
Capitolo III Codifica audio/video
Nel primo capitolo si è introdotto lo streaming come metodo di accesso a contenuti multimediali tramite reti di calcolatori, in grado di fornire ad un client gli strumenti per ottenere delle risorse di interesse presso un server remoto e riprodurne il flusso durante la stessa fase di trasferimento dei dati dalla sorgente alla destinazione. In questo contesto appare necessario fare riferimento ad una caratteristica fondamentale che giustifica la stessa multimedialità in generale, ossia alla codifica dei dati in formati compatibili per il trasferimento su Internet. Il concetto di compatibilità deve essere qui inteso nel senso più ampio possibile, quindi con esso si indicherà anche la possibilità di ottenere dati in forma compressa, utilizzando opportuni algoritmi di codifica, che non ne pregiudichino più di tanto la qualità a parità di informazione da trasmettere.
Lo stesso concetto di multimedialità è allora strettamente correlato a tale aspetto; è nata dunque lesigenza di sviluppare applicazioni specifiche per la codifica, necessarie quindi per la creazione di quei contenuti, oggetto dello streaming. Ma cosa significa effettivamente creare clips multimediali? In figura III.1, si mettono semplicemente in evidenza gli attori necessari ad una tale realizzazione.
Figura III.1 Codifica audio/video
Chiaramente si parte da un dispositivo di cattura delle immagini e suoni, quale ad esempio una videocamera o anche una semplice scheda TV, il cui input sarà successivamente o in tempo reale esportato su di un computer lavorante come una stazione di editing audio/video. Il passo seguente sarà quindi la creazione di files in determinati formati, che, una volta codificati tramite opportuni codificatori, saranno pronti per essere trasmessi.
Tutto ciò riguarda il solo lato trasmissione ed è chiaro che quando si parla in termini di architettura di streaming, entreranno in gioco anche gli applicativi utili per la riproduzione dei media oltre che naturalmente i servers necessari a fornire tali risorse. Si deve allora parlare necessariamente di interoperabilità nei sistemi di streaming tra le varie entità preposte a fornire detto servizio e che, quindi, devono anche condividere gli stessi meccanismi. Linteroperabilità riguarderà i servers, i players e i codificatori come raffigurati in figura III.2, dove si mettono anche in evidenza le mutue relazioni.
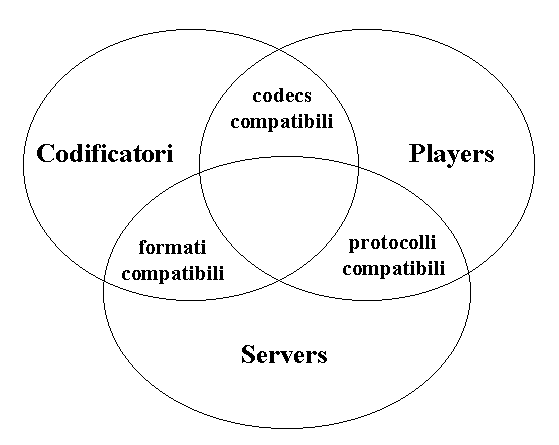
Figura III.2 Interoperabilità in ambito streaming
I codificatori, dovranno essere in grado di memorizzare i contenuti in files accessibili dai servers e quindi in un formato a loro compatibile, inoltre dovranno utilizzare dei codecs conosciuti e pienamente implementati dai players per permetterne la successiva riproduzione. Dal canto loro, i servers dovranno poter trasmettere detti contenuti, utilizzando protocolli che possano essere compresi dai players stessi.
E apparsa subito quindi evidente, la necessità di definire standard riguardanti sia gli algoritmi di codifica/decodifica dei flussi multimediali, sia i protocolli necessari al loro trasferimento e al loro controllo sulla rete. Dopo una fase iniziale dominata soprattutto da tecnologie proprietarie imposte da alcuni colossi dellinformatica, si è assistito al rapido sviluppo di un insieme di standard aperti, o quasi, per le tecnologie di streaming con lobiettivo di raggiungere proprio quella interoperabilità sopra citata tra applicativi di diversa origine e natura. Quando si parla di standard aperti si fa fondamentalmente riferimento a due livelli di apertura:
Essi dovranno essere pubblicamente disponibili, consentendo la libera e aperta implementabilità, garantendo anche lassenza di brevetti, che possano limitare in maniera stringente il proprio sviluppo.
Due delle iniziative principali sorte negli ultimi anni proprio per venire incontro a tale desiderio di standardizzazione, sono lInternet Engineering Task Force (IETF), nata per promuovere una serie di protocolli per il supporto di applicazioni audio/video/voce su IP e lInternet Streaming Media Alliance (ISMA), associazione riunente grandi industrie produttrici di hardware, software e contenuti multimediali, nata per proporre, in particolare, ladozione della codifica ISO MPEG-4 [24] per la compressione dei dati e dei protocolli di streaming proposti da IETF per il loro trasferimento su reti IP.
In realtà, loperazione di standardizzazione tuttora in atto, si è rivelata sin da subito molto ardua dato che naturalmente, le grandi industrie che avevano in passato introdotto i propri formati o sistemi di codifica con lovvio intento di conquistare il mercato e creare così una sorta di monopolio, continuano a fornire supporti per le applicazioni multimediali basandosi sulle proprie specifiche. Sarebbe quindi necessario che, compatibilmente con tale ferma volontà, si riuscissero a creare applicazioni che quanto meno supportino implementazioni varie.
Altro grosso problema, facilmente intuibile non appena si cerchi di entrare nel caos regnante in ambito multimediale, riguarda lesistenza di un errore comune molto diffuso, ossia il continuo confondere un formato file da un codec multimediale.
Quando infatti, per esempio, si vede un file con estensione ".avi", si pensa impropriamente che esso non sia un file MPEG; ciò non è assolutamente vero poiché, un simil file, potrebbe tranquillamente contenere video MPEG-1. Esempi di formati file saranno ".mov", ".avi", ".asf", mentre di codec saranno lMPEG-1, MPEG-2 ed il DivX. Laspetto più interessante da sottolineare è la relazione tra i due, mostrata in figura III.3.
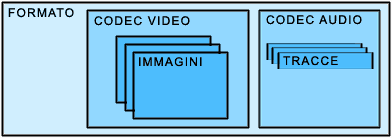
Figura III.3 Formato e codec multimediale
Per formato di un file, infatti, ci si riferisce alla struttura del contenitore di dati multimediali; i files di diverso formato, avranno degli headers diversi, oltre a differenti metodi di storaggio dei dati fisici nel proprio disco. Questi ultimi, dovranno essere necessariamente codificati con opportuni algoritmi, anche diversi tra di loro, implementanti i vari codec multimediali. Sappiamo, infatti, che la mole di dati che una sequenza video comporta e' molto elevata e che quindi sarebbe improponibile realizzare un filmato senza averlo prima compresso (e quindi codificato) con un algoritmo di compressione. Si pensi, ad esempio, a quanto occupi un immagine a colori di 800X600 pixels: sicuramente tanto, troppo per poterne visualizzare 25 al secondo e salvarli sul disco.
Ecco che allora interviene il codec (COmpressore-DECompressore o meglio COdificatore-DECodificatore), ovvero il software contenente un particolare algoritmo matematico attraverso il quale vengono codificati e quindi compressi i dati trasportati da un file di particolare formato (spesso in maniera "lossy", con perdita di informazione), per consentire una gestione agile e una riproduzione corretta del clip. Si potrà quindi sostenere di inserire un video codificato in DivX con audio in codifica MP3 in un file in formato AVI. Limportante è che un formato file dia la possibilità di poter descrivere le tracce in esso contenute con informazioni di diversa natura.
III.1.4 Ambito di lavoro: MPEG
Nei paragrafi seguenti, si è reputato importante, per prima cosa, affrontare lo studio dei principi basilari della video e audio compressione, in modo da poter comprendere meglio i meccanismi su cui si basano gli algoritmi di codifica; successivamente, dopo aver elencato alcuni dei formati files più importanti, si farà una breve trattazione relativa ai principali codec multimediali. E bene sottolineare, che il presente capitolo non nasce per essere un manuale di codifica audio/video dove ci si aspetta la trattazione completa delle metodologie di codifica e la descrizione accurata di tutti i codecs multimediali tuttora utilizzati. Vuole essere semplicemente un riferimento per la parte II della tesi, in cui come già detto, si relazionerà su applicazioni multimediali e sul loro utilizzo nellintento di costruire una architettura di streaming funzionante. E parsa allora scontata in questa sezione, la necessità di focalizzare lattenzione in particolare sui codec prodotti dal Motion Picture Expert Group (MPEG), che, per diffusione, completezza e affidabilità rappresentano il principale frutto di quella standardizzazione tanto ricercata. Non ci si scandalizzi quindi per la mancanza assoluta di riferimenti ad altri codecs e formati ed in particolare a quelli prodotti dal ITU-T (lintera famiglia H.xxx ), la maggior parte dei quali, sono rivolti ad applicazioni di diversa natura dal target della presente tesi.
III.2 Principi di audio compressione
La compressione del segnale audio usa naturalmente tecniche molto diverse da quelle della video compressione, ma di sicuro affronta delle tematiche concettualmente più semplici. Nella codifica audio si è essenzialmente alla ricerca di metodi che permettano di trasformare il segnale in una rappresentazione che modelli in modo conciso la sorgente e di costruire un modello psicoacustico, che fornisca un'approssimazione del meccanismo di percezione dell'orecchio umano.
Questi due elementi determinano lentità della ridondanza eliminabile dal segnale e quindi l'ammontare del data-rate necessario al processo di codifica.
La voce è chiaramente più semplice da codificare poiché tale operazione prevede lestrazione di pochi parametri vocali, mentre la musica presenta più problemi in fase di codifica, essendo più difficile ottenere una modellizzazione di tutte le possibili sorgenti sonore. Si pensi ad esempio alla diversità sonora tra i diversi generi musicali.
La codifica [1] generalmente ha inizio con una conversione tempo/frequenza attraverso un banco di filtri tempo varianti, in modo da evitare la propagazione di errori di quantizzazione ed eliminare i segnali non udibili: può infatti accadere che un segnale forte ne mascheri un altro più debole se questi si presentano in sequenza o contemporaneamente. Per quel che concerne il bit rate, cè da dire che anche se esistono canali e reti a velocità elevata a costi contenuti, la codifica a basso bit-rate dei segnali audio ha mantenuto la sua importanza. I motivi sono diversi e tutti legati alla riduzione dei costi ed all'aumento dell'efficienza. La cosa più importante sarà comunque mantenere una qualità elevata del segnale ricostruito, una robustezza alle variazioni nel contenuto spettrale e nelle ampiezze e una bassa complessità di sistema complessiva.
Codificare la voce, piuttosto che un generico segnale audio, è più semplice e dà migliori risultati in termini di rapporto di compressione, perché sono disponibili i modelli matematici e fisici di produzione della voce. Inoltre, lo spettro e il range dinamico della voce sono molto più ristretti di quelli di un normale brano musicale. In un qualsiasi segnale audio, invece, non si può sfruttare la dipendenza statistica tra i campioni di suono così come accade per la voce, per cui si sono scelti diversi approcci al problema, tra di loro combinabili.
Si utilizzerà allora la Adaptive Differential Pulse Code Modulation, diretta conseguenza della classica PCM, tesa a sfruttare oltre alla dinamica del segnale anche le sue caratteristiche statistiche, quali la correlazione tra i campioni; si quantizzerà soltanto la differenza tra il campione predetto e il campione vero, con un notevole risparmio di bit poiché la dinamica dei segnali differenza è molto più piccola e quindi è rappresentabile con la stessa precisione. In fase di decodifica si opererà la dequantizzazione dell'informazione differenza che, grazie alla memoria del sistema, fornirà la predizione del campione attuale.
Altra tecnica utilizzata sarà la codifica percettiva, con cui si sfruttano nozioni sulla percezione acustica, con lobiettivo di ricostruire solo il segnale udibile dall'orecchio umano. Si rimuoveranno allora le componenti ridondanti, derivanti dalla correlazione tra i campioni e le parti che l'orecchio non può distinguere correttamente, sia in termini di ampiezza che di frequenza. E importante ricordare, infatti, alcune proprietà di mascheramento delludito umano.
Lorecchio percepisce bene solo in determinate bande critiche comportandosi quindi come un banco di filtri passabasso, inoltre un segnale debole non può essere percepito da un segnale più forte quando i due segnali siano più vicini della risoluzione in frequenza dell'udito umano. Esiste pertanto una soglia di mascheramento, sotto la quale i segnali non sono percepibili. Tale effetto di mascheramento avviene non solo in frequenza ma anche in tempo, quando ci sarà una rapida successione di suoni deboli e forti; il suono forte sovrasterà il più debole, anche se questultimo si manifesterà prima. Ciò è dovuto alla minima risoluzione temporale dell'orecchio umano, sotto la quale non si riescono a distinguere due suoni, portando inevitabilmente a percepire dei due solo il più forte.
III.2.2.3 Codifica di frequenza
Infine è bene citare anche la codifica di frequenza, con cui si sfrutta la capacità di eliminare la parti ridondanti e irrilevanti del segnale PCM, separando questultimo in sottobande e quantizzandole separatamente.
III.3 Principi di video compressione
Un'immagine grafica viene solitamente interpretata come un insieme di pixel, a ciascuno dei quali è associato un colore che viene espresso mediante tre componenti fondamentali, il Rosso, il Verde ed il Blu, comunemente indicate con la sigla "RGB". È stato tuttavia dimostrato, attraverso considerazioni statistiche, che tali componenti presentano informazioni ridondanti, caratteristica questa, poco favorevole per una compressione efficiente; ciò ha portato ad effettuare una trasformazione delle componenti RGB, in un gruppo di componenti con basso grado di correlazione. Si giunge così, tramite un'opportuna matrice di conversione, a disporre delle cosiddette componenti "YUV" che presentano le caratteristiche ricercate. La componente Y rappresenta l'immagine in versione a tonalità di grigi, e prende il nome di luminanza, mentre le altre due componenti vengono indicate con il nome di crominanze, e contengono l'informazione sul colore. Ad esempio lo standard televisivo PAL (Phase Alternate Line) utilizza la seguente matrice di conversione:
Y=0.3R+0.59G+0.11B
U=0.493(B-Y)
V=0.877(R-Y)
Tra le diverse componenti, è la luminanza a contenere la maggior parte di informazione dell'immagine, a differenza delle crominanze, quindi è opportuno che la sola componente Y debba essere adeguatamente ed interamente trasmessa, lasciando di fatto alle altre due componenti leffetto predominante della compressione, accettando anche la perdita d'informazione.
Le tecniche di riduzione dei dati e della compressione degli stessi sono svariate e ciascuna metodologia è contraddistinta da un diverso livello di ottimizzazione. Alcune di queste metodologie infatti, fanno uso della ridondanza dei dati e questo permette da un lato una migliore ricostruibilità dell'immagine, rinunciando però ad un buon rapporto di compressione.
Si potrebbe oppure sfruttare le caratteristiche psico-visuali del sistema visivo umano, al fine di ottenere un altissimo rapporto di compressione dei dati a scapito di unimmagine numericamente degradata ma di qualità visiva pienamente accettabile.
Grande importanza allora in questo contesto riveste il concetto di ridondanza: guardando una comune sequenza televisiva ad esempio, si può facilmente notare come essa sia costituita essenzialmente da una grande quantità di elementi ricorrenti. Si parlerà in termini di ridondanza spaziale e di ridondanza temporale.
La prima, ha luogo all'interno di un singolo quadro dell'immagine televisiva e la compressione ottenibile viene indicata con il termine di compressione intra-frame. Per essa si sfrutta un principio molto semplice: considerando un immagine di cui una grossa porzione sia costituita dallo stesso colore di fondo e dalla stessa luminosità, si può ben sostenere che all'interno di questa area gli elementi adiacenti della figura siano spazialmente correlati tra loro. Lidea è allora di ricreare l'intera figura trasmettendo non tutti i dati relativi a ciascuna linea di colore omogeneo, ma inviando un codice di testa di pochi bit che descriva la situazione per il primo pixel e quindi le informazioni di ordine temporale descriventi quante volte deve essere duplicata questa situazione lungo la stessa linea.
La ridondanza temporale, invece, ha luogo tra quadri adiacenti e la compressione così ottenibile è definita compressione inter-frame. Anchessa, si basa su semplici considerazioni: avendo a che fare con immagini piuttosto statiche, è praticamente inutile trasmettere le identiche informazioni 25/30 volte al secondo, mentre sarebbe più sensato, al fine di minimizzare la quantità di dati da trasferire, trasmettere solamente le variazioni occorse tra il quadro attuale ed il successivo. Tale metodologia introduce però non pochi problemi; qualora infatti un immagine presenti una limitata sezione in cui vi sia un repentino movimento, questa si presenterà inevitabilmente corrotta in fase di riproduzione. Inoltre potrebbe accadere che unalterazione dellimmagine, si propaghi di frame in frame fino a quando la scena in questione non cambi radicalmente.
III.3.3 Compressione di immagini statiche
III.3.3.1 Codifiche utilizzate
Negli algoritmi di compressione e codifica delle singole immagini, due sono fondamentalmente le tecniche utilizzate. La prima prende il nome di codifica a sottobande, la quale mira a ridurre la ridondanza spaziale sfruttando la non uniforme distribuzione delle immagini nel dominio della frequenza. La seconda tecnica di codifica è conosciuta con il nome di DCT (Discrete Cosine Transform) che viene utilizzata in particolar modo nella compressione delle immagini statiche JPEG.
III.3.3.2 Differenze tra metodi di codifica
La differenza sostanziale tra le due tecniche di codifica sta nel fatto che la codifica a trasformate è rigorosamente locale, in quanto ogni blocco può essere trasformato e successivamente quantizzato in maniera indipendente dai blocchi vicini. La proprietà di località ha una conseguenza molto importante. Infatti, è possibile utilizzare all'interno di ogni blocco della stessa immagine algoritmi differenti scegliendo ogni volta quello più conveniente. Una seconda differenza sta nel fatto che eventuali errori di quantizzazione vengono confinati all'interno dei singoli blocchetti nel caso di codifica DCT, provocando l'effetto di blocchettizzazione, caratteristica negativa di tale metodo.
III.3.3.3 Quantizzazione e compressione entropica
Il passo intermedio per la codifica sarà la quantizzazione, in modo da codificare i segnali in campioni associati all'immagine nel tempo e nella frequenza scegliendo opportunamente il quantizzatore più adeguato a garantire la più alta possibile correlazione tra i vari coefficienti. Infine, con la fase di codifica entropica, ci sarà la compressione della rappresentazione dei coefficienti che sono stati calcolati successivamente al processo di quantizzazione.
III.3.4 Compressione di immagini in movimento
Lidea di partenza per tale processo sarà la conversione del segnale video grezzo di singole immagini, in un formato tipo il JPEG, utilizzando i metodi sopra citati. Se però si vuole ottenere un'elevata compressione, non è pensabile che le immagini componenti la sequenza video siano codificate ognuna in modo indipendente dalle altre. Si realizza, allora, una codifica in cui vengono mantenute alcune immagini codificate in maniera indipendente, quindi poco compresse, ma che garantiscono la possibilità di accesso casuale; le restanti immagini vengono ricavate da queste attraverso una predizione del moto, oppure mediante interpolazione tra più immagini.
Lidea basilare è allora quella di trasmettere non lintero set di frame opportunamente codificati individualmente ma, soltanto una selezione di essi in questa forma; per tutti gli altri, sono inviate soltanto le differenze tra i contenuti del frame attuale e quelli del frame predetto. Si parlerà allora in termini di "stima del movimento" (motion estimation) per indicare la suddetta tecnica e poiché saranno inviate anche informazioni aggiuntive relative alle differenze tra segmenti in movimento nei frame attuali e predetti, si utilizzerà una "compensazione del movimento" (motion compensation). Di entrambe si parlerà ampiamente in seguito.
Vediamo allora in dettaglio i diversi tipi di frames utilizzati: frames di tipo intra (I), frames predetti (P) e frames interpolati bi-direzionalmente (B) [1] [3]. Gli I-frames sono codificati in maniera a sé stante, senza far riferimento a immagini precedenti; forniscono i punti per l'accesso casuale, ma consentono una modesta compressione. Gli P-frames sono codificati in riferimento ad immagini passate di tipo I o P stesso e possono essere quindi utilizzati come riferimento per frame di tipo P futuri, oppure per frame di tipo B passati o futuri come si evince dalla figura III.4.
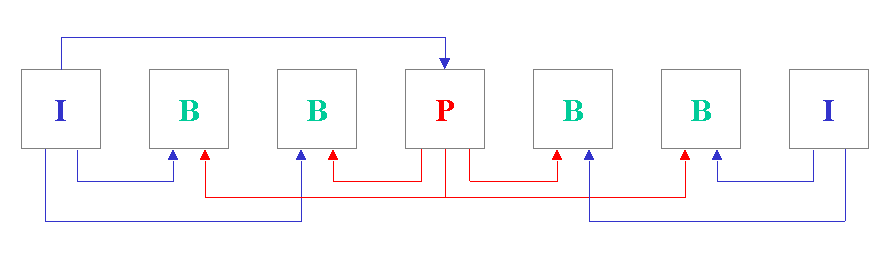
Figura III.4 Frames I/P/B
Le immagini di tipo B richiedono quindi un riferimento sia nel passato sia nel futuro, ma consentono un elevato livello di compressione. E ovvio che, poiché i frame predetti e quelli bidirezionali comunque dipendono dal frame I originale, se questultimo fosse corrotto, ci sarebbe una rapida propagazione dellerrore, andando a pregiudicare la qualità di una intera scena. Sarà necessario allora, che i frame I siano inseriti frequentemente nel flusso di output; il numero di frames tra due successivi frame I è conosciuto col nome di "group of pictures" (GOP), ed il suo valore sarà compreso tra un minimo di 3 ed un massimo di 12. Non si dimentichi tra laltro che, i frames P, sono codificati utilizzando una combinazione di stima del movimento e di compensazione dello stesso; per tale motivo, essi saranno inevitabilmente affetti da errore, che si propagherà nella sequenza. Per controllare tale effetto si introduce un secondo indice, il "prediction span", rappresentante il numero di frames tra un frame P e il precedente I o P frame.
III.3.4.3 Trasmissione dei frames
E bene ricordare che i frames B, poiché a differenza degli altri da loro non dipenderanno altri frames, non rappresentano un veicolo di propagazione di errore; hanno però lo svantaggio di aumentare il ritardo per la loro elaborazione poiché bisogna attendere necessariamente il prossimo I-P frame. Quando arriva infatti un frame B, esso è prima decodificato e la risultante informazione assieme a quelle dei precedenti I-P (che per lo scopo sono stati memorizzati) e dei seguenti I-P (che arriveranno dopo) servirà per derivarne i contenuti. Per minimizzare il tempo richiesto allora, lordine in trasmissione viene cambiato, ossia, si fa in modo che quando arriva un frame B, già siano presenti i frame I-P precedenti e I-P seguenti come si evince da figura III.5.
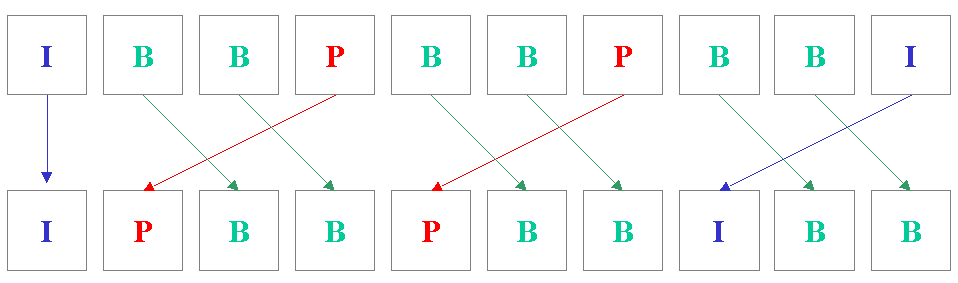
Figura III.5 Ordine di trasmissione dei frames
III.3.4.4 Stima e compensazione del movimento
Nell'ambito della trasmissione di immagini in movimento, la tecnica di compressione più utilizzata è la compensazione del movimento in cui come ipotesi fondamentale si considera localmente l'immagine corrente come una traslazione di un'immagine che la precedeva nel tempo. Questo non significa che necessariamente la stessa traslazione si debba seguire nella stessa misura in tutte le zone dell'immagine considerata.
III.3.4.4.1 Macroblocchi e vettori del movimento
L'immagine corrente viene suddivisa in blocchi di piccola dimensione: solitamente 8x8 pixel o, nel caso di MPEG, 16x16 pixel, definiti col nome di macroblocchi.
Per ogni blocco si cerca di stimare un vettore di movimento il quale indica come un blocco debba cambiare la propria posizione nel passaggio da un'immagine alla successiva; la regione puntata dal vettore di movimento nell'immagine precedente costituisce la predizione del blocco corrente. Il metodo più utilizzato per il calcolo della stima dei vettori di movimento ha il nome di block matching. Questo utilizza un metodo esaustivo per la determinazione del vettore appropriato all'interno di una certa area di ricerca (in termini statistici quello che si vuole è il vettore in grado di minimizzare la varianza dell'errore di predizione), cioè vengono provati tutti i possibili vettori di movimento selezionando quello che rimane al di sotto di una certa soglia di errore.
Nel caso in cui non venga selezionato nessun vettore di movimento, allora significa che non ne esiste uno che rimane al di sotto di una certa soglia di errore, ed in questo caso si preferisce trasmettere l'intero blocco originale.
III.3.4.4.2 Compressione inter - intra
La compensazione del movimento è un classico esempio di compressione di tipo inter, dove cioè si sfrutta la correlazione temporale con il fotogramma precedente. E' chiaro, però, che non è possibile continuare a trasmettere solamente differenze di immagini; infatti si rischierebbe una perdita di allineamento tra le diverse immagini in movimento. Per ovviare a questo inconveniente, come detto, si prevede sempre l'inserimento di un quadro di tipo intra ogni 10 o 15 quadri (quindi circa due volte al secondo per un frame rate di 25 fps).
III.3.4.4.3 Schema di predizione dei frames
L'idea alla base di questa tecnica di compressione
[2] sta nel trasmettere i vettori di movimento relativi ai singoli blocchi, piuttosto che trasmettere i blocchetti stessi. Quindi, ricapitolando, dal confronto di un precedente frame con quello attuale, si ricavano i vettori di movimento; a partire da essi, sempre con il frame precedente, si costruisce il frame predetto, che sottratto al frame attuale, dà luogo ad un errore di predizione. Questultimo sarà trasmesso assieme ai vettori del movimento e sarà necessario per compensare lerrore dovuto alla stima sulla predizione.Il principio di funzionamento di un sistema di compressione è raffigurato in figura III.6 in cui si fa riferimento anche al lato ricezione, dove, con i vettori di movimento e limmagine precedente si costruisce il frame predetto, il quale, sommato allerrore di predizione, fornisce limmagine attuale.
L'obiettivo della compressione non è comunque calcolare correttamente il modulo e la direzione del vettore di movimento, ma più semplicemente fornire dei blocchi tali da poter essere trasmessi con il minor numero di bit possibile.
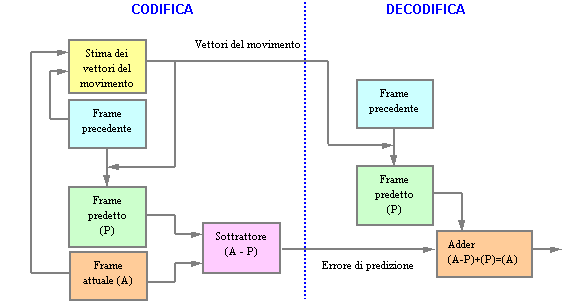
Figura III.6 Predizione dei frames
Da notare che, se si codifica linformazione del vettore di movimento con più dati, lerrore di predizione sarà più piccolo e quindi potrà avere dati più "leggeri", viceversa avere un errore di predizione grande (più dati) significa avere vettori di movimento con poche informazioni, quindi con pochi dati. Il giusto compromesso allora viene trovato proprio suddividendo in blocchi di 16X16 pixels limmagine da codificare.
III.4.1.1 Microsoft Wave (wav)
E il formato proprietario della Microsoft e certamente il più utilizzato. Questa sua diffusione dipende da aspetti commerciali e dal fatto che è il più supportato tra i suoi concorrenti. Possiede varie compressioni ed è un formato versatile ed altamente editabile e per questo è indicato per il digital video in generale, sia per il Multimedia Publishing sia per DeskTop Video.
III.4.1.2 MPEG-1 Audio Layer 3 (mp3)
Formato derivante dall'algoritmo di compressione video MPEG applicato all'audio di cui se ne discuterà nei prossimi paragrafi. Si ottengono buoni risultati, soprattutto se si prediligono le ridotte dimensioni ad un alta qualità di riproduzione. E' ormai standard audio affermato la versione MPEG layer 3 con la quale si ottengono file ridottissimi ed una ottima qualità, ottimo compromesso per la duplicazione e la creazione di file audio su CD. I software che lo gestiscono sia in codifica che in riproduzione sono innumerevoli e largamente diffusi.
III.4.1.3 Real Media Audio (rm, ra)
Formato, diventato ormai standard, per lo streaming audio/video, molto diffuso sul WWW. Concepito inizialmente per l'audio (RealAudio sino alla versione 3), questo formato è stato adattato anche per la compressione video, diventando un vero e proprio pacchetto per la creazione e la distribuzione del multimedia sul web. La qualità audio raggiunta è eccezionale (16bit, 44KHz, Stereo) in rapporto alla compressione ottenuta (10:1).
III.4.1.4 Microsoft NetShow (asf)
Estensione audio del formato NetShow per lo streaming video sul web.
Introdotto da Microsoft, lAudio Video Interleaved è un formato molto diffuso e multipurpose, supportante la stragrande maggioranza dei codecs di compressione in circolazione, quali SuperMac Cinepak , Intel Indeo , M-Jpeg e DivX tra i più noti. E' perfetto per lavori di varia natura, sia per la quantità e la versatilità dei codecs supportati ma soprattutto per la compatibilità praticamente assoluta con software per l'editing non lineare. Ha però molti svantaggi conosciuti oltre a manifestare incapacità nella gestione dello streaming. Supporta un flusso video e da 0 a 99 flussi audio. Può essere grande fino a 2Gb. Attualmente ci sono due tipi di file AVI:
III.4.2.2 Apple Quick Time File MOV
Formato proprietario della Apple [21] e principale estensione multimediale del Sistema Operativo "Mac"; Nelle applicazioni dedicate alla multimedialità, esso integra diversi tipi di dato, come audio video e animazioni, in modo dinamico, su base temporale, associando ad essi una descrizione del media trasportato, chiamato movie, contenente informazioni sul timing, sul numero di tracce e sulla locazione di memoria su cui salvare i dati. Gli algoritmi di compressione presenti in QuickTime sono di varia natura e scopo; i principali sono il Jpeg (photo compressor), il video compressor, il Sorenson Video, di cui è proprietario Apple, l'animation compressor dedicato alla grafica e alle animazioni generate al computer e per laudio lmp3. Da notare che il Gruppo MPEG4 ha scelto QuickTime come formato file raccomandato per il codec MPEG4; ciò ha portato alla oramai diffusa sostituzione dellestensione "mov" in "mpg" o "mp4".
Formato che si avvale dellalgoritmo di compressione MPEG, sviluppato dal Moving Picture Expert Group. Esso si presenta in diverse forme quali il MPG, versione base, contenente video in codifica MPEG1, il DAT, come il precedente ma con diversa estensione, usato in particolare nei video CD e lMPEG-2, formato divenuto oramai standard per produzioni di tipo broadcast ma con necessità di essere supportato da hardware potenti per la cattura e compressione. Non è uno standard di fruizione di massa proprio per le sue esose richieste hardware ma, raccoglie ugualmente utenti grazie alle televisioni, ai canali satellitari e ai recenti DVD. Una caratteristica importante di tali files è lavere un campo ben preciso per descrivere le proporzioni del flusso video che contengono, in modo che essa si possa ben conservare in fase di riproduzione.
III.4.2.4 RealMedia Audio/Video
Formato, molto diffuso per lo streaming audio/video sul WWW, nato per supportare le applicazioni prodotte da Real Networks, quali, in particolare, il Real Player. Concepito inizialmente per l'audio (RealAudio sino alla versione 3), questo formato è stato adattato anche per la compressione video, diventando un vero e proprio pacchetto per la creazione e la distribuzione del multimedia sul web. Si deve però tener conto di numerosi problemi di adattabilità e alle limitate capacità dei sistemi che adottano tale formato. La qualità e la fluidità che si ottengono dipenderanno sensibilmente dalla macchina di riproduzione, dai settaggi di compilazione, dal soggetto del filmato e soprattutto dalla larghezza di banda disponibile. Altro problema riguarda lassoluta incompatibilità di questo formato con la grande maggioranza dei players e server per lo streaming tuttora in circolazione; Il suo largo uso infatti, è giustificato esclusivamente dalla vasta diffusione del Real Player come riproduttore multimediale multipiattaforma.
III.4.2.5 Microsoft NetShow (ASF)
Lactive streaming format, è stato prodotto con lintento di creare un formato con ottime caratteristiche a livello di rapporto qualità/dimensioni per lo streaming; tuttora ne esistono due varianti di cui una compatibile con i lettori multimediali di Microsoft e completamente chiusa e laltra, pubblica e registrata di cui però non cè traccia!
Nasce nel novembre del 1992; opera a 3 frequenze di campionamento (32, 44.1 e 48 kHz) e utilizza uno o due canali. Ha quattro modi di funzionamento: mono, dual-mono, stereo e joint-stereo ed è strutturato in 3 livelli (Layers), a seconda delle caratteristiche del modello di quantizzazione e codifica dei campioni audio. Questi necessitano di bit-rate differenti per essere in grado di fornire audio con qualità soggettiva paragonabile a quella del CD (PCM, 16 bit, 44.1 kHz, stereo 1.41Mb/s + overhead = 4.32 Mb/s):
Layer 1, 2, 3 sono livelli perché il codificatore/decodificatore di livello più elevato incorpora quello di strato inferiore.
Codec sviluppato a partire dal 1994; esso aggiunge alle 3 frequenze di campionamento usate da MPEG-1 AUDIO altre tre frequenze (16, 22.05 e 24kHz) ed è in grado di utilizzare fino a 5 canali hi-fi, più un canale a bassa frequenza (adatto per Home Theater, Cinema, ...) e fino a 7 canali di commento (multilingua). Ve ne sono 2 versioni: una compatibile con MPEG-1, cui fa capo anche il Layer3 mp3, ed una non compatibile. Di quest'ultima categoria va citato il MPEG2-AAC (Advanced Audio Coding) [1], standardizzato nell'aprile del 1997 che consente inoltre di dimezzare il bit-rate dell'audio e le dimensioni del file rispetto alla codifica mp3. Ciò naturalmente significa ridurre notevolmente i tempi necessari ad un possibile download oltre a poter fare streaming utilizzando una larghezza di banda minore. Lo standard offre un audio di altissima qualità potendo utilizzare da 1 fino a 48 canali e frequenze di campionamento da 8 a 96kHz. AAC lavora a bit-rates da 8kbps per un segnale vocale monofonico fino a più di 160kbps per canale per codifica di altissima qualità permettendo molteplici cicli di codifica/decodifica.
Standardizzato nel 98, è stato costruito sul blocco base MPEG-2-AAC che consente bit-rate anche di soli 2kbps. Esso si basa sui cosiddetti oggetti; un oggetto audio può essere definito come un'entità udibile (la voce di uno o più parlatori, uno o più strumenti musicali, ecc.), può essere quindi registrato con l'uso di un microfono nel caso di una registrazione mono o con più microfoni, in differenti posizioni, nel caso di registrazione multi-canale. Oggetti audio possono essere raggruppati, ma non possono essere facilmente divisi in sotto-oggetti. I principali oggetti audio definiti in MPEG-4 sono:
Esempi di funzionalità sono il controllo di velocità (senza pitch shift), il cambio di pitch, capacità di recupero degli errori e scalabilità. Di questultima sono definiti diversi tipi:
Un'altra funzionalità molto importante è la robustezza agli errori fornita dall'abilità del decoder di evitare distorsioni udibili causate da errori di trasmissione.
Standard per il supporto di applicazioni video multimediali di qualità VHS con un bit rate fino a 1.5Mbps ed una risoluzione video fino a 352x288 pixels basata sul "source intermediate format" (SIF) [2]. Trascurando considerazioni sulla compressione della traccia audio, si può immaginare di spendere circa 256 Kbits/s per l'audio, circa 100 Kbits/s per lo stream di sistema, rimanendo circa 1.15 Mbps per lo stream di dati video. La quantità di bit proveniente dal video è di circa 18Mbps (320 pixel/linea x 240 linee x 30 field x 8 bit) per linformazione di luminanza, 9Mbps (320 pixel/linea x 120 linee x 30 field x 8 bit) per la componente U di crominanza e 9Mbps (320 pixel/linea x 120 linee x 30 field x 8 bit) per la componente V di crominanza.
La compressione video da raggiungere è circa 30:1, decisamente ragguardevole, ma le differenze tra il video originale e lo stream codificato sono percepibili solo minimamente.
Lo schema basilare per la codifica MPEG-1 è quello di predire il movimento da frame a frame nella direzione del tempo e quindi di utilizzare la DCT, per controllare la risoluzione spaziale. Le trasformate sono fatte su macroblocchi di 8x8 pixels e la predizione del moto è fatta sul canale di luminanza (Y) su macroblocchi di 16x16 pixels. Quindi dato un blocco di 16x16 pixels nel frame corrente che si vuole codificare, si cerca di determinare una stima quanto più realistica possibile basandosi sul contenuto dello stesso blocco ma di un frame precedente o addirittura futuro. Successivamente, lalgoritmo opera sui vari blocchi, seguendo questi tre passi: calcolo dei coefficienti DCT, ottenendo un blocco nel dominio trasformato; quantizzazione dei coefficienti trasformati; riorganizzazione dei dati in un ordine a zig-zag e conversione dei coefficienti trasformati in coppie {numero, ampiezza}. Per comodità di analisi, comunque, si preferisce parlare in termini di slices, ossia di un insieme finito di macroblocchi, in genere contigui, piuttosto che far riferimento al singolo blocco.
La quantizzazione è il passo che può essere utilizzato per adattare il bit rate di uscita del codificatore alla capacità del canale. Lo standard specifica soltanto come rappresentare nel bitstream le scelte fatte per la quantizzazione e non il modo in cui queste scelte vengono effettuate; queste ultime vengono lasciate al produttore ed è qui che si crea la competizione tra le varie industrie per trovare il miglior sistema che, a parità di bit rate, fornisca la migliore qualità dell'immagine. La quantizzazione adattativa è il metodo chiave con il quale ottenere un passo di quantizzazione che generi la massima compressione con minor perdita di qualità possibile. Si deve tenere presente che i blocchi codificati intra sono quantizzati in modo diverso rispetto ai blocchi codificati con predizione in quanto, mentre i primi contengono energia a tutte le frequenze, il segnale errore di predizione contiene principalmente componenti in alta frequenza.
La sequenza tipica dei frames è:
IBBPBBPBBPBBIBBPBBP ossia con 12 frames compresi tra due I successivi, anche se, come già visto, la sequenza in trasmissione sarà diversa. In questo modo, in ricezione, bisognerà decodificare i primi I e P frames, metterli in memoria per poi decodificare i due frames B.
Di notevole interesse è infine lo studio della struttura del pacchetto MPEG-1. Naturalmente, si parte dalla sequenza di GOP, ciascuno dei quali sarà costituita da campi di intestazione, per garantire la sincronizzazione, seguiti dalla stringa di frames I, P o B. A sua volta, ciascun frame, sarà costituito da headers, in cui saranno contenute le informazioni di sincronizzazione della sotto trama, i parametri della codifica e lindicazione del tipo di frame in questione (I,P,B), più un fissato numero di slices, ciascuno delle quali verrà mappata in una ulteriore sotto trama. In questultima, ci sarà un header per la sincronizzazione di detta sotto trama, un indicatore della posizione verticale della slice codificata nel quadro, alcuni parametri di quantizzazione, a cui di seguito farà capo la sequenza di macroblocchi costituenti quel dato slice.
Lo stesso numero di macroblocchi sarà presente per ogni slice. Per quel che concerne la pacchettizzazione della trama video MPEG-1 nel flusso RTP, è da sottolineare che tale operazione avviene in maniera assolutamente trasparente per i dati codificati; nelle specifiche [14] si pone laccento sulla necessità di mappare un frame in almeno un pacchetto RTP, evitando quindi di trasportare più frames in un pacchetto. Gli headers del RTP indicheranno il tipo di video trasportato (in questo caso MPEG-1 nel campo Payload Type), il tempo di presentazione del frame video (timestamp) e se è trasportato un intero frame o lultima porzione di esso (Mark) dato che, come detto, un frame può essere dilazionato in più pacchetti. In questultimo caso, ci sarà una sequenza di pacchetti RTP non marcati con stesso timestamp, cui seguirà un pacchetto marcato ad indicare il termine di detto frame.
Standard definito essenzialmente per la registrazione e trasmissione di audio e video con qualità e prestazioni diverse. L'applicazione primaria è la trasmissione a qualità televisiva con un bitrate tra 3 e 10 Mbps, ma successivamente si è visto che la sintassi del MPEG-2 può essere efficiente anche per applicazioni che richiedono un bitrate maggiore come ad esempio nella TV ad alta definizione (HDTV).
Essa ridefinisce ed estende le potenti capacità di compressione video già note nello standard MPEG-1, per offrire una più ampia gamma di tools per la codifica. Questi sono stati raggruppati in cinque profili di livello gerarchico, per offrire differenti funzionalità. Distingueremo allora il profilo "high" in cui si utilizza una rappresentazione di tipo YUV 4:2:2 (ossia 4 bit per la luminanza, 2 per ciascuna componente di crominanza), quello "spatial scalable" con rappresentazione YUV 4:0:0, il "snr scalable" con YUV 4:2:0, il "main" , con algoritmi di codifica non scalabili supportanti la funzionalità per la codifica di video interfacciato e per l'accesso casuale (rappresentazione YUV 4:2:0) ed infine il profilo "simple", di livello più basso, non supportante la predizione delle immagini B e utilizzante una rappresentazione YUV 4:2:0.
Per la pacchettizzazione, MPEG-2 segue le stesse regole generali del MPEG-1, sia in termini di struttura di trama, sia in termini di costruzione del pacchetto RTP.
Mpeg 4 è stato presentato nel novembre 1998 come standard per applicazioni e servizi multimediali con possibilità di interazione con gli stessi, su reti di diversa natura quali lInternet, la comune PSTN o network wireless in generale, compresa la stessa rete di telefonia mobile. Con il suo sviluppo si è cercato di creare finalmente uno standard studiato per le stringenti caratteristiche della rete, non a caso infatti esso nasce per il supporto di applicazioni multimediali a bit rate molto basso, anche di pochi kbps, anche con bassa risoluzione spaziale.
Lidea di base è stata quella di permettere ad un utente non solo di accedere ad una sequenza, ma anche di manipolare gli elementi che danno luogo ad ogni singola scena della sequenza stessa. LMPEG-4, infatti, ha prestazioni così fondamentalmente diverse dagli altri codec, proprio poiché è strutturato su funzionalità di tipo "content-based" [4] [24].
III.5.2.3.1 Oggetti audio-visuali
Il punto di partenza è quello di dividere e rappresentare ciascuna scena sotto forma di oggetti audio-visuali (media object), ciascuno dei quali sarà trattato come una entità a se stante e la cui natura potrà essere sia naturale, sia sintetica, quindi generata tramite computer. Ad esempio, se limmagine sarà costituita da un parlatore i cui movimenti siano limitati alla sola bocca e agli occhi, essa potrà essere scomposta in tre oggetti principali, la testa, la bocca e gli occhi. Successivamente alla identificazione degli oggetti, ci sarà la necessità di doverli descrivere, quindi tenere nota delle caratteristiche di ciascun oggetto per poi utilizzarle in fase di decodifica e riproduzione.
Infine bisognerà multiplexare e sincronizzare i dati associati con gli oggetti così che, essi possano essere trasportati in rete garantendo una QoS appropriata alla natura delloggetto specifico e possano bene interagire con lintera scena generata in lato ricezione.
E stato detto che una scena audio-visuale MPEG-4 è composta di vari media objects; questi sono organizzati secondo una struttura gerarchica ad albero, le cui foglie possono essere immagini statiche, come ad esempio uno sfondo, oggetti video, quale può essere ad esempio una persona o una automobile ed oggetti audio, rappresentati dalla voce di detta persona o dai suoni di fondo. Nel solo ambito visuale, si parlerà allora in termini di VOPs (Visual Object Planes), ciascuno dei quali si riferirà ad un oggetto distinto e come tali verranno codificati separatamente e indipendentemente basandosi sulla loro forma, sul proprio movimento e sulla propria struttura.
Quindi invece di parlare di I/P/B frame si parlerà più precisamente di VOP I/P/B, ciascuno dei quali allora sarà trattato e codificato come se fosse un frame a se stante [2]. Le tecniche usate per la codifica di ciascun VOP, in particolare del proprio movimento e della tessitura, saranno le stesse viste nelle sezioni precedenti, in particolare nellambito MPEG, ma che in questo contesto verranno esaltate nella propria funzionalità. Ciò perché, dividendo limmagine in oggetti, in generale le porzioni di aree statiche saranno ben numerose rispetto a quelle in cui si evidenziano dei VOPs di soggetti in movimento; i dati da codificare per gli sfondi, ad esempio, saranno non così ricchi di informazioni, mentre quelli degli altri VOPs, saranno relativi come detto ad aree molto piccole, quindi potranno supportare tranquillamente un basso bit rate. E ovvio che, in fase di compressione, laspetto più delicato sarà lidentificazione dei VOPs, a cui si arriverà basandosi su considerazioni posizionali, di tessitura e luminosità tra i pixel che mostrano similitudini in dette caratteristiche.
Successivamente si dovrà, come detto, descrivere ed anche poter modificare gli oggetti; il linguaggio utilizzato per tale fine è il BIFS , binary format for scenes, con il quale si potrà editare su un oggetto, cambiare la sua forma e apparenza o addirittura animarlo, inoltre, si potranno avere diverse versioni codificate di uno stesso oggetto, in modo che i contenuti siano trasmessi con un rate e riprodotti con una risoluzione compatibili con le caratteristiche interattive del terminale in uso [1].
Altra informazione fondamentale da conservare necessariamente sarà la descrizione della scena, ossia il modo in cui ciascun oggetto è in relazione con gli altri nel contesto di un intera scena.
III.5.2.3.4 Elementary e Transport streams
Da sottolineare che, in ambito streaming, a ciascun VOP codificato sarà associato uno stream al quale si affiancheranno oltre ai flussi relativi agli altri VOPs anche lo stream contenente le informazioni di descrizione. Ciascuno di tali flussi viene definito come un elementary stream (ES) con i quali poi, dopo opportuna multiplazione, si otterrà un unico transport stream (TS), che verrà in seguito trasmesso nella rete.
In lato ricezione ovviamente le operazioni verranno effettuate in ordine inverso, quindi dalla demultiplazione del transport stream si otterranno gli elementary stream.
Anche per MPEG-4, le nozioni di pacchettizzazione precedentemente citate nel contesto MPEG-1/-2, rimangono del tutto valide, con la sola differenza che è stato ideato un meccanismo più efficiente per evitare pesanti effetti dovuti ad errori di trasmissione. Si è detto, infatti, che nella trama video si evidenzia ad un determinato sottolivello di stratificazione della stessa, una sequenza di slices, ciascuno delle quali contiene una stringa di macroblocchi e necessariamente un marcatore di risincronizzazione, in modo da riuscire ad individuare linizio di un nuovo slice, qualora in quello corrente si fosse riscontrato un errore. In questo modo però, un errore relativo ad un solo macroblocco della slice, determina lo scarto e quindi linutilizzo di tutti gli altri macroblocchi della slice.
Il grosso problema della pacchettizzazione MPEG-1/-2 è da ricercarsi nella variabilità di lunghezza delle slices; se allora, in una sequenza, ci fosse una slice molto più lunga delle altre (poiché eventualmente nellarea scansionata ci sono più informazioni di movimento), è più probabile che un errore nella trasmissione corrompa detta slice, pregiudicando notevolmente la riproduzione in seguito al suo scartamento.
Per evitare questo problema, in MPEG-4 si è deciso allora di utilizzare in luogo di slices contenenti uno stesso numero di macroblocchi, dei video packets, contenenti uno stesso numero di bit e separati tra loro da marcatori di sincronizzazione. Ciascun video packet, conterrà anche lindicazione del macroblocco di riferimento, parametri di quantizzazione, vettori di movimento e informazioni DCT del macroblocco. Da notare che in questo modo, qualora si dovesse trasmettere una slice molto lunga e quindi anche preziosa dal punto di vista dei contenuti, le stesse informazioni da essa trasportate sarebbero suddivise tra tanti video packets; se un errore di trasmissione dovesse avvenire, esso affetterà soltanto un video packet e quindi un solo macroblocco, con ovvi miglioramenti in riproduzione rispetto al caso precedente. In ambito RTP, invece, le specifiche [15] suggeriscono di trasmettere ciascun VOP in almeno un pacchetto RTP, con la sola eccezione di VOPs di piccole dimensioni, costituite dal solo header, che possono essere contenute in un unico pacchetto. Il marker bit segnalerà la fine dei dati relativi ad un VOP e quindi, come si vede, il meccanismo è analogo a quello per la mappatura del MPEG-1/-2, con la differenza che è in questo contesto è più indicato parlare in termini di VOP che di frames. Si noti infine che per il MPEG-4 si utilizza il payload type dinamico nel SDP, mediante una sintassi del tipo :
m= video 1020 RTP/AVP 96
a= rtpmap: 96 mpeg4
Come già detto, lISO, propone una serie di standard audio e video prodotti dal Motion Picture Expert Group, è però importante sottolineare che, alcuni codecs molto diffusi, sono implementazioni non ufficiali dei codecs ISO. Tra questi, di sicuro il DivX è quello che più ha lasciato il segno. Esso infatti si basa interamente sul codec MPEG-4, mostrando interessanti caratteristiche quali l'elevato livello di compressione, lalta efficienza del codec e la scalabilità sia in codifica, con la scelta del miglior livello di compressione, sia in decodifica dando la possibilità alle macchine più lente di vedere ugualmente i filmati rinunciando un poco alla qualità. Rappresenta quindi oramai, uno standard molto potente per il supporto di applicazioni multimediali su Internet, tantè che la rivoluzione da esso generata in ambito video-streaming, viene sempre più paragonata alleffetto prorompente che lmp3 ha avuto tempo fa sui media audio. Non a caso viene considerato come un autentica minaccia per le principali case cinematografiche mondiali, in quanto, grazie alle sue caratteristiche di compressione, permette facilmente in banda larga, di scaricare interi film, spesso purtroppo da siti illegali. Da citare è la storia del codec: nato dopo opportuno lavoro di hacking, come versione illegale del codice originario di Microsoft sotto la sigla "DivX;-)", nel tempo ha perso "locchiolino", è diventato legale e, con la nascita di un suo gruppo di ricerca e sviluppo, il "Project Mayo", ha cambiato nome in OpenDivX. Per questo codec, si sono cercati di risolvere alcuni problemi legati al suo funzionamento originario, quali perdita di sync, bassa qualità video con movimenti veloci dell'immagine, contemporaneamente migliorando il rapporto qualità/compressione. Successivamente da OpenDivX si è arrivato allattuale DivX, tuttora però con codice sorgente chiuso, quindi, di fatto chiuso dalle enormi possibilità di sviluppo che la comunità può offrire.
Il nome può già suggerire la provenienza del codec; esso rappresenta infatti una biforcazione dello sviluppo del codec OpenDivX, che come detto è arrivato alla creazione del DivX, con sorgente però chiusa. Una parte della comunità di sviluppatori di Project Mayo ha allora deciso di staccarsi da tale gruppo di ricerca e dare luogo al XviD, con codice sorgente aperto e molto simile allo stesso DivX, con prestazioni addirittura superiori.