dalle tabelle poste a lato.
ab
a ⊕ b
0 0
0
0 1
1
1 0
1
1 1
0
ab
a ⋅ b
− 1 − 1
1
− 1 1
− 1
1 − 1
− 1
1 1
1
[879]Considerando x(t) realizzazione di un processo ergodico indipendente da pn(t), la potenza di x̃(t) risulta (§ 7.5.3) x̃2 = E{x2(t)pn2(t)} = x2 = Px, dato che dalla (21.72) si ha E{pn2(t)} = 1.
[880]L’autocorrelazione del prodotto di processi indipendenti è pari al prodotto delle autocorrelazioni (§ 7.5.3), ed a questo si applica la proprietà di equivalenza tra prodotto nel tempo e convoluzione in frequenza, applicato alle trasformate delle autocorrelazioni, in base al teorema di Wiener (§ 7.2.1).
[881]x̃(t)cos(ω0t + φ) con φ v.a. a d.d.p. uniforme può essere considerato come il prodotto di due processi statisticamente indipendenti, la cui potenza è il prodotto delle potenze, vedi § 7.5.3
[882]Il risultato si ottiene tenendo conto delle eq. (21.71) e (21.74), effettuando la convoluzione, e ricordando che Tp = 1⁄Wp.
[883]Eventualmente realizzato come descritto a pag. 1, supponendo inoltre che sia verificata la condizione di sincronizzazione temporale.
[884]Ossia l’antenna con cui tutti telefonini nella medesima cella sono in comunicazione.
[885]In tal caso infatti i K − 1 interferenti sono assimilabili ad un rumore gaussiano (in virtù del teorema centrale del limite) con potenza complessiva (K − 1) Px e limitato in banda alla stessa banda Wp del segnale utile. Dopo il despreading la densità spettrale interferente N0I⁄2si allarga su di una banda GpWp, e si riduce di ampiezza dello stesso fattore Gp. Pertanto il filtro passa basso a valle del despreading lascia passare una potenza interferente pari a (K − 1) Px⁄Gp.
[887]In quanto in linea di principio il periodo della sequenza può essere inferiore al massimo.
[888]Anche in questo caso come al § 15.6.3.3 la posizione degli xor può essere associata ad un polinomio generatore, e per produrre una sequenza di massima lunghezza occorre scegliere un polinomio primitivo, vedi https://en.wikipedia.org/wiki/Primitive_polynomial_(field_theory). A parità di m, cambiando polinomio si ottengono sequenze differenti ma di uguale lunghezza, ed il loro numero massimo N aumenta all’aumentare di m con legge N = (2m − 2)⁄m.
[889]Indicando con run una sequenza di bit uguali, su 2m − 1 bit si trova un run di uni lungo m, un run di zeri lungo m − 1, e quindi 2m − i − 2 run sia di zeri che di uni di lunghezza i, per 1 < i ≤ m − 2.
[890]L’autocorrelazione si intende calcolata a partire da valori bipolari, ossia ottenuti a partire dalla sequenza binaria facendo corrispondere ±1 ai valori 0, 1, vedi nota 879.
[891]La coppia di sequenze-m non è qualsiasi, ma scelta tra quelle con una intercorrelazione massima ridotta, chiamate sequenze preferite.
[908]Od alla fine, come nel caso di un ricevitore a correlazione, o basato su di un filtro adattato.
[909]Per il recupero della portante si possono usare circuiti del tipo di § 12.2.2.1, mentre l’uso del pll (§ 12.2.2.2) non è possibile a causa della assenza di residui di portante. Una volta acquisto il sincronismo di frequenza, quello di simbolo può essere ottenuto mediante schemi operanti in banda base, come quelli al § 15.7.2.1.
[912]L’esempio si riferisce ad una sequenza pn di massima lunghezza, della cui autocorrelazione si è discusso a pag. 1.
[913]Il blocco che valuta il valore assoluto dell’uscita dell’integratore è necessario in quanto x̃(t) trasporta anche l’informazione x(t), che determina l’eventuale inversione di segno della sequenza pn, e dunque un cambiamento di segno per l’uscita dell’integratore.
[914]In altri termini, le tre copie della pn (0, early e late) dovrebbero slittare a sinistra, e quindi il periodo della pn deve essere ridotto.
[916]Possiamo notare come la spaziatura tra le frequenze di segnalazione di fs2 fa si che due forme d’onda con una differenza di frequenza nΔ = nfs2 accumulino in un intervallo Ts una differenza di fase di nπ, ovvero un numero intero di semiperiodi.
[917]La (21.78) può essere derivata dalle (21.46) e (21.47) considerando EnbNn0 = SNRnlog2Ln, ovvero invertendo l’eq. (21.16)SNR = EbN02log2L(1 + γ) con γ = 0 e notando che a differenza del caso di banda base, per segnali am la banda (e la potenza di rumore) raddoppia. Ma se questa è una spiegazione troppo sintetica, ripercorriamo tutti i passaggi.
Partiamo dalla probabilità di errore condizionata (21.10)Pδ = erfc⎧⎩Δ2√2σN(L − 1)⎫⎭ del caso di multilivello di banda base, ed osserviamo che per un impulso rettangolare g(t) = rectT0(t) la (21.12) si modifica in PR = Δ212L + 1L − 1 in quanto PR = ∫PR(f)df = ∫σ2A|G(f)|2T0df dove σ2A = Δ212L + 1L − 1 come ottenuto al § 15.8.1, mentre ∫|G(f)|2df = ∫T20sinc2(fT0)df = T0 (vedi nota 858).
In tal modo, eseguendo i passaggi di cui alla nota 758 a pag. 15.4 otteniamo Pδ = erfc{√12 PR(L − 1)⁄(L + 1)2√2σn(L − 1)} = erfc{√321L2 − 1SNR} che conduce alla (21.78) ricordando che per il qam ogni ramo ha √L livelli, e che eseguendo il valore atteso rispetto alle probabilità dei simboli si ottiene Pe(bit) = ⎛⎝1 − 1√L⎞⎠Pδ (vedi eq. (21.11)).
[918]La riduzione da due ad una sommatoria si ottiene scrivendo esplicitamente tutti i termini della doppia sommatoria, e notando che si ottiene per N volte lo stesso termine RN(0), N − 1 volte i termini
RN(Tc)e jπe −j2π1Nn e RN( − Tc)e −jπe j2π1Nn
N − 2 volte quelli RN(2Tc)e j2πe −j2π2Nn e RN( − 2Tc)e −j2πe j2π2Nn, e così via.
[919]Se campioniamo z(t) con periodo Tc = 1NΔ, il segnale Z•(f) = ∑∞m = −∞Z(f − m ⋅ NΔ) non presenta aliasing (vedi figura),
ed il passaggio di z•(t) = ∑∞m = −∞z(mTc)δ(t − mTc) attraverso un filtro di ricostruzione H(f) = 1NΔ rectNΔ⎛⎝f − NΔ2⎞⎠ restituisce il segnale originario. Scriviamo pertanto
che, calcolata alle frequenze f = nΔ con n = 0, 1, ..., N − 1 fornisce
Z(f)|f = nΔ = 1NΔ∞⎲⎳m = −∞z(mTc)e −j2πmNn
Se ora non disponiamo di tutti i campioni z(mTc), ma solo dei 2N − 1 valori con m = − (N − 1), ..., 0, 1, ..., N − 1, la relazione precedente si applica ad un nuovo segnale z’(t) = z(t) ⋅ rect2NTc(t), fornendo
[921]Notiamo che in presenza di una codifica di sorgente efficace (PAG. 1) i simboli di ingresso dovrebbero essere pressoché equiprobabili.
[922]In caso contrario (ovvero p(x1) = p(x2) = 0.5) la (21.86) è equivalente alla (21.85). Nei casi in cui non si conoscano le prob. a priori, non si può quindi fare altro che attuare una decisione di massima verosimiglianza.
[923]Sono indicate come a posteriori perché misurano la probabilità del simbolo trasmesso x dopo la conoscenza di quello ricevuto y.
[924]Per ottenere le diverse forme della (21.87) si ricordi che p(xi, yj) = p(xi ⁄ yj)p(yj) = p(yj ⁄ xi)p(xi)
L’ultimo termine è indicato come entropia condizionale H(X ⁄ Y) (eq. (21.91)), mentre il penultimo è pari all’entropia di sorgente H(X) dato che saturando la prob. congiunta p(xi, yj) rispetto ad j, ovvero ∑jp(xi, yj) = p(xi), si perviene alla (21.89) in base al risultato ∑ilog21p(xi)∑jp(xi, yj) = ∑ip(xi)log21p(xi). Per la (21.89) il passaggio è del tutto simile.
[926]Infatti in tal caso la (21.91) diviene ∑i∑jp(xi, yj)log21p(xi ⁄ yj) = ∑ip(xi, yi)log21 = 0
[927]Notiamo l’invarianza di (21.95) rispetto al numero di livelli con cui è effettuata la trasmissione: se M bit sono raggruppati per generare simboli ad L = 2M livelli, come noto fs si riduce di M volte, mentre Cs aumenta della stessa quantità, dato che ogni simbolo trasporta ora M bit anziché uno.
[929]Ad esempio se L non è una potenza di due, un codificatore di sorgente che operi simbolo per simbolo produce necessariamente fb > R, mentre se concatena più simboli (§ 9.1.4), può avvicinarsi a fb = R.
[930]Infatti, potrebbe risultare R > C solo se fb < R, ovvero il codificatore dovrebbe produrre meno binit/secondo di quanti bit/secondo produca la sorgente
[931]Sono mostrati solo i valori per 0 ≤ pe ≤ 0.5 dato che successivamente l’andamento di Cs si riflette in modo speculare.
[932]Per il fatto di avere una ddp di y sia a numeratore che a denominatore del logaritmo, la (21.96) non soffre dei problemi discussi alla nota 477 a pag. 9.3.
[934]Senza pretendere di svolgere l’esatta dimostrazione, tentiamo di dare credibilità a questo risultato. Osserviamo quindi che se r(t) = xk(t) + n(t), il valore atteso dell’errore εk si riduce a 1Ts∫Ts0[n(t)]2dt → σ2n, dato che essendo n(t) stazionario ergodico, le medie di insieme coincidono con le medie temporali. Viceversa, se il segnale trasmesso è xh(t) con h ≠ k, allora il relativo errore quadratico vale ε(h)k = 1Ts∫Ts0(xh(t) + n(t) − xk(t))2dt, ed il suo valore atteso E{ε(h)k} → σ2n + 2σ2x essendo le forme d’onda dei simboli ortogonali tra loro e rispetto al rumore. I valori limite mostrati sono in realtà grandezze aleatorie, ma la loro varianza diviene sempre più piccola all’aumentare di Ts, e quindi in effetti con Ts → ∞ risulta sempre εk < ε(h)k, azzerando la probabilità di errore.
in cui ln è il logaritmo naturale in base e, e si è posto PsN0B = λ. Ricordando ora lo sviluppo di Maclaurin f(x) = f(0) + ∑∞n = 1⎛⎝∂nf(x)∂xn||x = 0 ⋅ xnn!⎞⎠ e che ddxln x = 1x, il termine ln (1 + λ) può essere espanso in serie di potenze come ln (1 + λ) = λ − 12λ2 + 13λ3 + ⋯; notando infine che per B → ∞ si ha λ → 0, e che limλ → 0ln (1 + λ)λ = 1, si giunge in definitiva al risultato (21.103).
[936]Riscrivendo la (21.101) come 2CB − 1 = PsN0B, moltiplicando ambo i membri per BR, e semplificando il risultato, si ottiene BR(2CB − 1) = PsN0R. L’uguaglianza individua la circostanza limite in cui R = C, mentre se nell’esponente di 2 a primo membro sostituiamo C con R, e R ≤ C, il primo membro diviene più piccolo, e pertanto BR(2RB − 1) ≤ PsN0R. Infine, notiamo che PsN0R = EbN0, da cui il risultato mostrato (21.104).
[937]Vedi ad es. il caso di banda base al § 15.4.9 o quello del qam al § 16.3.1.
[938]Infatti partendo dall’espressione della banda occupata dall’fskB → fb2 ⋅ Llog2L (eq. (21.54)) e considerando che L = 2M = 2fbT si ottiene B = 12T ⋅ 2fbT ovvero un aumento esponenziale di B al crescere di T. Un diverso esempio può essere l’uso di forme d’onda ortogonali realizzate come rectT⁄L posti all’interno del periodo di simbolo T in modo che non si sovrappongano se associati a simboli diversi (vedi fig. 7.20 a pag. 1). Anche qui, aumentando T il numero di simboli L = 2M = 2fbT aumenta esponenzialmente, e la durata T⁄L = T⁄2fbT di ogni rect tende esponenzialmente a zero se T → ∞, mentre la banda occupata tende ad infinito, sempre con legge esponenziale rispetto a T.
[939]Si ricorda che l’insieme delle 2k codeword costituisce un codebook.
[940]Notiamo la differenza tra queste tre grandezze dall’aspetto simile: l’efficienza spettrale ρ = fb⁄B indica quanto una tecnica di modulazione numerica faccia buon uso dello spettro, il rapporto BR esprime l’inverso del grado di utilizzo della banda B di un canale numerico, mentre Rc = k⁄n misura l’efficienza del codice adottato.
[942]Nel caso di decisioni hard o bit a bit, si ottiene una espressione del tipo Gac, hard = Rc(t + 1), in cui t è il numero di bit per parola che il codice è in grado di correggere.
[943]Infatti dalla definizione di somma tra cw otteniamo che dH(x, y) è pari al peso w(z) della codeword z = x + y, ossia z presenta componenti zj = 1 solo in corrispondenza di elementi xj ≠ yj. Ma per la linearità anche z appartiene al codebook, ovvero sommando tra loro tutte le possibili coppie ottengo l’intero codebook, e dunque la ricerca su tutte le coppie si trasforma in una ricerca su tutte le codeword.
[944]Questa fantomatica matrice generatrice che cala dall’alto in realtà ha una genesi ben razionale.
Se infatti definiamo una base ortogonale {ui} per lo spazio k − dimensionale descritto da tutti i possibili vettori m come i k vettori con componenti tutte nulle tranne quella in posizione i − esima e pari ad 1, possiamo allora scrivere un generico vettore m con componenti binarie mi come una combinazione lineare di vettori della base, ovvero m = ∑ki = 1miui.
Indicando ora con gi la codeword (di n elementi) associata a ciascun vettore ui, otteniamo che ad un generico vettore m è associata la codeword x = ∑ki = 1migi = m ⋅ G, in cui G è la nostra matrice generatrice di dimensione k × n le cui righe sono pari alle codeword gi con i = 1, 2, ⋯, k associate ai vettori della base ui.
[945]In effetti la simpatia c’entra ben poco, ed H è costruita in modo che le sue q colonne siano ortogonali a tutte le k righe di G (oltre che tra loro), individuando così una base di rappresentazione per il sottospazio di dimensione 2qcomplemento ortogonale di quello di dimensione 2k descritto dalle codeword di lunghezza n = k + q. La dimostrazione che ho trovato (per provare che per codici sistematici il risultato è quello mostrato nel testo) contiene un errore, e non la cito.
[946]Ad esempio, il codice [000, 110, 101, 011] è un codice ciclico, mentre [000, 010, 101, 111] no. Notiamo che gli scorrimenti della codeword 000, sono la codeword stessa.
[951]Il valore dei coefficienti del polinomio prodotto è indicato anche come prodotto di Cauchy (vedi http://it.wikipedia.org/wiki/Prodotto_di_Cauchy), e che si ottenga come una convoluzione è facilmente verificabile: dati ad es. a(p) = a0 + a1p + a2p2 e b(p) = b0 + b1p, si ottiene c(p) = a0b0 + (a0b1 + a1b0)p + a2p2 = ∑2i = 0pi∑2j = 0ajbi − j. La notazione lievemente diversa del testo, è dovuta al diverso modo di indicizzare i coefficienti.
[952]Forse ho trovato dove si spiega come faccia un registro a scorrimento controreazionato a svolgere questo genere di compiti: penso che in una prossima edizione sarà interessante aggiungerlo.
[956]Ovvero deve essere della forma L = αk con α numero primo e k intero positivo. Ciò è necessario affinché gli L simboli corrispondano agli elementi di un campo di Galois GF(L).
[959]Come ad esempio avviene nella codifica di sorgenti multimediali (cap. 10)
[960]Il valore di 188 byte deriva dalla dimensione di una cella atm (48 byte di dati e 5 di intestazione, § 23.2): infatti 48 ⋅ 4 = 192, ed una codeword si suddivide su 4 celle.
[961]Come osservato a pag. 1 in presenza di un numero di errori superiori al massimo correggibile, se ne verificano ancora di più.
[962]O meglio, ad una versione dello schema in cui la ridondanza interna viene calcolata sulla totalità dei simboli nella stessa posizione di M codeword esterne, come avviene per la tecnica esposta al § 15.6.3.2.
[967]La dipendenza di xj da (mj, Sj) è legata alla scelta dei generatori gi. Nel caso in cui un valore xj(i) sia sempre uguale ad uno dei k bit di mj, il codice diviene sistematico.
[968]Questo caso viene indicato con il termine hard-decision decoding in quanto il ricevitore ha già operato una decisione (quantizzazione) rispetto a x̃. Al contrario, se i valori ricevuti sono passati come sono al decodificatore di Viterbi, questo può correttamente valutare le probabilità p(x̃ ⁄ ^x) ed operare in modalità soft decoding, conseguendo prestazioni migliori.
[970]Dato che da ogni stato si dipartono 2k archi, ad ogni istante j il numero di percorsi alternativi aumenta di un fattore 2k, crescendo molto velocemente all’aumentare di j.
[971]Ad esempio, con riferimento alla fig. 17.22, la {S} = {00, 10, 11, 01, 10} ha un costo pari a 3.
[972]Qualora la distanza tra x̃j ed un possibile xj sia invece espressa da una probabilità condizionata p(x̃j ⁄ xj), il processo di decodifica è detto di massima verosimiglianza e la decodifica è detta soffice (soft), vedi § 17.4.2.3.
[973]La scelta del miglior percorso parziale è l’applicazione del principio di programmazione dinamica, secondo il quale “quando due percorsi con costi diversi si incontrano in uno stesso nodo, quello di costo maggiore sicuramente non è la parte iniziale del percorso di minimo costo, e quindi può essere eliminato”.
[974]Per questo detta hard decision decoding in quanto opera su decisioni già prese.
[980]Illustrato per esteso in J.Hagenauer, P.Hoeher, A Viterbi algorithm with soft-decision outputs and its applications, 1989 ieee, a cui si ispira questa parte, e reperibile ad es. presso http://shannon.ece.ufl.edu/eel6550/lit/SOVA.pdf
[981]Si è volutamente mantenuta la notazione introdotta al § 17.4.2.
[982]In particolare sono stati adottati nell’ambito della telefonia gsm, gprs, edge, e 3g e 3gpp, della diffusione televisiva dvb-s e dvb-t, del wifi (802.11a-g) e delle missioni spaziali, per non parlare dei supporti di memorizzazione come cd audio, dvd, unità raid. Per una narrazione di questa evoluzione, oltre che degli argomenti che stiamo trattando, si veda http://www.crit.rai.it/eletel/LeMiniSerie/MS1.pdf
[985]Come ad esempio dvb-2, telefonia umts ed lte, 10gbase-t Ethernet, wifi 802.11n e ab, WiMAX 802.16, nonché le missioni spaziali più recenti.
[986]Evidenziamo tra breve la presenza di un vero e proprio percorso di retroazione, ma l’aggettivo turbo è nato in analogia a quanto avviene in campo automobilistico con i motori turbo, una novità tecnica introdotta negli stessi anni in cui è stato definito questo metodo di decodifica.
[987]L’acronimo sta per Recursive Sistematic Convolutional, ed al § 17.4.2.4 ne è raffigurato un possibile schema architetturale. Il motivo di questa scelta è triplice: da un lato un rsc è simile ad uno scrambler pseudo random, e la teoria di Shannon basa la sua dimostrazione (vedi nota 934 a pag. 17.3) su codeword casuali; inoltre, un rsc ha prestazioni migliori dei CC classici per bassi valori di Eb⁄N0. Infine, solo poche sequenze di lunghezza finita in ingresso ne producono di lunghezza finita in uscita, indice di una elevata ridondanza.
[988]In realtà possono anche essere diversi e con un diverso tasso Rc, ma non si desidera appesantire la trattazione.
[989]Ad esempio, l’interleaver può essere implementato mediante una sequenza di numeri pseudo casuali da utilizzare ciclicamente come indice di scrittura in un array dove si memorizzano gli elementi della sequenza di ingresso, e la cui lettura avviene poi in modo sequenziale.
[990]Questo è il nome attribuito a tale quantità dalla comunità che ha lavorato alla definizione dei turbocodici. In effetti, essendo la llr un logaritmo di probabilità può a tutto diritto essere chiamata informazione, ma espressa in nat anziché in bit, avendo adottato un logaritmo in base e.
[991]Infatti ora yi è una v.a. gaussiana con media xi = ±1 e varianza σ2, e dunque
[992]Per poter utilizzare anche le prob. a priori in sova occorre che nella (21.112) venga sommato anche un termine ln (p(xj)).
[993]L. Bahl; J. Cocke; F. Jelinek; J. Raviv, Optimal decoding of linear codes for minimizing symbol error rate, in IEEE Trans. on Inf. Theory, March 1974, per come modificato in C Berrou, A Glavieux, Near optimum error correcting coding and decoding: Turbo-codes, IEEE Trans. on Comm., Oct. 1996.
In parole povere, il traliccio è esaminato oltre che da sinistra a destra, anche da destra a sinistra, permettendo il calcolo per ogni istante i della probabilità congiunta di trovarsi in uno stato, e che sia stato trasmesso un valore xi, da cui saturando sugli stati ottenere i valori Pr(xi = 1 ⁄ y) e Pr(xi = 0) ⁄ y). Tale procedura fu poi adottata nel contesto della stima di parametro dei modelli di Markov nascosti (hmm) utilizzati per il riconoscimento del parlato, ma quella è un'altra storia.
[994]Vedi ad es. P. Robertson; E. Villebrun; P. Hoeher, A comparison of optimal and sub-optimal MAP decoding algorithms operating in the log domain, Proc. IEEE ICC ’95
[996]Si adotta il simbolo ∑⊕ per intendere una somma modulo due.
[997]Ci si discosta dalla notazione adottata a pag. 1 in quanto la H definita qui è la trasposta di quella definita in tale sede.
[998]Vedi ad es. S.Lin, D.J.Costello, Error control coding, Prentice-Hall 1983
[999]Infatti H ⋅ xT = H ⋅ (m ⋅ G)T = H ⋅ GT ⋅ mT = (G ⋅ HT)T ⋅ mT = 0(n − k) × k ⋅ mT = 0Tn − k
[1000]In linea di principio per trovare una matrice generatrice Gk × n tale che G ⋅ HT = 0 si può procedere trasformando prima H nella forma canonica di un codice sistematico, modificandone le righe applicando il metodo di Gauss; ciò determina però una G per nulla sparsa, ed una eccessiva complessità di codifica per n elevato. Fortunatamente hanno escogitato metodi più efficienti, anche ricorrendo a codici ldpcnon regolari; per un approfondimento si può vedere W.E.Rayan, An introduction to ldpc code, Univ. of Arizona 2003, ed es. presso http://tuk88.free.fr/LDPC/ldpcchap.pdf.
[1001]La nomenclatura adottata in letteratura indica i nodi-variabile come v-nodes e li rappresenta con la lettera c, mentre quelli di controllo (check-nodes o nodi-fattore) sono rappresentati dalla lettera f. Preferisco qui attenermi alla notazione dell’attuale contesto espositivo.
[1003]Applicando il solito teorema di Bayes, ed omettendo il pedice j per estetica e spazio.
[1004]Questo perché p(x = 1) è la prob. a priori considerata pari a 1⁄2, e quindi p(x = 1)p(y) = p(x = 0)p(y). Imponendo ora p(x = 1 ⁄ y) + p(x = 0 ⁄ y) = 1 si ottiene (p(y ⁄ 1) + p(y ⁄ 1))K = 1, e dunque il risultato.
[1005]In quanto p(1 ⁄ 1) + p(1 ⁄ 0) = 1 − pe + pe = 1
[1006]Il risultato si ottiene imponendo che la stessa normalizzazione valga anche per l’evento complementare, ovvero 1 − q21 = k2(1 − p(0)1)(1 − r14), ma dall’equazione sopra abbiamo anche 1 − q21 = 1 − k2p(0)1r14, ed eguagliando le due espressioni si consegue lo scopo.
[1007]Infatti questa stima non deve essere re-inviata a nessuno, per cui nel caso dell’esempio il nodo x1 calcola p̃(υ)1 = k2p(0)1r12r14 con k2 = 1(1 − p(0)1)(1 − r12)(1 − r14) + p(υ)1r12r14.
[1009]Che può essere svolto incrociando le infomazioni presenti oltre che nel già citato W.E.Rayan, An introduction to ldpc code, anche in T.Strutz, Low-Density Parity-Check codes - An introduction presso
[1015]E’ bene notare esplicitamente che questo massimo è valido solo nel caso in cui non sia possibile modificare la Zg(f). Altrimenti, per un qualunque valore fissato di Zc(f), il massimo di Wzc(f) si ottiene quando Zg(f) → 0.
Sono chiaramente possibili modelli diversi, basati su topologie e relazioni differenti. Esistono infatti circuiti a T, ad L, a scala, a traliccio, a pigreco; le relazioni tra le grandezze di ingresso ed uscita possono essere espresse mediante modelli definiti in termini di impedenze, ammettenze, e parametri ibridi.
Il caso qui trattato è quello di un modello ibrido, con la particolarità di non presentare influenze esplicite dell’uscita sull’ingresso. Qualora il circuito che si descrive presenti una dipendenza, ad esempio di Zi da Zc, o Zu da Zg, questo deve risultare nell’espressione della grandezza dipendente. Viceversa, qualora il circuito presenti in ingresso un generatore controllato da una grandezza di uscita, il modello non è più applicabile.
[1017]L’ultimo passaggio tiene conto che (omettendo la dipendenza da f):
[1018]L’attenuazione supplementare (pag. 1) può esprimere il peggioramento dovuto al mancato verificarsi delle condizioni di massimo trasferimento tra le impedenze di uscita e di ingresso delle reti affacciate.
[1020]A volte si incontra anche il termine figura di rumore, derivato dall’inglese noise figure (che in realtà si traduce cifra di rumore), e che si riferisce alla misura di F in decibel.
[1022]Con SNRi = αSNR0 = αPRPn, dove Pn = kTeiW è la potenza di rumore nella banda di messaggio W, PR è la potenza ricevuta da un ripetitore (uguale per tutti se le tratte sono uguali), e α è un fattore che dipende dal tipo di modulazione (cap. 14).
[1023]I casi di segnale di banda base e di segnale modulato sono trattati nel seguito in modo unitario, facendo riferimento solo ai primi, ovvero alle c.a. di b.f. nel caso di segnale modulato.
[1025]Operazione necessaria se il canale cambia da un collegamento all’altro, come nel transito in una rete commutata, o nel caso di una comunicazione radiomobile.
[1026]Si veda l’eq. (10.172) a pag. 1, tralasciando il termine di fase lineare necessario a rendere hR(t) causale.
[1027]Sia che si abbia HR(f) = HT(f) = √G(f) come per il caso del ricevitore ottimo (§ 15.5), sia nel caso in cui HT(f) = G(f), e HR(f) ha il solo scopo di filtrare il rumore. C’è poi l’aspetto trattato al § 15.5.1 relativo all’equalizzazione distribuita, che prevede di ripartire il compito in parti uguali tra i due lati, e che necessita di un canale di ritorno per comunicare al trasmettitore le stime operate a destinazione.
[1028]Che equivale all’impulso g̃(t) di eq. (21.1) a pag. 1
[1029]La (21.135) rappresenta l’uscita di un filtro firanti-causale, dato che z(t) dipende da valori futuri di ingresso, fino a y(t + Nτ), mentre l’espressione causale che rispecchia la notazione usata nella figura dovrebbe essere z(t) = ∑Nn = − Ncny(t − nτ − Nτ), che corrisponde ad un semplice ritardo dell’ingresso pari a Nτ, trascurato per semplicità di notazione nel seguito.
[1030]Dato che per evitare aliasing (§ 4.1.1) la frequenza di campionamento fc = 1τ deve risultare maggiore del doppio della massima frequenza presente in y(t), scegliamo fc = 2fs, ovvero τ = Ts⁄2. Infatti, un segnale dati di banda base a coseno rialzato occupa una banda a frequenze positive pari a B = fs2 (1 + γ), e dunque scegliendo fc = 2fs ci cauteliamo anche nel caso di γ = 1. La scelta di porre τ < Ts viene indicata anche con il termine di fractionally spaced equalizer o fse.
[1031]Piuttosto che l’azzeramento dell’errore, come nell’approccio zero forcing.
[1032]Tale errore dipende sia dal rumore presente in ingresso che dall’isi introdotta dal canale, le cui potenze sono quindi minimizzate in forma congiunta.
[1034]In realtà la minimizzazione ha successo solamente se σ2e è una funzione convessa (vedi https://it.wikipedia.org/wiki/Funzione_convessa) dei cn, ma più avanti (pag. 1) troveremo che questo è proprio il nostro caso.
[1035]In effetti, RY(n) e RYA(n)non sono note al ricevitore, ma nell’ipotesi di stazionarietà ed ergodicità per y(t) ed an, possono essere stimate a partire da una fase iniziale di apprendimento durante la quale viene trasmesso un segnale di test associato ad una sequenza {ak} nota al ricevitore, in base alla quale quest’ultimo calcola le medie temporali
[1037]Viene applicata l’equivalenza tra convoluzione nel tempo e prodotto in frequenza, nonché quella tra trasformata della correlazione e densità di potenza.
[1038]Analogamente all’energia mutua (§ 3.2), PYA(f) esprime una similitudine tra due segnali e/o processi, frequenza per frequenza. Laddove risulti PYA(f) = 0, i segnali sono ortogonali in tale regione di frequenze.
[1039]Ricordando che y(t) = ∑kakh(t − kTs) + ν(t) in cui h(t) è la risposta impulsiva complessiva h(t) = hT(t) * hc(t) * hR(t) (vedi fig. 18.16) e ν(t) rappresenta l’effetto di HR(f) su n(t), dalla (21.143) scriviamo RY(n) = E{y(mTs)y(mTs + nτ)} e quindi esprimendo h(mTs − kTs) come h((m − k)Ts) si ottiene
i cui termini dell’ultima riga risultano nulli se i simboli am sono statisticamente indipendenti dai campioni di rumore, ed almeno uno dei due processi è a media nulla. Essendo inoltre E{akai} = 0 per i ≠ k, il termine con la doppia sommatoria si riduce a
e come prima troviamo E{ν(mTs − nτ)am} = 0, mentre della sommatoria rimane il solo termine k = m.
[1041]In particolare, scegliendo HR(f) = rect2fs(f) si ottiene che i campioni di rumore presi con intervallo τ = 1⁄2Ts sono incorrelati e dunque statisticamente indipendenti perché gaussiani. Infatti Pν(f) = N02|HR(f)|2 e dunque Rν(τ) = N022fssinc(2fsτ), che quindi si azzera per τ = 1⁄2Ts, vedi § 7.2.4. In tal caso la (21.149) diviene He(f) = σ2aH*(f)σ2a|H(f)|2 + σ2υ.
[1042]Per quanto il risultato sembri banale, la dimostrazione non è troppo diretta, e si basa sullo scomporre il termine
in cui si tiene conto che Ts = 2τ, mentre gli am sono prodotti uno per simbolo; introducendo R’A(n) = ⎧⎨⎩RA⎛⎝n2⎞⎠npari 0 altrimenti e con qualche cambio di variabile si ottiene infine ∑qR’A(q)RH(n − q) che ha l’aspetto rassicurante della convoluzione, da cui scaturisce il risultato.
[1043]Ciò deriva dal fatto che [RY(n − k)] = B è legata alla matrice di covarianzaΣY (§ 6.7.3) dalla relazione [RY(n − k)] = ΣY + m2Y (vedi eq. (10.152) a pag. 1 in condizioni stazionarie), e dato che ΣY è una matrice definita positiva lo è anche [RY(n − k)], non decadendo la proprietà in seguito alla somma per una quantità positiva (m2Y). Pertanto la forma quadratica∑Nn = − N∑Nk = − NcnckRY(n − k) è ovunque convessa (vedi § 6.7.3), e dotata di un unico minimo globale. Questa proprietà permane anche considerando gli altri due termini della (21.150) che concorrono al valore di σ2e(c), essendo questi rispettivamente lineari in c e costanti, e che dunque non ne modificano la convessità.
[1044]Considerando la sequenza informativa am a media nulla, si ha E{a2m} = σ2a.
avendo prima sostituito d = Bc̃ e poi il contrario, e valutato c̃t = (B− 1 d)t = dt(B− 1)t = dtB− 1 in quanto B è una matrice simmetrica, così come la sua inversa.
[1046]Considerando z a media nulla, si ha σ2z = E{z2} = E{c̃tyytc̃} = c̃tE{yyt}c̃ = c̃tBc̃.
[1049]Coma abbiamo discusso, il minimo è unico, dunque raggiungibile da dovunque si parta.
[1050]Una regola pratica suggerisce di porre Δ = 15(2N + 1) PY in cui PY è la potenza ricevuta di segnale più rumore. Valori maggiori possono accelerare la convergenza, ma dare anche luogo ad instabilità della soluzione, mentre valori più piccoli rallentano la convergenza, ma possono produrre errori finali minori.
[1052]Un interessante modo di interpretare la (21.155) si basa sull’osservare che la minimizzazione di (21.141) ovvero l’azzeramento del gradiente (21.142)gm = 0 comporta che ciascun valore di errore em deve essere ortogonale (in senso statistico, vedi § 7.7.2) a tutte le osservazioni ym − N, ⋯, ym + N da cui dipende la stima z(mT), ossia le 2N + 1 coppie di sequenze devono essere incorrelate, e quindi prive di legami di tipo lineare.
[1053]La sequenza dei simboli trasmessi è nota all’inizio della trasmissione, e spesso generata nella forma di una sequenza pseudo-noise. Durante la fase di apprendimento l’algoritmo viene lasciato iterare arrivando alla stima dei coefficienti c; terminata questa fase ha inizio la trasmissione vera e propria, e l’equalizzatore commuta su di una modalità dipendente dalle decisioni, in cui l’errore em è valutato rispetto ai valori ~am emessi dal decisore: se la probabilità di errore per simbolo non è troppo elevata, la maggior parte delle volte la decisione è esatta, ed il metodo continua a funzionare correttamente.
[1054]Poniamo di eseguire l’aggiornamento (21.156) dei coefficienti c ogni K periodi di simbolo: otterremmo cm + K = cm − Δ∑K− 1k = 0em + kym + k, in cui il termine sommatoria risulta in effetti proporzionale alla stima di E{emym}, almeno più di quanto non appaia il termine emym che compare isolato nella (21.156).
[1055]Possiamo infatti notare che alla m − esima iterazione della (21.156) il coefficiente cn viene aumentato se em e yn sono di segno opposto, e diminuito se concorde. Ovvero: se l’uscita è piccola allora em = z(mTs) − am < 0, e il contributo cn dell’n-esima memoria viene aumentato se ym(n) è positivo, o diminuito se ym(n) è negativo; viceversa, se em = z(mTs) − am > 0 (uscita troppo grande) il valore di cn viene aumentato se ym(n) è negativo, e diminuito nel caso opposto. Inoltre, se cn e ym(n) hanno lo stesso segno contribuiscono a zm come un termine positivo, oppure come un termine negativo se di segno diverso. Infine, la colonna δ esprime la variazione del contributo di cnym(n) a zm, frutto della variazione di cn e dei segni di cn e di ym(n). Come si può verificare, δ è sempre tale da contribuire alla riduzione di em.
em
ym(n)
cn
cn
cnym(n)
δ
+
+
+
+
+
+
−
−
+
−
+
−
+
−
−
+
−
+
+
+
−
+
−
−
−
−
+
−
−
−
−
+
[1056]Ovvero il filtro fir ha solo i ritardi relativi ai coefficienti cn con n ≥ 0, così come la sommatoria (21.135).
[1057]Anche qui, nella fase di apprendimento sono usati i valori am noti a priori, mentre in quella successiva si usano quelli ãm emessi dal decisore, supposti per la maggior parte esatti.
[1058]A questo proposito, è opportuno che HR(f) sia realizzato come un passa basso e non come un filtro adattato, o nel caso di rumore colorato in ingresso, che si effettui una operazione di sbiancamento.
[1059]Tratta da J.G. Proakis, M. Salehi, Communication systems engineering, 2nd Ed., 2002 Prentice-Hall
[1060]Nonostante mmse tenti di minimizzare σ2e tenendo conto sia dell’isi che del rumore, le sue prestazioni degradano in presenza di canali che manifestano profonde attenuazioni per alcune frequenze. D’altra parte per canali meno problematici, le sue prestazioni possono avvicinarsi a quelle dell’mlsd.
[1062]Come definito al § 14.1.4, SNR0 dipende solo dalle caratteristiche del collegamento, mentre il coefficiente α rappresenta la dipendenza dal tipo di modulazione adottata, e differisce da 1 nei casi di modulazione fm, am-pi e am-pps.
[1063]Notiamo che Gs è definito come ingresso/uscita, contrariamente agli altri guadagni. Infatti, non è una grandezza del collegamento, bensì una potenzialità dello stesso.
[1067]Questa circostanza è comune con le trasmissioni in fibra ottica (vedi fig. 19.16 a pag. 1), ed è legato alla presenza nel mezzo di una componente dissipativa, in questo caso la resistenza.
[1068]... le famose interferenze telefoniche, praticamente scomparse con l’avvento della telefonia numerica (PCM), da non confondere con ... le intercettazioni.
[1069]Omettiamo di indicare di operare in dB per compattezza di notazione.
[1070]Ovvero, tali che 2dβ(f) = kπ con k = 0, 1, 2, …
[1071]Può ad esempio rendersi necessario “tarare” un trasmettitore radio, la prima volta che lo si collega all’antenna.
[1072]E’ questa la fase in cui il modem anni 90 che si usava per collegarsi al provider Internet emetteva una serie di orribili suoni... corrispondenti alla ricezione della sequenza di apprendimento, vedi anche la nota 1035 di pag. 18.4.
[1073]Ovvero, una sezione capace di reggere il peso del cavo lungo una campata.
[1077]Indicata anche come intensity modulation and direct detection (imdd). In realtà è anche possibile adottare tecniche di modulazione numerica come psk e qam, che richiedono una detezione coerente (vedi ad es. https://doi.org/10.1364/OE.16.000753), ma tali sistemi sono tuttora in fase sperimentale, e l’esposizione prosegue per il caso universalmente adottato.
[1079]Qui descritto in termini di ottica geometrica, approssimazione valida per un diametro del core ben maggiore di quello della λ incidente. Per dimensioni comparabili, occorre invece ricorrere alla teoria di propagazione delle onde, in cui non ci avventuriamo.
[1080]I diversi valori di n sono ottenuti drogando differentemente la sezione della fibra.
[1082]In realtà questa interpretazione data in chiave di ottica geometrica è una semplificazione, ed in effetti i modi di propagazione sono quelli che risultano dalla applicazione delle equazioni di Maxwell alla propagazione in fibra.
[1083]Si passa dai 50 μm per le fibre multimodo, a circa 8 μm nel caso monomodo.
[1084]Ovvero molecole e ioni di altri elementi. Ad esempio, lo ione oh- è quello che determina il picco di assorbimento a 1.39 μm.
[1085]Il fenomeno descritto viene detto dispersione da materiale o DM, oltre al quale ne interviene anche un altro detto dispersione di guida d’onda o DW, che dipende da fattori geometrici come la dimensione del core e l’apertura numerica.
[1086]Il fenomeno della dispersione cromatica è l’equivalente ottico della distorsione di fase (o distorsione di ritardo) introdotta al § 8.2 per i segnali elettrici.
[1087]D’altra parte, dato che i termini DM e DW descritti alla nota 1085 hanno una diversa dipendenza da λ, variando i loro contributi a D0 si è riusciti a realizzare un tipo di fibra detto dispersion-shifted (o ds) che presenta il minimo di dispersione in terza finestra, vedi fig. 19.17.
[1090]In particolare, con laser detti distributed feedback (dfb) si riesce ad eccitare un solo modo di emissione, producendo una luce di fatto monocromatica, la cui effettiva λ può anche essere variata in tutta la gamma che va dalla II alla III finestra.
[1091]La potenza emessa da un laser non può aumentare a piacimento: oltre un certo valore intervengono infatti fenomeni non lineari, e la luce non è più monocromatica, causando pertanto un aumento della dispersione cromatica.
[1092]La presenza di valori di dispersione negativi in fig. 19.17 può destare una legittima curiosità. Ma non si tratta di un fenomeno anticausale! Come indicato dall’unità di misura psKm ⋅ nm di D0, la dispersione cromatica rappresenta la derivata di un ritardo rispetto a λ, derivata che dipende essa stessa da λ. Dunque, come i suoi valori positivi indicano che il ritardo aumenta con λ, e quindi le frequenze più basse (con λ maggiore) arrivano dopo di quelle più alte, i valori negativi di D0 individuano il fenomeno inverso, ovvero che il ritardo aumenta con il diminuire di λ, ovvero le frequenze più alte arrivano dopo (di quelle basse).
[1093]In questo senso, il prodotto banda-lunghezza costituisce un parametro di sistema che tiene conto di un concorso di cause. Un po’ come il concetto di tenuta di strada di una autovettura, che dipende da svariati fattori, come il peso, i pneumatici, la trazione, il fondo stradale....
[1094]Tuttavia il dimezzamento della durata di un bit causa una perdita di potenza di 3 dB, in base alle considerazioni riportate a pag. 1.
[1097]La consuetudine del dimensionamento dei collegamenti in fibra ottica porta a considerare ogni bit in transito nella sua purezza, senza cioè confidare (o meno) nella presenza di elaborazioni terminali come la codifica di canale, e/o il numero di bit/simbolo. In tale prospettiva, si ritiene che un valore di Pe = 10 − 11 sia più che sufficiente a qualunque tipo di trasmissione: un errore ogni 100.000 miliardi di bit!
[1098]Questo metodo di calcolo è approssimato, in quanto nei trasduttori avvengono fenomeni non-lineari che legano il livello di potenza del rumore, alla potenza di segnale ricevuta. Trascurando questo effetto, si può applicare l’espressione (21.173).
[1099]Anche se, relativamente a queste prime fasi, si è soliti distinguere tre generazioni, corrispondenti all’uso delle corrispettive finestre, vedi fig. 19.16.
[1101]La natura del rumore è ottica anziché elettrica, ed è indicato come emissione spontanea amplificata (ase) in quanto ha origine dai fotoni che si producono in modo spontaneo (anziché stimolato come nei laser), e che poi interagiscono con gli ioni di drogante producendone l’amplificazione.
[1103]I dispositivi reali basano il loro funzionamento su fenomeni di diffrazione e interferenza.
[1104]Si sfrutta il principio “dell’arcobaleno” (ma che a me ricorda The dark side of the moon...), in quanto uno stesso materiale (il prisma) presenta indici di rifrazione differenti per lunghezze d’onda diverse, e quindi è in grado di focalizzare più sorgenti di diverso colore in un unico raggio.
[1105]Sono anche prodotte delle fibre prive dello ione oh responsabile del picco di assorbimento a 1.4 μm, dette dry fibre, per le quali è possibile allocare portanti in una regione veramente estesa!
[1106]Le portanti sono centrate attorno f0 = 193 THz. Ricordando che λ = v⁄f0 e ponendo v ≃ c = 3 ⋅ 108 m/sec, otteniamo che alla f0 corrisponde λ = 3 ⋅ 108⁄193 ⋅ 1012 = 1554 nm, mentre una spaziatura tre le f0 di 100 GHz equivale ad un Δλ = c(1⁄f2 − 1⁄f1) ≃ 0.8 nm; pertanto, 40 portanti occupano un intervallo di 32 nm, e dunque entrano perfettamente nei 1565 - 1525 = 40 nm della banda c.
[1107]Ancor più grave se l’irregolarità si ripete uguale su diverse sezioni consecutive di amplificazione, e che può essere affrontata interponendo filtri ottici progettati in modo da compensare le differenze di guadagno.
[1108]Facendo riferimento alla fig. 19.17, notiamo come per una fibra normaleD0 in terza finestra sia positivo, ed aumenti con λ. Per invertire questo fenomeno, la fibra compensatrice oltre ad avere un D0 negativo, deve anche variarne il valore con un andamento complementare a quello della fibra da compensare, in particolar modo nel caso di trasmissione dwdm.
[1110]In questo modo si realizza una rete di tipo broadcast (ovvero non switchata) qualora ogni nodo terminale emetta su di una sua propria λ, e riceva quelle emesse dagli altri nodi.
[1111]Come la cross gain modulation che si manifesta neisoa, il cui il guadagno satura con la potenza in transito. Quando al segnale ook in arrivo con λ1 è mescolato quello (debole e continuo) di pompa con λ2, il guadagno satura nei periodi di bit di λ1, mentre invece quando λ1 è spenta, λ2 viene amplificato. Un filtro ottico rimuove λ1, e la sua informazione è stata trasferita su λ2, con segno invertito; altri schemi risolvono anche questo aspetto. Altri dispositivi fanno uso dell’effetto fwm, in cui la presenza di λ1 e λp = 2λ1λ2λ1 + λ2 (di pompa) produce la comparsa di λ2 in uscita.
[1112] Vedi https://it.wikipedia.org/wiki/MEMS. Ogni specchietto ha dimensioni inferiori al mm2, e riflette o meno la luce a seconda della sua disposizione controllata da micro-attuatori, il tutto realizzato direttamente su dei chip in silicio o polisilicio. Adottando una architettura di commutazione a due stadi è possibile realizzare strutture tridimensionali come quella mostrata in figura, che consente di adottare un numero di specchi pari a 2N (dato che un mems altera l’indice di riga, e l’altro di colonna) contro gli N2 relativi al caso di una matrice bidimensionale (i cui flussi entranti ed uscenti sono disposti rispettivamente sui due lati di un mems squadrato), e di mantenere le differenze di percorso ottico entro limiti ridotti.
[1117]Dato che tale conversione avviene unicamente a seguito delle variazioni del segnale, è esclusa la presenza di una componente continua, e per questo (ma non solo) il segnale può unicamente essere di natura modulata.
[1120]Il processo di focalizzazione parabolica, comunemente usato ad esempio nei fanali degli autoveicoli, era ben noto ad Archimede da Siracusa, che lo impiegò negli specchi ustori...
[1121]Si tratta di un concetto del tutto analogo alla “frequenza di taglio a 3 dB”, ma applicata ad un dominio spaziale con geometria radiale.
[1122]Indicando con Ar l’area reale (fisica) dell’antenna, risulta Ae = ρAr, con ρ < 1. La diseguaglianza tiene conto delle perdite dell’antenna, come ad esempio le irregolarità nella superficie della parabola, o l’ombra prodotta dalle strutture di sostegno. Ovviamente anche l’antenna trasmittente presenta perdite, ed il valore GTmisurato è inferiore a quello fornito dalla (21.175), a meno di non usare appunto il valore di area efficace.
[1123]La costante c = 3 ⋅ 108 metri/secondo rappresenta la velocità della luce nel vuoto, ossia la velocità di propagazione dell’onda elettromagnetica nello spazio.
[1124]Mantenendo fissa la dimensione delle antenne si ottiene il risultato che trasmissioni operanti a frequenze più elevate permettono di risparmiare potenza. Purtroppo però, guadagni di antenna superiori a 30-40 dB (corrispondenti a piccoli valori di θb) sono controproducenti, per i motivi esposti al § 20.3.1.
[1128]Lo stesso fenomeno di diffrazione è egualmente valido per l’energia luminosa, e può essere sperimentato illuminando una fessura, ed osservando le variazioni di luminosità dall’altro lato.
[1131]Anche, ma non solo, in concorso con la riflessione operata da masse d’acqua, come mostrato in figura.
[1132]L’elevata attenuazione chilometrica presente a 60 GHz può essere sfruttata nei sistemi di comunicazione allo scopo di riusare una stessa banda di frequenze per altri utenti, anche a breve distanza.
[1133]L’assorbimento della potenza di un’onda elettromagnetica a 2.45 GHz da parte delle molecole d’acqua è il principio su cui si basa il funzionamento di un forno a microonde.
[1134]Nel caso in cui una massa d’aria calda ne sovrasti una più fredda, si verifica una inversione dell’indice di rifrazione, e l’onda elettromagnetica si propaga come lungo una guida d’onda, vedi anche http://en.wikipedia.org/wiki/Tropospheric_propagation.
[1135]Ad esempio, desiderando 1T > 1 MHz, si ottiene TMax = 1μsec; se l’onda radio si propaga alla velocità c = 3 ⋅ 108 m/sec, la massima differenza di percorso vale Δmax = c ⋅ TMax = 3 ⋅ 108 ⋅10 − 6 = 300 metri.
[1137]Alla frequenza di 1 GHz si ha λ = 30 cm e per una distanza di 100 metri dal trasmettitore si ottiene un raggio massimo dell’ellissoide pari a 12√.3 ⋅ 100 = 12√30 ≃ 2.7 metri.
[1139]Mentre il fading produce una attenuazione variabile sul segnale, la stessa variabilità delle condizioni di propagazione può portare a livelli di interferenza variabili, causati da altre trasmissioni nella stessa banda. La variabilità temporale della qualità del segnale ricevuto, in particolare quella veloce (vedi § 20.4.6), produce errori a burst, che possono essere corretti mediante codifica di canale ed interleaving (vedi § 15.6.2.3).
[1140]Considerando le v.a. statisticamente indipendenti.
[1142]La d.d.p. gaussiana discende dall’ipotesi che uno dei cammini multipli pervenga al ricevitore con una potenza nettamente predominante rispetto agli altri. In questo caso l’inviluppo complesso x del segnale ricevuto è adeguatamente rappresentato da una v.a. di Rice (vedi pag. 1) x = a + r, in cui |r| ha d.d.p. di Rayleigh e rappresenta l’effetto di molte cause indipendenti, relative ai cammini multipli, ed a è l’ampiezza della eco di segnale ricevuta con la maggiore ampiezza. Se a≫|r| possiamo scrivere
in quanto log(1 + α) ≃ α con α≪1, e quindi as(dB) ha media 10log10a2 (compresa nel path loss) ed esibisce una d.d.p. gaussiana, la stessa di rc.
[1143]Anche se l’aumentare dell’altezza di una antenna ne estende la relativa area di copertura, in ambito urbano questo corrisponde ad una maggiore variabilità delle effettive condizioni operative.
[1144]A frequenza di 1 Ghz, si ha λ ≃ 30 cm. Questo fenomeno può essere facilmente sperimentato quando, durante una sosta al semaforo, si perde la sintonia di una radio fm, riacquistandola per piccoli spostamenti dell’auto; un altro esempio può essere la ricerca del campo per poter telefonare.
[1145]La (21.183) discende dal considerare un generico segnale modulato x(t) = a(t)cos(2πf0t + φ(t)) ed il suo inviluppo complesso x(t) = a(t)ejφ(t): per ogni sua replica ritardata xn(t) = x(t − τn) possiamo scrivere
[1146]Si consideri che il risultato dell’esempio di pag. 1 valuta i ritardi in gioco dell’ordine di grandezza delle decine di nanosecondi, mentre (ad esempio) ad un segnale x(t) limitato in banda a 10 KHz corrisponde un periodo di campionamento Tc = 50 μsec.
[1147]Se ad esempio i ritardi τn sono dell’ordine di 10 − 8, l’ipotesi è valida per f0 > 100 MHz, quasi 1⁄10 delle frequenze a cui operano i radiomobili.
[1148]Per semplicità nel seguito consideriamo x(t) a potenza unitaria, in modo che ρ2 sia proprio la potenza istantanea ricevuta.
[1149]Impostando il cambiamento di variabile s = ρ2 si possono applicare le regole viste al § 6.4, individuando la funzione inversa come ρ = √s, la cui dds ρ(s) fornisce 12√s.
Pertanto la d.d.p. della nuova v.a. s vale
In figura si mostra il processo di costruzione grafica che produce una d.d.p. esponenziale negativa a partire dal quadrato di una d.d.p. di Rayleigh.
[1150]A tal fine osserviamo che il collegamento va fuori servizio quando la potenza ricevuta è inferiore alla sensibilità del ricevitore WRmin, e la probabilità di questo evento si esprime come p = Pr(ρ2 < WRmin) = 1 − exp⎛⎝ − WRminmρ2⎞⎠, essendo appunto ρ2 una v.a. a d.d.p. esponenziale con media mρ2 = 2σ2, e tenendo conto dell’eq. (26.3) a pag. 1. Al tempo stesso, mρ2 = E{ρ2} rappresenta la potenza media ricevuta, ovvero lo zero dB di fig. 20.16: esprimendo dunque il margine M (non in dB) come il rapporto tra la potenza media ricevuta e la sensibilità del ricevitore M = mρ2WRmin, si ottiene p = 1 − e− 1M, e quindi − 1M = ln (1 − p) e, passando ai decibel, − 10log10M = 10log10( − ln (1 − p)), da cui la (21.187).
[1151]Infatti in tal modo la percentuale di tempo p viene spalmata su di un secondo, e suddivisa per il numero (medio) di volte (in un secondo) per cui avviene che ρ2 < WRmin. Esempio Se p = 0.1 ed Na = 5 fading/sec allora τa = 0.1⁄5 = 0.02, ossia 20 msec, ripartendo i 100 msec (10% di 1 secondo) sui 5 affievolimenti medi.
[1152]Visto che la causa nota per cui H(f) ≠ cost è l’eccessiva banda del segnale, a ciò corrisponde un maggior contenuto di alte frequenze e dunque una maggiore velocità di variazione temporale.
[1153]Il cambiamento negli indici della sommatoria è legato a considerare l’origine dei tempi in corrispondenza al primo arrivato dei cammini multipli.
[1154]Si sottintende che T sia minore dell’inverso del doppio della banda di Z(t), ovvero T < 1⁄2W.
[1155]Libera traduzione del termine power delay spread.
[1156]Tipicamente di 1⁄4 della lunghezza d’onda relativa alla portante adottata.
[1161]Approssimiamo θ come uguale in X e Y, nell’ipotesi che S sia molto lontana rispetto a d.
[1162]Il rapporto n = △l⁄λ indica quanti periodi di portante entrano in △l, che moltiplicato per 2π fornisce appunto la differenza tra le fasi di arrivo, nulla se n è intero.
[1163]La (21.199) si ottiene applicando alla (21.198) la definizione di deviazione di frequenza fd come differenza fd(t) = fi(t) − f0 in cui la frequenza istantanea fi è data dalla (14.49) come fi(t) = f0 + 12πddtα(t)
[1165]La stessa analisi è valida anche nel caso di un ricevitore fermo ma con i riflettori in movimento, come per la la riflessione ionosferica: in tal caso l’espressione si scrive come fnd = f0vnccosθn, considerando cioè la possibilità che i riflettori abbiano velocità diverse tra loro.
[1166]Notiamo che se θn = 0 ci stiamo riferendo al caso in cui il moto si realizza lungo la congiungente tra ricevitore e sorgente (o riflettore).
[1167]Notiamo che il risultato è diretta conseguenza della condizione di scattering isotropo: infatti la (21.200) costituisce un processo armonico (pag. 1) quando − π < θn < π con d.d.p. uniforme, ed al tempo stesso rappresenta la deviazione della frequenza istantanea fi rispetto ad f0 (§ 11.2.2), e dunque si verifica l’effetto
di conversione am-fm descritto al § 12.3.3.3. Se viceversa esistono ad es. due soli cammini, il primo diretto (S) e l’altro riflesso (R) con il mobile nel mezzo, Py(f) corrisponde a due impulsi in ± fD.
[1168]In questo modo si ottiene una trattazione unificata sia per il caso di un ricevitore mobile in un contesto statico, sia per quello di un ricevitore fermo con riflettori in movimento. In entrambi i casi il doppler spreadfD può essere effettivamente misurato al ricevitore, in presenza di una portante non modulata.
[1169]Ciò avviene perché in pratica è come se due simboli consecutivi pervenissero attraverso due differenti canali, e dunque non è possibile eseguire operazioni di media.
[1170]Infatti le due condizioni W < Bc e Ts < Tc possono essere riscritte in base alle (21.196) e (21.202) come Wστ < 0.1 e fDTs < 0.1, e moltiplicando queste ultime tra loro si ottiene WστfDTs < 0.01. Ponendo quindi W ≃ 1⁄Ts (eq. (21.5)) si ottiene la condizione fD ⋅ στ < 0.01, in cui sostituendo fD = 0.1⁄Tc e στ = 0.1⁄Bc (di nuovo in virtù delle (21.196) e (21.202)) si ottiene la seconda relazione.
[1171]Ovvero contesto rurale, urbano, indoor, oltre ovviamente ai fenomeni legati al movimento.
[1172]Come osservato alla nota precedente W ≃ 1⁄Ts, da cui W ⋅ Ts ≃ 1
[1173]Trovandosi il prodotto sopra l’iperbole unitaria.
[1174]A causa delle fluttuazioni di ampiezza legate al fading non è possibile ricorrere a modulazioni di tipo qam, e nel seguito sono prese in considerazione unicamente modulazioni di fase e di frequenza.
[1175]Il dominio di integrazione è rappresentato in figura, e anziché muoversi prima lungo y dalla retta
y = ρ√Eb⁄N0 ad infinito ottenendo una funzione di ρ, e quindi integrare con 0 < ρ < ∞, ci si muove in orizzontale tra ρ = 0 e ρ = y√N0⁄Eb ottenendo una funzione di y, quindi integrata con 0 < y < ∞. Verifichiamo quindi che
[1177]Ottenuti grazie ad una tecnica di stima di canale.
[1178]I correlatori del Rake sono anche detti fingers, ovvero dita (del rastrello), ognuno dei quali utilizza una pn con un ritardo pari a quello di uno degli echi del multipath, realizzando uno schema di ricezione a diversità di tempo.
[1179]In pratica nello schema in figura la pn è allineata al ritardo maggiore τn, mentre i ritardi mostrati vanno da zero (per correlare la replica più ritardata) alla massima differenza τn − τ0.
[1180]Ciò riduce il peso dei contributi relativi a rami su cui perviene un segnale di ampiezza ridotta, la cui uscita dipende in misura maggiore dal rumore.
[1181]In altre parole la velocità aggregata aumenta linearmente con il numero delle antenne, inteso come il numero minimo tra quelle di trasmissione e quelle di ricezione.
[1183]Al contrario, le tecniche di broadcast analogico (cap. 25) su scala nazionale prevedono l’uso di regioni di frequenza diverse per lo stesso canale trasmesso in bacini di propagazione differenti, in cui questi ultimi sono definiti dalle condizioni di visibilità legate alla conformazione del territorio.
[1185]I valori reale e immaginario di sk rappresentano le coordinate nel piano dell’inviluppo complesso di un punto appartenente alla costellazione A scelta per la trasmissione, vedi ad es. la figura a pag. 1.
[1186]In virtù della (14.67) scriviamo y(t) = 12h(t) * x(t) = 12h ⋅ x(t) dato che per fading piatto si ha h(t) = h ⋅ δ(t); a sua volta (eq. (14.21)) h = H(f) = 2H+(f + f0) = 2H(f0) e dunque y(t) = 12 ⋅ 2H(f0) ⋅ x(t) ovvero, ponendo x(tk) = sk si ottiene rk = y(tk) = H(f0) ⋅ sk.
[1187]Essendo n una v.a. complessa n = nc + jns, otteniamo σ2n = E{nn*} = E{n2c + n2s} = 2σ2nc = 2σ2ns, in accordo con i risultati del § 14.1.3.
[1188]Di qui in poi sarà possibile riferirsi agli istanti di simbolo come all’“uso del canale”, ovvero pensando alla trasmissione di un simbolo snT − dimensionale come ad un singolo uso del canale.
[1189]σ2h dipende dalla somma delle intensità con cui le repliche del segnale trasmesso dall’antenna j giungono all’antenna i.
[1190]Nel caso di un telefono cellulare sono presenti numerosi riflettori nelle vicinanze del ricevitore, producendo neidownlink fading incorrelati per distanze tra le antenne dei mobili di circa mezza lunghezza d’onda. Viceversa nel caso della base station fissa con cui il cellulare comunica, i cammini multipli dell’uplink hanno quasi tutti origine nei pressi del mobile, riducendo la gamma di angoli di incidenza dei raggi ricevuti, che iniziano ad essere indipendenti per distanze di decine di lunghezze d’onda: pertanto alla base station sono necessarie antenne molto più lontane tra loro.
[1191]Il valore Es individua l’energia per simbolo, e misura il valore di E{s2}.
[1192]Istantaneo perché dipende da hi che in linea di principio può variare da istante ad istante; per simbolo perché Esσ2n = PsPn1fs.
[1193]Vedi D.G. Brennan, Linear Diversity Combining Techniques. Proc. IEEE, Vol. 91, N. 2, Feb 2003.
[1194]Valida per un intervallo temporale minore del tempo di coerenza del canale.
[1195]E’ proprio in base a questa considerazione che il vettore gaussiano complesso costituito da campioni dell’inviluppo complesso di un processo di rumore passa banda prende il nome di processo circolare.
[1196]Nel senso che dato che (come stiamo per vedere) γMR dipende dagli hi che sono v.a., è una v.a. anch’esso. Ma allo stesso tempo gli hi sono considerati costanti per tutto il tempo di coerenza, ed altrettanto accade a γMR.
[1197]Con l’accortezza che per grandezze complesse il quadrato si valuta come prodotto per il coniugato, ossia z2 = z ⋅ z* = (ℜ{z})2 + (ℑ{z})2.
[1198]Nel senso di pervenire ad una espressione di Pe(γMR) e poi calcolarne il valore atteso rispetto alla v.a. γMR, che ora non è più esponenziale, bensì chi quadro (§ 6.6.5) con 2nR gradi di libertà, essendo le hi v.a. gaussiane complesse.
[1199]Vedi ad es. il riferimento della nota 1193; per lo stesso risultato sussiste inoltre anche un’argomentazione basata sugli autovettori della matrice h ⋅ h† (l’apice † indica il trasposto coniugato), vedi B. Holter, G.E. Oien, The Optimal Weights of a Maximum Ratio Combiner using an Eigenfilter Approach, Proc. 5th IEEE Nordic Signal Processing Symposium, Hurtigruten, 4-6 October 2002, reperibile presso https://www.ux.uis.no/norsig/norsig2002/Proceedings/papers/cr1099.pdf, e che esamina anche il caso in cui il rumore si presenti con potenze differenti sui diversi rami.
[1200]Rimane infatti la necessità di rifasare i rami per ottenere una somma coerente.
[1201]Dove per uguali si intende |wi| = 1⁄nR senza riguardo per |hi|, causando nella (21.224) l’insorgenza di un fattore moltiplicativo, che può essere ignorato nel caso di una modulazione psk ovvero con costellazione circolare.
[1202]Aleatori a componenti gaussiane a media nulla etc etc...
[1203]In realtà ad es. nella modulazione cofdm (§ 16.8.10) la ridondanza viene distribuita anche sulle diverse sottoportanti, dunque in frequenza. Ma ci torniamo al § 21.7.2.
[1204]Qualora la trasmissione nelle due direzioni avvenga sulla stessa portante è necessario che le parti si alternino nei ruoli (time-duplex), mentre invece possono trasmettere e ricevere allo stesso tempo se si adottano frequenze differenti (frequency-duplex).
[1205]Anche perché le ridotte dimensioni dei device mobili rendono problematico realizzare antenne sufficientemente distanziate.
[1207]Dunque le codeword C sono costituite dai simboli di sorgente stessi, una sorta di codice a ripetizione, se non fosse che ora ci sono anche i coniugati, e quel segno cambiato... in effetti la scelta di tab. 21.1 è un caso particolare di una regola più generale, ovvero costruire gli elementi di C come combinazione lineare dei simboli si, e dei loro coniugati.
[1208]Svolgendo infatti i calcoli per una di esse, ad esempio n1̃ = 1α(h * 1n1 + h2n * 2), in virtù dell’incorrelazione tra n1 ed n2 si ottiene
[1209]Si ribadisce che per grandezze complesse il modulo quadro si calcola come prodotto per il coniugato, dunque la (21.233) diviene (s − s̃i)2 = (s − s̃i)(s* − s̃ * i) = ss* + s̃is̃ * i − ss̃ * i − s̃is*, da valutare per ogni s ∈ A.
[1210]Questi 3 dB di differenza sono da interpretare come un guadagno di array legato al disporre di due antenne di ricezione, per cui in pratica viene ricevuta il doppio della potenza che si riceverebbe con una sola antenna, mentre in trasmissione ciò non si verifica, per la limitazione sulla potenza massima trasmessa.
[1211]Indicato anche come operatore aggiunto, mentre A† è detta matrice aggiunta di A.
[1212]Che ho trovato accennati, con i dovuti rimandi, su E. Krouk, S. Semenov, Modulation and coding techniques in wireless communications, 2011 John Wiley & Sons Ltd.
[1213]Il rango di una matrice quadrata An × n è definito come il numero delle sue righe (o colonne) linearmente indipendenti, ma è anche uguale al numero di autovalori diversi da zero, dove gli autovalori sono gli zeri del polinomio caratteristico definito come det(A − λIn)
[1214]Infatti il determinante è anche pari al prodotto degli autovalori, e dunque il suo essere ≠ 0 implica che non vi siano autovalori nulli.
[1215]Anziché mostrare la Pe in scala logaritmica come si fa di solito, per coerenza con l’espressione 10log10Pe ∝ = − Gd(GdBc + ΓdB) sulle ordinate è mostrato il log di Pe, ed essendo Pe < 1, il suo log è negativo.
[1216]L’ortogonalità delle codeword è la proprietà che consente di conseguire la piena diversità spaziale e che permette la decodifica semplificata discussa precedentemente.
[1217]Ovvero per i quali il prodotto C ⋅ C† non assume la forma αIT.
[1218]Ripercorriamo lo sviluppo svolto al § 17.3 per un canale a valori reali, che definisce C = maxp(s){I(S;R)} in cui I(S;R) = h(R) − h(R ⁄ S) è l’informazione mutua media tra simbolo s trasmesso e valore ricevuto r. Il termine h(R ⁄ S) è dovuto al solo rumore, e per esso rimane valido il risultato (21.99) ovvero h(R ⁄ S) = 12log2(2πeσ2n); il massimo di C si ottiene quindi massimizzando h(R), che come noto (§ 9.6.2) avviene con rgaussiano, fornendo h(R) = 12log2(2πeσ2r) in cui per σ2r si ottiene
in cui definiamo σ2sσ2n = ρ pari all’SNR in assenza di fading. Per arrivare alla (21.243) osserviamo come un canale a valori complessi equivalga a due canali reali indipendenti (basti pensare al mo-demodulatore in fase e quadratura), essenzialmente in virtù della indipendenza delle parti reale ed immaginaria del coefficiente complesso h e del rumore n. Pertanto la capacità del canale complesso è il doppio di quanto ora calcolato, come espresso dalla (21.243). Qualcuno può giustamente chiedersi ora se l’SNRρ sia da riferirsi al singolo ramo (I o Q), oppure al segnale complesso. In realtà i due valori sono equivalenti, perché per il canale complesso sia σ2s che σ2nraddoppiano.
[1219]La definizione W = HH† è valida quando nR ≤ nT, mentre se nT < nR conviene scrivere W = H†H, con dimensioni nR × nR e nT × nT rispettivamente. Da questo punto di vista è da notare che in base al teorema di Weinstein–Aronszajn sussiste l’identità
[1220]Ovvero per la quale ΓΓ† = Æà = I, ossia la matrice identità.
[1221]Ossia tale che ℜ{c†Wc} ≥ 0 per ∀c, vedi anche § 6.7.3. Per la precisione W è una matrice Hermitiana, ossia tale che W = W†, e la condizione precedente diviene c†Wc ≥ 0, vedi ad es. https://it.wikipedia.org/wiki/Matrice_definita_positiva. Anzi, ad essere ancora più precisi, per la sua natura aleatoria W è nota come matrice di Wishart, e la legge di distribuzione probabilistica dei suoi valori è descritta dalla omonima distribuzione, vedi ad es. https://it.wikipedia.org/wiki/Distribuzione_di_Wishart.
(Σs̃)i, i = E{sĩsĩ*} = E{(V†)isis * i(V)i} = E{sis * i}(V†)i(V)i = Esi
ovvero l’energia per il simbolo trasmesso dall’antenna i. Con (V†)i si è indicata l’i − esima riga di V† e con (V)i l’i − esima colonna di V, il cui prodotto scalare è uno, essendo la matrice unitaria. La trasformazione s̃ = V†s è infatti una rotazione che non altera la norma di s, e dunque Σs e Σs̃ hanno la stessa diagonale.
dove i canali per i quali in base alla (21.256) si ottiene ρi = 0 (ovvero elementi diℬ) avrebbero dato un contributo log2(1 + ρiλi) = log2(1) = 0.
[1230]Ricordiamo che il valore di capacità è un limite massimo di velocità per la trasmissione senza errori, rispetto al quale confrontare le prestazioni della codifica di canale in uso.
[1231]Considerando l’intero vettore ñ = U†n, le sue componenti ñi sono v.a. gaussiane complesse a media nulla in quanto combinazioni lineari di v.a. della stessa natura. Per la covarianza si ottiene
[1232]Le tecniche usate a questo scopo sono generalmente basate sulla trasmissione preventiva di sequenze di training o di toni pilota concordati, in base alla ricezione (alterata) dei quali il ricevitore è in grado di ricostruire le alterazioni subite dal segnale trasmesso. In linea generale questo processo richiede un tempo proporzionale ad nT, vedi ad es. https://en.wikipedia.org/wiki/Channel_state_information
[1233]Nel senso che la risposta in frequenza hij del canale radio tra l’antenna j di trasmissione e quella i di ricezione è la stessa di quella in senso inverso. Pertanto se un ricevitore con nR antenne stima una Havanti relativa ai segnali ricevuti, quando lo stesso si comporta da trasmettitore (con uguale numero di antenne) traspone la matrice stimata e la usa come csi per il canale mimo in direzione opposta, ovvero Hindietro = HTavanti.
[1234]Infatti in tal caso occorre adottare due portanti differenti nelle due direzioni, per non incorrere in una forte auto-interferenza in ricezione.
[1235]E’ lecito pensare come per SNR elevati l’acqua sia profonda, e dunque l’allocazione di potenza sia circa la stessa per tutti i canali virtuali.
[1236]Vedi ad es. B. Hassibi, H. Vikalo, On the Sphere-Decoding Algorithm, Expected Complexity, ma anche Mathworks, comm.SphereDecoder. In estrema sintesi, questa tecnica riduce la complessità della ricerca del ricevitore ML limitandola ai vettori s che ricadono (in qualche modo) all’interno di una sfera di raggio fisso e centrata sul vettore ricevuto r. All’aumentare del raggio aumenta la complessità ed al limite si ottiene la soluzione ML, ma anche per complessità ridotte la soluzione trovata non si discosta molto da quella ottima.
[1237]In questo testo la definizione di pseudo inversa è scaturita all’eq. (10.188) nel contesto della regressione lineare multipla (§ 7.7.1), con l’analogia che diviene evidente qualora si confronti la (21.261) con la (10.187) e si sostituisca r, H, s con y, X, β. La discussione ivi svolta nel nostro caso significa che se fosse stato trasmesso s̃ che soddisfa (21.261) avremmo ricevuto r̃ = Hs̃ + n vincolato (a parte per il rumore) a giacere nello spazio esplorato dalle colonne di H, e dunque la differenza ε = r̃ − r = H(s̃ − s) deve essere ortogonale alle stesse colonne, e quindi H† ⋅ ε = 0, dopodiché i passaggi sono gli stessi utilizzando l’hermitiano † anziché il trasposto ⊤.
[1241]Indicando l’argomento interno di (21.264) come l’errore ε(G) = s − Gr ed il suo valore atteso quadratico come J(G) = E{ε2} = E{ε†ε}, quando J è minimo tutte le componenti del suo gradiente devono annullarsi, ovvero ∇GJ(G)|G = G◇ = 0nT × nR (cioè si annullano le derivate di J rispetto a tutti gli elementi di G). Possiamo quindi scrivere
∂J∂G = ∂∂GE{ε2} = 2E{ε ⋅ ∂ε†∂G} = 0
e dato che ∂ε†∂G = ∂∂G(s − Gr)† = − r† si ottiene J minimo quando
[1243]A partire dalla (21.265) otteniamo E{(s − G◇r)r†} = E{sr† − G◇rr†} = ΣSR − G◇ΣRR = 0 per cui deve risultare G◇ = ΣSR⁄ΣRR, dove le matrici di covarianza Σ coincidono con quelle di correlazione, dato il valore atteso nullo di s e di r. Calcoliamone il valore:
dato che E{sn†}, E{Hsn†} e E{ns†H†} sono nulli in virtù dell’incorrelazione tra s ed n, e si è posto ΣS = EsI e ΣN = σ2nI in virtù dell’incorrelazione tra simboli delle diverse antenne, nonché tra campioni di rumore, in cui Es = E{s * isi} = PT⁄fsnT è pari all’energia per simbolo e per antenna, uguale per tutte, mentre σ2n = E{n * ini} = 1⁄nRE{n†n} è la potenza del campione di rumore in ingresso all’i − esima antenna ricevente. Sostituendo ora ΣSR e ΣRR nella relazione G◇ = ΣSR⁄ΣRR otteniamo il risultato cercato
G◇ = ΣSRΣRR = EsH†EsHH† + σ2nI = H†HH† + σ2nEsI
[1244]Nel senso che il vettore di pesi w con coefficienti (21.221) è il coniugato dell’unica colonna di H presente nel caso simo, come ora la riga i − esima di H† è coniugata dell’i − esima colonna di H - ma vedi anche la discussione seguente.
in cui si tiene conto dell’ortogonalità tra wi e le colonne (H)j con j ≠ i, e del fatto che wTi(H)i = 1 essendo wTi pari all’i − esima riga della pseudoinversa di H. Pertanto l’SNR risulta pari a
[1249]In realtà la figura è frutto di un missaggio di due prelevate da lavori differenti, ed i valori mostrati sono da ritenersi indicativi e non esatti, oltre che frutto della H adottata.
[1250]Vedi L.Zheng, D.N.C.Tse, Diversity and multiplexing: a fundamental tradeoff in multiple-antenna channels, IEEE Trans. on Inf. Theory, May 2003, dove sono riportate le considerazioni e le ipotesi che determinano il risultato; trovo una copia libera presso l’Univ. di Stanford.
[1251]Dato che la capacità per simbolo C = log2(1 + SNR) di un canale siso tende a log2SNR con SNR → ∞, il valore r nella (21.269) esprime il numero di canali siso equivalenti.
[1252]Probabilmente ci vorrebbe qualche passaggio in più, ma la relazione Pe ∝ 1⁄SNRd deriva dal confronto tra la (21.223) del ricevitore mrc che sfrutta la diversità, e la (21.208) valida per un canale siso.
[1253]S.Sfar, L.Dai, K.B.Letaief, Optimal Diversity-Multiplexing Tradeoff With Group Detection for MIMO Systems, IEEE Tr. on Comm. 2005; P. Elia ed al, Explicit Space-Time Codes Achieving The Diversity-Multiplexing Gain Tradeoff, IEEE Tr. on Inf. Th. 2006
[1255]Supponiamo qui che i terminali mobili siano sincronizzati temporalmente, e che il sistema sia in grado di compensare i diversi ritardi di propagazione per la corretta determinazione degli istanti di campionamento dei simboli.
[1256]Infatti ogni canale utente-bs sperimenta cammini multipli completamente differenti ed incorrelati, rendendo le colonne di H indipendenti, al punto da definirle come una firma spaziale di ciascun utente, dando al sistema di trasmissione la denominazione di space division multiple access o sdma.
[1257]Corrispondente all’unica riga di Hdk pertinente all’utente k qualora nk = 1. Il vettore hk può essere pensato nel senso letterale di indicare una direzione (a coordinate complesse) nello spazio generato dalle antenne della bs, dunque non la direzione fisica dell’utente, ma che lo distingue comunque dagli altri.
[1258]A ben vedere, per un numero U elevato di utenti si applica il teorema centrale del limite, ed il termine ∑Uh = 1, h ≠ khhsh tende ad una v.a. gaussiana.
[1262]N. Jindal, MIMO Broadcast Channels With Finite-Rate Feedback, IEEE Trans. on Inf. Th. Nov. 2006, ne trovo una copia libera presso Univ. of Minnesota
[1263]La scelta degli elementi del codebook può avvenire in accordo ad un modello di d.d.p. p(hd) nel contesto dell’algoritmo di Lloyd-Max (nota 165 a pag. 4.3), oppure a partire da una base dati di vettori osservati su cui eseguire un algoritmo di clusterizzazione, vedi ad es. https://en.wikipedia.org/wiki/K-means_clustering. Infine è da citare la possibilità di popolare il cb in modo casuale, a partire da un seme iniziale, trasmettendo il quale il cb stesso può essere autonomamente ri-generato alla bs.
[1264]Vedi § 2.4.3. In questo modo due vettori sono tanto più simili quanto più condividono lo stesso orientamento; la normalizzazione ne ha portato la punta sulla superficie di una sfera di raggio unitario, e qui si va a finire negli spazi Grassmaniani. Qualcuno può chiedersi: come mai la distorsione è nulla anche per vettori opposti? Una possibile risposta è che i vettori quantizzati h̃h servono alla bs per calcolare vettori pk di precoding ortogonali ad h̃h ≠ k. L’ortogonalità dunque permane anche nei confronti di un vettore con il segno cambiato.
[1265]Per evitare che più terminali possano scegliere lo stesso vettore del cb, ognuno di essi può utilizzare un diverso cb. Dato che questi devono essere tutti noti presso la bs, la questione può essere semplificata nel caso di cb generati casualmente a partire da un seme.
[1266]Ovvero tali da rendere massima la separazione angolare minimad(P) tra due elementi di P, avendo definito d(P) = min1 ≤ i ≤ j ≤ 2Bsin(θi, j) e θi, j = arccos(p†ipj), e quindi P: d(P) = max. Di nuovo, è un problema noto, vedi J.H. Conway, R.H. Hardin, N.J.A. Sloane, Packings in Grassmannian Spaces, Experimental Mathematics 5:2, 1996, vedihttp://www2.stat.duke.edu/~sayan/SAMSI/lec/conway.pdf. Notiamo che qualora 2B > nBS non è possibile trovare 2B vettori mutuamente ortogonali.
[1267]Consideriamo la (ipotetica) trasmissione da parte della bs del segnale sP = ∑2Bh = 1 phsh, che determina presso uek la ricezione (vedi eq. (21.275)) del segnale rk = hTksP + n = ∑2Bh = 1 hTkphsh + n. Si intende trovare l’indice h associato al vettore ph che determina le migliori condizioni di ricezione per uek. Se consideriamo come componente di segnale quella relativa al generico indice m ovvero hTkpmsm, il termine di rumore è ∑2Bh = 1, h ≠ mhTkphsh + n, e dunque il valore di SINRk, m si calcola come
SINRk, m = E{|hTkpmsm|2}σ2n + E{|⎲⎳2Bh = 1, h ≠ mhTkphsh|2} = Es ⋅ |hTkpm|2σ2n + Es ⋅ ⎲⎳2Bh = 1, h ≠ m|hTkph|2 = | hTkpm|21⁄ρ + ⎲⎳2Bh = 1, h ≠ m|hTkph|2
in cui ρ = Es⁄σ2n e Es = E{|sh|2}, ed il passaggio a denominatore è possibile considerando i phortonormali. SINRk, m è dunque massimo quando lo è il numeratore, ossia quando lo è il prodotto scalare tra hk e pm.
[1269]Cioè pilotare i modulatori collegati alle antenne con un vettore sB = ∑nBh = 1 bhsh in cui il simbolo sh destinato all’h − esimo utente viene affasciato nella direzione stabilita dal beam bh, ne più ne meno come avviene nel precoding.
[1270]La fonte di questa affermazione (Wikipedia) cita la tesi di dottorato G.Raleigh, On Multivariate Communication Theory and Data Rate Multiplying Techniques for Multipath Channels, 1998, ma il link a cui puntava non risulta più attivo.
[1271]La diversità in frequenza è esattamente quella discussa al § 20.3.3.1 e dovuta ai cammini multipli che rendono il canale selettivo in frequenza (§ 20.4.5).
[1272]Possiamo notare che come le antenne riescono ad offrire diversità spaziale solo qualora le stesse siano sufficientemente distanziate rispetto alla lunghezza d’onda λ della trasmissione, così le sottoportanti offrono diversità in frequenza solo su canali separati da un intervallo di frequenza maggiore della banda di coerenza.
[1274]Con il massimo conseguito solo per il caso di indipendenza di tutti i percorsi alternativi.
[1275]In alternativa la ripartizione può contemplare elaborazioni più complesse come quelle descritte al § 21.7.2, o prevedere anche uno stadio di precoding, od anche di codifica di canale e/o interleaving..
[1276]Una buona sintesi storica di questo filone di studio si trova in W Zhang, XG Xia, KB Letaief, Space-time/frequency coding for MIMO-OFDM in next generation broadband wireless systems, IEEE Wireless Comm. June 2007, di cui trovo una copia presso https://www.eecis.udel.edu/~xxia/WeiZhang1.pdf
[1278]Vedi W. Zhang, X. Xia, P. C. Ching, High-Rate Full-Diversity Space–Time–Frequency Codes for Broadband MIMO Block-Fading Channels, IEEE Trans. on Comm., January 2007, di cui trovo una copia su CiteseerX
[1279]Distinguibili grazie ai vettori di precoding pk e di combinazione gk.
[1280]Verso i quali si trasmette in contemporanea realizzando lo sdma.
[1281]Tratta dall’ottimo testo di E. Björnson, J. Hoydis, L. Sanguinetti,Massive MIMO Networks: Spectral, Energy, and Hardware Efficiency, 2017, accessibile presso https://massivemimobook.com
[1282]Considerando che un inviluppo complesso che occupa una banda bilateraBc viene campionato a frequenza doppia di Bc⁄2, in Tc secondi si ottengono appunto BcTc campioni. Una volta eliminato il prefisso ciclico (fig. 21.26) tale numero si riduce, ed il ricevitore ofdm ne effettua la fft ottenendo altrettanti campioni complessi in frequenza.
[1283]Per la modalità tdd su cui stiamo basando l’esposizione l’espressione costante di tempo individua la durata di un cb, mentre più in generale ci si riferisce non tanto al periodo di simbolo ofdm quanto ad un periodo di trama, che comprende un preambolo composto da qualche simbolo ofdmaccorciato in cui trovano posto le portanti pilota, a cui fa seguito la sotto-trama dei simboli con i dati, per la cui ricezione si fa uso del risultato della stima di canale. Spesso alcune pilota sono presenti anche nei simboli dati, per favorire il mantenimento delle condizioni di sincronizzazione.
[1284]Notiamo che per uno spazio descritto da una base vettoriale τp − dimensionale si possono individuare non più di τp diversi vettori ortogonaliφk.
[1287]In effetti nella trasmissione di uplink di un sistema mu-mimo il requisito 3) è ancora più stringente, dato che in tal caso è richiesto che i simboli trasmessi dagli uearrivino alla bs allo stesso istante, cosa resa possibile dalla conoscenza della distanza tra ciascuno di essi e la bs; ciò non è possibile in un sistema broadcast, data la presenza di molteplici ricevitori ad antenna singola, al posto di una singola bs.
[1289]Le cui sigle non hanno nulla a che vedere con la qualità dell’immagine!
[1290]Come dati di servizio si intendono le portanti pilota di sincronizzazione in frequenza e nel tempo, di ausilio alla stima di canale, e che trasportano dati di segnalazione a riguardo (tra l’altro) del tipo di modulazione (m-qam con M = 4, 16 o 64) e di codifica di canale, parametri questi ultimi che determinano la velocità binaria conseguita dal flusso dati trasmesso, variabile in un intervallo da 5 a 31 Mbps.
[1291]Che consistono nel transport streammpeg che multiplexa le emittenti che prendono parte alla sfn, a cui sono stati applicati stadi di codifica di canale e di scrambling, vedi ad es. Lo standard DVB-T, Centro Ricerche RAI, da cui è anche tratta la tab. 21.2
[1292]Indicando con Ñd il numero di portanti che trasportano informazione, con Rc il tasso di codifica fec, e con M il numero di bit/portante della costellazione adottata, se il tempo di guardia fosse nullo si otterrebbe una velocità fmaxb = Ñd ⋅ Rc ⋅ M⁄T0. Dato però che il periodo di simbolo è pari a Ts = Tg + T0, la velocità si riduce a fb = fmaxbT0Tg + T0 e dunque l’efficienza è pari a η = T0Tg + T0 = 11 + Tg⁄T0. Con i valori di Tg⁄T0 in fig. 21.2 si ottiene η = \strikeout off\xout off\uuline off\uwave off0.8, 0.88, 0.94 e 0.97.
[1293]Costituito da una serie di pacchetti di 188 byte il cui contenuto è descritto dal campo pid presente nell’header, che può anche specificare un pacchetto nullo inserito per adattare la velocità variabile dei contenuti multimediali con quella fissa offerta dal canale a disposizione.
[1300]L’operatore matriciale tr(A) restituisce la somma degli elementi sulla diagonale della matrice quadrataA. Dal momento che xΣxT è un numero, ovvero una matrice 1 × 1, la sua traccia è pari al numero stesso.
[1304]O molto più banalmente, il campionamento dell’inviluppo complesso del rumore osservato su n canali equivalenti di bassa frequenza.
[1305]Il termine grado di servizio esprime un concetto di qualità, ed è usato in contesti diversi per indicare differenti grandezze associate appunto alla qualità dei servizi di telecomunicazione, vedi pag. 1. Nel caso presente, una buona qualità corrisponde a una bassa probabilità di occupato.
[1306] Infatti i termini (Nk) sono pari ai coefficienti della potenza di un binomio (p + q)N, calcolabili anche facendo uso del triangolo di Pascal (ma definito prima da Tartaglia, e prima ancora da Hayyām), mostrato per riferimento a lato.
[1307]Infatti si applica ad un qualunque fenomeno aleatorio rappresentato dalla ripetizione di un secondo fenomeno aleatorio soggiacente, come ad esempio il lancio ripetuto di monete o di dadi: in questi casi, ha senso chiedersi con che probabilità una funzione della v.a. soggiacente acquisisce un certo valore, per un certo numero di volte. Esempio: si voglia calcolare la probabilità di osservare 3 volte testa, su 10 lanci di una moneta. Applicando la (26.1), si ottiene pB(3) = ⎛⎜⎝103⎞⎟⎠p3q7 = 120 ⋅ .53 ⋅.57 = 0.117, ovvero una probabilità dell’11,7 %. Come ulteriore esempio, citiamo l’uso della distribuzione binomiale per calcolare la probabilità di errore complessiva in una trasmissione numerica realizzata mediante un collegamento costituito da N tratte collegate da ripetitori rigenerativi, come illustrato al § 18.3.2.
[1308]Usando il modello Poissoniano la probabilità che (ad esempio) si stiano svolgendo meno di 4 conversazioni contemporanee è pari pertanto a pP(0) + pP(1) + pP(2) + pP(3) = e − α⎛⎝1 + α + α22 + α36⎞⎠.
[1309]La trattazione può facilmente applicarsi a svariate circostanze: dalla frequenza con cui si presentano richieste di collegamento ad una rete di comunicazioni, alla frequenza con cui transitano automobili sotto un cavalcavia, alla frequenza con cui particelle subatomiche transitano in un determinato volume, alla frequenza con cui gli studenti si presentano a lezione...
[1310]Esempio: se da un cavalcavia osserviamo (mediamente) λ = 3 auto/minuto, nell’arco di T = 2 minuti, transiteranno (in media) 3*2 = 6 autovetture.
[1311]Esempio: sapendo che l’autobus (completamente casuale!) che stiamo aspettando ha una frequenza di passaggio (media) di 8 minuti, calcolare: A) la probabilità di non vederne nessuno per 15 minuti e B) la probabilità che ne passino 2 in 10 minuti.
Soluzione: si ha λ = 1 ⁄ 8 passaggi/minuto e quindi: A)pP(0)|15 = e − 158 = 0.15 pari al 15%; B)pP(2)|10 = e − 108⎛⎝108⎞⎠22 = 0.224 pari al 22.4%
[1312]Da un punto di vista formale per eventi completamente casuali si intende che gli eventi stessi non hanno memoria di quando siano accaduti l’ultima volta, permettendo di scrivere
Pr(t > t0 + θ ⁄ t > t0) = Pr(t > θ)
ossia la probabilità di attendere altri θ istanti, avendone già attesi t0, non dipende da t0. Per verificare che la ddp esponenziale consente di soddisfare questa condizione svolgiamo i passaggi, applicando al terzultimo la (26.3):
[1313]La ddp esponenziale è spesso adottata come un modello approssimato ma di facile applicazione per rappresentare un tempo di attesa, ed applicato ad esempio alla durata di una conversazione telefonica, oppure all’intervallo tra due malfunzionamenti di un apparato.
[1314]Per quanto riguarda il valor medio mE = ∫∞0tλe − λtdt possiamo procedere per parti, ossia applicando la regola ∫baf’(t)g(t)dt = f(t)g(t)|ba − ∫baf(t)g’(t)dt, avendo posto f’(t) = e − λt e g(t) = λt: si ottiene allora
essendo limt → ∞e − λt ⋅ λt = 0. Per σ2E = ∫∞0t2λe − λtdt − (mE)2, il primo integrale (sempre procedendo per parti) fornisce ∫∞0t2λe − λtdt = 2λ2, e dunque σ2E = 2λ2 − 1λ2 = 1λ2.
[1315]Consideriamo un ospedale in cui nascono in media 6 bimbetti al giorno (o 0.25 nascite l’ora), e consideriamo l’intervallo tra questi eventi come una v.a. completamente casuale. Se assumiamo che la probabilità di k nascite in un tempo T sia descritta da una v.a. di Poisson, ossia a cui compete una probabilità pP(k) = e − λT(λT)kk!, allora la probabilità che durante un tempo T non avvenga nessuna nascita, dovrebbe corrispondere a calcolare pP(0), ovvero e − λT(λT)00! = e − λT, che è esattamente il risultato che fornisce la v.a. esponenziale per la probabilità Pr(t > T) che non vi siano nascite per un tempo T.
[1316]La dimostrazione della (26.4) si basa sulla considerazione che Pr(t ≤ t0) = 1 − Pr(t > t0), e sulla espansione in serie di potenze ex = 1 + x + x2⁄2 + x3⁄3! + ⋯ che si riduce a ex = 1 + x + o(t0) se x → 0. Pertanto la (26.3) diviene Pr(t > t0)|t0 → 0 = 1 − λt0 + o(t0), e quindi Pr(t ≤ t0) = 1 − 1 + λt0 + o(t0) = λt0 + o(t0).
[1317]Gli esempi dalla vita reale sono molteplici, dal casello autostradale presso cui arrivano auto richiedenti il servizio del casellante (M=numero di caselli aperti), al distributore automatico di bevande (servente unico), all’aereo che per atterrare richiede l’uso della pista (servente unico).... nel contesto delle telecomunicazioni, il modello si applica ogni qualvolta vi siano un numero limitato di risorse a disposizione, come ad esempio (ma non solo!) il numero di linee telefoniche uscenti da un organo di commutazione, od il numero di time-slot presente in una trama PCM, od il numero di operatori di un call-center....
[1318]L’ipotesi permette di valutare la probabilità che l’intervallo temporale tra due eventi di ingresso sia superiore a θ, in base alla (26.3), come e − λθ (ad esempio, la prob. che tra due richieste di connessione in ingresso ad una centrale telefonica passi un tempo almeno pari a θ); allo stesso modo, la probabilità che il servizio abbia una durata maggiore di θ è pari a e − μθ (ad esempio, la prob. che una telefonata duri più di θ).
[1319]Le ipotesi poste fanno sì che i risultati a cui giungeremo siano conservativi, ovvero il numero di serventi risulterà maggiore od uguale a quello realmente necessario; l’altro caso limite (di attese deterministiche) corrisponde a quello in cui il tempo di servizio non varia, ma è costante, come ad esempio il caso del tempo necessario alla trasmissione di una cella atm di dimensioni fisse. In questi casi, la stessa intensità media di traffico Ao = λμ può essere gestita con un numero molto ridotto di serventi; nella realtà, ci si troverà in situazioni intermedie.
[1320]Si noti che il pedice o è una “o” e non uno “0”, ed identifica appunto l’aggettivo offerto.
[1321]Pensiamo ad un ufficio postale visto dall’esterno: la frequenza media λ con cui entrano nuove persone non dipende da quanti siano già all’interno, mentre invece la frequenza con la quale escono dipende sia dal tempo medio 1⁄μ di permanenza allo sportello, che dal numero di sportelli (serventi) M in funzione. La differenza con il caso che stiamo trattando deriva dal fatto che l’ufficio postale è un sistema a coda, e dato che la coda c’è praticamente sempre (ossia i serventi sono generalmente tutti occupati) possiamo dire che la frequenza media di uscita è proprio Mμ.
[1322]E’ un po come se il numero medio di nuove richieste per unità di tempo λ si distribuisse, in accordo alle probabilità pk, tra tutti gli stati possibili del sistema: come dire che del totale di λ, una parte λp0 trovano il sistema vuoto, una parte λp1 con un solo occupante, eccetera. Per quanto riguarda le richieste servite per unità di tempo, la frequenza di uscita dal sistema è quella che si otterrebbe con un unico servente, moltiplicata per il numero di serventi occupati. Dato che questa ultima quantità è una grandezza probabilistica, la reale frequenza di uscita μr può essere valutata come valore atteso, ossia μr = ∑Mk = 1μ ⋅ k ⋅ pk
[1323]Usiamo il pedice m anziché k per non creare confusione nella (26.8)
[1324]Questo risultato è in perfetto accordo con le la (26.2), quando abbiamo sostituito alla ddp di Bernoulli quella di Poisson, mantenendo inalterato il numero medio di serventi occupati, che ora indichiamo con Ao, come definito al § 22.3.2.
[1325]ovvero, all’aumentare del traffico offerto, M aumenta più lentamente di Ao. Ad esempio, dalla figura si può verificare che se per Ao = 10 occorrono circa 21 serventi, per una intensità doppia Ao = 20 il numero di serventi necessario a mantenere la stessa PB risulta poco più di 32.
[1326]In effetti, è stato dimostrato che i risultati ottenuti per i sistemi di servizio orientati alla perdita possono essere considerati validi anche nel caso di tempi di servizio a distribuzione qualsiasi, non necessariamente esponenziale.
[1327]Un esempio di tale tipo di traffico potrebbe essere... l’uscita da uno stadio (o da un cinema, una metropolitana,...) in cui il flusso di individui non è casuale, ma aumenta fino a saturare le vie di uscita.
[1328]Se PB è la probabilità di blocco derivante dalla disponibilità di M serventi, una frequenza di richieste pari a PB ⋅ λo non può essere servita immediatamente; adottando una coda, la frequenza delle richieste non servite immediatamente PB ⋅ λo è uguale a λo(Pp + Pr(1 − Pp)), ed eguagliando le due espressioni si ottiene Pp = PB − Pr1 − Pr, che è sempre minore di PB.
[1329]Nella derivazione del risultato si fa uso della relazione ∑∞k = 0αk = 11 − α, nota con il nome di serie geometrica, e valida se α < 1, come infatti risulta nel nostro caso, in quanto necessariamente deve risultare Ao = λoμ < 1; infatti se il servente è unico una frequenza di arrivo maggiore di quella di servizio preclude ogni speranza di funzionamento, dato che evidentemente il sistema non ha modo di smaltire in tempo le richieste che si presentano.
[1330]Ricordiamo che p0 è la probabilità che il sistema sia vuoto, e dunque 1 − p0 quella che non sia vuoto.
[1331]si fa uso della relazione ∑∞k = 0kαk = α∑∞k = 0kαk− 1 = α∂∂α∑∞k = 0αk = α∂∂α11 − α = α(1 − α)2
[1332]Non può essere λs > λo, perché si servirebbero più richieste di quante se ne presentano. Se fosse invece λs < λo, la coda crescerebbe inesorabilmente e sarebbe quindi inutile.
[1333]In una trasmissione a pacchetto, operata a frequenza binaria fb e con pacchetti di lunghezza media Lp bit, il tempo medio di servizio per un singolo pacchetto è pari a quello medio necessario alla sua trasmissione, e cioè τS = Lp ⁄ fb.
[1334]1 byte = 8 bit, 1 K = 210 = 1024. Il “K” in questione è “un K informatico”. Nel caso invece in cui ci si riferisca ad una velocità di trasmissione, il prefisso K torna a valere 103 = 1000.
[1335]In virtù di quanto esposto alla nota precedente, in questo caso 1M = 106 = 1000000.
[1336]La sigla CRC significa Cyclic Redundancy Check (controllo ciclico di ridondanza) ed indica una parola binaria i cui bit sono calcolati in base ad operazioni algebriche (vedi § 15.6.3.3) attuate sui bit di cui il resto del messaggio è composto. Dal lato ricevente sono eseguite le stesse operazioni, ed il risultato confrontato con quello presente nel CRC, in modo da controllare la presenza di errori di trasmissione.
[1337]L’entità delle informazioni aggiuntive rispetto a quelle del messaggio può variare molto per i diversi protocolli, da pochi bit a pacchetto fino ad un 10-20% dell’intero pacchetto (per lunghezze ridotte di quest’ultimo).
[1340]Un modo di trasferimento con pacchetti di dimensione fissa è l’ATM (Asynchronous Transfer Mode) che viene descritto al § 23.2.
[1341]Nel caso del pots (vedi § 24.9.1) si creava un vero e proprio circuito elettrico (vedi anche pag. 1), e le risorse fisiche impegnate sono gli organi di centrale ed i collegamenti tra centrali, assegnati per tutta la durata della comunicazione in esclusiva alle due parti in colloquio. Nel caso del pcm (vedi § 24.3.1), le risorse allocate cambiano natura (ad esempio consistono anche nell’intervallo temporale assegnato al canale all’interno della trama) ma ciononostante vi si continua a far riferimento come ad una rete a commutazione di circuito.
[1342]Le risorse impegnate sono dette logiche in quanto corrispondono ad entità concettuali (i canali virtuali descritti nel seguito).
[1343]Il termine canale virtuale simboleggia il fatto che, nonostante i pacchetti di più comunicazioni viaggino “rimescolati” su di uno stesso mezzo, questi possono essere distinti in base alla comunicazione a cui appartengono, grazie ai differenti IC (numeri) con cui sono etichettati; pertanto, è come se i pacchetti di una stessa comunicazione seguissero un proprio canale virtuale indipendente dagli altri.
[1344]I numeri di c.v. sono negoziati tra ciascuna coppia di nodi durante la fase di instradamento, e scelti tra quelli non utilizzati da altre comunicazioni già in corso. Alcuni numeri di c.v. inoltre possono essere riservati, ed utilizzati per propagare messaggi di segnalazione inerenti il controllo di rete.
[1345]In realtà vengono prima fatti dei tentativi di inviare nuovamente i pacchetti “vecchi”. Questi ultimi infatti sono conservati da chi li invia (che può anche essere un nodo intermedio), finché non sono riscontrati dal ricevente. Quest’ultimo fatto può causare ulteriore congestione, in quanto restano impegnate risorse di memoria “a monte” della congestione che così si propaga.
[1346]Per questo motivo, il collegamento è detto senza connessione.
[1347]Il termine buffer ha traduzione letterale “respingente, paracolpi, cuscinetto” ed è a volte espresso in italiano dalla locuzione memoria tampone.
[1348]La soluzione a questa “spirale negativa” si basa ancora sull’uso di un allarme a tempo (timeout), scaduto il quale si giudica interrotto il collegamento, e sono liberati i buffer.
[1349]In virtù dell’intreccio di sigle, il modello di riferimento prende il nome (palindromo) di modello ISO-OSI.
[1350]Il modo di trasferimento è completamente definito dopo che sia stato specificato in quale strato siano svolte le funzioni di commutazione e multiplazione. In una rete a commutazione di circuito, queste sono realizzate dallo strato fisico che, esaurita la fase di instradamento ed impegno di risorse fisiche, collega in modo trasparente sorgente e destinazione. Nella commutazione di pacchetto, invece, le funzioni di multiplazione e commutazione coinvolgono (per tutti i pacchetti del messaggio) tutti i nodi di rete interessati; si dice pertanto che i protocolli di collegamento e di rete devono essere terminati (nel senso di gestiti) da tutti i nodi di rete.
[1351]Queste tecniche hanno origine a scopo di controllo degli errori nei collegamenti punto-punto per i quali si osserva una probabilità di errore non trascurabile. Successivamente, sono stati utilizzati nelle reti a pacchetto, in cui è possibile la perdita totale dei pacchetti in transito. Per questo le implementazioni attuali dei arq, specie se applicati da un estremo all’altro di una rete, privilegiano l’uso di timeout piuttosto che quello di riscontri negativi.
[1352]Sottolineiamo nuovamente l’importanza dei numeri di sequenza, che permettono al ricevitore di capire il numero della trama corrotta, grazie alla discontinuità dei numeri stessi.
[1353]Nel caso in cui l’integrità della trama sia protetta da un codice a blocco (n, k) con dm = l + 1 (§ 15.6.2.1), la probabilità che la trama contenga più di l errori e che quindi venga accettata dal ricevitore anche se errata, vale approssimativamente P(l + 1, n) = ⎛⎜⎝nl + 1⎞⎟⎠Pie (vedi formula (21.27)). Dato che il ricevitore accetta le trame che non hanno errori, oppure che hanno più di l errori, la probabilità che venga richiesta una ritrasmissione risulta
p = 1 − P(0, n) − P(l + 1, n)
Considerando ora che P(l + 1, n) ≪ P(0, n) (vedi eq. 21.27), si ottiene
p ≃ 1 − P(0, n) = 1 − (1 − Pe)n ≃ nPe
in cui Pe è la probabilità di errore sul bit (dato che (1 − Pe)n ≃ 1 − nPe se nPe≪1).
[1355]Dato che p aumenta con n (vedi pag. 1), l’efficienza del protocollo arqpeggiora con l’aumentare della dimensione delle trame. Questo risultato determina l’esigenza di ricercare una soluzione di compromesso, dato che l’incidenza dell’overhead sulla dimensione complessiva della trama invece si riduce all’aumentare di n.
[1356]L’espressione “bit in aria” trae spunto dalla metafora di una coppia di giocolieri, posti ai due estremi di una piazza, che si lanciano una serie di clave. Il primo ne lancia in continuazione, e quando iniziano ad arrivare al secondo, questi le rilancia verso il primo. Nel momento in cui la clava partita per prima torna nelle mani del primo giocoliere, un certo numero di clave sono sospese a mezz’aria, e corrispondono approssimativamente al numero di bit trasmessi in un tempo di pari durata, con una frequenza pari al ritmo di lancio delle clave, e non ancora riscontrati.
[1357]La ricezione di una sequenza di trame corrette determina l’avanzamento alternato dei due bordi della finestra al ricevitore: questa inizialmente è vuota, poi contiene solo la trama ricevuta (avanza bordo superiore), e quindi è di nuovo svuotata non appena viene trasmesso l’ack (ed avanza il bordo inferiore). In presenza di errori, il bordo inferiore non avanza, ma resta fermo sulla trama ricevuta con errori, e di cui si attende la ritrasmissione. Mentre il trasmettitore continua ad inviare trame, il ricevitore le memorizza e fa avanzare il bordo superiore, finché non siano state ricevute tutte quelle trasmissibili senza riscontro, e pari alla dimensione massima della finestra in trasmissione.
[1358]Se il trasmettitore invia tutte le W trame, ma tutti gli ack sono corrotti, allora la (W + 1) -esima trama trasmessa è un duplicato della prima, ritrasmessa per time-out, ed il ricevitore può accorgersene solo se la trama reca un numero differente da quello della prima.
Per il caso selective repeat, vale un ragionamento simile, ma che per le differenze nella definizione del protocollo, porta ad un risultato diverso.
[1359]Dato che in realtà il verso della comunicazione si può invertire, l’entità che ha un ruolo master è indicato come primary, e le entità asservite sono dette secondary.
[1360]Migliore sforzo, ossia la rete dà il massimo, senza però garantire nulla.
[1362]Local Area Network, ossia rete locale. Con questo termine si indica un collegamento che non si estende oltre (approssimativamente) un edificio.
[1363]La funzione di conversione di protocollo tra reti disomogenee è detta di gateway, mentre l’interconnessione tra reti locali è svolta da dispositivi bridge oppure da ripetitori se le reti sono omogenee. Con il termine router si indica più propriamente il caso in cui il nodo svolge funzioni di instradamento, che tipicamente avviene nello strato di rete. Nel caso in cui invece si operi un instradamento a livello dello strato di collegamento, ossia nell’ambito di sezioni diverse (collegate da bridge o ripetitori) di una stessa LAN, il dispositivo viene detto detto switch. Infine, un firewall opera a livello di trasporto, e permette di impostare regole di controllo per restringere l’accesso alla rete interna in base all’indirizzo di sorgente, al tipo di protocollo, e/o a determinati servizi .
[1365]Con 4 byte si indirizzano (in linea di principio) 232 = 4.29 ⋅ 109 diversi nodi (più di 4 miliardi). E’ stato sviluppato il cosiddetto IPv6, che estende l’indirizzo IP a 16 byte, portando la capacità teorica a 3.4 ⋅ 1038 nodi. L’IPv6 prevede inoltre particolari soluzioni di suddivisione dell’indirizzo, allo scopo di coadiuvare le operazioni di routing. Per approfondire, vedi ad es. https://it.wikipedia.org/wiki/IPv6
[1366]Evidentemente esistono molte diverse possibilità di collegamento ad Internet, come via telefono (tramite provider), collegamento satellitare, Frame Relay, linea dedicata, isdn, adsl... ma si preferisce svolgere un unico esempio per non appesantire eccessivamente l’esposizione. La consapevolezza delle molteplici alternative consente ad ogni modo di comprendere la necessità di separare gli strati di trasporto e di rete dall’effettiva modalità di trasmissione.
[1367]Mostriamo in seguito che questo avviene mediante il protocollo ARP.
[1368]I top level domain possono essere pari ad un identificativo geografico (.it, .se, .au...) od una delle sigle .com, .org, .net, .mil, .edu, che sono quelle utilizzate quando Internet era solo americana.
[1369]Il “proprio” DNS viene configurato per l’host in modo fisso, oppure in modo dinamico dai Service Provider raggiungibili via adsl, e convenientemente corrisponde ad un nodo situato “vicino” al nodo che lo interroga.
[1370]Chi registra il dominio deve disporre necessariamente di un DNS in cui inserire le informazioni sulle corrispondenze tra i nomi dei nodi del proprio dominio ed i loro corrispondenti indirizzi IP. In tal caso quel DNS si dice autorevole per il dominio ed è responsabile di diffondere tali informazioni al resto della rete.
[1371]In realtà esiste anche una diversa modalità operativa, che consiste nel delegare la ricerca ad un diverso DNS (detto forwarder), il quale attua lui i passi descritti appresso, e provvede per proprio conto alla risoluzione, il cui esito è poi comunicato al primo DNS e da questi ad hostX. Il vantaggio di tale procedura risiede nella maggiore ricchezza della cache (descritta appresso) di un DNS utilizzato intensivamente.
[1372]Il DNS ricorda anche le altre corrispondenze ottenute, come il DNS autorevole per .tld e per .dominio.tld; nel caso infine in cui si sia utilizzato un forwarder, sarà quest’ultimo a mantenere memoria delle corrispondenze per i DNS intermedi.
[1373]Cache è un termine generico, che letteralmente si traduce come nascondiglio dei viveri, e che viene adottato ogni volta si debba indicare una memoria che contiene copie di riserva, o di scorta...
[1374]Socket è un termine che corrisponde alla... presa per l’energia elettrica casalinga, ed in questo contesto ha il significato di una presa a cui si “attacca” il processo che richiede la comunicazione. Per l’esattezza, un socket Internet è individuato dal numero di porta tcp e dall’indirizzo ip.
[1375]Spesso gli indirizzi che identificano i punti di contatto di servizi specifici vengono indicati come Service Access Point (SAP), anche per situazioni differenti dal caso specifico delle porte del TCP.
[1377]Il numero di porta costituisce in pratica l’identificativo di connessione del circuito virtuale. Nel caso in cui un server debba comunicare con più client, dopo avere accettato la connessione giunta su di una porta ben nota, apre con i client diversi canali di ritorno, differenziati dall’uso di porte di risposta differenti.
La lista completa dei servizi standardizzati e degli indirizzi ben noti (socket) presso i quali i serventi sono in attesa di richieste di connessione, è presente in tutte le distribuzioni Linux nel file /etc/services.
[1378]Il numero di sequenza si incrementa ad ogni pacchetto di una quantità pari alla sua dimensione in bytes, ed ha lo scopo di permettere le operazioni di controllo di flusso. Il valore iniziale del numero di sequenza e di riscontro è diverso per ogni connessione, e generato in modo pseudo-casuale da entrambe le parti in base ai propri orologi interni, allo scopo di minimizzare i problemi dovuti all’inaffidabilità dello strato di rete (l’IP) che può perdere o ritardare i datagrammi, nel qual caso il TCP trasmittente ri-invia i pacchetti precedenti dopo un time-out. Questo comportamento può determinare l’arrivo al lato ricevente di un pacchetto duplicato, e consegnato addirittura dopo che la connessione tra i due nodi è stata chiusa e riaperta. In tal caso però la nuova connessione adotta un diverso numero di sequenza iniziale, cosicché il pacchetto duplicato e ritardato risulta fuori sequenza, e non viene accettato.
[1380]Per ciò che riguarda i valori dei numeri di riscontro NR, questi sono incrementati di 1, perché la finestra (descritta nel seguito) inizia dai bytes del prossimo pacchetto, a cui competeranno appunto valori di NS incrementati di uno.
[1381]Il riscontro può viaggiare su di un pacchetto già in “partenza” con un carico utile di dati e destinato al nodo a cui si deve inviare il riscontro. In tal caso quest’ultimo prende il nome di piggyback (rimorchio), o riscontro rimorchiato.
[1382]In tal caso, il campo Puntatore Urgente contiene il numero di sequenza del byte che delimita superiormente i dati che devono essere consegnati urgentemente.
[1383]Il mancato invio del riscontro può anche essere causato dal verificarsi di un cecksum errato dal lato ricevente, nel qual caso quest’ultimo semplicemente evita di inviare il riscontro, confidando nella ritrasmissione per timeout.
[1384]Con licenza poetica: il ritardo del girotondo, che qui raffigura un percorso di andata e ritorno senza soste.
[1385]L’IP può trovarsi a dover inoltrare i pacchetti su sottoreti che operano con dimensioni di pacchetto inferiori. Per questo, deve essere in grado di frammentare il pacchetto in più datagrammi, e di ricomporli nell’unità informativa originaria all’altro estremo del collegamento.
[1386]Si suppone infatti che le sottoreti a cui sono connessi i nodi non garantiscano affidabilità. Ciò consente di poter usare sottoreti le più generiche (incluse quelle affidabili, ovviamente).
[1387]La Qualità del Servizio richiesta per il particolare datagramma può esprimere necessità particolari, come ad esempio il ritardo massimo di consegna. La possibilità di esprimere questa esigenza a livello IP fa parte dello standard, ma per lunghi anni non se ne è fatto uso. L’avvento delle comunicazioni multimediali ha risvegliato l’interesse per il campo tos.
[1388]Lo scopo del ttl è di evitare che si verifichino fenomeni di loop infinito, nei quali un pacchetto “rimbalza” tra due nodi per problemi di configurazione. Per questo, ttl è inizializzato al massimo numero di nodi che il pacchetto può attraversare, e viene decrementato da ogni nodo che lo riceve (e ritrasmette). Quando ttl arriva a zero, il pacchetto è scartato.
[1389]In presenza di un frammento ricevuto con errori nell’header viene scartato tutto il datagramma di cui il frammento fa parte, delegando allo strato superiore le procedure per l’eventuale recupero dell’errore.
[1390]Possiamo portare come analogia un indirizzo civico, a cui il postino consegna la corrispondenza, che viene poi smistata ai singoli condomini dal portiere dello stabile. Il servizio postale, così come la rete Internet, non ha interesse di sapere come sono suddivise le sottoreti delle diverse organizzazioni, ed i router instradano i pacchetti IP in base alla parte “rete” dell’indirizzo, delegando ai router della rete di destinazione il completamento dell’instradamento.
[1391]In questo caso, l’Università di Roma “La Sapienza” è intestataria della rete 151.100.
[1392]Ad esempio, organizzazioni con poco più di un migliaio di nodi erano costrette a richiedere una intera classe B con capacità di 65536 nodi.
[1393]Sebbene la topologia di Internet possa essere qualunque, nella pratica esistono dei carrier internazionali che svolgono la funzione di backbone (spina dorsale) della rete, interconnettendo tra loro i continenti e le nazioni.
[1395]Il termine multicast è ispirato alle trasmissioni broadcast effettuate dalle emittenti radio televisive.
[1396]Mediante il protocollo IGMP (Internet Group Management Protocol) che opera sopra lo strato IP, ma (a differenza del TCP) fa uso di datagrammi non riscontrati, similmente all’UDP ed all’ICMP.
[1397]Data l’impossibilità a stabilire un controllo di flusso con tutti i destinatari, il traffico multicast viaggia all’interno di pacchetti UDP.
[1398]E rappresenta quindi ciò che viene detto uno spazio di indirizzi piatto (flat address space).
[1399]Al contrario, il partizionamento dell’indirizzo IP in rete+nodo permette di utilizzare tabelle di routing di dimensioni gestibili.
[1400]Ad ogni porta del router è associata una coppia sottorete/maschera (vedi pag. 1) che descrive l’insieme degli indirizzi direttamente connessi alla porta. La verifica di raggiungibilità (o adiacenza) è attuata mettendo in and l’ip di destinazione con le maschere, e confrontando il risultato con quello dell’and tra le maschere e gli indirizzi delle sottoreti collegate.
[1401] Dato che i nodi possono essere spostati, possono cambiare scheda di rete e possono cambiare indirizzo IP assegnatogli, la corrispondenza IP-Ethernet è tutt’altro che duratura, ed ogni riga della tabella ARP indica anche quando si sia appresa la corrispondenza, in modo da poter stabilire una scadenza, ed effettuare nuovamente la richiesta per verificare se sono intervenuti cambiamenti topologici.
Se il nodo ha cambiato IP, ma non il nome, sarà il TTL del DNS (mantenuto aggiornato per il dominio del nodo) a provocare il rinnovo della richiesta dell’indirizzo.
[1405]Su di un cavo coassiale tick da 50 Ω, la velocità di propagazione risulta di 231 ⋅ 106 metri/secondo. Su di una lunghezza di 500 metri, occorrono 2.16μsec perché un segnale si propaghi da un estremo all’altro. Dato che è permesso congiungere fino a 5 segmenti di rete per mezzo di ripetitori, e che anch’essi introducono un ritardo, si è stabilito che la minima lunghezza di un pacchetto Ethernet debba essere di 64 byte, che alla velocità di trasmissione di 10 Mbit/sec corrisponde ad una durata di 54.4μsec, garantendo così che se si è verificata una collisione, le due parti in causa possano accorgersene.
[1406]Tick = duro (grosso), thin = sottile. Ci si riferisce al diametro del cavo.
[1407]Le sigle indicano infatti la velocità, se in banda base o meno, e la lunghezza della tratta.
[1408]Unshielded Twisted Pair (UTP), ossia la coppia ritorta non schermata.
[1409]La trasmissione full-duplex si instaura quando entrambe le interfacce agli estremi ne sono capaci. Una interfaccia half-duplex deve invece gestire situazioni interne di collisione, quando un pacchetto uscente da un nodo si scontra con uno entrante.
[1411]Per traffico real-time si intende sia quello telefonico, sia più in generale quello di natura multimediale.
[1412]Siamo alla fine degli anni ’80, e la definizione Integrated Service Data Network (isdn) si riferisce ad una rete in grado di permettere, oltre al normale trasporto dei dati, anche servizi di rete. La rete isdn era però limitata ad una velocità massima (presso l’utente) di 2 Mbps, e per questo venne chiamata narrow-bandisdn (n-isdn). A questa, avrebbe fatto seguito la broad-band isdn (b-isdn) che ha poi dato luogo alla definizione dell’atm.
[1413]Sono definite due tipi di interfaccia utente-network (uni): quella sdh/sonet, in cui le celle sono inserite nel payload della trama sdh, e quella cell-based, che prevede un flusso continuo di celle. Mentre nel primo caso il bit rate lordo comprende l’overhead di trama, nel secondo comprende la presenza di celle di tipo Operation and Maintenance (oam).
[1414]Nel primo caso la cella viene scartata, mentre nel secondo inoltrata correttamente. La presenza di più di due errori, provoca un errato inoltro della cella.
[1415]Le celle idle sono riconoscibili in base ad una particolare configurazione dei primi 4 byte dell’header, così come avviene per le celle oam, nonché per altri tipi particolari di cella, che trasportano la segnalazione degli strati superiori.
[1416]Mentre per vci sono riservati 16 bit, per vpi si usano 12 bit all’interno della rete, e 8 bit ai suoi bordi, riservando 4 bit indicati come Generic Flow Control (gfc) per regolare il flusso delle sorgenti.
[1417]Questa semplificazione del lavoro di instradamento, quando confrontata con quello relativo ad una rete ip, è all’origine della vocazione fast switching della rete ATM. Per di più, permette la realizzazione hardware dei circuiti di commutazione. D’altra parte, mentre per ip l’instradamento avviene al momento della trasmissione, in atm avviene durante il set-up della connessione, quando le tabelle di instradamento sono inizializzate.
[1418]Nel caso in cui venga invece scambiato solo il vci, si ottiene uno switch vc puro.
[1419]La rete ATM assicura la consegna delle celle di una stessa vcc nello stesso ordine con cui sono state trasmesse, mentre non assicura l’ordinamento per le celle di una stessa vpc.
[1420]Può accadere infatti di incontrare uno switch vc puro, in cui è scambiato solo il vci, ed al quale fanno capo due diverse vcc.
[1421]I nodi di ingresso ed uscita sono indicati come ingress ed egress nella terminologia ATM.
[1422]Nella richiesta di una svc, l’utente invia i messaggi di setup su di una particolare (well known) coppia vpi/vci=0/5. In generale, le prime 32 vci di ogni vpi sono riservate per propositi di controllo. In queste, sono contenuti dei messaggi di segnalazione che aderiscono alle specifiche Q.2931, che fanno parte di User Network Interface (uni) 3.1, e che sono un adattamento di Q.931 per n-isdn. Le specifiche uni 4.0 prevedono la negoziazione della QoS, e la capacità di richiedere una svc per una vpc.
[1423]Letteralmente: poliziottamento. Il controllo può anche essere effettuato su di una intera vpc.
[1424]La classe cbr si presta bene a trasportare traffico telefonico pcm. In questo caso, può trasportare solo gli intervalli temporali realmente occupati.
[1425]La classe ubr è particolarmente adatta al trasporto di traffico ip, in quanto questo è un protocollo senza connessione, e gli strati superiori (ad es. il tcp) sono in grado di gestire correttamente un servizio di collegamento con perdita di dati.
[1426]Un sagomatore è composto in prima approssimazione da un buffer di memoria, il cui ritmo di svuotamento non è mai superiore ad un valore costante.
[1427]Ad esempio, una cbr supera il proprio pcr, od una vbr oltrepassa il pcr per più tempo di mbs, oppure il traffico generato da una ubr non può essere instradato per l’esaurimento della banda.
[1428]Alcune classi di traffico pongono clp=1 già in partenza, sia per una capacità indipendente di risolvere situazioni di perdita di dati, sia per la diversa natura dei dati che possono inviare, come ad esempio una codifica di segnale in cui alcuni dati posso essere interpolati, mentre altri no. Al contrario, alcune sorgenti confidano molto nel rispetto del proprio clp=0, come ad esempio nel caso in cui queste inviino pacchetti di dati ben più grandi delle celle atm, e che sono di conseguenza frammentati in molte unità, ed in presenza di una sola cella mancante, devono ritrasmettere l’intero pacchetto. In quest’ultimo caso, sono state elaborate strategie di scarto precoce (early discard) di tutte le celle di un pacchetto, per il quale si è già verificato lo scarto di una cella componente.
[1429]Il formato nsap si ispira al Network Service Access Point dell’OSI, e se ne differenzia per aver fuso i campi Routing Domain e Area in un solo campo ho-dsp, per il quale si è adottata una gerarchia di instradamento basata su di un prefisso mobile, in modo simile al cdir dell’ip.
[1430]Questi ultimi 4 byte contengono l’indicazione (2 bit) se si tratti della prima, ultima od intermedia cella di una stessa cs-pdu, la lunghezza dei dati validi se è l’ultima (6 bit), un numero di sequenza (4 bit), un controllo di errore (10 bit), ed una etichetta (10 bit) che rende possibile interallacciare temporalmente le celle di diverse cs-pdu.
[1431]In questo modo si risparmiano 4 byte ogni 48. Ora però è indispensabile che le celle arrivino in sequenza, e non è più possibile alternare diverse cs-pdu.
[1432]Quando la distanza tra i nodi oltrepassa dimensioni di un edificio, si parla di Campus Network o di Wide Area Network (wan), ed a volte è usato il termine Metropolitan Area Network (man) per estensione cittadine. Per estensioni ancora maggiori si parla di reti in area geografica.
[1433]Tutti i nodi della lis hanno configurato manualmente l’indirizzo atm del server atmarp.
[1434]Un vc permanente collega solamente una coppia di nodi, ed in tal caso è possibile anche fare a meno del server atmarp, in quanto un pvc è configurato manualmente. Nei fatti, questo è l’uso più diffuso del trasporto ip over atm, ed è tipicamente utilizzato per collegare sedi distanti di una stesso sistema autonomo, eliminando la necessità di sviluppare in proprio un impianto di tlc tra le sedi.
[1435]La emulazione di una lan da parte della rete atm è possibile dopo aver definito per ogni elan un lan Emulation Server(les) a cui ognilan Emulation Client (lec) si rivolge per conoscere l’indirizzo atm di un altro lec, a partire da suo indirizzo mac (la traduzione da ip a mac è già avvenuta tramite arp a livello ip). In una elan deve inoltre essere presente un dispositivo Broadcast and Unknown Server (bus) che diffonde a tutti i lec i pacchetti broadcast Ethernet (come ad es. le richieste arp), e che viene usato dai lec che devono inviare un broadcast. Infine, occorre un lan Emulation Configuration Server (lecs) che conosce, per ogni elan della rete atm, l’elenco dei lec, del les e del bus.
All’accensione di un lec, questo contatta il lecs (conoscendone l’indirizzo atm, oppure su di una vcc ben nota, o tramite segnalazione atm) per apprendere gli indirizzi atm del proprio les e del bus. Quindi, registra presso il les la corrispondenza tra i propri indirizzi mac ed atm. Quando un lec desidera inviare dati ad un altro lec, dopo averne risolto l’indirizzo atm interrogando il les, incapsula le trame ip con un header llc ieee 2 proprio come nel caso classico.
[1436]I nhs risiedono su dispositivi che sono anche router ip, e che quindi mantengono aggiornate le tabelle di instradamento che indicano il prossimo salto (next hop) verso destinazioni ip. Le richieste di risoluzione atmarp per un certo indirizzo ip sono instradate mediante queste stesse tabelle, giungendo di salto in salto fino al router-nhs appartenente alla stessa lis dell’ip di destinazione, che conosce la risposta. Quest’ultima ripercorre all’indietro il percorso fatto dalla richiesta, fino alla sorgente. I router attraversati dal passa parola,ricordano (per un pò) le risposte trasportate, riducendo il traffico nhrp.
[1437]Il metodo si basa su di un meccanismo indicato come flow detection, attuato dal ruoter ip-atm prossimo alla sorgente, che è in grado di accorgersi di traffico non sporadico diretto verso una medesima destinazione. Questo router impersona allora un mpoa Client (mpc), ed interroga un mpoa server (mps) per conoscere l’indirizzo atm della destinazione, in modo da creare un collegamento diretto. Ogni mps serve una o più elan, e gli mps comunicano tra loro mediante il nhrp.
L’mpoa realizza la separazione tra il calcolo dell’instradamento e l’inoltro dei dati. A differenza di un ruoter tradizionale, che svolge entrambi i compiti, l’mpc svolge solo l’inoltro verso l’indirizzo atm di destinazione, mentre quest’ultimo è fornito dall’mps, che si comporta quindi come un route server.
[1438]Nel routing IP tradizionale, una fec coincide con l’instradamento individuato dal longest match.
[1439]Nel routing ip convenzionale, per ogni router, la tabella di routing deve essere esaminata per intero per ogni pacchetto, alla ricerca del longest match tra le regole presenti.
[1440]Il routing ip tradizionale opera su di una base hop-by-hop, e per questo non può tenere conto della provenienza. Quando due pacchetti per una medesima destinazione passano da uno stesso router, proseguono per lo stesso percorso.
[1441]Infatti, è la label del pacchetto ricevuto che determina il next hop, e quindi è quest’ultimo a definire la semantica della label presso i propri vicini.
[1450]La tecnica di multiplare un blocco di bit (in questo caso 8) alla volta prende il nome di word interleaving, distinto dal bit interleaving, in cui l’alternanza è a livello di bit.
[1451]Il segnale PCM ispira il suo nome dal PAM (vedi § 24.9.5) in quanto ora, anziché trasmettere le ampiezze degli impulsi, si inviano i codici binari dei livelli di quantizzazione.
[1452]frame significa più propriamente telaio, e in questo caso ha il senso di individuare una struttura, da “riempire” con il messaggio informativo.
[1453]In figura è mostrato un esempio, in cui i campioni sij di N sorgenti Si si alternano a formare una trama. Durante l’intervallo temporale tra due campioni, devono essere collocati nella trama tutti gli M bit/campione delle N sorgenti, e quindi la frequenza binaria (in bit/secondo) complessiva sarà pari a fb = fc (campioni/secondo/sorgente) ⋅ N (sorgenti) ⋅ M (bit/campione).
[1458]Un oscillatore con precisione di una parte su milione, produce un ciclo in più o in meno ogni 106; ad una velocità di 2 Mbps, ciò equivale a un paio di bit in più od in meno ogni secondo.
[1459]Comité Consultif International pour la Telephonie et Telegraphie. Questo organismo non esiste più. ed ora l’ente di standardizzazione ha nome itu-t, vedi https://it.wikipedia.org/wiki/ITU-T.
[1462]Il contatore write, come anche read, conta in binario, e si incrementa con frequenza fW (fR). Le parole binarie rappresentate da read e Write forniscono l’indirizzo (all’interno del banco di memoria) in cui leggere i dati in uscita e scrivere quelli in ingresso rispettivamente.
[1463]Infatti il sincronismo di trama viene preservato; inoltre l’evento di sovrapposizione dei puntatori può essere rilevato, e segnalato ai dispositivi di demultiplazione, in modo che tengano conto dell’errore che si è verificato.
[1465]Con il termine payload si indica il carico pagante, ossia i dati che vengono trasportati
[1466]Notiamo che la differenza tra i 2349 ottetti di payload ed i 2016 canali voce fornisce 2349 - 2016 = 333 ottetti, che suddivisi per le nove righe, danno luogo a 37 ottetti per riga in più.
[1467]Sto parlando di qualcosa la cui odierna evoluzione mi è ignota, ma la storia merita di essere raccontata.
[1468]come ad esempio un centralino (PBX, private branch exchange) con 8 derivati (interni) e 2 linee esterne: se due interni parlano con l’esterno, un terzo interno che vuole anche lui uscire trova occupato. Si dice allora che si è verificata una condizione di blocco.
[1469]E’ una condizione sufficiente a scongiurare il blocco anche nella condizione peggiore. Tale circostanza si verifica quando:
▷ una matrice del primo stadio (i) ha n − 1 terminazioni occupate
▷ una matrice del terzo stadio (j) ha m − 1 terminazioni occupate e
▷ tali terminazioni non sono connesse tra loro, anzi le connessioni associate impegnano ognuna una diversa matrice intermedia e
▷ si richiede la connessione tra le ultime due terminazioni libere di i e j ⇒ in totale si impegnano allora m − 1 + n − 1 + 1 = m + n − 1 matrici intermedie.
[1470]Le comunicazioni presenti in uno stesso flusso, ovvero appartenenti alla stessa trama, condividono la stessa origine/destinazione.
[1471]La tecnica prende il nome di double buffering.
[1472]Ovviamente, m − n intervalli sono lasciati vuoti, in ordine sparso tra gli m.
[1473]Si confronti questo risultato con la condizione di Clos, fornita al § 24.8.2.
[1474]In inglese si dice andare off-hook, con riferimento storico al gancio su cui riporre la cornetta, presente nei primi modelli di telefono.
[1500]All’aumentare della lunghezza del collegamento, oltre a ridursi la potenza ricevuta e quindi peggiorare l’snr, aumenta l’entità della diafonia (di tipo next, pag. 1) tra utenti differenti, determinando un ulteriore peggioramento di snr, che la tecnica di modulazione affronta riducendo la velocità trasmissiva.
[1501]Ciò permette di non ascoltare nel telefono il fruscio della trasmissione adsl, e di ridurre il rischio che le comunicazioni vocali determino la caduta della connessione adsl.
[1502]I modem più recenti incorporano il passa alto al loro interno, e sono venduti assieme a splitter con la sola funzione passa basso per il canale vocale.
[1503]Non lasciarsi fuorviare dal ruolo di trasporto della rete, che in effetti assolve unicamente un ruolo di livello due (o di collegamento), in quanto il punto di uscita non è qualsiasi, ma l’isp fornitore dell’utente.
[1507]La pensata non ebbe molte applicazioni, se non in ambito della commutazione interna ad esempio ad un centralino, a causa della sensibilità del metodo agli errori di temporizzazione, ed alle caratteristiche del mezzo trasmissivo su cui inviare il segnale pam.
[1508]Lo switch off al digitale terrestre in Italia è avvenuto nel luglio 2012, ed anche i tubi catodici sono pressoché estinti..
[1509]La riproduzione di metà quadro alla volta è chiamata scansione interallacciata dell’immagine. Nulla vieta al costruttore del ricevitore di prevedere una memoria di quadro e di riprodurre le immagini in modo non interallacciato; il segnale trasmesso invece presenta sempre le righe in formato interallacciato.
[1510]La frequenza di 50 semiquadri/secondo è stata scelta di proposito uguale alla frequenza di funzionamento della rete elettrica, in modo che eventuali disturbi elettrici avvengano sempre nello stesso punto dell’immagine, riducendo gli effetti fastidiosi.
[1511]Il flicker si manifesta nel caso in cui la frequenza di rinfresco è inferiore al tempo di persistenza delle immagini sulla retina, pari a circa 140 di secondo.
[1512]In questo modo si riduce mediamente la potenza trasmessa, dato che sono più frequenti scene chiare che scure.
[1513]Nel tempo destinato alle linee che non sono mostrate vengono comunque trasmesse altre informazioni, come ad esempio i dati che compaiono nelle pagine del televideo.
[1514]Ad esempio, si può stabilire di realizzare la stessa risoluzione orizzontale e verticale. A fronte delle 625 linee, il rapporto di aspetto di 43 determina l’esigenza di individuare 625 ⋅ 43= 833 puntilinea, e quindi 833 ⋅ 625 = 520625 puntiquadro, ossia circa 13 ⋅ 106puntisecondo. Per il teorema del campionamento, il segnale deve allora avere una banda minore od uguale di fc2 = 6.5 MHz.
[1515]In realtà ogni componente è pesata mediante un opportuno coefficiente che tiene conto della diversa sensibilità dell’occhio ai tre colori fondamentali. Infatti per ottenere il bianco i tre colori non devono essere mescolati in parti uguali, bensì 59% di verde, 30% di rosso e 11% di blu.
[1516]Le ampiezze delle componenti in fase e quadratura del segnale di crominanza devono essere opportunamente scalate, per impedire al segnale complessivo (luminanza più crominanza) di assumere valori troppo elevati.
[1517]Possiamo riflettere su quali siano le circostanze che producono la massima interferenza della luminanza sulla crominanza: ciò avviene in corrispondenza di scene molto definite, relative ad immagini con elevato contenuto di frequenze spaziali elevate, ad esempio nel caso di righe fitte; il disturbo è più appariscente nel caso in cui la zona ad elevato contrasto sia povera di componenti cromatiche. Avete mai notato cravatte a righine bianche e nere, divenire cangianti ?
[1518]La portante di colore si colloca a 4,43361975 MHz per il sistema pal.
[1524]Dal greco hypsos che significa altezza. Mentre l’ipsografia è un diagramma che individua il rilievo altimetrico terrestre, il termine ipsogramma è a volte usato nelle telecomunicazioni per descrivere come varia il livello di potenza in funzione della portata di un collegamento.
[1525]Più precisamente, l’eirp è la potenza che erogherebbe una antenna isotropa, per generare lo stesso campo elettrico prodotto dalla antenna direttiva nella direzione di massimo guadagno.
[1526]Un satellite in orbita geostazionaria è visto da terra sempre nella stessa posizione (e ciò consente di puntare l’antenna in modo permanente) in quanto la sua orbita giace sul piano definito dall’equatore, ed il suo periodo di rivoluzione attorno all’asse terrestre coincide con quello di rotazione della terra (pari ad un giorno). Il moto orbitale è causa di una forza centrifuga, che è bilanciata da quella centripeta prodotta dall’attrazione terrestre. Dato che all’aumentare della distanza dalla terra, la prima aumenta (con orbite più grandi, deve aumentare la velocità tangenziale) e la seconda diminuisce, la quota di 36.000 Km costituisce un punto di equilibrio, al disotto del quale il satellite precipiterebbe al suolo, ed al disopra del quale si perderebbe nello spazio.
[1527]Le considerazioni sulla diafonia si applicano altrettanto bene anche al caso di ripetitori terrestri.
[1528]Come descritto al § 12.2.7, l’oscillatore locale deve avere una frequenza fe tale che fd = fu − fe, in modo che il segnale di downlink sia centrato ad una frequenza pari alla differenza tra quella di uplink e quella di eterodina.
[1529]La suddivisione della amplificazione in due stadi a frequenza diversa previene fenomeni di reazione positiva.
[1532]Per contro, nel caso in cui dietro al satellite verso cui è puntata l’antenna vi sia una stella luminosa, la Ta è più elevata.
[1533]Come descritto nel paragrafo che discute dell’effetto pelle (pag. 1), l’attenuazione in dB del cavo aumenta con l’aumentare della radice della frequenza.
Prev Indice AnaliticoSu Part IV: Sistemi di TelecomunicazioneNote di copertina Next
Cliccando sul bottone acconsenti a salvare sul tuo device i cookie provenienti da questo sito,
utilizzati al solo fine di migliorare l'esperienza di navigazione
Spiegami meglio


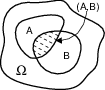
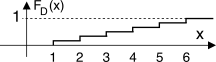





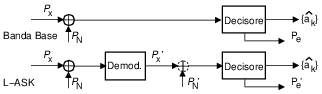
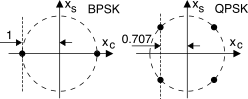





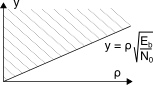

{kind=link}
{kind=link}