Capitolo 1
Introduzione al GPS
1.1 Caratteristiche Generali
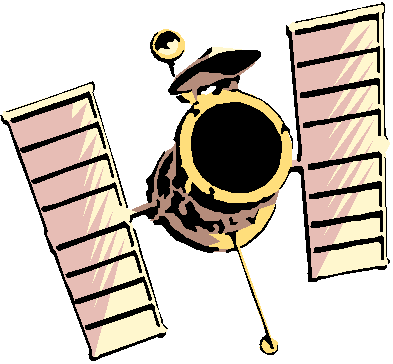
Il Global Position System (GPS) e’ un sistema di rilevamento della posizione basato su una particolare costellazione di satelliti , in numero di 24 di cui 21 operativi ed altre unita’ di scorta ( si deve tenere conto infatti che il periodo vitale di un satellite artificiale va’ da 7 a 10 anni) , posti ad una distanza media di 20200 Km dalla terra , suddivisi in sei piani orbitali formanti un angolo di 60° ed inclinati rispetto all’equatore di 55°. La figura 1 puo’ aiutare a comprendere il dislocamento satellitare.

Figura
1 Costellazione dei satelliti GPS
Tale sistema e’ stato sviluppato a partire dagli anni 70 dal Dipartimento della Difesa degli Stati Uniti (DoD) con lo scopo di permettere a tutte le strutture militari e paramilitari di determinare la propria posizione sull' emisfero terrestre , riservando una parte per applicazioni prettamente civili. Allo stesso tempo il DoD si preoccupo’ di inserire una degradazione per le applicazioni civili in modo da garantire un errore medio di posizionamento vicino ai 100 metri, (introduzione della Disponibilita’ Selettiva SA ). Ovviamente l’introduzione di tale segnale ha scatenato ricercatori di tutto il mondo tanto che oramai questo disturbo e’ stato rimosso visto che le soluzioni trovate per migliorare la precisione del sistema hanno raggiunto risultati del tutto inaspettati anche da parte del DoD , basti pensare che in alcuni casi si raggiunge una precisione al sotto del metro senza particolari attrezzature tecnologiche. Grande successo ha avuto in questo senso lo sviluppo del GPS differenziale.
1.2 I Segmenti GPS
Il sistema si suddivide in tre segmenti :spaziale,di controllo, utente.
Segmento spaziale : e’ costituito dall’insieme dei satelliti
Segmento utente : e’ costituito dai ricevitori utente ,ne esistono ovviamente una grande quantita’ in commercio e si suddividono in due categorie fondamentali a singolo frequenza o a doppia frequenza .
Segmento di controllo:

Figura 2 Segmenti GPS
Come vediamo in figura 2 il segmento di controllo e’ formato da particolari stazioni di terra , le quali hanno il compito di correggere gli errori degli orologi di bordo dei satelliti , la rete delle stazioni di controllo e’ visibile in figura tre.
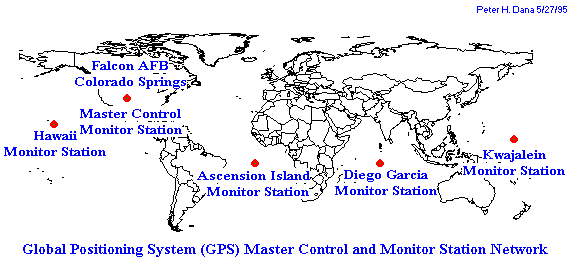
Figura 3:Master Control Station
1.3 Principi di Funzionamento
Ovviamente il sistema GPS non fu il primo ad essere sviluppato , il DoD realizzo’ sistemi basati sull’effetto Doppler (sistema Transit) che prevedevano due passaggi del satellite ed una sincronizzazione perfetta tra orologio utente e orologio satellitare. Questo sistema fu presto abbandonato per la scarsa precisione , per i costi ma soprattutto per i tempi di attesa fra un passaggio e l’altro del satellite. L’effetto Doppler fu sostituito dalla misurazione della distanza fra utente e satellite e quindi il problema era quello di trovare un sistema che realizzasse tale misura in modo molto preciso. Per questo i satelliti furono dotati di orologi atomici ed il calcolo della posizione utente venne fatto utilizzando l’intersezione fra le sfere dovute ai raggi che si ricavano considerando l’utente ed i singoli satelliti. In particolare considerando 4 satelliti e quindi 4 sfere , l’intersezione fra le sfere da’ luogo ad un unico punto , ed e’ quindi determinata univocamente la posizione utente. Importanza rilevante per una corretta misurazione ha la geometria satellitare , migliore e’ la separazione fra i satelliti migliore e’ la misurazione , se infatti osserviamo la figura 5
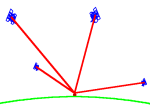
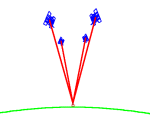
Figura 4 Geometria corretta Figura 5 Geometria non efficiente
notiamo che i satelliti sono molto allineati quindi e’ come se il ricevitore ne vedesse uno solo .Ogni satellite trasmette impulsi radio ad istanti prefissati , quindi sapendo l’istante di arrivo dell’ impulso , il ricevitore e’ in grado di risalire alla distanza del satellite trasmittente. Sembra evidente quindi che il livello di sincronizzazione degli orologi deve essere elevatissimo viste le distanze in campo, basti pensare che un errore di un milionesimo di secondo si traduce in 300 metri di margine di precisione.
4 Posizione Utente e Precisione del Sistema
Come abbiamo detto per il calcolo della posizione utente sono necessari quattro satelliti , in pratica pero’ ne bastano tre poiche’ l’intersezione delle prime tre sfere genera due punti di cui uno cade all’interno della Terra. Per il calcolo matematico si deve risolvere il seguente sistema:
(X1-Ux)^2+(Y1-Uy)^2+(Z1+Uz)=(t1
c)^2
(X2-Ux)^2+(Y2-Uy)^2+(Z2+Uz)=(t2 c)^2
(X3-Ux)^2+(Y3-Uy)^2+(Z3+Uz)=(t3 c)^2
(X4-Ux)^2+(Y4-Uy)^2+(Z4+Uz)=(t4 c)^2
dove
c è la velocità della luce X, Y, Z sono le coordinate
del satellite ,Ux, Uy, Uz sono le coordinate del ricevitore GPS.
Risolvendo questo sistema si può ricavare:
· la
posizione avendo il dato di tempo
· il dato di tempo
avendo l'esatta posizione.
Il sistema fornisce due livelli di servizio :
Standard Position Service (SPS) , dedicato alle applicazioni civili e come detto precedentemente sotto totale controllo e guida del DoD . Con l’introduzione della SA i valori di precisione attesi erano i seguenti:
![]() 100 meter horizontal accuracy
100 meter horizontal accuracy
![]() 156 meter vertical accuracy
156 meter vertical accuracy
![]() 340 ns time accuracy
340 ns time accuracy
Precise Positioning Service (PPS) , dedicato agli utenti autorizzati dal DoD, ai quali e’ garantito un livello di precisione molto elevato .
Capitolo 2
Il GPS Differenziale
2.1 Generalita’
Come abbiamo detto Il GPS e’ soggetto ad errori , nel corso degli anni quindi si e’ cercato di rimediare elaborando sistemi via via sempre piu’ efficienti , in particolare, Charles C. Counselman III ed i colleghi del Massachussetts Institute of Technology diedero vita al cosiddetto GPS Differenziale (dgps).

Figura 6:schema base dgps
In figura 6 abbiamo la struttura generica di un sistema differenziale , attraverso un collegamento dati (data link) l’utente e’ connesso ad una stazione fissa , la quale attraverso una complessa elaborazione dei parametri ricevuti dai satelliti e’ in grado di generare la correzione da applicare alle misure ricavate dal ricevitore utente. In genere e’ lo stesso ricevitore ad accorgersi del collegamento con una stazione differenziale , a questo punto applica un semplice algoritmo che permette di ricavare una misura molto precisa della posizione utente.
2.2 Collegamento alla stazione differenziale
In questa breve sezione di chiara utilita’ pratica spiegheremo le modalità di connessione alla stazione differenziale con un ricevitore di tipo commerciale . I ricevitori GPS sono di dimensioni variabili, quelli tascabili sono grandi piu’ o meno come un normale telefonino mobile , hanno un display con un menu’ e relative opzioni , una di queste permette di stabilire il formato dei dati sia in ingresso che in uscita .Difatti e’ possibile collegare il ricevitore ad un comune computer ed e’ quindi necessario che fra le due macchine sia definito un protocollo , le due macchine possono scambiarsi dati in formato testo (ascii) , in formato proprietario (relativo al produttore) ,oppure nel formato NMEA (National Marine Elettronics Association) ,il quale e’ riconosciuto da tutti i ricevitori GPS .Viceversa per comunicare i dati differenziali al ricevitore attraverso il data link ,oltre ai formati proprietari, si utilizza il formato RTCM-SC104 (Radio Technical Commission For Maritime Services). Per effettuare il collegamento fisico alla stazione e’ sufficiente selezionare un opportuno formato di input /output dati , non e’ necessario viceversa utilizzare altre opzioni per verificare la sincronia dei dati o il funzionamento del ricevitore in dgps-mode , l’effettivo funzionamento differenziale deve essere valutato ponendo il ricevitore in ambiente aperto , collegandolo alla stazione differenziale , e verificando che ogni satellite in vista sia marcato con una “d” , che appunto significa “corretto differenzialmente”. Deve essere noto infatti che altri sistemi di verifica per il funzionamento differenziale possono dare risultati errati a causa della apparente mancanza di sincronia fra stazione e ricevitore , soprattutto quando questi sono di aziende produttrici diverse.
2.3 Le stringhe NMEA
Vediamo alcuni esempi di stringhe NMEA emesse dal un ricevitore GPS collegato ad un computer.
|
1) $GPRMC, 225446,A,4916.45,N,12311.12,W,000.5,054.7,191194,020.3,E*68 |
|
2) $GPRMB,A,0.00,R,010,ASCEND,3743.000,N,12214.000,W,000.0,000.0,,A*28 |
|
3) $GPGGA, 123519,4807.038,N,01131.000,E,1,08,0.9,545.4,M,46.9,M, , *42 |
|
4) $GPGSA,A,3,01,03,,,15,21,23,25,31,,,,,,,,0.7,0.4,0.6*36 |
|
5) $GPGSV,3,1,09,01,70,041,49,03,17,209,46,09,01,031,00,14,05,281,34*76 |
|
6) $GPGSV,3,2,09,15,30,315,50,21,46,069,50,23,11,086,39,25,31,159,49*7F |
|
7) $GPGSV,3,3,09,31,28,249,48,,,,,,,,,,,,*4B |
|
8) $PGRME,5.9,M,10.1,M,11.7,M*25 |
|
9) $GPGLL,3743.000,N,12214.000,W,011243,A*3B |
Tabella 1 : Alcune Stringhe NMEA
Stringa 1
RMC - Recommended minimum specific GPS/Transit data
* 225446 Time of fix 22:54:46 UTC
* A Navigation receiver warning A = OK, V = warning
* 4916.45,N Latitude 49 deg. 16.45 min North
* 12311.12,W Longitude 123 deg. 11.12 min West
* 000.5 Speed over ground, Knots
* 054.7 Course Made Good, True
* 191194 Date of fix 19 November 1994
* 020.3,E Magnetic variation 20.3 deg East
* *68 mandatory checksum
Stringa 3
GGA - Global Positioning System Fix Data
* 123519 Fix taken at 12:35:19 UTC
* 4807.038,N Latitude 48 deg 07.038' N
* 01131.000,E Longitude 11 deg 31.000' E
* 1 Fix quality: 0 = invalid
* 1 = GPS fix
* 2 = DGPS fix
* 08 Number of satellites being tracked
* 0.9 Horizontal dilution of position
* 545.4,M Altitude, Metres, above mean sea level
* 46.9,M Height of geoid (mean sea level) above WGS84
* ellipsoid
* (empty field) time in seconds since last DGPS update
* (empty field) DGPS station ID number.
Per la lista completa delle stringhe e del loro significato si rimanda al codice “nmea.c” di Wolfgang Rupprecht e contenuto in dgpsisp-1.32 . Mi preme comunque segnalare la vasta gamma di dati che si possono acquisire dalle stringhe NMEA , in particolare quelle sopra descritte sono state utilizzate per la creazione del DGPS-NAVIGATOR , un GTK-Program in grado di visualizzare tutte le informazioni piu’ importanti ricavate dal GPS.
2.4 Le Stringhe RTCM_SC104
Questo standard permette alla stazione differenziale di generare , partendo dai dati ricevuti dai satelliti , una vasta gamma di messaggi , ogni messaggio ha una sua funzione specifica , in figura 7 abbiamo le prime due word di ogni messaggio.
Il Preambolo ha un formato esadecimale fisso “66” , e’ infatti costituito dai seguenti bit 01100110 e determina l’inizio di ogni messaggio , e’ utilizzato dal decoder interno al ricevitore per sincronizzarsi con la trama rtcm .
Il Message type e’ costituito da 6 bit e quindi possiamo avere 64 diversi tipi di messaggio.
 Prima
word di ogni messaggio
Prima
word di ogni messaggio
Preamble Message Type
Station I.D Parity
1
2 3 4 5 6 7 8 9 10 11 12
13 14 15 16 17 18 19 20 21 22 23 24
25 26 27 28 29 30
bit
FBT msb lsb msb lsb LBT
Seconda word di ogni messaggio
Modified z-count
Seq.n° n° of word st .healt
Parity
1
2 3 4 5 6 7 8 9 10 11 12
13 14 15 16 17 18 19 20 21 22 23 24
25 26 27 28 29 30
bit
FBT lsb msb lsb LBT
Figura 7 :Le word rtcm comuni a tutti i messaggi
|
word1 |
preamble |
Mess.type |
station_id |
parity |
|
|---|---|---|---|---|---|
|
N#bit |
8 |
6 |
10 |
6 |
|
|
word2 |
mdz_zcnt |
seq_n# |
N#word |
st_healt |
parity |
|
N#bit |
13 |
3 |
5 |
3 |
6 |
Tabella 2:Contenuto in bit delle word rtcm comuni
Lo station ID permette il riconoscimento della stazione , bisogna specificare che questo valore deve essere impostato manualmente ma non sempre gli si da’ importanza , per questo motivo alcune stazioni non hanno alcun ID di riconoscimento e questo non permette una eventuale separazione dei dati provenienti da stazioni diverse nel caso di ricezione multipla sulla base dello station ID.
La parita’ e’ costituita da 6 bit opportuni che permettono al decoder di rilevare errori di sincronizzazione o ricezione .
Il modified Z-count E’ il riferimento temporale e determina l’inizio della trama successiva .
Gli altri parametri determinano rispettivamente :
il numero di sequenza , il quale assume valori ciclici da 0 a 7
il numero delle word che formano il messaggio
lo stato di salute della stazione.
Dopo questa panoramica , di carattere introduttivo , possiamo addentrarci nel progetto , cominciando con l’analizzare il funzionamento della stazione differenziale a nostra disposizione .Prima di tutto e’ necessario uno sguardo sul progetto “Broadcasting di Correzione di GPS su IP” , sviluppato nell’anno accademico 2000/2001 e che ha costituito una valida base di partenza.
Maggiori dettagli sul formato NMEA ed RTCM-SC-104 saranno aggiunti successivamente nella parte di generazione dei codici: “metaserver2.c” ,”minimetas.c” ,”GTK-dgpsnavigator” e nella parte di elaborazione con Octave. Per una analisi approfondita si rimanda al volume “RTCM recommended standards for differenzial GNSS” (copyrigth 2001 rtcm) , si veda anche www.rtcm.org .
Capitolo 3
Panoramica sul progetto “Broadcasting di Correzione di GPS su IP”
3.1 Distribuzione delle correzioni differenziali via Internet
Come detto nella sezione 2.1 e come si vede dalla figura 6 e’ possibile acquisire i dati correttivi disponendo di una opportuna apparecchiatura in grado di collegarsi alla stazione differenziale. Prima dello sviluppo della rete Internet l’unico modo per acquisire questi dati era l’uso di un ricevitore radio portatile collegato al ricevitore gps secondo uno degli standard citati precedentemente. Dopo lo sviluppo della rete Wolfgang Rupprech (www.wsrcc.com/wolfgang) penso’ di distribuire i dati correttivi utilizzando una sola radio per molti utenti tutti collegati ad un opportuno server. In questo modo si ha un risparmio economico , e’ possibile in teoria contattare diversi server per ottenere le correzioni piu’ opportune , e’ possibile elaborare le informazioni rtcm ed nmea attraverso opportuni programmi e quindi sfruttare al 100% tutte le potenzialita’ del ricevitore GPS. Daltra parte l’utente deve possedere un dispositivo per la connessione alla rete :un computer , un portatile , un palmare oppure un telefonino con tecnologia WAP o UMTS. Vediamo in figura 8 la struttura necessaria per il dgps su IP:
Dgps:GPS+RTCM Programma client Portatile
RTCM station Computer Server Internet Network






Figura 8 Struttura del dgps su IP
La struttura comprende componenti hardware :ricevitore gps , rtcm station e due elaboratori oltre alla rete internet , ma anche componenti software , ovvero il programma server e quello client. Il programma che permette la ricezione dei dati dalla stazione e’ chiamato programma server ed e’ liberamente scaricabile in formato tar. gz-linux con il nome di dgpsip-1.32 , viceversa il programma che fornisce il servizio e’ chiamato single-client dgpsipd-1.06 , anche questo liberamente scaricabile. Bisogna sottolineare che questo programma non consente connessioni multiple alla stazione , lo stream rtcm diventa accessibile ad un solo utente , per questo il target del progetto “Broadcasting di Correzione di GPS su IP”, era quello di permettere la connessione ad una molteplicita’ di utenti. Per una analisi approfondita su questo progetto si rimanda all’omonimo testo disponibile al dipartimento INFOCOM dell’Universita’ La Sapienza in Roma Facolta' di Ingegneria.
In questa sezione verranno esaminati i problemi ed in generale i “bugs”di metaserver1 per dare la possibilita' al lettore di capire passo dopo passo gli sviluppi dei successivi programmi.
La piattaforma Software il sistema operativo Linux
Una breve parentesi va' fatta per illustrare le qualita' e le potenzialita' del sistema operativo su cui si siamo basati. Sia la stazione rtcm sia le macchine utilizzate per lo sviluppo software ,sfruttano il sistema operativo Linux. Vale la pena citarne alcune caratteristiche fondamentali.
Il mondo Open Source
Tutti i programmi sono corredati di codice, cio' significa che ogni utente puo' valutarne pregi e difetti ed eventualmente procedere a modifiche del codice stesso. Tutto il codice e' publicato con licenza “ Free Software Foundation, Inc.”. Ovviamente e' facile immaginare quale immenso aiuto e' dato allo sviluppatore-software,che puo' imparare semplicemente decodificando il codice gia' presente ,oppure puo' riutilizzare parte del codice di altri programmi ,inserirlo in un progetto piu' ampio e poi ridistribuire il tutto ad altri utenti.
Le distibuzioni Linux
Una distribuzione (distro) Linux e' una semplice raccolta di programmi , ogni societa' si preoccupa poi di personalizzare i programmi e' di rendere unica la distro prodotta. Tutte le distribuzioni hanno come punto di riferimento la filosofia “Open Source” di conseguenza la maggior parte di loro sono liberamente scaricabili dalla rete. Le potenzialita' delle distribuzioni sono diverse caso per caso ma tutte danno la possibilita' di sfruttare il computer in diversi molteplici modi , ed e' per questo che Linux si e' dimostrato efficiente sia dal lato server sia da quello client , ma anche come piattaforma di sviluppo. Una delle caratteristiche che si deve citare e' la capacita' di multitasking , ovvero di esecuzione contemporanea, o meglio, concorrente di piu' processi ,dove per processo si intende una attivita' della macchina dovuta ad un programma , il programma viceversa e' una unita' passiva. E' fondamentale che l'utente abbia la possibilita' durante lo sviluppo del software di poter valutare il consumo delle risorse macchina eseguito da un processo ,di seguito vediamo i comandi elementari che sono stati ampiamente utilizzati per mantenere il controllo della macchina durante il lavoro:
![]() ps [opzione]:fornisce le seguenti informazioni per ogni
processo in esecuzione:
ps [opzione]:fornisce le seguenti informazioni per ogni
processo in esecuzione:
pid: numero identificativo del processo
tty: codice di identificazione del terminale
stat: stato del processo , R=running , S=sleeping
time: tempo di esecuzione
command: comando relativo al programma
Le opzioni sono -a per mostrare i processi degli altri utenti , oppure -x per mostrare i processi non controllati da un terminale. Vediamo in figura 9 un output del comando “ps x”.
|
PID TTY STAT TIME COMMAND |
|
6761 pts/5 S 0:00 /bin/bash |
|
7120 pts/5 R 0:01 ./dgpsip -h gnssip.ing.uniroma1.it -d |
|
7124 pts/3 R 34:03 ./decoder2 -t 28000 -h BOCH0 |
|
7125 pts/1 R 34:00 ./decoder2 -t 28000 -h BRUS0 |
|
7126 ? S 0:13 /usr/lib/openoffice/program/soffice.bin private:facto |
|
7174 ? S 0:00 evolution |
|
7177 ? S 0:00 oafd --ac-activate --ior-output-fd=10 |
|
7185 ? S 0:00 bonobo-moniker-xmldb --oaf-activate-iid=OAFIID:Bonobo |
|
7189 ? S 0:00 evolution-mail --oaf-activate-iid=OAFIID:GNOME_Evolut |
|
7191 ? S 0:00 /usr/bin/gconfd-1 12 |
Figura 9:Output del comando “ps x”
Come vediamo i processi 7120 7124 7125 sono attivi ,in particolare essi sono dovuti all'esecuzione dei programmi dgpsip e decoder2 .
![]() top :e' un comando simile a “ps “ ma permette di
visualizzare piu' opzioni
top :e' un comando simile a “ps “ ma permette di
visualizzare piu' opzioni
L'output del comando “top” e' sufficientemente autoesplicativo , in tutti i casi si rimanda alla relativa pagina “man” visibile con il comando “man top”. Le pagine “man “ sono disponibili per tutti i comandi macchina o istruzioni di programmazione. Sottolineo i campi PRI e NI dove viene mostrata la priorita' di esecuzione del processo. Alcune volte e' vantaggioso eseguire un processo con bassa priorita' quando non gli si vuole dare molta CPU sottraendola a processi che si ritengono piu' importanti.

10:33:57 up 27 min, 4 users, load average: 0,01, 0,15, 0,32
72 processes: 71 sleeping, 1 running, 0 zombie, 0 stopped
CPU states: 9,3% user 1,6% system 0,0% nice 0,0% iowait 89,0% idle
Mem: 384580k av, 375180k used, 9400k free, 0k shrd, 20200k buff
270288k actv, 104k in_d, 4300k in_c
Swap: 843360k av, 2008k used, 841352k free 221108k cached
PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME CPU COMMAND
1 root 15 0 104 84 56 S 0,0 0,0 0:04 0 init
2 root 15 0 0 0 0 SW 0,0 0,0 0:00 0 keventd
3 root 15 0 0 0 0 SW 0,0 0,0 0:00 0 kapmd
4 root 34 19 0 0 0 SWN 0,0 0,0 0:00 0 ksoftirqd_CPU
9 root 25 0 0 0 0 SW 0,0 0,0 0:00 0 bdflush
5 root 15 0 0 0 0 SW 0,0 0,0 0:00 0 kswapd
6 root 15 0 0 0 0 SW 0,0 0,0 0:00 0 kscand/DMA
7 root 15 0 0 0 0 SW 0,0 0,0 0:00 0 kscand/Normal
8 root 15 0 0 0 0 SW 0,0 0,0 0:00 0 kscand/HighMe
10 root 15 0 0 0 0 SW 0,0 0,0 0:00 0 kupdated
11 root 25 0 0 0 0 SW 0,0 0,0 0:00 0 mdrecoveryd
63 root 24 0 0 0 0 SW 0,0 0,0 0:00 0 khubd
2549 root 15 0 616 96 0 S 0,0 0,0 0:00 0 isdnlog
2673 root 15 0 116 64 36 S 0,0 0,0 0:00 0 syslogd
2677 root 15 0 48 4 0 S 0,0 0,0 0:00 0 klogd
2695 rpc 23 0 76 0 0 SW 0,0 0,0 0:00 0 portmap
[mauro@hall2001 mauro]$
Figura 10:output del comando top
![]() kill :e' il comando che ci permette di “uccidere”un processo
attivo , anche in modo multiplo ,ad esempio : kill 7120
7124 7125 , “uccidera'”
i relativi processi ovvero chiudera' i
programmi che li hanno generati . Questo non e' sempre vero
,difatti un programma puo' generare piu' processi quindi puo'
rimanere in esecuzione anche alla chiusura di uno dei processi da
lui generati. Questa importante proprieta' di generazione multipla
di processi e di esecuzione contemporanea degli stessi e' stata
ampiamente sfruttata in metaserver1 , di cui ora analizzeremo tutte
le caratteristiche.
kill :e' il comando che ci permette di “uccidere”un processo
attivo , anche in modo multiplo ,ad esempio : kill 7120
7124 7125 , “uccidera'”
i relativi processi ovvero chiudera' i
programmi che li hanno generati . Questo non e' sempre vero
,difatti un programma puo' generare piu' processi quindi puo'
rimanere in esecuzione anche alla chiusura di uno dei processi da
lui generati. Questa importante proprieta' di generazione multipla
di processi e di esecuzione contemporanea degli stessi e' stata
ampiamente sfruttata in metaserver1 , di cui ora analizzeremo tutte
le caratteristiche.
Analisi di Metaserver1
Come si vede in figura 11 , la struttura di metaserver1 prevede almeno la creazione di due processi figli , controllo connessioni, ricevi rtcm ,nel caso in cui ci sia una connessione entrante ,o piu' connessioni , metaserver1 crea un nuovo processo figlio ,
quindi poiche' il dimensionamento del sistema e' stato fatto su un massimo di 64 connessioni , abbiamo un 66 processi concorrenti possibili , piu' il processo padre.

blocco ”define”
blocco “include”
blocco definizione variabili
1


gestione file di log:
openlog,setlogmask,syslog
2

apertura file di configurazione
conta stazioni
gestione segnali:
signal
3

creazione semafori:
semget,semctl
connessione stazione j
creazione pipe
4

creazione “processo controllo connessione”
fork()

 5
5


processo padre processo figlio (1)


 controllo
connessioni
controllo
connessioni
aggiornamento ritardo
stampa situazione
ciclo infinito
 6
6
funzione ricevirtcm()
 creazione
“figlio ricevi rtcm”
creazione
“figlio ricevi rtcm”
 7
7


processo padre processo figlio (2)


lettura dati stazione j:
read
controllo connessione
ciclo infinito
8

 creazione del socket
creazione del socket
socket,memset,bind,
shutdown,listen
9
accept---->fork()
 creazione “processo
invia rtcm”
creazione “processo
invia rtcm”

 10
10

 processo padre processo
figlio (3+?)
processo padre processo
figlio (3+?)



interazione con il client
spedizione lista stazioni
scelta utente
invio rtcm
11
Figura 11: Flow chart di Metasever1



![]()
![]()
![]()
![]()
![]()



 client
stazione
rtcm
client
stazione
rtcm

![]()
![]()
![]()


 client
Metaserver1 stazione rtcm
client
Metaserver1 stazione rtcm
![]()
 client
stazione
rtcm
client
stazione
rtcm
![]()
![]()
![]()
Figura 12: Schema Metaserver1
Come si vede dal blocco 5 in figura 11 , la creazione di un processo figlio necessita dell'istruzione “fork”,questa istruzione facilita la programmazione e la logica di un programma , ma consuma molte risorse macchina . Difatti ogni volta che si esegue un forking tutto il codice precedente viene raddoppiato , raddoppiano di conseguenza i consumi di memoria e di cpu ,possiamo affermare che un primo bug di metaserver1 sia stato l'eccessivo uso del forking.
Come detto prima in conseguenza ad una fork il codice precedente viene raddoppiato , ora se si osserva il blocco 4 in figura 11 si vede che sia le “pipe” sia i “semafori” (particolari strutture che regolano l'accesso ad una risorsa ) sono create (giustamente) prima della fork ,questo aumenta enormemente il consumo di risorse macchina e richiede particolari accortezze in fase di sviluppo , come ad esempio la chiusura delle “pipe” in lettura o scrittura dopo la fork nei processi non interessati al loro utilizzo. Inoltre tutti gli strumenti di tipo IPC come appunto “pipe” e “fork” (ma anche “fifo” e “code”) devono essere create dal processo padre per poter essere condivise opportunamente da tutti i processi , difatti se una “pipe” viene creata da un processo figlio il contenuto della stessa non e' visibile agli altri processi . Proprio per questo metaserver1 presentava un bug nel controllo delle stazioni. Il programma richiamava la stazione non connessa se la stazione era pronta creava le pipe per il trasferimento dati, poiche' il controllo veniva fatto da un processo figlio i dati contenuti nella pipe non erano visibili al processo che li inviava , di conseguenza il programma si bloccava irrimediabilmente.
Il controllo delle connessioni veniva fatto con un timer costante , ovvero ogni 30 secondi , si e' pensato quindi di implementare un controllo con timer scalabile .
Le connessioni erano di tipo bloccante , di conseguenza in caso di caduta della stazione il sistema rimaneva sospeso .
E' stata inoltre disabilitata l'opzione di scelta della stazione da parte dell'utente , ragionando in ottica futura si e' pensato di creare un vero server multiclient per dati rtcm , connesso ad una o piu' stazioni. Al momento dello sviluppo le stazioni rtcm disponibili erano 2 , una a Roma una in Texas e come e' noto una distanza cosi' grande fra le stazioni rende i dati totalmente scorrelati , questo perche' evidentemente le due stazioni vedono satelliti diversi ed hanno riferimenti temporali assolutamente non comparabili. Nella sezione di analisi e' stata verificata la correlazione fra le varie stazioni in funzione della distanza, sempre in ottica futura si e' cercato di capire quale possa essere la distanza limite fra le stazioni che permetta il mix di dati correttivi.
Capitolo 4
La stazione gnssip
4.1Analisi e reimpianto della stazione
Prima di tutto e' stato verificato il funzionamento della stazione chiamata “gnssip “, formata da un ricevitore satellitare Trimble 4000SSi e da un normale computer, collocata alle coordinate ECEF 4642432.57 1028629.39 4236854.23 . Il ricevitore presentava un setup diverso da quello normalmente richiesto a questo genere di stazioni,difatti la frequenza di emissione dei dati era di 9600 b/s , il computer presentava malfunzionamenti dovuti ad un attacco informatico. E' stato necessario il totale “spianamento software” della stazione . Dopo la reinstallazione del sistema operativo si e' proceduto alla configurazione con i seguenti passi:
Istallazione del programma client dgpsip-1.06 fornito da Wolfgang Rupprech
Configurazione del “superdaemon” Xinetd secondo i parametri della stazione
Configurazione del file /etc/services
Configurazione dei file “Host deny” “Host allow”
Configurazione delle regole del Firewall (/sysconfig/ipchains)
il superdemone Xinetd si occupa di monitorare le porte del sistema , di accettare o rifiutare un servizio che viene richiesto su una particolare porta , nel nostro caso abbiamo adottato la seguente configurazione:
service rtcm-sc104
{
disable = no
port = 2102
socket_type = stream
protocol = tcp
wait = no
user = root
server = /usr/local/sbin/dgpsipd
server_args = dgpsipd -s 9600
}
Il servizio e ' stato dunque redirezionato sulla porta 2102 con l'opzione -s 9600 , in questo modo e' stata possibile la sincronia di trama fra dati uscenti ed entranti , assolutamente mancante in precedenza con conseguenti missmatched in ricezione causati dalla differenza di velocita fra la stazione e la porta seriale.
 fAjTr{m_|gAF[\@aKzz`QM@LVCw_Sr~oT[h|grv@L|AHiF`R]bsO`{BPa]Pw[}[vOh@Up_A^WUUsYvVkLDbYDlgmeavg}rGB]q_NKhcquJx`mUDpAE^K@Fn}iW|ovHZ~d`G\w[YGP~`G_RtT^BGOMPcDlbnyCNs\zSOZeqrbYvTkv{]j{qomea]Xnott]Z{HrWpPsVHMXlmOvPOaWG}oLhHoPlRpg|Pxco`cY{uN[xtoDj`rZg@PcOoe^}@`lXPGqn_aa~YvVkLDb]DRYRZ^\XbKpJeXKHShc\iv@cEqO~WIlDycz_h@gxbYb|AiG|Z{p[KKvIx`bjHeu[Uso\xLAPnfqP@cA}dbFuxzYvTkSDbSDJQRZ^wgQPKn]ZSF{WpPsVHMLXKpYopXhxrAvWWPoTmOdNOxso`eY{ePHxtoDO_Mu[ho\pP^]_]V@Woxjn_nCvY~UkMDrjCDX~ydc^tEE_nLPsi|H`lMAPkdWCXMIsC~w@VE
fAjTr{m_|gAF[\@aKzz`QM@LVCw_Sr~oT[h|grv@L|AHiF`R]bsO`{BPa]Pw[}[vOh@Up_A^WUUsYvVkLDbYDlgmeavg}rGB]q_NKhcquJx`mUDpAE^K@Fn}iW|ovHZ~d`G\w[YGP~`G_RtT^BGOMPcDlbnyCNs\zSOZeqrbYvTkv{]j{qomea]Xnott]Z{HrWpPsVHMXlmOvPOaWG}oLhHoPlRpg|Pxco`cY{uN[xtoDj`rZg@PcOoe^}@`lXPGqn_aa~YvVkLDb]DRYRZ^\XbKpJeXKHShc\iv@cEqO~WIlDycz_h@gxbYb|AiG|Z{p[KKvIx`bjHeu[Uso\xLAPnfqP@cA}dbFuxzYvTkSDbSDJQRZ^wgQPKn]ZSF{WpPsVHMLXKpYopXhxrAvWWPoTmOdNOxso`eY{ePHxtoDO_Mu[ho\pP^]_]V@Woxjn_nCvY~UkMDrjCDX~ydc^tEE_nLPsi|H`lMAPkdWCXMIsC~w@VE
Figura 13:Allineamento dei dati
In figura 13 vediamo il completo allineamento dei dati grazie alle opzioni inserite nel file di configurazione di Xinetd.
Le configurazioni 2,3,4 sono state necessarie per la sicurezza della stazione , l'accesso alla stesso e' stato vietato a tutti gli utenti esclusi quelli che utilizzano particolari host.
A questo punto lo schema del sistema puo' essere rappresentato in figura 15

ricevitore rtcm

 dgpsipd-1.06
dgpsipd-1.06
![]()

 gnssip
gnssip
 rete Internet
rete Internet

utente singolo
figura 14:Schema della stazione
Analisi e verifica dei dati emessi dalla stazione
Una volta ottenuta la sincronia di trama sono stati analizzati i dati emessi dalla stazione. Per la verifica si e' scelto il programma standard dgpsip_1.32 in quanto metaserver1 presentava numerose limitazioni e bugs di cui ne si riporta la lista:
|
Processo Padre |
CTRL Connessioni |
Ricevi RTCM |
Invia RTCM |
|---|---|---|---|
|
Basato su soli strumenti IPC |
Controllo non scalabile di 30 “ |
Stazione che si riconnette: BLOCCO causato dal permesso di ricezione dato dal semaforo IPC su socket non leggibile dal processo |
Nei casi precedenti il processo di invio rimaneva sospeso. |
|
Eccessivo logging nel sistema |
Riconnessione:Il socket non era leggibile dal processo RICEVI RTCM:BLOCCO |
Stazione in reboot : Processo di ricezione sospeso , sistema BLOCCATO |
Mai verificata la ricezione dall' host “smile” con GPS portatile. |
|
|
|
La stazione riconnessa veniva riesclusa dal processo e di conseguenza ricontattata dal processo CTRL CONNESSIONI: BLOCCO |
|
Tabella 3:Bugs di Metaserver1
Il programma dgpsip-1.36 permette invece la corretta ricezione dei dati ed utilizzando sia la funzione di decodifica rtcm (rtcm.c) sia l'opzione “verbose” , e'stato possibile studiare i dati emessi da gnssip , si parlera' approfonditamente del decoder RTCM nell'opportuno capitolo.
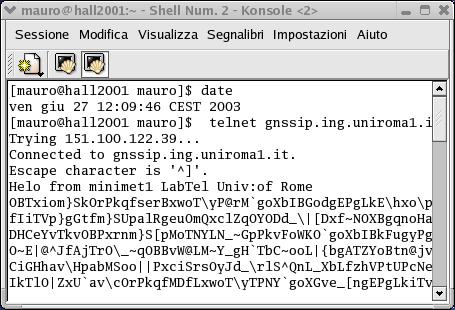
 [mauro@hall2001
dgpsip-1.32]$ ./dgpsip -h gnssip.ing.uniroma1.it -v 20 -w
[mauro@hall2001
dgpsip-1.32]$ ./dgpsip -h gnssip.ing.uniroma1.it -v 20 -w
dgpsip 1.32
Read 40 bytes
Read 32 bytes
Read 40 bytes
Read 32 bytes
Read 64 bytes
Read 32 bytes
Read 32 bytes
Read 32 bytes
Read 32 bytes
Read 32 bytes
Read 32 bytes
Read 64 bytes
Read 32 bytes
Read 4 bytes
Figura 15:numero di BYTE inviati da gnssip
Come si vede dalla figura 17 il numero di caratteri inviati e' molto basso , mediamente abbiamo gruppi di 32 byte. Considerando che i dati rtcm relativi alle correzione hanno frequenza media di 1 pacchetto al secondo ,possiamo subito concludere che abbiamo a che fare con una connessione a bassa frequenza e con dati rarefatti.
 M state
change: WORD_SYNCING -> WORD_SYNC
M state
change: WORD_SYNCING -> WORD_SYNC
M state change: WORD_SYNC -> FRAME_SYNCING
M state change: FRAME_SYNCING -> FULL_SYNC
H 18 330 2631.6 2 19 0
? 18
H 19 330 2631.6 3 19 0
? 19
H 18 330 2631.6 4 19 0
? 18
H 19 330 2631.6 5 19 0
? 19
H 1 330 2632.8 6 15 0
S 29 0 155 2632.8 -5.280 0.000
S 10 0 67 2632.8 -23.780 0.000
S 26 0 213 2632.8 -4.260 0.000
S 5 0 131 2632.8 -23.700 0.002
S 18 0 227 2632.8 -10.080 0.000
S 9 0 72 2632.8 -8.840 0.000
S 28 0 74 2632.8 -7.540 0.000
S 7 0 90 2632.8 -5.780 0.002
S 8 0 211 2632.8 -18.380 -0.002
H 18 330 2632.8 7 19 0
? 18
H 19 330 2632.8 0 19 0
? 19
H 18 330 2632.8 1 19 0
? 18
H 19 330 2632.8 2 19 0
? 19
H 1 330 2634.0 3 15 0
Figura 16 :Decodifica dei messaggi
Utilizzando invece l'opzione “-d” il dgpsip fornisce un output del tutto simile a quello di figura 18.Come verra' spiegato in dettaglio piu' avanti , dopo una fase iniziale di sincronizzazione , possibile solo grazie alle opzioni di configurazione discusse nel paragrafo 4.1 , il decoder fornisce in output (cosi come anticipato nel paragrafo 2.4) le seguenti informazioni:

|
type |
hdr |
station_ID |
mdf_zcnt |
seq_n# |
length |
healt |
useful |
|
|
|---|---|---|---|---|---|---|---|---|---|
|
1 |
H |
330 |
2632.08.00 |
6 |
15 |
optz |
optz |
|
|
Tabella 4:Message type 1 header H
in tabella 4 abbiamo un esempio di messaggio di tipo 1 ,il quale precede le informazioni di correzione ,.
|
header |
satellite |
udre |
Iod |
mdf_zcnt |
Range error |
Rate error |
|---|---|---|---|---|---|---|
|
S |
29 |
0 |
155 |
2632,8 |
-5,28 |
0 |
Tabella 5:Messagge type 1 header S
La tabella 5 invece e' un esempio di messaggio di correzione relativo ad un satellite , con i dati da esso forniti abbiamo le seguenti informazioni :
il satellite 29 deve essere corretto dal ricevitore con un valore in metri di 5.28 , la velocita di variazione di questa correzione e' pari a 0 , tale correzione e' valida per il riferimento temporale 2632,8 ovvero per il minuto 43-esimo dell'ora corrente al secondo 53-esimo e decimo 8 . Udre fornisce l'intervallo di errore differenziale -utente , in qualche modo ci indica la qualita' del servizio . IOD serve per il calcolo delle effemeridi del satellite e deve coincidere con quello ricavato dal ricevitore all'istante indicato dal mdf_zcnt .
E' evidente che la stazione emette altri messaggi oltre alle correzioni , dallo standard RTCM-SC-104 sappiamo che i messaggi di tipo 17-21 riguardano le informazioni di fase della correzione e sono utilizzati per la sorveglianza cinematica in tempo reale (Real Time Kinematic RTK). La stazione quindi emette gli standard RTCM +RTK , tuttavia la presenza delle informazioni di fase non pregiudica il corretto funzionamento , anche se come riportato in “RTCM Recommended Standards” il range di utilizzo delle correzioni potrebbe diminuire , normalmente esse possono essere considerate valide nel raggio di 200/400 dalla stazione con buoni risultati.
La connessione diretta con la stazione tramite il dgpsip-1.36 effettivamente permetteva la corretta ricezione dei dati da parte del GPS con conseguente miglioramento della misura di posizionamento.
Da questa analisi nasce il progetto Minimetas ma prima di tutto e' bene fare una panoramica sugli strumenti utilizzati nei seguenti sviluppi.
Capitolo 5
Approccio al progetto Minimetas
Protocolli e rete Internet
Le applicazioni Internet sfruttano il protocollo TCP/IP strutturato in quattro livelli:
|
Livello |
Nome |
Esempi |
|---|---|---|
|
Livello 4 |
Applicazione |
Telnet ,FTP |
|
Livello 3 |
Trasporto |
TCP, UDP |
|
Livello 2 |
Rete |
IP, (ICMP, IGMP) |
|
Livello 1 |
Collegamento |
device driver & scheda di interfaccia |
Tabella 6:Protocollo TCP
Applicazione :É relativo ai programmi di interfaccia con la rete, in genere questi vengono realizzati secondo il modello client-server , realizzando una comunicazione secondo un protocollo che è specifico di ciascuna applicazione.
Trasporto :Fornisce la comunicazione tra le due stazioni terminali su cui girano gli applicativi, regola il flusso delle informazioni, può fornire un trasporto affidabile, cioè con recupero degli errori o inaffidabile.
Rete :Si occupa dello smistamento dei singoli pacchetti su una rete complessa e interconnessa, a questo stesso livello operano i protocolli per il reperimento delle informazioni necessarie allo smistamento, per lo scambio di messaggi di controllo e per il monitoraggio della rete. Il protocollo su cui si basa questo livello è IP (sia nella attuale versione, IPv4, che nella nuova versione, IPv6).
Collegamento :Gestisce l'interfacciamento al dispositivo elettronico che effettua la comunicazione fisica, l'invio e la ricezione dei pacchetti da e verso l'hardware.
In figura 18 vediamo il flusso dei dati fra due stazioni remote
* Le singole applicazioni comunicano scambiandosi i dati ciascuna secondo un suo specifico formato. Per applicazioni generiche, come la posta o le pagine web, viene di solito definito ed implementato quello che viene chiamato un protocollo di applicazione (esempi possono essere HTTP, POP, SMTP, ecc.), ciascuno dei quali è descritto in un opportuno standard (di solito attraverso un RFC4).
* I dati delle applicazioni vengono inviati al livello di trasporto usando un'interfaccia opportuna . Qui verranno spezzati in pacchetti di dimensione opportuna e inseriti nel protocollo di trasporto, aggiungendo ad ogni pacchetto le informazioni necessarie per la sua gestione. Questo processo viene svolto direttamente nel kernel, ad esempio dallo stack TCP, nel caso il protocollo di trasporto usato sia questo.
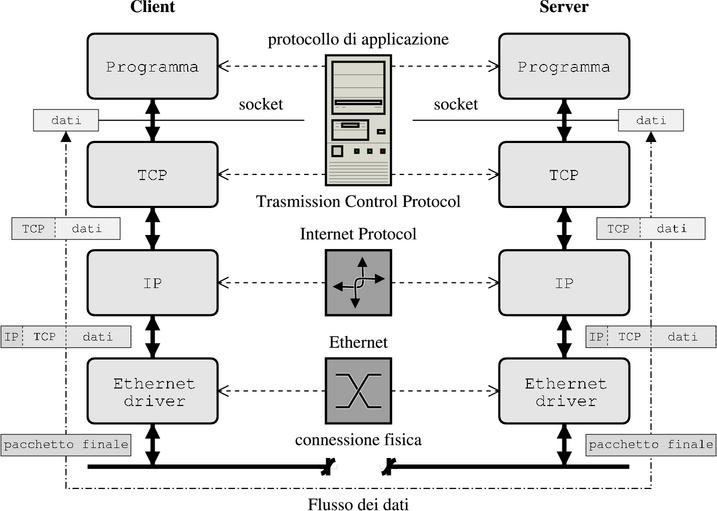
Figura17:Comunicazione client server
* Una volta composto il pacchetto nel formato adatto al protocollo di trasporto usato questo sarà passato al successivo livello, quello di rete, che si occupa di inserire le opportune informazioni per poter effettuare l'instradamento nella rete al recapito della destinazione finale. In genere questo è il livello di IP (Internet Protocol), a cui vengono inseriti i numeri IP che identificano i computer su Internet.
* L'ultimo passo è il trasferimento del pacchetto al driver della interfaccia di trasmissione, che si incarica di incapsularlo nel relativo protocollo di trasmissione. Questo può avvenire sia in maniera diretta, come nel caso di ethernet, in cui i pacchetti vengono inviati sulla linea attraverso le schede di rete, che in maniera indiretta con protocolli come PPP o SLIP, che vengono usati come interfaccia per far passare i dati su altri dispositivi di comunicazione (come la seriale o la parallela).
La filosofia architetturale del TCP/IP è semplice: costruire una rete che possa sopportare il carico in transito, ma permettere ai singoli nodi di scartare pacchetti se il carico è temporaneamente eccessivo, o se risultano errati o non recapitabili.
L'incarico di rendere il recapito pacchetti affidabile non spetta al livello di collegamento, ma ai livelli superiori. Pertanto il protocollo IP è per sua natura inaffidabile, in quanto non è assicurata né una percentuale di successo né un limite sui tempi di consegna dei pacchetti.
È il livello di trasporto che si deve occupare del controllo del flusso dei dati e del recupero degli errori; questo è realizzato dal protocollo TCP. La sede principale di intelligenza della rete è pertanto al livello di trasporto o ai livelli superiori.
Infine le singole stazioni collegate alla rete non fungono soltanto da punti terminali di comunicazione, ma possono anche assumere il ruolo di router (instradatori), per l'interscambio di pacchetti da una rete ad un'altra. Questo rende possibile la flessibilità della rete che è in grado di adattarsi ai mutamenti delle interconnessioni.
La caratteristica essenziale che rende tutto ciò possibile è la strutturazione a livelli tramite l'incapsulamento. Ogni pacchetto di dati viene incapsulato nel formato del livello successivo, fino al livello del collegamento fisico. In questo modo il pacchetto ricevuto ad un livello n dalla stazione di destinazione è esattamente lo stesso spedito dal livello n dalla sorgente. Questo rende facile progettare il software facendo riferimento unicamente a quanto necessario ad un singolo livello, con la confidenza che questo poi sarà trattato uniformemente da tutti i nodi della rete.
Internet Protocol nasce per disaccoppiare le applicazioni della struttura hardware delle reti di trasmissione, e creare una interfaccia di trasmissione dei dati indipendente dal sottostante substrato di rete, che può essere realizzato con le tecnologie più disparate (Ethernet, Token Ring, FDDI, etc.). Il compito di IP è pertanto quello di trasmettere i pacchetti da un computer all'altro della rete; le caratteristiche essenziali con cui questo viene realizzato in IPv4 sono due:
* Universal addressing la comunicazione avviene fra due stazioni remote identificate univocamente con un indirizzo a 32 bit che può appartenere ad una sola interfaccia di rete.
* Best effort viene assicurato il massimo impegno nella trasmissione, ma non c'è nessuna garanzia per i livelli superiori né sulla percentuale di successo né sul tempo di consegna dei pacchetti di dati.
I socket sono uno dei principali meccanismi di comunicazione utilizzato in ambito Unix fra i vari meccanismi di intercomunicazione fra processi. Un socket costituisce in sostanza un canale di comunicazione fra due processi su cui si possono leggere e scrivere dati in modo analogo a quello di una pipe ma, a differenza di questa e degli altri meccanismi IPC , i socket non sono limitati alla comunicazione fra processi che girano sulla stessa macchina, ma possono realizzare la comunicazione anche attraverso la rete.
Caratteristica fondamentale di TCP è l'affidabilità; quando i dati vengono inviati attraverso una connessione ne viene richiesto un "ricevuto" (il cosiddetto acknowlegment), se questo non arriva essi verranno ritrasmessi per un determinato numero di tentativi, intervallati da un periodo di tempo crescente, fino a che sarà considerata fallita o caduta la connessione (e sarà generato un errore di timeout); il periodo di tempo dipende dall'implementazione e può variare far i quattro e i dieci minuti.
Inoltre, per tenere conto delle diverse condizioni in cui può trovarsi la linea di comunicazione, TCP comprende anche un algoritmo di calcolo dinamico del tempo di andata e ritorno dei pacchetti fra un client e un server (il cosiddetto RTT, round-trip time), che lo rende in grado di adattarsi alle condizioni della rete per non generare inutili ritrasmissioni o cadere facilmente in timeout.
Inoltre TCP è in grado di preservare l'ordine dei dati assegnando un numero di sequenza ad ogni byte che trasmette. Ad esempio se un'applicazione scrive 3000 byte su un socket TCP, questi potranno essere spezzati dal protocollo in due segmenti (le unità di dati passate da TCP a IP vengono chiamate segment) di 1500 byte, di cui il primo conterrà il numero di sequenza 1 - 1500 e il secondo il numero 1501 - 3000. In questo modo anche se i segmenti arrivano a destinazione in un ordine diverso, o se alcuni arrivano più volte a causa di ritrasmissioni dovute alla perdita degli acknowlegment, all'arrivo sarà comunque possibile riordinare i dati e scartare i duplicati.
Il protocollo provvede anche un controllo di flusso (flow control), cioè specifica sempre all'altro capo della trasmissione quanti dati può ricevere tramite una advertised window, che indica lo spazio disponibile nel buffer di ricezione, cosicché nella trasmissione non vengano inviati più dati di quelli che possono essere ricevuti.
Questa finestra cambia dinamicamente diminuendo con la ricezione dei dati dal socket ed aumentando con la lettura di quest'ultimo da parte dell'applicazione, se diventa nulla il buffer di ricezione è pieno e non verranno accettati altri dati.
Infine attraverso TCP la trasmissione è sempre bidirezionale (fulll-duplex). È cioè possibile sia trasmettere che ricevere allo stesso tempo, il che comporta che quanto dicevamo a proposito del controllo di flusso e della gestione della sequenzialità dei dati viene effettuato per entrambe le direzioni di comunicazione.
Il processo che porta a creare una connessione TCP è chiamato three way handshake; la successione tipica degli eventi (e dei segmenti di dati che vengono scambiati) che porta alla creazione di una connessione è la seguente:
Il server deve essere preparato per accettare le connessioni in arrivo; il procedimento si chiama apertura passiva del socket . Questo viene fatto chiamando la sequenza di funzioni socket, bind e listen. Completata l'apertura passiva il server chiama la funzione accept e il processo si blocca in attesa di connessioni.
Il client richiede l'inizio della connessione usando la funzione connect, attraverso un procedimento che viene chiamato apertura attiva, dall'inglese active open. La chiamata di connect blocca il processo e causa l'invio da parte del client di un segmento SYN, in sostanza viene inviato al server un pacchetto IP che contiene solo gli header IP e TCP (con il numero di sequenza iniziale e il flag SYN) e le opzioni di TCP.
Il server deve dare l'acknowledge del SYN al client, inoltre anche il server deve inviare il suo SYN al client (e trasmettere il suo numero di sequenza iniziale) questo viene fatto ritrasmettendo un singolo segmento in cui sono impostati entrambi i flag SYN ACK.
Una volta che il client ha ricevuto l'acknowledge dal server la funzione connect ritorna, l'ultimo passo è dare il ricevuto del SYN del server inviando un ACK. Alla ricezione di quest'ultimo la funzione accept del server ritorna e la connessione è stabilita.
Il procedimento viene chiamato three way handshake dato che per realizzarlo devono essere scambiati tre segmenti. In fig.19 è rappresentata graficamente la sequenza di scambio dei segmenti che stabilisce la connessione.


Client TCP TCP SERVER
 socket
closed closed socked
socket
closed closed socked
 (blocks)
connect------------> bind
(blocks)
connect------------> bind
active open listen
syn_ sent passive open
syn j accept (blocks)
listen
syn k,ack j+k syn_recvd

connect <---------established
ack k+1
established---->accept
Figura 18:three way handshacking
Quando un client contatta un server deve poter identificare con quale dei vari possibili servizi attivi intende parlare. TCP definisce un gruppo di porte conosciute (le cosiddette well-known port) che identificano una serie di servizi noti (ad esempio la porta 22 identifica il servizio ssh) effettuati da appositi server che rispondono alle connessioni verso tali porte.
La lista delle porte conosciute è definita dall'RFC 1700 che contiene l'elenco delle porte assegnate dalla IANA (la Internet Assigned Number Authority),nel caso del servizio RTCM-SC104 e' stata assegnata la porta 2101.
I/O Multiplexing
Qualunque connessione ad un socket puo' bloccarsi indefinitamente a causa dell'assenza di dati disponibili sul descrittore su cui si opera. Se la connessione e' contenuta in un programma chiaramente l'intera esecuzione rimane sospesa indefinitamente , per risolvere questo problema e' possibile utilizzare il forking, come visto nel capitolo 3 , oppure le modalita' non bloccanti , in questo secondo caso siamo in grado di contattare una lista di socket e di leggere i dati prelevandoli solo da quelli pronti. Questa tecnica (polling) e' sicuramente di facile implementazione ma risulta gravemente inefficiente poiche' si tiene impegnata la cpu del sistema in modo continuato con forte consumo di risorse , un rapido test ha dimostrato che in caso di servizi trasmissione dati a bassa frequenza (come appunto il servizio RTCM-SC104) un solo processo occupa fra il 50-70 % di cpu di un moderno calcolatore con clock superiore al MHZ.
La soluzione a tale problema e' l'utilizzo della funzione select , la quale e' in grado di controllare un set di file descriptor e di sospendere il processo finche' uno di essi non abbia dati pronti o finche' non viene raggiunto il tempo limite di attesa. L'utilizzo della select presuppone la manipolazione dei file descriptor con le seguenti funzioni:
|
FD_ZERO(fd_set*set) |
FD_SET(int fd,fd_set*set) |
FD_CLR(int fd, fd_set*set) |
FD_ISSET(int fd,fd_set*set) |
|---|---|---|---|
|
Inizializza l'insieme |
Inserisce il file descriptor nell'insieme |
Rimuove il file descriptor dall'insieme |
Controlla se il file descriptor e' nell 'insieme |
Tabella 7:Manipolazione file descriptor
La select ha invece questa forma
int select(int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout);
*readfds: rappresenta il gruppo di descrittori per la lettura dati
*writefds: rappresenta il gruppo di descrittori per la scrittura dei dati
*exceptfds: rappresenta un gruppo di descrittori dati particolari
*timeout:definisce il tempo di attesa sul socket , notare che “0” corrisponde ad un tempo infinito.
Queste sono le conoscenze minime per iniziare lo sviluppo del nostro server RTCM.
Capitolo 6
Il Progetto Minimetas
Gnssip multiclient
Vista la funzionalita' della stazione il , target successivo e' stato di ampliare il numero di possibili utenti , ovvero di passare alla modalita' multiclient , allo stesso tempo si doveva garantire la massima robustezza , la massima efficienza e semplicita' di struttura.
Vista la lunghezza media dei messaggi si e' pensato ad un tipo di trasmissione sequenziale con conseguente abolizione di tutti i processi “figlio” e degli strumenti IPC. La struttura scelta e' rappresentata in figura 21

 ricevitore
rtcm
ricevitore
rtcm

 dgpsip-1.06
gnssip:2102
dgpsip-1.06
gnssip:2102
![]()



 utente
socket
utente
socket




 utente INTERNET socket
Minimetas:2101
utente INTERNET socket
Minimetas:2101


 .
.
.
.
. .
 .
.
.
.
utente
socket
Figura 19:Schema di Minimetas
Per il codice completo si veda l'appendice A, riporto di seguito il flow-chart del programma e la spiegazione di tutte le funzioni implementate.

Sezione #include
Sezione #define


creazione struttura client
elenco funzioni interne


creazione della funzione demonize




definizione variabili interne
creazione socket crea_socket ()
connessione al ricevitore RTCM

creazione dei socket di ascolto
demonizazione
daemonize()
ciclo
 lettura dati
lettura dati
verifica di connessione entrante


 richiesta di connessione
NO
richiesta di connessione
NO
SI

verifica numero utenti


 NO socket disponibile
NO socket disponibile

send_gbye()
SI

setto flag modalita' NON BLOCK
apro il socket in lettura e scrittura
salvo i socket nell'array


invio saluto
send_hello()

ciclo
invio dati
 send_data()
send_data()

 SI
SI


 connessione j-esima chiusa
connessione j-esima chiusa
 eliminazione
socket j-esimo
eliminazione
socket j-esimo
NO


SI NO

 FINE CICLO DI INVIO
FINE CICLO DI INVIO


END
Figura 20:flow-chart di Minimetas
Analisi delle funzioni di Minimetas
La struttura client_type
typedef struct client_type {
int sock; /*client socket */
FILE *fw; /*to write*/
FILE *fr; /*to read client*/
} client_type;
struct client_type client[CLT_NMB];
Ad ogni nuova connessione viene definito un file descriptor per il socket e due FILE uno per la scrittura uno per la lettura, questa struttura viene ripetuta secondo il numero massimo di connessioni accettate pari a 64 e quindi abbiamo un array strutturato con 64 elementi di tipo “struct”.
Le funzioni openlog,syslog,setlogmask
openlog ("Minimetas", LOG_PID, LOG_DAEMON);
setlogmask (LOG_UPTO (LOG_INFO));
syslog (LOG_INFO, "Starting version: %s %s\n", PACKAGE, VERSION);
Openlog comunica al sistema che i messaggi relativi al programma devono essere inclusi nel file di log (in genere messages.log contenuto in /var/log/), ogni messaggio deve essere corredato di PID , minimetas grazie a LOG_DAEMON e' considerato come un programma qualunque senza opzioni speciali. Viceversa in un primo tempo e' stato necessario modificare il file di logging di metaserver1 perche' il programma a causa del timer non scalabile ripeteva la connessione ad una stazione non esistente generando un errore che veniva ovviamente riportato nel file di log. Questo problema e' stato risolto utilizzando LOGROTATE ed aggiungendo alcune righe nel file syslog.conf (contenuto in /etc) che riporto di seguito:
local0.info /var/log/metaserver.log
local0.err /var/log/messages
La prima riga redirige i messaggi che hanno un livello informativo nel file metaserver.log , la seconda redirige i messaggi di livello piu' alto (livello “errore”) nel file message.log. L'opzione LOG_DAEMON e' stata cambiata in LOG_LOCAL0. Per poter controllare la dimensione dei file di log e' stata modificata la directory logrotate.d inserendo un file relativo a metaserver1, anche questo viene riportato di seguito:
/var/log/metaser.log {
compress
sharedscripts
postrotate
/bin/kill -HUP cat /vart/run/syslogd.pid 2> /dev/null || true
endscript
}
Il file metaserver.log viene ruotato e compresso secondo le opzioni contenute nel file syslog.conf.
Setlogmask comunica al sistema il livello di logging , in particolare vengono loggati tutti i messaggi a partire dal livello informativo.
Syslog comunica al sistema che deve essere loggato l'avvio del programma corredato di numero di versione.
La funzione crea_socket ();
sfd=crea_socket ();
Vengono utilizzati i classici strumenti di Network Programming:
s = socket (PF_INET, SOCK_STREAM, 0):viene creato un socket , specificando il protocollo internet Ipv4 con connessione a due vie basata su stream di byte.
memset (&laddr, 0, sizeof (laddr)):inserisce in memoria la lunghezza massima dell'indirizzo “laddr” , ritorna un puntatore a questa zona di memoria.
bind (s, (struct sockaddr *) &laddr, sizeof (laddr)):lega il socket creato ad una porta.
listen (s, 5) ::pone il sistema in ascolto di connessioni entranti sul socket creato .
flags=fcntl(s,F_GETFL,0)) , flags |= O_NONBLOCK: questa e' la funzione che permette la modalita' non bloccante ,i dati sono inviati continuamente senza alcuna attesa o pausa .
La Funzione daemonize
daemonize()
Permette di demonizzare il programma ovvero di portare in background l'esecuzione. Questa semplice funzione e' stata importata nel codice sfruttando la licenza “Open Source” , fa parte del codice “gpsd-1.07”,scritto da Remco Treffkorn ,
praticamente si tratta di un fork che chiude il processo Padre ed affida al figlio tutto il programma come se fosse lui stesso il padre , questo permette all'utente di tornare al prompt dei comandi mentre il programma continua a girare , l'utilita' maggiore di questa funzione sta' nel fatto che il server puo' essere lanciato da remoto , e' possibile quindi lavorarci per il mantenimento senza muovere un passo .
La funzione accept()
accept (sfd, (struct sockaddr *) &raddr, &raddrlen):
Ovviamente si preoccupa di accettare le connessioni entranti sul socket creato, restituisce un intero che viene poi utilizzato come file descriptor per l'invio dei dati.
La Funzione connessione
connessione (0, MaxConn1);
Questa funzione deriva da metaserver1 ed e' stata rivista ed adattata a metaserver2 , in ottica futura avendo a disposizione un certo numero di stazioni bisogna specificare quale stazione chiamare con un intero e quanti tentativi di connessione bisogna fare .
La funzione apriconnessione
apriconnessione (u_char * hostsr, u_char * portasr, u_int af_family);
Questa e' la funzione che si occupa di stabilire una connessione con il ricevitore ,sostanzialmente e' come se gnssip dovesse chiamare una stazione remota , con la differenza che la stazione e' lui stesso , per questo , come si vede in figura 21 e' stata necessaria la redirezione dei servizi su porte diverse da quelle standard. In questo caso abbiamo la seguente chiamata:
apriconnessione ("127.0.0.1","rtcm-sc104",af_family);
come si vede l'host a cui connettersi e' quello ospitante , la porta e' quella del servizio dgpsipd , il protocollo da utilizzare e' definito dalla famiglia “af_family”. Gli altri strumenti di networking utilizzati sono elencati di seguito:
gethostbyaddr:prende l'indirizzo IP dell host
gethostbyname:prende il nome dell'host
getservbyname :prende il nome del server
connect:connessione al server
evidentemente in questo caso e' del tutto inutile aggiungere opzioni non bloccanti , il server ed il dgpsipd girano contemporaneamente sulla stessa macchina quindi non abbiamo bisogno di verifiche ulteriori della stazione .
La funzione accept
accept (sfd, (struct sockaddr *) &raddr, &raddrlen);
Si occupa di accettare le connessioni entranti sul socket creato per la distribuzione dei dati.
la funzione fcntl
fcntl(client[i].sock,F_SETFL,flags)
Permette di cambiare le opzioni su un qualunque descrittore , poiche' il socket creato e' di tipo non bloccante possiamo controllare con la accept le connessioni entranti senza sospendere l'esecuzione del programma,una volta accettata la connessione sempre con la fcntl settiamo il descrittore restituito dalla accept come non bloccante e questo per tutti le connessioni, in modo da poter trasmettere i dati sequenzialmente . Notare tuttavia che le opzioni non bloccanti sono relative ai socket in scrittura questo non aumenta il polling e di conseguenza il consumo di risorse macchina.
La funzione send_gbye
send_gbye(s2)
Dopo aver accettato la connessione viene controllato il numero di utenti totali, se non ci sono socket liberi il nuovo utente viene semplicemente salutato con una stringa che lo avverte di rimanere in attesa fino a che non si sia liberato un socket. La connessione non viene chiusa per evitare che il client richieda nuovamente la connessione subito dopo, con il rischio di mettere in crisi il sistema , il limite dell'attesa da parte del client e' definito dal timeout standard sui socket.
La funzione send_hello
send_hello(s2)
Se ci sono posti disponibili il client viene accettato , si richiede una stringa di riconoscimento , e si memorizza il tipo di client , l'host di partenza , e la data corrente sul file minimetas.log (contenuto in /var/log) .
La funzione send_data
send_data (client[i].sock,mess,cnt_r,client[i].fw,client[i].fr).
Ovviamente e' la funzione che si occupa dell'invio dei dati ,dopo un ulteriore controllo sulla connessione chiama la funzione inviortcm. Inoltre e' in grado di leggere il socket quindi se il client manda dei dati al server questi e' in grado di salvarli , in particolare ,sempre in ottica futura , ho pensato di ricavare la posizione utente in modo che il futuro encoder rtcm possa sfruttarla per la codifica ottimale, quindi Minimetas e' in grado di leggere la posizione del client se questo la invia . Ovviamente questa opzione e' stata un forte stimolo alla generazione di un codice client “ad hoc”!!!.
La funzione inviortcm
inviortcm (f1, buf_i,correzione , f2,length);
si occupa semplicemente di contare il numero di caratteri da inviare e di chiamare la funzione writeinvio
La funzione writeinvio
writeinvio (FILE * fd, u_char * buf_i, int cnt_i, FILE * f2)
Particolare attenzione e' stata data a questa funzione , in quanto vista la modalita non bloccante e' stato necessario sbloccare i file di scrittura e lettura del socket utilizzando
getc_unlocked(FILE).
I test su Mimimetas
Il sever e' stato testato per 6 mesi simulando tutte le condizioni possibili, durante questo periodo solo 4 volte e' stato trovato fermo ,due volte a causa di malfunzionamenti della rete Universitaria e altre due a causa della poca attenzione sugli altrui strumenti da parte di un “non so' chi” , in pratica hanno spento la macchina.
Mimimetas versione2 e' distribuito in pacchetto tar.gz ed e' liberamente scaricabile dal portale labtel e dal mio sito http://members.xoom.virgilio.it/maurovenanzi .

Figura
21:Ricezione multipla da gnnsip
Integrazione con il Progetto EUREF-IP
Durante lo sviluppo di Minimetas ho fatto una affannosa ricerca quotidiana su internet nella speranza di trovare una seconda stazione rtcm che ci permettesse di fare un confronto tra dati differenziali , dopo alcuni mesi finalmente ho trovato non una ma una serie di stazioni controllate dai gestori del progetto EUREF. I target di questo progetto sono molteplici , uno dei primi e' la collocazione di un server centrale in grado di acquisire dati da diverse stazioni , distribuire in tutta europa questi dati e creare un protocollo per la loro trasmissione con telefonia mobile , ad ogni utente e' fornito un client , al momento del contatto esisteva solo il client windows. Poiche' i test su minimets hanno dato fin da subito un risultato piu' che soddisfacente ho proposto alla societa' tedesca che gestisce il progetto EUREF uno scambio di dati rtcm , soddisfatti del comportamento del nostro server hanno reso disponibili le loro stazioni e come si puo' vedere in figura 23 ......Minimetas ha trovato compagnia.
Figura 22:Rete gps/rtcm EUREF
Mediamente abbiamo avuto la disponibilita' di almeno altre 25 stazioni ben funzionanti. Minimetas e' stato dunque aggiunto alla rete europea di distribuzione di dati rtcm ed e' quotidianamente in contatto con il server EUREF collocato a Francoforte.
A questo punto del progetto sembrava decisamente necessaria la creazione di un nostro client , ovvero di un programma che potesse ricevere i dati rtcm ed allo stesso tempo mandare la posizione utente al server , che fosse in grado di elaborare i dati gps e che desse la possibilita' all'utente di verificare il funzionamento del ricevitore in dgps-mode. Nasce da queste considerazioni il progetto dgpsnavigator totalmente creato da me.
Capitolo 7
Il progetto dgpsnavigator
Principi base del progetto
Nella mia idea il dgpsnavigator non doveva essere un semplice programma ma piuttosto una vera interfaccia fra due sistemi remoti. Da una parte abbiamo il ricevitore GPS con i dati in un certo formato , dall'altra abbiamo il server rtcm .Il programma doveva permettere all'utente di visualizzare i dati emessi dal GPS , almeno i fondamentali , doveva inviarne una parte al server , il tutto utilizzando una sola porta seriale e se possibile mantenendo la compatibilita' con altri programmi che necessitano del ricevitore GPS come ad esempio il gpsdrive ,utilissimo se si vuole anche il mapping cartografico della zona in cui ci si trova. Per ovvi motivi il punto di partenza del progetto e' stato il dgpsip-1.36 e il primo passo di sviluppo e' stata la creazione di una interfaccia grafica in modo che i dati non scorrano a schermo in modo confuso ma siano ben visibili all'utente nell'interfaccia stessa.




ricevitore GPS ![]()

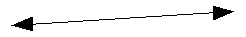
![]()
client stazione
rtcm
DATI GPS interfaccia grafica Figura 23:Schema base di dgpsnavigator
Le librerie ed i tools di sviluppo GTK+
GTK+ e' una piattaforma completa di sviluppo per le interfacce grafiche adatta al piccolo ed al grande programma , compatibile con diverse tipologie di macchina e facente parte del progetto GNU-Linux. Tale piattaforma e' sviluppata da un team di programmatori. Le librerie GTK sono racchiuse in un gruppo denominato Glib e fornito assieme ai programmi Gnome , esse permettono la totale compatibilita' con le librerie e le funzioni classiche del C ,in sostanza un programma GTK e' scritto in C , ma il programmatore ha a disposizione piu' strumenti. Gli header GTK+ vanno ovviamente inclusi all'inizio di ogni programma con le seguenti istruzioni
#include <gdk/gdkkeysyms.h>
#include <gtk/gtk.h>
a questo puno il programmatore puo' sviluppare il progetto normalmente oppure includendo particolari funzioni come le “GTK_timeout_add” che permettono di inserire un ciclo periodico da eseguire secondo un certo intervallo temporale. I principali tool che sfruttano le librerie GTK sono “Glade Interface Desiner” ed Anjuta , per le maggiori possibilita' offerte ho deciso di utilizzare il secondo, che sostanzialmente incorpora anche il Glade.
Scelta dei dati GPS
Prima di procedere alla costruzione dell'interfaccia dovevo decidere quali e quanti dati estrapolare dal gps . Come abbiamo visto nel paragrafo 2.3 le stringhe NMEA ci permettono di avere a disposizione una grande quantita' di dati , la scelta e' caduta sui seguenti :
latitudine
longitudine
altitudine
velocita'
time e data
precisione orizzontale
precisione verticale
numero di satelliti e satelliti tracciati
Tutti i parametri dovevano essere inseriti in opportuni widgets gtk . Il programma inoltre doveva dare l'opportunita' all'utente di scegliere quando connettersi al server per ricevere i dati rtcm , l'utente doveva avere la possibilita' di scegliere tale server e poteva decidere se connettersi al gps oppure no. Il programma doveva fornire informazioni sullo stato delle connessioni sia lato GPS sia lato server e nel caso di ricevitori con piu' porte di ingresso/uscita doveva permettere la ricezione su una seconda porta. Per la condivisione dei dati GPS con altri programmi si e' scelto di utilizzare il gpsd con una chiamata system , quindi il programma non e' stato incluso ma come spiegato nel Readme si suppone che l'utente provveda alla sua installazione. E' possibile scegliere se utilizzare la ricezione seriale o leggere i dati dal socket creato dal gpsd ovvero sulla porta 2947 della macchina locale . Un mini help completa la lista delle funzionalita' comprese.
Il risultato e' visibile in figura 25:
Il codice completo viene riportato in appendice B, proseguiamo invece con la spiegazione di tutte le funzioni implementate e l'associazione di queste con i vari pulsanti.
Figura
24:l'interfaccia di gpsnavigator
La struttura del dgpsnavigator

sezione include
sezione define
lista funzioni interne
lista variabili globali

costruzione interfaccia grafica
associazione destroy/finestra
associazione pulsanti/funzioni
funzione/tasto exit
funzione/tasto help
funzione/tasto gpsd
funzione/tasto port2
funzione/tasto gps
funzione/tasto dgps
end gtk_main()
Figura 25:Schema base del dgpsnavigator
Come si vede i programmi GTK+ non hanno un vero diagramma di flusso poiche' le varie funzioni vengono attivate dai pulsanti a cui sono associate ,vediamo quindi le singole funzioni contenute nel programma
Le funzioni del dgpsnavigator
Funzione/tasto exit
Il tasto exit avvia la funzione destroy , che stampa un messaggio infomativo in shell (se il programma non viene lanciato con doppio click sul Desktop) e chiude il motore Gtk. La stessa funzione e' associata al gestore della finestra ,ovvero chiudendo il programma cliccando sulla “x” della finestra viene avviata la funzione destroy che termina l'esecuzione.
Funzione/tasto help
Viene avviata la funzione help che genera una nuova finestra dove sono contenuti messaggi informativi sul programma .
Funzione/tasto port2
Permette all'utente di ricevere i dati del gps sulla seconda porta seriale , alcuni ricevitori infatti hanno porte separate per la ricezione e trasmissione dei dati .
Funzione/tasto gpsd
Chiama la funzione set_gpsd
Permette all'utente di ricevere i dati dalla porta locale numero 2947, questo tasto quindi genera una connessione a questa porta sull'host locale , come detto precedentemente non e' stato inserito direttamente il codice gpsd nel programma , ma viene chiamato con l'istruzione system.
Funzione/tasto dgps
Chiama la funzione dgps_data ,vengono verificate le stringhe in corrispondenza della latitudine e dell'altitudine , e confrontate con gli indirizzi di default , se l'utente prima di connettersi al gps ha cambiato queste stringhe il programma si connette agli indirizzi indicati dall'utente, altrimenti si creano delle connessioni agli indirizzi di default . Viene aperta la porta seriale in sola scrittura , viene effettuata la connessione al server , viene disabilitato il tasto dgps per evitare connessioni multiple , viene generata una funzione periodica di lettura dati correttivi (dgps_cbk)
Funzione/tasto gps
Avvia la funzione gps_data che apre la porta seriale scelta dall'utente e genera la funzione periodica per la lettura dei dati nmea (parse_cbk) , viene disabilitato il pulsante di connessione al gps per evitare connessioni multiple.
Funzione parse_cbk
volge il parsing nmea leggendo i dati secondo la modalita' scelta dall'utente , viene quindi controllato lo stato del gpsd , in caso di attivita viene controllato il socket con una istruzione select , altrimenti i dati vengono prelevati direttamente dalla seriale. La lettura dati dalla seriale risulta molto meno precisa di quella effettuta dal socket.
Viene controllata la lunghezza della stringa e lo stato del gps , nel caso in cui non si ricevono dati validi per un certo tempo viene stampato il messaggio “GPS OFF” sulla statusbar principale, altrimenti viene copiata la stringa letta e comparate con quelle scelte per il parsing che elenco di seguito:
$GPRMC,011243,A,3743.000,N,12214.000,W,000.0,267.6,310796,,*03
RMC - Recommended minimum specific GPS/Transit data
$GPGSV,3,1,09,01,70,041,49,03,17,209,46,09,01,031,00,14,05,281,34*76
GSV - Satellites in view
$GPGGA,011243,3743.000,N,12214.000,W,2,07,0.4,2.8,M,-27.9,M,0,0269*45
GGA - Global Positioning System Fix Data
$PGRME,5.9,M,10.1,M,11.7,M*25
In particolare l'ultima stringa ci permette di ricavare la precisione della misura e quindi di valutare il miglioramento ottenuto con le correzioni differenziali.
Le funzioni src_nsat,src_higth, src_prc, src_pos, servono per ricavare rispettivamente il numero di satellti in vista e il numero di satelliti tracciati , l'altitudine , la precisione e la posizione . In caso di perdita di segnale viene stampato un messaggio sulla statusbar principale.
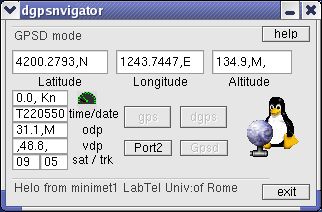

Figura 26:Il dgpsnavigator in funzione
Come si vede dal riferimento temporale dopo pochi minuti di connessione al server rtcm si ottengono circa 26 metri di precisione orizzontale e quasi 40 in verticale. Alcune volte ,quando le condizioni atmosferiche e la visibilita' satellitare lo permettono si ottiene un errore di misura di 1.2-1.7 metri in orizzontale.
Vediamo inoltre la modalita' gpsd e dgps , a sinistra vediamo la velocita' espressa in nodi , il numero di satelliti in vista e quelli utilizzati per il tracciamento pari a 5/4 . L 'orario e la data sono visualizzati alternativamente .
Questo programma e' totalmente compatibile con altre applicazioni che richiedono l'utilizzo condiviso del ricevitore GPS ,e' possibile ad esempio ricevere le correzioni differenziali e graficare mappe topografiche.
Capitolo 8
Il Decoder RTCM
KDevelop ed il debug passo-passo
Questa parte riguarda l'analisi fatta sui dati correttivi ed in ottica futura potrebbe consentire la miscelazione dei dati rtcm.
Tale analisi e' basata sul codice rtcm.c di cui ho gia' descritto alcune caratteristiche , approfondiamo ora la sua conoscenza con lo studio delle sue funzioni. A questo scopo e' stato utilizzato un apposito tool di sviluppo software , KDevelop ,fornito con la maggior parte delle distribuzioni Linux. In particolare e' stato sfruttata la capacita di debug passo-passo ,ovvero di eseguire un certo programma per singole istruzione e di controllare il contenuto delle variabili. Poiche' il codice rtcm.c implementa una macchina a stati l'utilizzo di KDevelop ha dato grandi risultati e byte per byte si e' potuto seguire l'evoluzione della macchina.
Per effettuare il debugging e' sufficiente includere il codice all'interno di un progetto avendo cura di generare anche un file per gli header che contenga la lista delle funzioni svolte dal codice incluso. Le variabili da controllare possono essere inserite in un opportuno elenco dove viene visualizzato il loro valore ad ogni passo di debug effettuato. Nel caso in cui il programma effettui un forking il debugger segue il processo padre nel quale devono essere contenute le variabili da controllare.
Il debug passo passo e' stato anche fondamentale per lo sviluppo di metaserver2 che rappresenta una evoluzione non operativa di metaserver1 di cui si discutera' piu' avanti.
Il codice rtcm.c
Il codice e' stato scritto da John Sager nel 1999 , nella prima versione permetteva la decodifica dei messaggi di tipo 1,3,6,7,9,16 , successivamente anche dei messaggi 4 , 5, effettua una discriminazione dei dati entranti grazie al fatto che tutti quelli rtcm sono del tipo 01xxxxxx , ovvero iniziano tutti con i bit “01”. Prendiamo in considerazione le seguente mini stringa rtcm:
 Y~]QVh'm
Y~]QVh'm
01011001 0111110 01011101 0101001 01010110 01101000 01100000 01101101
possiamo vederne la codifica binaria sulla riga precedente , ogni carattere corrisponde come e' noto ad un byte i cui primi due bit sono sempre “01”.Nel caso in cui il byte non sia un dato rtcm il programma stampa il messaggio “unknown byte type”, viceversa viene chiamata la funzione data_byte().
Altra caratteristica dei dati rtcm e' quella di avere un ordine binario invertito e quindi viene chiamata la funzione reverse_bit() ad esempio il byte Y a cui corrisponde la stringa binaria 01011001 viene messo in maschera con 0x3f (ovvero con 00111111), questo consente di estrapolare gli ultimi sei bit che vengono poi invertiti , quindi abbiamo i seguenti passi:
Y=01011001--->00011001---->intero=25---->inversione=38-->00100110
Per ogni byte ricevuto ed invertito viene controllato lo stato della macchina , il primo switch si ha quando viene acquisito con successo numero sufficiente di caratteri ed e' possibile cercare il flag iniziale della trama.
Quindi il primo stato della macchina (NO_SYNC) viene cambiato in “WORD_SYNCING” se la funzione find_sync() ritorna un valore positivo. La funzione find_sync(), viene chiamata da data_byte() ed effettua lo lo shift a sinistra del dato , controlla che non ci siano errori di parita' ovvero chiama la funzione parity_ok per il dato shiftato . Una volta acquisito un certo numero di byte senza errori di parita' allora lo stato della macchina viene cambiato. A questo punto bisogna valutare se i dati acquisiti formano una word completa di 30 bit (rispetto ai 32 standard) altrimenti si riempie la word con altri byte. Dopo aver acquisito un numero sufficiente di word lo stato interno cambia ancora in FRAME_SYNCING , a questo punto viene cercato l'inizio di trama. Ogni trama RTCM inizia con il seguente flag binario 01100110 (preamble) che in esadecimale corrisponde a 0x66 per trovarlo vengono messi in maschera i bit di trama via via shiftati a sinistra con 0x19800000 che corrisponde in binario a 000110011000000..........0 ,(32 bit) escludendo come sempre i primi due bit (word di 30 bit)i primi otto bit formano esattamente il preambolo .
A questo punto la funzione new frame analizza la trama a disposizione denominata “message”. In realta' message e' un vettore di interi ogni intero rappresenta una word.
Lo shift del primo elemento di 16 posizioni a destra in maschera con 0x3f ritorna i bit che definiscono il MESSAGE_TYPE , difatti sappiamo che sono possibili 64 diversi messaggi rtcm e quindi abbiamo 6 bit , se a questi aggiungiamo gli 8 bit di preambolo abbiamo 6+8 +16 (shift) =30 bit ovvero la word di correzione.
Lo shift del primo elemento di sei posizione a destra in maschera con 0x3ff ritorna lo STATION_ID.
Operazioni simili sul secondo elemento (seconda word) ritornano il MDF_ZCNT,e lo STATION_HEALT. Questi parametri sono i primi che vengono stampati a schermo , e coincidono con quelli descritti nella sezione 2.4.
A questo punto vengono esaminati i messaggi secondo il tipo. Per quelli di correzione possiamo avere il tipo 1 o il tipo 9. In questo secondo caso abbiamo il messaggio di correzione parziale , entrambe vengono decodificati dalla funzione printcor().
Come e' noto il numero delle word non e' definito a priori ma varia di volta in volta , quindi ' la funzione printcor scandisce l'intera trama (al massimo sono consentite 33 data word) ed analizza ogni word secondo il suo numero di ordine. Ad esempio la word numero 3 contiene informazioni sul fattore di scala (primo bit) , UDRE, numero di satellite ,pseudorange di correzione , piu' i bit di parita'. Per ottenere i singoli elementi e' sufficiente shiftare la word del numero di posizioni necessarie e mettere i bit rimanenti in AND con opportune maschere.
Encoder RTCM
Come abbiamo visto il decoder ci fornisce in uscita tutti i parametri contenuti nelle stringhe di correzione. E' quindi possibile ricostruire la trama RTCM basandosi sui dati ricavati, ovviamente tale ricostruzione non ha senso se i dati trasmessi sono quelli gia' decodificati , ma diventa importante quando si vogliono cambiare i valori delle correzioni. Ad esempio se un utente e' in una posizione intermedia fra due stazioni differenziali si potrebbe pensare di inviargli una correzione fatta a misura ovvero pesata secondo dei coefficienti opportuni, supponiamo una situazione tipo quella di figura 29:
stazione1 stazione 2
![]()
![]()


A B

utente gps
Figura 27:utente GPS fra due stazioni
dove :
A=distanza utente stazione 1
B=distanza utente stazione 2
avendo a disposizione i valori delle correzioni delle due stazioni (che chiamero' Ф e Г)
si potrebbe fornire il seguente valore correttivo
У=A/(A+B)*Ф +B/(A+B)* Г
Se A e' maggiore di B avra' piu' peso la correzione data dalla stazione 1 ,viceversa sara' la stazione 2 ad essere preponderante.
La distanza fra le due stazioni deve essere comunque contenuta (si pensa ad un range massimo di 150-200 km) e poiche' attualmente in Italia non ci sono stazioni cosi' vicine si e' pensato prima di tutto di capire se questa distanza cosi' ridotta sia veramente necessaria ed in secondo luogo di creare un nuovo stream rtcm che fosse utilizzabile da un utente. La produzione dello stream elaborato non e' parte centrale di questo progetto , tuttavia dopo l'intenso studio sul decoder rtcm credo sia possibile fornire almeno una idea su come ottenerlo.
Il decoder ci fornisce tutti i valori ,supponiamo allora di voler creare la word numero 1, abbiamo bisogno del preambolo , del message type , dello station id e dei parity bit , preleviamo tali valori , codifichiamoli con un numero intero (quindi con 32 bit) , ad esempio per type 1 abbiamo 000000......1 (32 bit), shiftiamo questo valore di 16 posizioni a sinistra ,preleviamo lo station id ,nel caso di Roma pari a 330 e quindi in binario diventa 000....0101000010 (32 bit) , shiftiamo questo valore di 6 posizioni a sinistra , ora possiamo mettere in OR i due valori ottenendo
^ ^ ^ ^ ^ ^
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 1 0 0 0 0 0 0 0
^ ^ ^ ^ ^ ^ ^ ^ ^ ^

0 0 0 0 0 0 0 0 0 0 [0 0 0 0 0 1][ 0 1 0 1 0 0 0 0 1 0] 0 0 0 0 0 0 ^^^^^^^^^^ ^^^^^^^^^^^^^^^^
msg_type station_id
ora sapendo che il flag iniziale di trama e' pari a 01100110 shiftando questo dato , che corrisponde all'intero 112 , di 22 posizioni e ponendo ancora in OR il valore precedente con quello appena ricavato abbiamo
0 0 [ 0110 0110 ][0 0 0 0 0 1 ][0 1 0 1 0 0 0 0 1 0 ] 000000
flag 8 bit msg_type 6 bit station_id 10 bit
ora sfruttando l'algoritmo di generazione dei bit di parita' (che descrivero' successivamente ) otteniamo una stringa binaria del seguente tipo:
0 0 0 0 0 0 0 0 0 0 [0 0 0 0 0 1][ 0 1 0 1 0 0 0 0 1 0] 0 0 0 0 0 0 ^^^^^^^^^^ ^^^^^^^^^^^^^^^^
msg_type station_id
ora ( a parte la ridondanza di due bit) e' sufficiente suddividere i 30 bit ottenuti in 5 gruppi da 6 bit ed aggiungere ad ogni gruppo i bit di identificazione (0 1 ) , otteniamo i seguenti gruppi:
0 1 0 1 1 0 0 1
0 1 1 0 0 0 0 0
0 1 0 1 0 1 0 1
0 1 0 0 0 0 1 0
0 1 x x x x x x
ora bisogna tenere conto dell'inversione binaria e quindi gli ultimi sei bit di ogni gruppo vanno invertiti ottenendo
0 1 1 0 0 1 1 0 ----->intero 104 ---->carattere 'h'
0 1 0 1 1 1 1 1 ----->intero 95 ---->carattere '_'
0 1 1 0 1 0 1 0 ----->intero 106 ---->carattere 'j'
0 1 1 1 1 1 0 1 ----->intero 125 ---->carattere '}'
0 1 x x x x x x ----->intero ? ---->carattere ?
la mini stringa risultante e' la seguente:

“h _ j }“
ovviamente manca il carattere determinato dai bit di parita'. Il procedimento va' ripetuto per tutte le word da trasmettere.
Parity Algorithm
Gli algoritmi di parita' permettono ad un elaboratore di capire quando i dati ricevuti Contengono degli errori , il valore dei bit di parita' e' calcolato secondo quello dei bit che formano il dato trasmesso . L'algoritmo raffigurato nelle successive due figure permette di capire se ci sono stati errori di trasmissione nei dati correttivi ed e' implementato allo stesso modo sia per le stringhe rtcm sia per i normali dati GPS.
In figura 30 abbiamo il parity encoding , il simbolo '*' specifica i bit della word appartenenti alla precedente trama, d1....d24 sono i bit di dato contenuti nella word da trasmettere ,D25...D30 sono i bit di parita', l'operazione di OR-esclusivo e' indicata con xor.
In figura 30 abbiamo il flow chart che implementa l'algoritmo di parita'.
D1 = d1 xor D30*
D2 = d2 xor D30*
D3 = d3 xor D30*
....
....
....
D24 = d24 xor D30*
D25 = D29*xor d1xor d2 xor d4 xor d5 xor d6 xor d10 xor d11 xor d12 xor d13 xor d14 xor d17 xor d18 xor d20 xor d23
D26 = D30*xor d2xor d3 xor d4 xor d6 xor d7 xor d11 xor d12 xor d13 xor d14 xor d15 xor d18 xor d19 xor d21 xor d24
D27 = D29*xor d1xor d3 xor d4 xor d5 xor d7 xor d8 xor d12 xor d13 xor d14 xor d15 xor d16 xor d19 xor d20 xor d22
D28 = D30*xor d2xor d4 xor d5 xor d6 xor d8 xor d9 xor d13 xor d14 xor d15 xor d16 xor d17 xor d20 xor d21 xor d23
D29 = D30*xor d1xor d3 xor d5 xor d6 xor d7 xor d9 xor d10 xor d14 xor d15 xor d16 xor d17 xor d18 xor d21 xor d2 xor d24
D30 = D29 *xor d3xor d5 xor d6 xor d8 xor d9 xor d10 xor d11 xor d13 xor d15 xor d19 xor d22 xor d23 xor d24
Figura 27:User parity algorithm


enter



 SI NO
SI NO



 complement D*30=1 do
not complement
complement D*30=1 do
not complement
D1..........D24 D1...................D24
to obtain to obtain
d1...........d24 d1...................d24




 substitute
d1.......d24
substitute
d1.......d24
D29*&.D30* into
 parity
equation
parity
equation
are computed
NO D25....D30 SI



 equal
to correspondig
equal
to correspondig

 received
D25....D30
received
D25....D30
parity check fails parity check passes
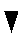


fail exit pass exit
Figura 28:Parity flow chart
Capitolo 9
La raccolta di dati correttivi
Hacking con Ethereal
Grazie al supporto del centro EUREF e' stato possibile acquisire una grande quantita' di dati correttivi , per effettuare l'acquisizione multipla e contemporanea non e' stato possibile l'utilizzo del client EUREF denominato NTRIP e quindi anche in questo caso e' stato sviluppato un apposito codice denominato Decoder-2. Il target di questo programma era di simulare in client NTRIP e quindi doveva connettersi al server rtcm di Francoforte rispettando il protocollo EUREF. Prima di procedere alla generazione del codice si doveva capire quale fosse il processo di comunicazione instaurato fra client e server. A questo scopo e' stato di grande utilita' il tool Ethereal (Network Protocol Analyzer) che permette lo sniffing dei dati che si ricevono sul proprio computer e' possibile scegliere la periferica di acquisizione e filtrare determinati host. Pochi secondi sono sufficienti per capire come avviene in pratica la comunicazione specifica tra un client ed un server. In figura 22 capitolo 5 abbiamo visto il three way handshacking , era logico aspettarsi un risultato che riflettesse il protocollo standard.
Lanciando il client EUREF richiedendo i dati di Roma dopo aver preparato Ethereal alla ricezione abbiamo ottenuto il seguente file:
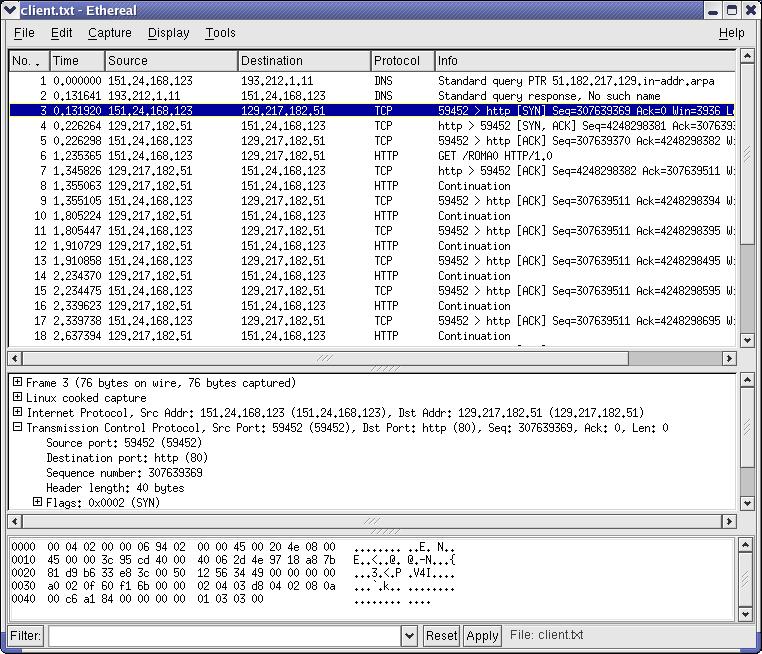
Figura
29: Analisi con Ethereal
La riga selezionata in blu determina l'inizio dell' handshacking fra client e server vediamola in particolare:
Frame 3 (76 bytes on wire, 76 bytes captured)
Arrival Time: Jun 28, 2003 22:51:29.754933000
Time delta from previous packet: 0.000279000 seconds
Time relative to first packet: 0.131920000 seconds
Frame Number: 3
Packet Length: 76 bytes
Capture Length: 76 bytes
Linux cooked capture
Packet type: Sent by us (4)
Link-layer address type: 512
Link-layer address length: 6
Source: 94:02:00:00:45:00 (94:02:00:00:45:00)
Protocol: IP (0x0800)
Internet Protocol, Src Addr: 151.24.168.123 (151.24.168.123), Dst Addr: 129.217.182.51 (129.217.182.51)
Version: 4
Header length: 20 bytes
Differentiated Services Field: 0x00 (DSCP 0x00: Default; ECN: 0x00)
0000 00.. = Differentiated Services Codepoint: Default (0x00)
.... ..0. = ECN-Capable Transport (ECT): 0
.... ...0 = ECN-CE: 0
Total Length: 60
Identification: 0x95cd
Flags: 0x04
.1.. = Don't fragment: Set
..0. = More fragments: Not set
Fragment offset: 0
Time to live: 64
Protocol: TCP (0x06)
Header checksum: 0x2d4e (correct)
Source: 151.24.168.123 (151.24.168.123)
Destination: 129.217.182.51 (129.217.182.51)
Transmission Control Protocol, Src Port: 59452 (59452), Dst Port: http (80), Seq: 307639369, Ack: 0, Len: 0
Source port: 59452 (59452)
Destination port: http (80)
Sequence number: 307639369
Header length: 40 bytes
Flags: 0x0002 (SYN)
0... .... = Congestion Window Reduced (CWR): Not set
.0.. .... = ECN-Echo: Not set
..0. .... = Urgent: Not set
...0 .... = Acknowledgment: Not set
.... 0... = Push: Not set
.... .0.. = Reset: Not set
.... ..1. = Syn: Set
.... ...0 = Fin: Not set
Window size: 3936
Checksum: 0xf16b (correct)
Options: (20 bytes)
Maximum segment size: 984 bytes
SACK permitted
Time stamp: tsval 13017476, tsecr 0
NOP
Window scale: 0 (multiply by 1)
le righe evidenziate ci danno i tempi intercorsi fra i pacchetti di dati , l'indirizzo IP della macchina che richiede il servizio e soprattutto l'indirizzo IP ed il numero di porta utilizzati dal server. Come si vede il client ha inviato il segnale SYN e quindi si aspetta un SYN ACK dal server.
Transmission Control Protocol, Src Port: http (80), Dst Port: 59452 (59452), Seq: 4248298381, Ack: 307639370, Len: 0
Source port: http (80)
Destination port: 59452 (59452)
Sequence number: 4248298381
Acknowledgement number: 307639370
Header length: 40 bytes
Flags: 0x0012 (SYN, ACK)
Come previsto il server invia SYN ACK , nelle successive due righe abbiamo ancora un ACK del client ed una GET.
La GET descrive l'ordine che il client invia al server e contiene tutte le informazioni richieste dal sever stesso. Vediamola in particolare:
Protocol: TCP (0x06)
Header checksum: 0x2cc7 (correct)
Source: 151.24.168.123 (151.24.168.123)
Destination: 129.217.182.51 (129.217.182.51)
Transmission Control Protocol, Src Port: 59452 (59452), Dst Port: http (80), Seq: 307639370, Ack: 4248298382, Len: 141
Source port: 59452 (59452)
Destination port: http (80)
Sequence number: 307639370
Next sequence number: 307639511
Acknowledgement number: 4248298382
Header length: 32 bytes
Flags: 0x0018 (PSH, ACK)
0... .... = Congestion Window Reduced (CWR): Not set
.0.. .... = ECN-Echo: Not set
..0. .... = Urgent: Not set
...1 .... = Acknowledgment: Set
.... 1... = Push: Set
.... .0.. = Reset: Not set
.... ..0. = Syn: Not set
.... ...0 = Fin: Not set
Window size: 3936
Checksum: 0x4141 (correct)
Options: (12 bytes)
NOP
NOP
Time stamp: tsval 13017587, tsecr 61249033
Hypertext Transfer Protocol
GET /ROMA0 HTTP/1.0\r\n
User-Agent: NTRIP GNSSInternetRadio/1.2.0\r\n
Accept: */*\r\n
Connection: close\r\n
Authorization: Basic dXNlcjI5OmRmNTRndA==\r\n
\r\n
come si vede il client richiede la stazione di Roma identificata con il nick
ROMA0,
il sever richiede al client di identificarsi ed il client deve rispondere con la seguente stringa:
NTRIP GNSSInternetRadio/1.2.0
viene richiesta la password personale
Authorization: Basic dXNlcjI5OmRmNTRndA==\r\n
A questo punto poiche' la GET corrisponde ad una scrittura del server socket e' stato sufficiente allineare la stringa contenuta nella GET e scrivere un codice che dopo la connessione effettuasse una write .
Riporto una parte del codice:
dichiarazione delle stringhe:
char * stazione1="GET /";
char * stazione2=" HTTP/1.0\r\nUser-Agent: NTRIP GNSSInternetRadio/1.2.0\r\nAccept: */*\r\nConnection: close\r\nAuthorization: Basic dXNlcjI5OmRmNTRndA==\r\n\r\n";
costruzione della stringa finale:
strcpy (stazione,stazione1);
strcat(stazione,dgpshost);
strcat(stazione,stazione2);
scrittura del socket
cnt_r=write (sock_dsc,stazione, strlen (stazione));
come si vede la costruzione della stringa presuppone la conoscenza della variabile dgpshost, difatti in questo caso abbiamo richiesto i dati di Roma , ma in generale l'utente deve poter scegliere la stazione sorgente.
Il clone NTRIP
L 'estensione di questo codice doveva avere i seguenti target
Emulazione totale del client NTRIP
scelta della stazione da parte dell'utente
scelta del tempo di acquisizione
decodifica dei dati ricevuti con il decoder rtcm
estensione della ricezione in modalita' multipla e sincrona
redirezione dei dati decodificati su singoli file per stazione.
Per poter permettere la scelta della stazione e del tempo di acquisizione le variabili dgpshost e tmout sono acquisite da linea di comando grazie alla getop
while ((c = getopt(argc, argv, "c:h:t:v")) != EOF) {
switch (c) {
case 't': /* timeout */
tmout = atoi(optarg);
break;
case 'h': /*dgps host */
dgpshost=optarg;
break;
}
}
Per la decodifica dei dati e' stato inserito il codice rtcm.c con le modalita' descritte nel paragrafo 8.1.
Per la ricezione multipla e sincrona e' stato creato un bash script apposito che decrivero' successivamente.
Per la redirezione e' stato sufficiente lanciare il programma con l'opzione “>” “nomefile” , dove “nomefile” e' una variabile d'ambiente opportunamente creata.
Il codice complessivo e' riportato nell'appendice C. In questo caso e' necessaria l'installazione del programma poiche' lo script per l'acquisizione multipla lo chiama da linea di comando .
Una simpatica curiosita':in sei mesi di acquisizione i gestori EUREF hanno mosso solo un gentile appunto “si prega di aggiornare il programma NTRIP”...detto ...fatto.
Rtcm_dec Linux script
Per la ricezione multipla e contemporanea ho creato uno script denominato rtcm_dec.
Lo script avvia il programma decoder2 sfruttando le opzioni da riga di comando.Per poter scegliere la stazione e' stato necessario creare un file con l'elenco dei nick utilizzati dal server EUREF e quindi una serie di hack con Ethereal , per poter salvare i dati su file diversi per ogni acquisizione e' stato associato il nick al nome della citta' dove risiede la stazione e quindi creata una opportuna variabile di ambiente.
Poiche' il server EUREF ha la “cattiva abitudine” di chiudere alcune connessioni dopo
un certo tempo per motivi ignoti ,lo script definisce anche il numero dei tentativi da fare per ogni gruppo di acquisizione. Ogni gruppo di file viene separato e non sovrascritto. Riporto interamente lo script:
#!/bin/bash
T1=0; #variabili interne
T2=0;
while getopts "t:n:h" Option
do
case $Option in
t )
T=$OPTARG;; # tempo di acquisizione
n )
N=$OPTARG;; # numero di acquisizioni
h )
echo #help on line
echo "---------------------------------------------------";
echo "decoder scpript for rtcm acquisition"
echo "option: -t:acquisition time in minutes"
echo " -n acquisitions number;"
echo "i assumed a directory called 'dati_rtcm' in your home";
echo "WARNING:any old file in the directory will be deleted!"
echo ----------------------------------------------------;
echo
exit;;
esac
done
echo
echo
echo " type dec1 -h for help "
echo " ************************************************************";
echo " * WARNING:any old file in the directory will be deleted! *";
echo " * Ctrl c to stop program before countdown end *";
echo " * i assumed a directory called 'dati_rtcm' in your home *";
echo " ************************************************************";
echo
echo
T1=20; #countdown
while [ "$T2" -lt 20 ];
do
printf ' : %02d\r Countdown ' $T1;
sleep 1
let T2=T2+1;
let T1=T1-1;
done
T2=0;
T1=0;
tt1=$T;
tt2=m;
tt=$tt1$tt2;
while [ "$T2" -lt "$N" ]; #numero acquisizione
do
if [ "$T1" = 0 ]; then #non sto' acquisendo
while read stazione nick #leggi file con elenco stazione
do
nomefile=$stazione$T2
date > ~/dati_rtcm/$nomefile.txt &
decoder -t $T -h $nick >> ~/dati_rtcm/$nomefile.txt &
done < elenco_stazioni1
let T2=T2+1 #numero di acquisizione fatte
T1=5;
else
sleep $tt #aspetto la fine dell'acquisizione
T1=0;
fi
done
come si vede dalle righe selezionate lo script acquisisce prima di tutto la data corrente e quindi le correzioni rtcm in modalita' append, questo consente di avere un riferimento temporale esatto per l'elaborazione dei dati.
Il file assume di volta in volta un nome diverso secondo il numero di acquisizione .ad esempio Roma0 Roma1.....RomaN .... questo per tutte le stazioni. Prima di procedere l'utente viene avvertito che i file contenuti nella directory dati_rtcm saranno sostituiti con i nuovi , tale directory deve essere presente nella home utente.
Per eseguire lo script bisogna cambiare i permessi sul file con chmod
chmod 755 rtcm_dec.
Un esempio di applicazione puo' essere il seguente comando
./rtcm_dec -t 180 -n 5
che avvia il decoder chiedendo 5 acquisizioni di 180 minuti ciascuna.
Capitolo 10
Elaborazione ed analisi dei dati
Octave Matlab clone
Terminata la fasi di installazione del server , sviluppo del client e di acquisizione dei dati , grazie al tool Octave si e' passati alla fase di elaborazione ed analisi. Octave e' il Linux Matlab clone , in grado di simulare praticamente un qualunque elaboratore. In un primo momento si e' pensato di esaminare i dati e successivamente siamo passati alla elaborazione .
Grafici dei dati correttivi
Tutti i grafici ricavati sono ottenuti con post processing delle correzioni, ogni programma Octave svolge piu' di un funzione , il primo che consideriamo e' filtrofir.m, tutti i codici sono mostrati nell'appendice D.

Inizializzazzione
apertura file dati in lettura
scansione del file
memorizzazione in matrice
costruzione vettore tempo di acquisizione
filtraggio FIR
plotting dei dati
Figura 30:Struttura di filtrofir.m
Il programma elabora i file una prima volta in modo diretto ed una seconda con filtraggio FIR .Consideriamo la prima elaborazione.
In figura 35 vediamo finalmente l'andamento delle correzione differenziali per un determinato satellite .

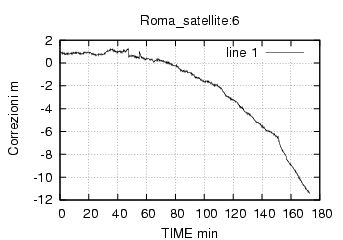




 Figura
31 :Andamento delle correzioni differenziali
Figura
31 :Andamento delle correzioni differenziali
La figura mostra il risultato di un elaborazione di dati acquisiti per un tempo di circa 2 /3 ore , la prima a destra rappresenta l'andamento per le prime due ore di acquisizione
mentre la seconda mostra quello delle tre ore successive . E' evidente il trend crescente e poi decrescente (evidenziato in rosso), mentre quello complessivo e' di tipo parabolico (evidenziato in verde). A questo punto dobbiamo esaminare molti altri satelliti per capire se questo tipo di andamento e' del tutto generico.
Di fondamentale importanza e' stato l'utilizzo della rete EUREF.
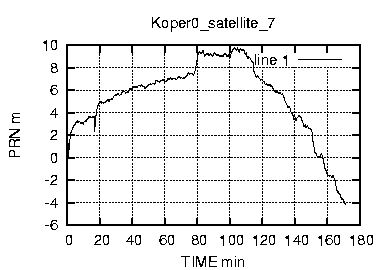
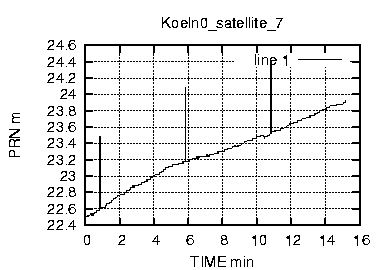




 :spike
di correzione
:spike
di correzione

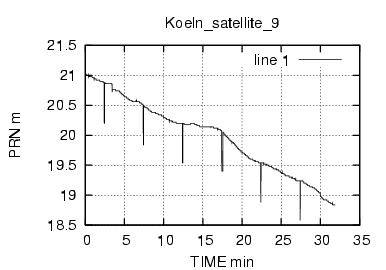
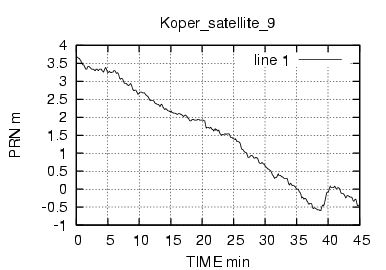



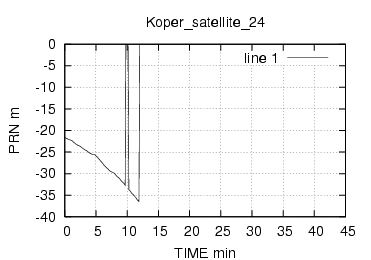
 Figura
32:Gruppo satellitare con trend decrescente
Figura
32:Gruppo satellitare con trend decrescente
:Tramonto satellitare
In questo primo gruppo di acquisizioni (ovviamente sincrone) abbiamo un trend decrescente , notiamo la presenza di spike correttivi dovuti ad una serie di fattori , qualita' momentanea del segnale , qualita' della stazione , intasamento della rete internet , escludo errori del decoder rtcm. Gli spike potrebbero essere un problema per la futura analisi poiche' rappresentano valori di correzione non del tutto reali . Notiamo che quasi tutti i satelliti sono in un range centrale mentre ad esempio in figura 31 il satellite 6 raggiunge il picco di correzione. Nei successivi grafici abbiamo gli andamenti per le le ore precedenti.
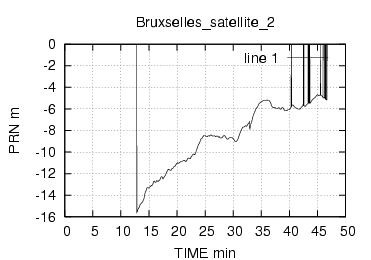

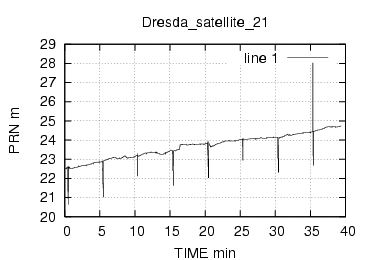




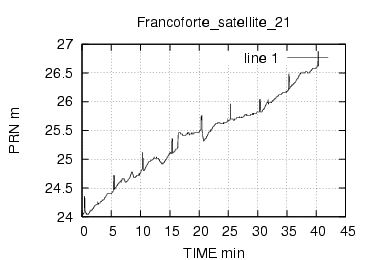
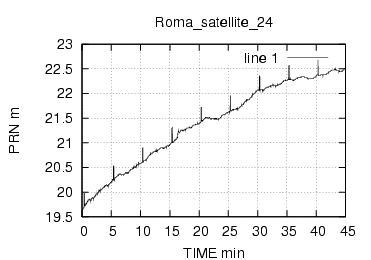
Figura
33: Gruppo satellitare con trend crescente
 :
alba satellitare
:
alba satellitare
 : buchi in ricezione
: buchi in ricezione
Nel caso del satellite 2 di Bruxselles abbiamo una alba satellitare , ovvero il satellite sorge all'orizzonte e comincia ad essere visibile dalla stazione , in questo caso i valori di correzione sono massimi in modulo e si aggirano attorno a -20/-30 m. Nel caso di Bochum satellite 6 abbiamo dei buchi di ricezione causati sicuramente non dal malfunzionamento satellitare (visto che le altre stazioni lo ricevono bene)ma piu' probabilmente da una violenta perturbazione o da fattori riguardanti la qualita' della stazione correttiva. Nel caso di Koper satellite 24 abbiamo un tramonto satellitare con valori di correzione ovviamente paragonabili a quelli che si hanno all'alba.
Per completezza vengono riportati lo zoom sulle correzioni ed un grafico della velocita' di variazione , quest' ultimo tuttavia poco esplicativo.
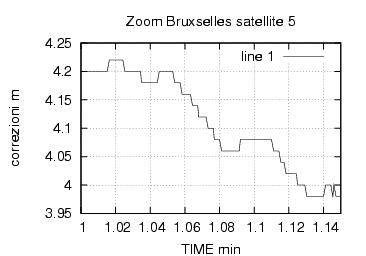
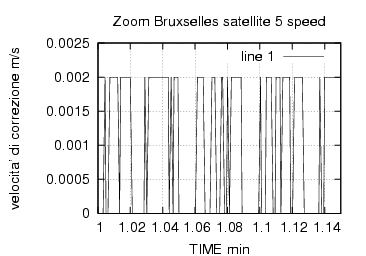
Figura
34:Zoom e velocita' di variazione
Dai grafici esaminati fino ad ora (e dai molti altri creati che non riporto ) possiamo concludere:
l'andamento dei valori delle correzioni differenziali e' affetto in modo pesante dall'orbita satellitare
sono presenti spike correttivi soprattutto in fase di alba e tramonto
sono presenti buchi di ricezione
sono presenti stazioni con bassa qualita' trasmissiva
cio' ci suggerisce di :
effettuare una radicale selezione fra le stazioni
confrontare i dati su periodi temporali limitati e multipli
esaminare le componenti orbitali singole
rimuovere le componenti orbitali
valutare il residuo correttivo fra due stazioni
Rimozione delle componenti di bassa frequenza
Consideriamo ora la seconda elaborazione creata da filtrofir.m. Il modo piu' semplice e diretto per eliminare tutte le componenti di disturbo sulle correzioni differenziali e' quello di utilizzare un filtro FIR del primo ordine il cui schema e' riportato in figura 35 , successivamente vengono riportati alcuni grafici delle correzioni differenziali filtrate.




 correzioni 1/2n+1
correzioni 1/2n+1
 2n+1
2n+1
 -
-


 delay
n
delay
n
+
Figura 35:Filtro FIR del primo ordine
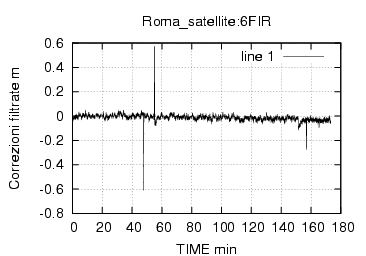
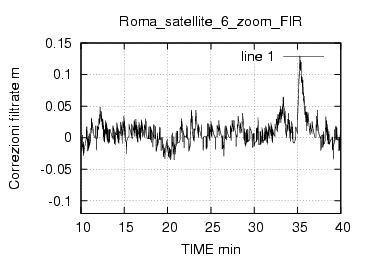
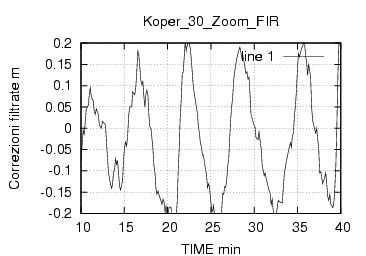

Figura
36:Correzioni filtrate
Gli andamenti ottenuti sono quelli depurati da qualunque disturbo esclusi gli spike che rimangono ma sono comunque in numero molto limitato. Possiamo proseguire con l'analisi cominciando a valutare il residuo correttivo fra due stazioni.
La differenza di correzione
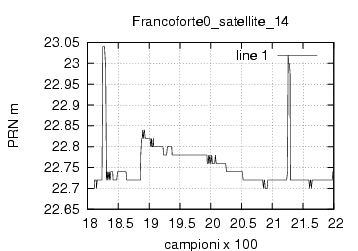
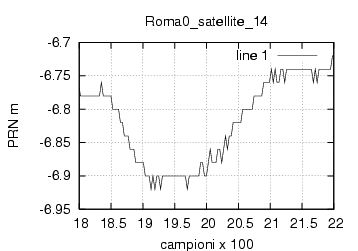
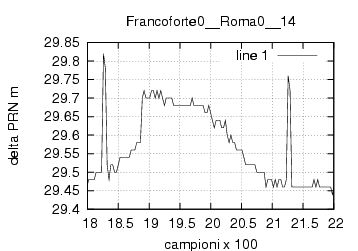
Figura
37:Differenza di correzione diretta

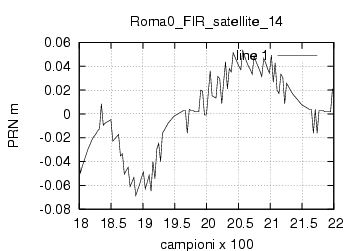

figura
38:Differenza di correzione filtrata
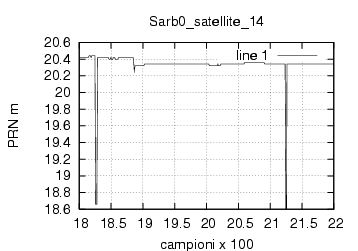
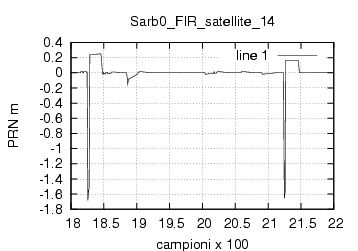
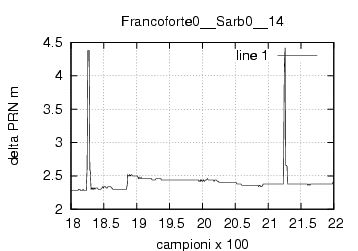
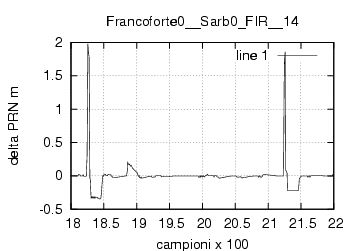

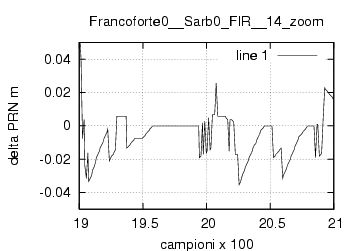
Figura
39:Correzione differenza per stazioni molto vicine
otteniamo un buon abbassamento della dinamica media, difatti passiamo da circa 0.12 nel caso non filtrato a circa 0.05 nel caso filtrato.
La correlazione per satellite
Passiamo ora alla valutazione della correlazione per satellite fra stazioni con dati filtrati. Consideriamo come al solito alcune stazioni molto vicine e altre molto lontane, si consulti l'appendice E per la lista delle distanze fra le stazioni.

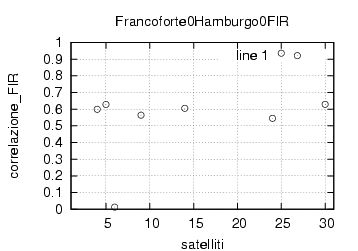


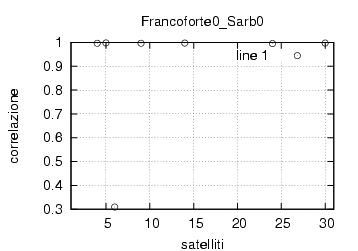


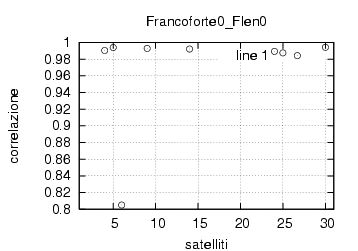


Figura
40 : correlazioni per satellite
Ne concludiamo che:
i dati non filtrati sono fortemente correlati per distanze anche maggiori di 500 Km ,
l'andamento delle correlazioni risulta fortemente variabile da satellite a satellite se la distanza e' maggiore di 500 km. Questo ci suggerisce di estendere l'analisi a tutte le possibili coppie di stazioni 3 di mediare su scatter plot i risultati ottenuti.
Scatter plot con filtro FIR
Considerando di volta in volta una stazione come riferimento sono stati calcolati i parametri statistici di : correlazione media fra stazioni , varianza e media della correzione differenza .
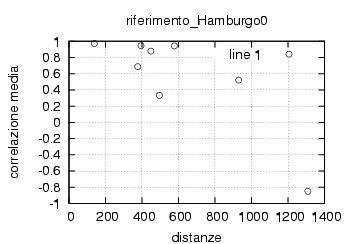
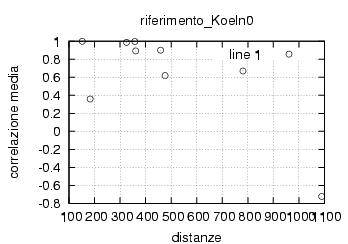

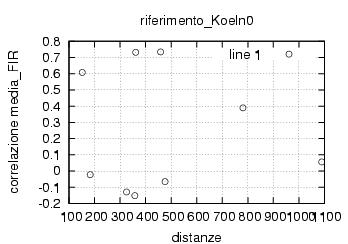

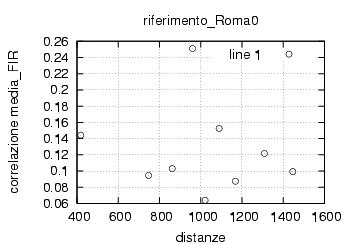
Figura 41:Correlazione media in
funzione della distanza

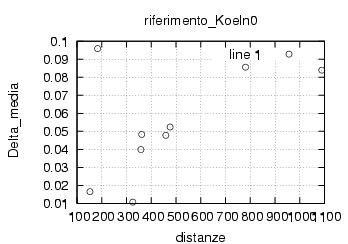
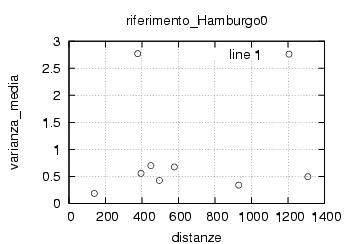
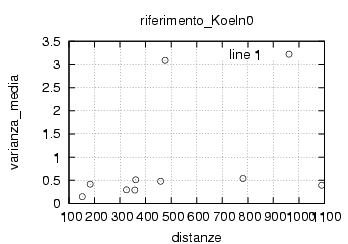
Figura 42:Valor medio e varianza della differenza di correzione
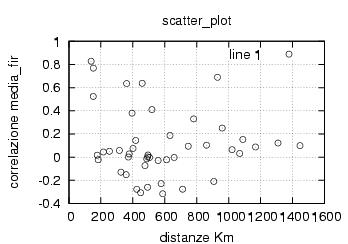
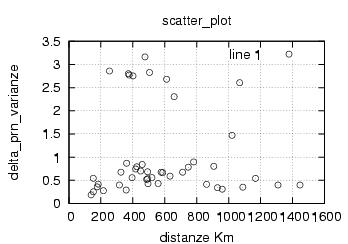
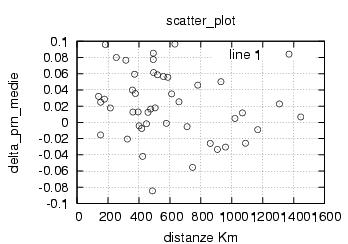
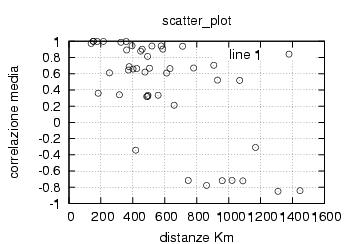




 Figura
42 :Gli scatter plot con filtro FIR
Figura
42 :Gli scatter plot con filtro FIR
In figura 42 abbiamo gli scatter plot , e come si vede se le correzioni non sono filtrate (in alto a sinistra) non e' possibile definire punti limite e punti di rottura ,la linea verde rappresenta solo una media grossolana ma non e' un limite per i valori di correlazione
In ato a destra abbiamo lo scatter plot con correzioni filtrate e possiamo definire un andamento limite (in rosso) dovuto al naturale aumento della decorrelazione dovuto al crescere della distanza. La curva in blu rappresenta il rapido decadimento della correlazione dai valori massimi di 0.8-0.85.
I valori compresi fra 140-180 km sono quelli piu' interessanti per valutare la distanza di collocazione due stazioni correttive.
Il simulatore Metaserver3
Come detto i grafici sin qui' ottenuti sono frutto di un post processing sui dati acquisiti
e' noto che una tale elaborazione non puo' essere fatta su dati che devono essere trasmessi in tempo reale , ad esempio non e' possibile rimuovere i disturbi sulle correzione sfruttando un filtro FIR , perche' questo richiederebbe appunto una post elaborazione e si perderebbe la caratteristica real time. Si e' pensato simulare completamente il comportamento del server rtcm futuro e quindi si' e' generato un codice con queste caratteristiche:
acquisizione contemporanea dei dati da due stazioni
capacita' di risincronizzazione delle stazioni
acquisizione effemeridi dei satelliti e parametri ionosfera
calcolo del tempo GPS
calcolo della posizione del satellite
calcolo dell'angolo di elevazione
calcolo della componente ionosferica
calcolo del nuovo pseudorange di correzione
tale codice prende il nome di meta3sml.m ed ingloba al suo interno i codici satpos.m , ionocorr.m , sat_angle.m , ecef_xyz.m ,plotter.m . il codice ecef_xyz.m ci
permette di calcolare le coordinate cartesiane da quelle ECEF , plotter e' utilizzato per i grafici ed il calcolo delle varie medie. Prima di illustrare i risultati inseriamo qualche nozione teorica.
Sistemi di coordinate
Il sistema ECEF Earth-Centered-Earth-Fixed Coordinate System e' solidale con la terra e ruota con esso , considera le coordinate rispetto all'ellissoide di riferimento mostrato in figura 43.

Figura
43 ellissoide di riferimento
Il sistema ECI ,Earth Centered Inertial considera l'origine coincidente con il centro della terra e tipicamente il piano XY coincidente con quello equatoriale.
Parametri delle efferidi
E' possibile utilizzare Internet per scaricare i file delle effemeridi e ricavare i parametri necessari per il calcolo della posizione utente.

Figura
44:parametri delle effemeridi
Componenti atmosferiche
Nel calcolo delle correzioni abbiamo detto essere presente sia il ritardo dovuto alla ionosfera che quello troposferico. La ionosfera coincide con la fascia compresa fra 70 e 1000 km al di sopra della superficie terrestre , la troposfera fra 10 e 40. Per il calcolo della componente di ritardo si e' utilizzato il modello della ionosfera che tuttavia non risulta totalmente accurato , ci sono infatti deviazioni dal modello che alterano le misure.
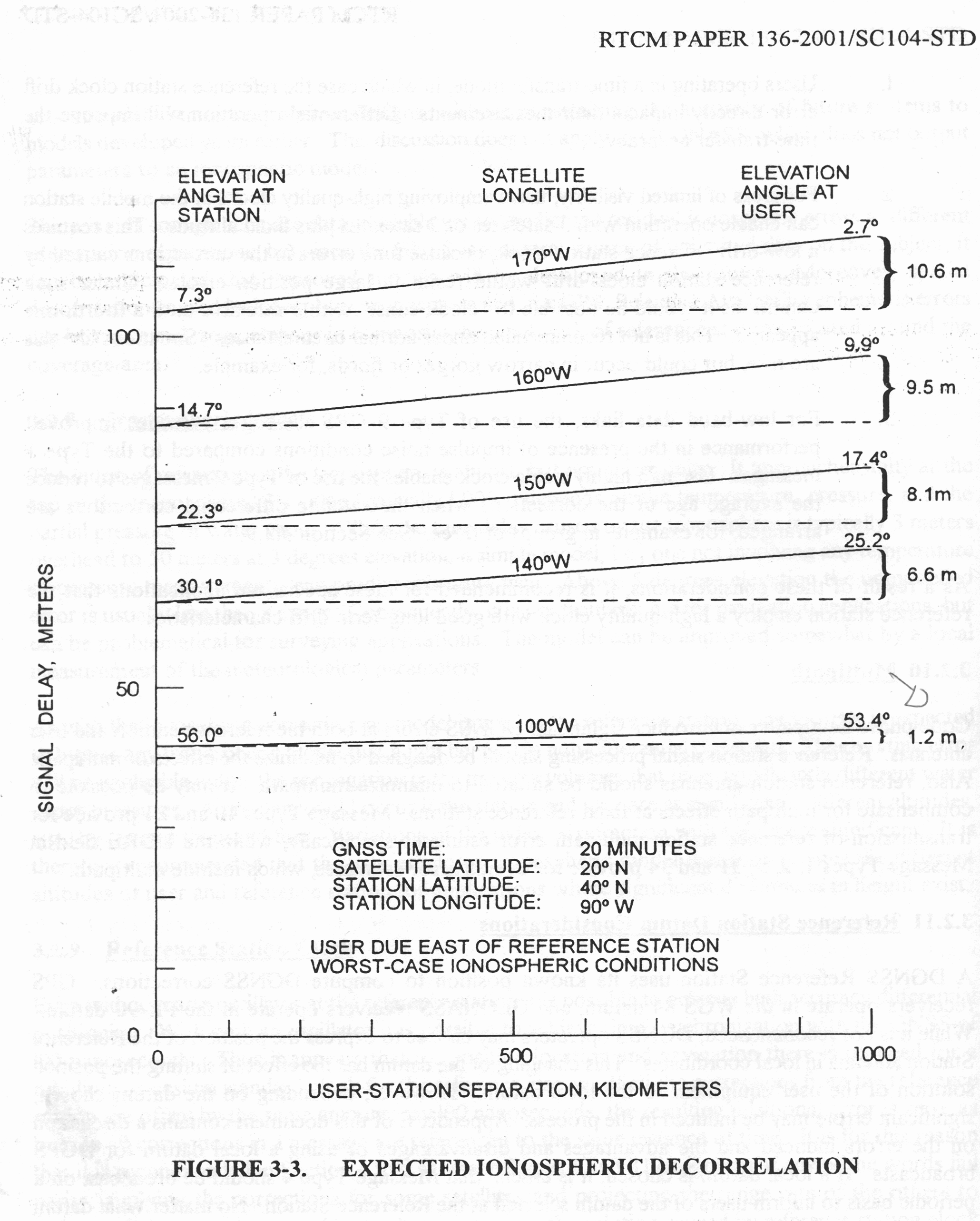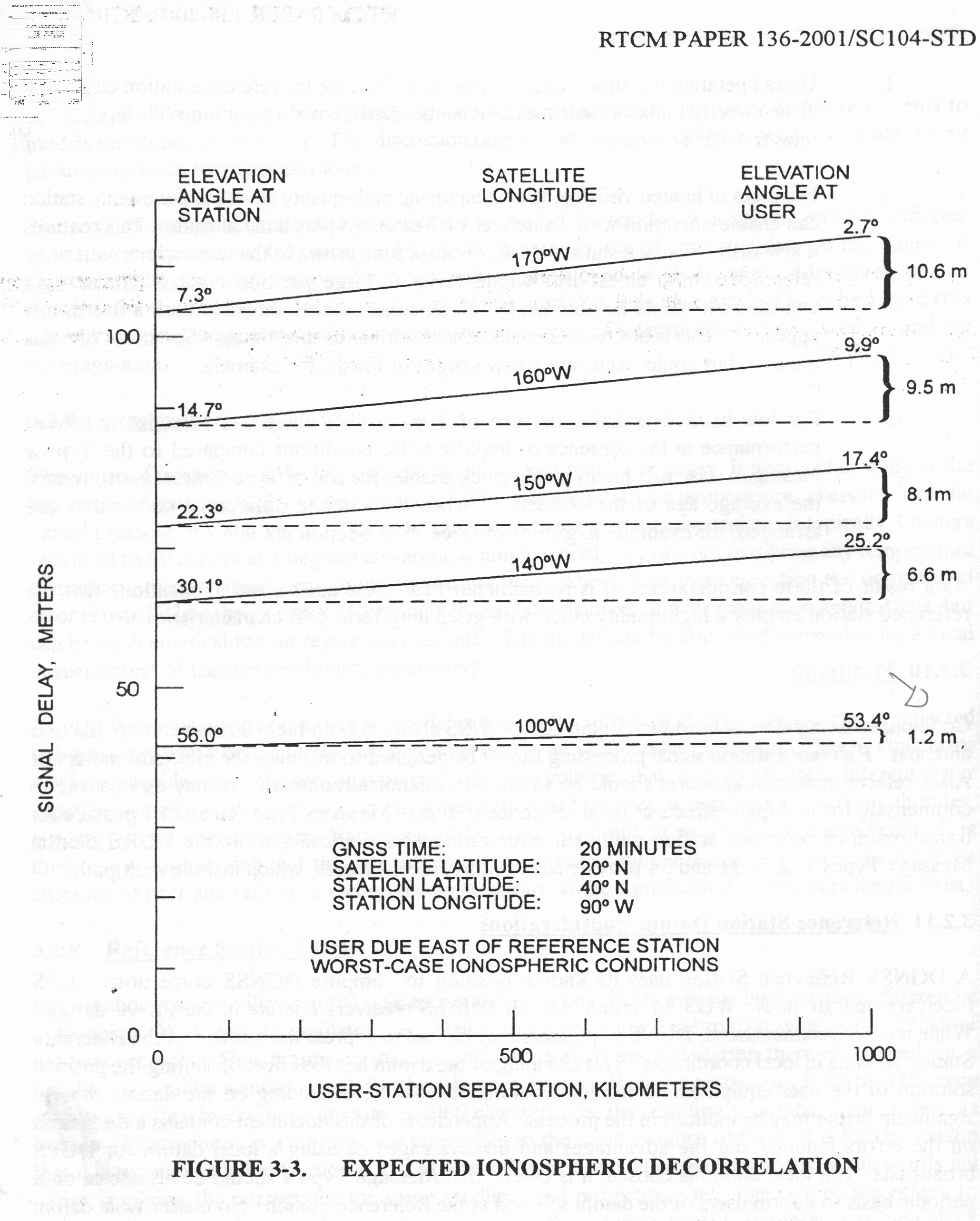

 Elevazione
ed azimuth
Elevazione
ed azimuth
Come si vede i valori del ritardo ionosferico dipendono dagli angoli fra stazione e satellite . In figura 46 abbiamo la disposizione geometrica di tali angoli.
Figura
46:angolo di elevazione h e di azimut ∂
riporto i grafici ottenuti con meta3sml.m premettendo che a causa della forte elaborazione ho pensato di decimare i dati di conseguenza gli andamenti risultano piu' lineari del dovuto.

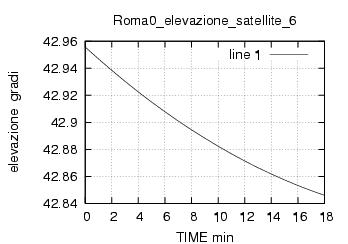
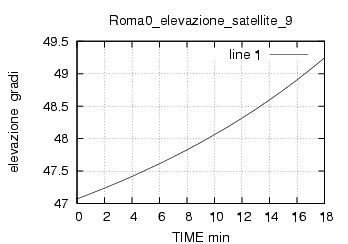
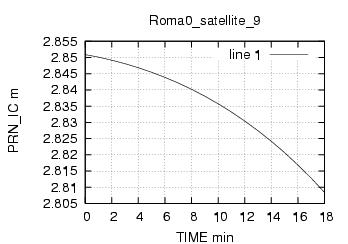
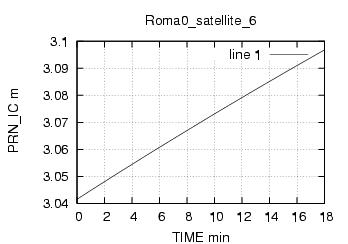

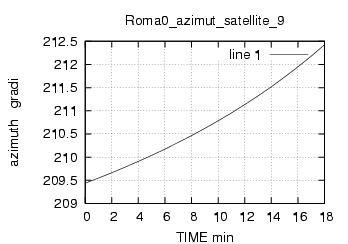


Figura 47:stazione di Roma con componente ionosferica rimossa
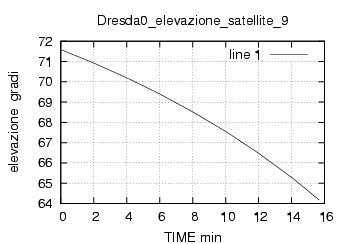
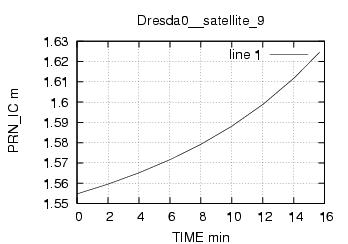
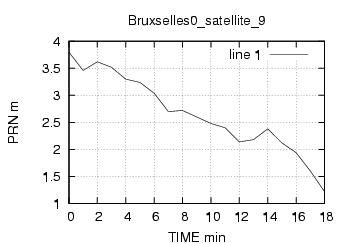



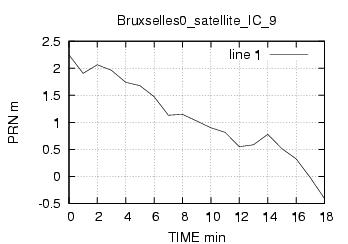

Figura
48:Altre stazioni corrette dal ritardo ionosferico

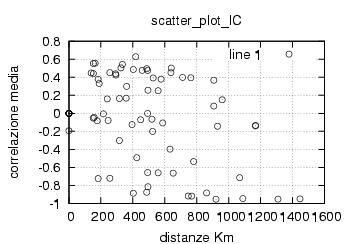
Come si vede anche in questo caso riusciamo ad abbassare la correlazione ma il grafico non fitta a zero come con l'utilizzo del filtro Fir.
Conclusioni
Decisamente interessanti sono i valori ricavati per distanze vicine ai 180 km , che permetterebbero la massimizzazzione dellla copertura del segnale correttivo sul territorio.
Dobbiamo comunque dire che e' possibile l'introduzione di artefatti nelle correzioni di alcune stazioni , tanto che ci stiamo chiedendo se non e' casoi di valutare le possibili coppie sospette visto che alcune correlazioni sono molto elevate anche a distanze sopra i 500 km.
Il lavoro svolto dovrebbe servire per l'efettivo collocamento della nuova stazione differenziale , gli sviluppi sono quindi:
collocazione della stazione
inserimento del decoder rtcm in minimetas versione multi stream
inserimento calcolo range ionosferico in minimetas
inserimento encoder in minimetas .
THE END
Mauro Venanzi