Prec Sezione 11.2: Codifica di
canale Su
Capitolo 11: Teoria dell’informazione e codifica Capitolo
12: Codifica di sorgente multimediale Segue
11.3 Codici di canale↓
Dopo aver esposto i risultati che la teoria
dell’informazione fornisce a riguardo delle migliori prestazioni
ottenibili, proseguiamo il discorso iniziato al § 8.4.2.1↑ relativo a come
aggiungere ridondanza↓
ad un flusso binario a velocità fb
da trasmettere su di un canale numerico, in modo da realizzare una
protezione fec capace di ridurre la
probabilità di errore sul bit Pe
in ricezione. Ricordiamo che al § 11.2.3↑
abbiamo mostrato come, aumentando il ritardo di codifica, la probabilità
di errore può essere resa piccola a piacere, purché fb
= R < C, essendo C
la capacità di canale. Ma mentre la soluzione teorica basata su
segnalazione asintoticamente ortogonale di fig. 11.13↑
prevede un aumento esponenziale [470] [470] Consideriamo
infatti di rappresentare le forme d’onda ortogonali mediante un rect posto all’interno del periodo
di simbolo T, in modo da non
sovrapporsi ai rect associati
a simboli diversi (vedi § 6.5.2↑).
All’aumentare del periodo di simbolo T
il numero di bit/simbolo M = fbT
aumenta in modo proporzionale, mentre il numero di possibili simboli
L = 2M = 2fbT
aumenta esponenzialmente. Pertanto, ogni rect
ha a disposizione un intervallo temporale pari a T⁄2fbT
e quindi la sua durata tende a zero esponenzialmente se T
→ ∞, mentre la sua banda tende ad infinito, sempre con
legge esponenziale rispetto a T.
della banda occupata, le tecniche illustrate nel seguito consentono di
mantenere la relazione tra grado di protezione e banda occupata di tipo
proporzionale.
Riprendiamo la notazione introdotta a pag. 1↑
per i codici a blocchi↓,
 in cui
per ogni k bit in ingresso sono
prodotte codeword↓↓
con lunghezza n = k + q
> k mediante l’aggiunta di q
bit di protezione in funzione dei primi k:
indichiamo questo procedimento come un codice (n, k),
la cui efficienza è misurata dal tasso di codifica↓
(code rate)
in cui
per ogni k bit in ingresso sono
prodotte codeword↓↓
con lunghezza n = k + q
> k mediante l’aggiunta di q
bit di protezione in funzione dei primi k:
indichiamo questo procedimento come un codice (n, k),
la cui efficienza è misurata dal tasso di codifica↓
(code rate)
Rc = (k)/(n) < 1
che rappresenta la frazione di bit informativi sul totale di quelli
trasmessi, nonché l’inverso del fattore di espansione di
banda: la nuova velocità di trasmissione in presenza di codifica
vale infatti
f’b = (fb)/(Rc)
Osserviamo ora che all’aumento della velocità di segnalazione (essendo f’b > fb)
corrisponde una eguale diminuzione del rapporto Eb⁄N0 = (
Px)/(N0f’b), e conseguentemente si
assiste ad un peggioramento della probabilità di errore grezza
del decisore: pertanto, la capacità correttiva del codice deve essere
tale da compensare anche questo aspetto. Per mantenere limitato
l’effetto descritto, così come l’espansione di banda, vorremmo trovare
codificatori per cui Rc
sia il più possibile vicino ad uno. Al tempo stesso, la capacità di correzione del
codice è direttamente legata alla minima distanza↓
di Hamming dm
definita a pag. 1↑
come il minimo numero di bit diversi tra due parole di codice,
sussistendo le relazioni
- per accorgersi di l (o meno) errori per codeword occorre dm ≥ l + 1
- per correggere t (o meno) errori per codeword occorre dm ≥ 2t + 1
Un codice è tanto più potente quanti più
errori è in grado di correggere, e dunque deve possedere dm
elevato. In un codice a blocchi (n,
k) i k
bit del messaggio originale assumono tutte le configurazioni possibili,
e quindi contribuiscono alla distanza tra codeword per un solo bit; per
ottenere dm > 1
occorre pertanto sfruttare gli n − k
= q bit di protezione, portando a scrivere
dm ≤ n − k
+ 1 = q + 1
che evidenzia la relazione tra dm
e la quantità di bit aggiunti q.
L’uguaglianza sussiste solo per una particolare classe di codici [471] [471] Indicati
come codici mds, vedi http://en.wikipedia.org/wiki/Singleton_bound#MDS_codes.
tra cui il codice a ripetizione, discusso a pag. 1↑,
che adottando una dimensione di blocco in ingresso k
= 1 ha un tasso di codifica Rc
= k⁄n = 1⁄n
molto inefficiente. La distanza dm
ed il tasso Rc
non possono essere scelti indipendentemente, dato che per aumentare dm occorre aumentare
i bit di protezione q, a cui
corrisponde una diminuzione del valore di Rc.
Inoltre, il miglioramento in termini di Pe
dovuto ad un codice di canale, può essere equiparato a quello
corrispondente a un aumento della potenza di segnale, di un fattore pari
a
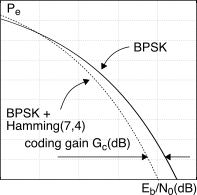 indicato come guadagno di codifica asintotico [472] [472] In
altre parole, se Gc
= 2 significa che l’adozione del codice permette di
conseguire un valore di Pe
pari a quello ottenibile con una trasmissione a potenza doppia, ma
non codificata.. Tale risultato è valido nel caso di soft-decoding [473] [473] Nel caso di decisioni hard
o bit a bit, si ottiene una espressione del tipo Gac,
hard = Rc(t
+ 1), in cui t
è il numero di bit per parola che il codice è in grado di
correggere. (pag. 1↓),
ed è descritto come asintotico in quanto è valido solo per
valori di Eb⁄N0
elevati: infatti all’aumentare della potenza di rumore, per qualunque
codice e metodo di decisione il valore di Gc
si riduce, fino a divenire inferiore ad uno, quando gli errori sono così
numerosi da non poter più essere corretti.
indicato come guadagno di codifica asintotico [472] [472] In
altre parole, se Gc
= 2 significa che l’adozione del codice permette di
conseguire un valore di Pe
pari a quello ottenibile con una trasmissione a potenza doppia, ma
non codificata.. Tale risultato è valido nel caso di soft-decoding [473] [473] Nel caso di decisioni hard
o bit a bit, si ottiene una espressione del tipo Gac,
hard = Rc(t
+ 1), in cui t
è il numero di bit per parola che il codice è in grado di
correggere. (pag. 1↓),
ed è descritto come asintotico in quanto è valido solo per
valori di Eb⁄N0
elevati: infatti all’aumentare della potenza di rumore, per qualunque
codice e metodo di decisione il valore di Gc
si riduce, fino a divenire inferiore ad uno, quando gli errori sono così
numerosi da non poter più essere corretti.
(12.31)
Gac = dmRc
Mostriamo ora delle soluzioni che consentono di
ottenere un adeguato potere di correzione, senza per questo aumentare di
molto la velocità di trasmissione del flusso codificato.
11.3.1 Codice lineare a blocchi↓
Le proprietà di questa classe di codici di
canale possono essere meglio analizzate interpretando l’insieme delle
possibili codeword da un punto di vista algebrico, ed adottando una
notazione matriciale idonea a descrivere la classe di codici a
blocchi, mentre per i codici ciclici (§ 11.3.1.2↓) interverrà
una notazione polinomiale.
Scegliamo di rappresentare una codeword
arbitraria x di un codice a
blocchi (n,
k) mediante un vettore ad
elementi binari
x = (x1
x2 ⋯ xn)
che può assumere solo 2k
diversi valori tra i 2n
possibili, mentre le ricezione di una delle rimanenti 2n
− 2k combinazioni di bit segnala la presenza
di almeno un errore. Il codice è detto lineare se le 2k
codeword costituiscono uno spazio lineare (pag. 1↑), ovvero se
comprendono la codeword nulla, e se la somma di due codeword è anch’essa
una parola di codice [474] [474] Poco
più avanti si mostra che un codice sistematico è anche
lineare.. La somma tra due codeword è definita in base
alla matematica binaria modulo due, espressa mediante l’operatore di or esclusivo ⊕
come
Indicando ora come peso w(z) di un vettore z
il numero di suoi elementi non zero, come conseguenza della linearità è
possibile valutare la minima distanza↓ di Hamming dm tra parole di
codice, come il minimo peso tra tutte le codeword non zero [475] [475] Infatti dalla definizione di
somma otteniamo che la distanza tra due codeword x
e y è pari al peso della
codeword z = x + y:
infatti z presenterà
componenti zj = 1
solo in corrispondenza di elementi xj
≠ yj. Ma per la linearità anche z appartiene al codebook, e dunque
la ricerca su tutte le coppie si trasforma in una ricerca su tutte
le codeword., ossia
dm =
minx ≠ 0
[w(x)]
Rappresentazione
matriciale per codici sistematici↓
Finora abbiamo assunto che gli n
bit delle codeword rappresentino per primi i k
bit da proteggere, a cui seguono i q = n
− k bit di protezione, anche se questa ripartizione non
è per nulla scontata: qualora effettivamente si verifichi, il codice
risultante viene detto sistematico. In tal caso le codeword
possono essere scritte nella forma
x = (m1
m2 ⋯ mk c1
c2 ⋯ cq)
ovvero in forma partizionata x = (m|c), che consente di rappresentare x a partire dai bit da proteggere m e dalla definizione di una matrice generatrice↓
k × n con struttura generale
G = [Ik|P], in cui Ik
è una matrice identità k × k
e P è una sotto-matrice di
elementi binari k × q,
permettendo di scrivere x = m⋅G,
ovvero
in modo che P produca [476] [476] Sono
valide le normali regole di moltiplicazione tra matrici, tranne per
l’accortezza di usare la somma modulo due anziché quella
convenzionale. i q
bit di protezione come c = m⋅P.
Dato che il valore della (generica) j-esima
componente di c si calcola come
cj = m1p1j⊕m2p2j⊕⋯⊕mkpkj
osserviamo che ciascuna colonna di P
individua un sotto-insieme di componenti di m
su cui calcolare una somma di parità↓,
ed è per questo che il sotto-blocco di matrice è rappresentato dalla
lettera P. Ma non è ancora stato
definito nulla che ci possa aiutare a scegliere i coefficienti pij
allo scopo di ottenere i valori dm
e Rc desiderati:
il codice di Hamming (§ 11.3.1.1↓)
ci fornisce una possibile soluzione. Dato che la somma modulo due di due vettori
binari x⊕y avviene bit per
bit (eq. 12.32↑),
la linearità di un codebook sistematico può essere verificata
considerando le due parti m e c in modo indipendente. Dato che m può assumere una qualunque delle 2k configurazioni possibili,
è sempre vero che m3 = m1⊕
m2 appartiene allo stesso insieme. Per quanto
riguarda i q bit di protezione c, osserviamo che c3
= c1⊕ c2 = m1
P⊕m2 P = (m1⊕
m2) P, e
dunque c3 corrisponde
alla protezione di m3:
pertanto, anche per la parte c la
proprietà di linearità è verificata.
11.3.1.1 Codice di Hamming↓
| q | n | k | Rc |
| 3 | 7 | 4 | 0.57 |
| 4 | 15 | 11 | 0.73 |
| 5 | 31 | 26 | 0.84 |
| 6 | 63 | 57 | 0.9 |
| 7 | 127 | 120 | 0.94 |
n = 2q − 1
e k = n − q
per cui il tasso di codifica vale
Rc = (k)/(n) = (n − q)/(n) = 1 − (q)/(2q
− 1)
che aumenta con il crescere di q,
come mostrato in tabella. Le codeword si individuano ponendo le
righe della sottomatrice P
pari a tutte le parole di q bit
con due o più uni, in qualsiasi ordine. Ma la cosa più
simpatica, è che per un codebook↓ siffatto si
ottiene una distanza di Hamming minima dm
= 3, indipendentemente dalla scelta di q.
Esempio: codice
di Hamming (7,
4). Consideriamo un codice di
Hamming con q = 3, e quindi n = 23 − 1 = 7 e k = 7 − 3 = 4. Una possibile
matrice generatrice è quindi pari a
G = ⎡⎢⎢⎢⎢⎢⎣
1 0 0
0
0 1 0
0
0 0 1
0
0 0 0
1 ||||||| 1
0
1
1
1 1
1 1 0
0
1
1 ⎤⎥⎥⎥⎥⎥⎦
a cui corrispondono le seguenti 24
= 16 codeword, per ognuna delle quali si è evidenziato il
peso w(x),
confermando che dm
= 3. -
m c w(x) 0 0 0 0 0 0 0 0 0 0 0 1 0 1 1 3 0 0 1 0 1 1 0 3 0 0 1 1 1 0 1 4 0 1 0 0 1 1 1 4 0 1 0 1 1 0 0 3 0 1 1 0 0 0 1 3 0 1 1 1 0 1 0 4 m c w(x) 1 0 0 0 1 0 1 3 1 0 0 1 1 1 0 4 1 0 1 0 0 1 1 4 1 0 1 1 0 0 0 3 1 1 0 0 0 1 0 3 1 1 0 1 0 0 1 4 1 1 1 0 1 0 0 4 1 1 1 1 1 1 1 7 Dato inoltre che sia m che c assumono tutte le configurazioni possibili, è verificata la linearità, ossia che la somma di una qualunque coppia di codeword corrisponde ad una terza codeword.
Indichiamo ora con y
la parola di codice ricevuta; in presenza di errori, risulta y
≠ x. Il metodo diretto per rivelare ed
eventualmente correggere gli errori presenti è quello di confrontare gli
n bit ricevuti con tutte le
possibili 2k codeword,
e se nessuna di queste risulta uguale ad y,
scegliere la x̂ con la
minima distanza di Hamming, ossia quella per la quale il peso w(y⊕x̂)
è minimo, ovvero
x̂ = argminx
{w(y⊕x)}
Correzione
basata sulla sindrome↓
Un metodo che non richiede una ricerca esaustiva
si basa invece sul calcolo della cosiddetta sindrome, ottenuta
mediante moltiplicazione del vettore y
ricevuto per una matrice n × q
di controllo parità↓
H, definita come H
= ⎡⎣(P)/(Iq)⎤⎦ in
cui P è la stessa matrice di
parità utilizzata nella matrice generatrice G,
e Iq è una
matrice identità di dimensioni q × q.
La matrice H esibisce la simpatica
proprietà che, se moltiplicata per una qualunque codeword valida,
fornisce un vettore nullo di dimensione q,
ossia
x⋅H = (0
0 ⋯ 0)
Al contrario, se moltiplicata per un vettore y
non appartenente al codebook, fornisce un vettore detto sindrome
s = y⋅H non nullo,
e quindi il suo calcolo permette la rivelazione (nei limiti
consentiti da dm)
dell’occorrenza di errori. Esempio considerando di nuovo il caso di q
= 3, la corrispondente matrice di controllo parità H = ⎡⎣(P)/(Iq)⎤⎦
è
mostrata a lato. E’ facile
verificare che per tutte le possibili codeword x
(ad es. x = [0100111]) si ottiene x⋅H
= [000].
Poniamo ora che si verifichi una sequenza di errore e
= [0010010],
dando luogo alla ricezione della parola y
= x⊕e = [0110101]: per essa si ottiene una
sindrome s = y⋅H = [100].
H
= ⎡⎢⎣
1 0 1
1
1
1
1
1
0
0
1
1
1
0
0
0
1
0
0
0
1
⎤⎥⎦
Per quanto riguarda la correzione, se
scriviamo il vettore ricevuto come y = x⊕e,
dove e è un vettore di n
bit le cui componenti sono diverse da zero in corrispondenza dei bit
errati di y, il calcolo della
sindrome risulta
s = y⋅H = (x⊕e)⋅H = x⋅H⊕e⋅H
= e⋅H
visto che come detto sopra, la sindrome delle codeword è nulla. Dato
però che la sindrome ha dimensione di q
elementi, tutte le 2n
possibili sequenze di errore e
danno luogo a sole 2q
diverse sindromi, e quindi la conoscenza della sindrome non consente di
risalire direttamente a e. Ma
riprendendo i risultati esposti a pag. 1↑,
risulta che la probabilità P(i,
n) che si siano verificati
i errori su n
bit decresce al crescere di i, e
pertanto il vettore ê che con
maggior probabilità ha prodotto ognuna delle 2q
sindromi s ≠ 0, è quello (tra
tutti quelli che producono la stessa s)
con il minor peso:
ê = argmin
e : e⋅H
= s {w(e)}
Anziché effettuare questo calcolo ad ogni codeword ricevuta, si può precalcolare,
per ogni possibile e, la relativa
sindrome, e compilare una tabella T(s)
in cui memorizzare per ogni possibile s,
il vettore ê di peso minore che
la produce. La stessa tabella può quindi essere consultata usando come
chiave di ricerca la sindrome s ≠ 0
calcolata per ogni y ricevuto,
ottenendo il vettore di errore ê = T(s)
più probabile, e che se sommato ad y,
permette la correzione degli errori. La figura che segue riepiloga i
passi necessari alla correzione mediante sindrome. 
Notiamo innanzitutto che la compilazione di T(s)
è più semplice del previsto: infatti è facile verificare come ad ogni
vettore di errore con soltanto l’i − esimo
bit pari ad uno, sia associata la sindrome corrispondente all’i
− esima riga di H.
Notiamo inoltre che se si verificano più errori di
quanti dm
permetta di correggere, è inutile (anzi dannoso) cercare di eseguire la
correzione, perché il numero di errori complessivo può risultare ancora
più elevato. Nel caso del codice di Hamming in cui dm
= 3 si può correggere un solo errore per codeword, ed esistono
solo n vettori e
di peso unitario, a cui corrispondono sindromi esattamente pari alle n = 2q − 1 righe di H. Ma se ad esempio e
contiene due errori, la sua moltiplicazione per H
produce comunque una delle 2q
possibili sindromi, ed il tentativo di correzione produce un vettore x̂ contenente tre errori.
Esempio Un gruppo di bit 1001
è protetto dal codice di Hamming di pag. 1↑
producendo x = 1001110,
mentre in ricezione si osserva y
= 1101110. Il calcolo della sindrome s
= y⋅H fornisce il risultato s
= 111, che corrisponde alla seconda riga di H,
ovvero al vettore di errore ê =
0100000, cioè proprio quello che si è verificato. Se invece
avvengono due errori, e si riceve ad es. y
= 1111110, si ottiene s =
101, a cui corrisponde ê =
1000000, e quindi il calcolo x̂
= y⊕ê produce ora x̂
= 0111110, che appunto contiene tre errori.
Per il motivo illustrato, nel caso in cui gli
errori non siano indipendenti e dunque isolati nel tempo, ma avvengano
in sequenza come nel caso del fast fading (§ 348↓), il solo
codice di Hamming è del tutto inadeguato alla loro correzione, mentre
una soluzione comunemente adottata in tal caso è quella di ricorrere
alla tecnica dell’interleaving↓ (§ 8.4.2.3↑) in cui m
codeword di lunghezza n uscenti
dal codificatore sono scritte per righe, e quindi lette per colonne
prima di trasmettere il flusso numerico risultante: ciò consente di
correggere fino ad m errori
consecutivi, in quanto in ricezione il processo inverso di de-interleaving
ridistribuisce i bit errati su m
diverse codeword. In alternativa, si possono utilizzare le soluzioni
descritte nel seguito.
Finora la decodifica di canale è stata applicata
a valle del processo di decisione [477] [477] Per
questo detta hard decision decoding in quanto opera su
decisioni già prese., in modo da individuare le
codeword come quelle con la minima distanza di Hamming rispetto
al risultato prodotto dal decisore. Se invece le due operazioni sono fuse
in un unico elemento che opera su interi blocchi di n
bit y = (y1,
y2, ⋯, yn),
e che tenta di individuare le codeword trasmesse come quelle con la
minima distanza euclidea rispetto a quanto ricevuto [478] [478] Tale
possibilità è indicata come soft decision decoding
(decodifica con decisioni soffici) in quanto richiede
operazioni in virgola mobile; si veda ad es. la spiegazione fornita
presso http://www.gaussianwaves.com/2009/12/hard-and-soft-decision-decoding-2/.,
si ottengono prestazioni migliori a spese di una maggior complessità di
calcolo. Questa seconda tecnica valuta le distanze dE(y, xj)
= ∑ni = 1(yi − xji)2 tra i valori yi
effettivamente ricevuti, e quelli che avrebbero dovuto essere
nell’ipotesi che fosse stata trasmessa una delle possibili codeword xj = (xj1,
xj2, ⋯, xjn), decidendo quindi per la codeword x̂ tale che dE(y, x̂)
è minima [479] [479] Si
veda lo sviluppo a pag. 1↓
per mettere in relazione la distanza dE(y, xj) con la verosimiglianza
logaritmica ln(pn(y ⁄ xj))
della v.a. n − dimensionale y rispetto all’ipotesi che sia
stata trasmessa la codeword xj,
in presenza del rumore gaussiano n
in sede di decisione.. In tal modo si ottengono
prestazioni equivalenti a quelle dell’approccio hard decoding
operante con un Eb⁄N0 di
circa 2 dB più elevato.
11.3.1.2 Codici ciclici ↓
Sono un sottoinsieme dei codici lineari a
blocchi, con la condizione aggiuntiva che se x
= (x1, x2,
⋯, xn) è
una codeword, lo sono anche tutti i suoi scorrimenti ciclici [480] [480] Ad esempio, il codice [000, 110, 101, 011] è un codice ciclico, mentre [000, 010, 101, 111] no. Notiamo che gli scorrimenti
della codeword 000, sono la codeword
stessa., ovvero le codeword x(1) = (x2, x3,
⋯, x1), x(2) = (x3, x4,
⋯, x2), ⋯,
x(n) = (xn,
x1, ⋯, xn − 1).
In tal caso sussistono delle proprietà algebriche aggiuntive che si
basano sulla teoria dei campi di Galois [481] [481] http://it.wikipedia.org/wiki/Campo_finito,
i cui elementi sono polinomi x(p) = x1pn
− 1 + x2pn − 2 + ⋯
+ xn − 1p + xn
nella variabile p, con
coefficienti binari definiti a partire dagli elementi delle codeword x; per tale motivo, i codici ciclici
sono detti anche codici polinominali↓ [482] [482] Si
veda http://en.wikipedia.org/wiki/Polynomial_code:
senza volerci addentrare nei particolari della teoria [483] [483] http://en.wikipedia.org/wiki/Cyclic_code,
citiamo direttamente i principali risultati.
Un codice ciclico (n,
k) è completamente
definito a partire da un polinomio generatore↓
g(p) = pn − k +
g2pn − k − 1 + ⋯ +
gn − kp + 1 di grado n − k e che deve risultare un
divisore di pn + 1,
ovvero essere tale che pn + 1⁄g(p)
= q(p)
con resto nullo [484] [484] Si
applicano le regole di divisione tra polinomi http://it.wikipedia.org/wiki/Divisione_dei_polinomi.
Una volta definito g(p), è possibile ottenere la matrice
generatrice↓ G
del codice in forma sistematica G
= [Ik|P],
calcolando le k righe di P
come i coefficienti del polinomio resto della divisione tra pi e g(p),
con i = n − 1, n − 2, ⋯, n
− k.
Esempio Troviamo la matrice generatrice in forma sistematica
per un codice ciclico (7,
4). Osserviamo innanzitutto
che pn + 1
si fattorizza come p7
+ 1 = (p + 1)(p3 + p2
+ 1)(p3
+ p + 1), e scegliamo g(p) = p3 + p2
+ 1 come polinomio generatore. Il calcolo di pi⁄p3 + p2
+ 1 per i =
6, 5, 4, 3 fornisce come resti i polinomi p2
+ p, p + 1, p2 + p + 1, p2 + 1, pertanto la
matrice generatrice risulta G = ⎡⎢⎢⎢⎢⎢⎣
1
0 0 0
0
1 0 0
0
0 1 0
0
0 0 1 |||||||
1 1 0
0
1
1
1
1 1
1 0 1 ⎤⎥⎥⎥⎥⎥⎦.
Osserviamo che, a parte una permutazione, le righe di P
sono le stesse di quelle che definiscono il codice di Hamming di
pag. 1↑: infatti, anche
quest’ultimo rientra nella classe dei codici ciclici.
D’altra parte nel caso di un codice ciclico le
codeword x associate ai bit m da proteggere possono ottenersi non
solo utilizzando G come descritto
dalla (12.33↑),
ma anche in base alla seguente proprietà: indicando con m(p) = m1pk
− 1 + m2pk − 2 + ⋯
+ mk − 1p + mk
il polinomio associato ai k bit da
codificare, il polinomio associato alla corrispondente codeword x
si ottiene come il prodotto x(p) = m(p)⋅g(p),
e quindi gli elementi xi
della codeword sono individuati come la convoluzione discreta [485] [485] Il valore dei coefficienti
del polinomio prodotto è indicato anche come prodotto di Cauchy
(vedi http://it.wikipedia.org/wiki/Prodotto_di_Cauchy),
e che si ottenga come una convoluzione è facilmente verificabile:
dati ad es. a(p) = a0 + a1p
+ a2p2 e b(p) =
b0 + b1p, si
ottiene c(p) = a0b0
+ (a0b1
+ a1b0)p
+ a2p2 = ∑2i = 0pi∑2j = 0ajbi
− j. La notazione lievemente diversa del
testo, è dovuta al diverso modo di indicizzare i coefficienti.
tra i coefficienti di m(p) e g(p):
xi = ∑kj = 1mjgi
− j + 1 per i =
1, 2, ⋯, n, operazione che può essere realizzata
mediante un filtro fir con
coefficienti dati dai valori gi.
Notiamo infine che nel testo si è già incontrato
un codice polinomiale (e quindi ciclico) al § 8.4.3.3↑
a proposito del crc: i q
bit di protezione possono quindi essere anche ottenuti mediante
l’utilizzo di un registro a scorrimento controreazionato [486] [486] Forse
ho trovato dove si spiega come faccia un registro a scorrimento
controreazionato a svolgere questo genere di compiti: penso che in
una prossima edizione sarà interessante aggiungerlo.,
e lo stesso può essere usato anche per il calcolo della sindrome dal
lato ricevente.
Codice
BCH↓
Prende il nome dalle iniziali dei rispettivi
inventori, e rappresenta una sottoclasse dei codici ciclici, in grado di
correggere fino a t < n
errori: per ottenere questo risultato occorre scegliere un numero di bit
di protezione q ≤ mt in cui
m ≥ 3 è un intero, una lunghezza
delle codeword pari a n = 2m
− 1, ed un polinomio generatore g(p)
di grado massimo mt le cui radici
sono potenze dell’elemento primitivo α
del campo di Galois GF(2m) [487] [487] http://en.wikipedia.org/wiki/BCH_code.
In tal caso si ottiene dm
≥ 2t + 1, e la capacità di correggere fino a t
errori. Nel caso in cui t = 1, si
ricade nel caso dei codici di Hamming. La fase di correzione degli
errori può essere realizzata mediante il calcolo di una sindrome, per
mezzo di una matrice di controllo H
realizzata a partire dalle potenze dell’elemento primitivo α,
o sfruttando nuovamente proprietà algebriche, che eventualmente si
traducono in soluzioni circuitali basate su registri a scorrimento
controreazionati. Inoltre, è anche possibile applicare l’algoritmo
iterativo di Berlekamp-Massey [488] [488] http://en.wikipedia.org/wiki/Berlekamp-Massey_algorithm.
Codice
di Reed-Solomon↓
Si tratta di un sottoinsieme dei codici bch,
caratterizzato [489] [489] http://en.wikipedia.org/wiki/Reed-Solomon_error_correction
da parole di codice ad elementi non binari ma bensì L-ari;
scegliendo L = 2k
si possono mappare k bit della
sequenza informativa m in un
singolo elemento del codice.

11.3.2 Codice convoluzionale↓
Individua un modo di realizzare la codifica di canale che, a
differenza dei codici a blocchi, produce una sequenza binaria i cui
valori dipendono da gruppi di bit di ingresso temporalmente
sovrapposti, in analogia all’integrale di convoluzione che
fornisce valori che dipendono da intervalli dell’ingresso,
pesati dai valori della risposta impulsiva. Un generico codice
convoluzionale è indicato con la notazione CC(n, k, K),
che lo descrive capace di generare gruppi di n
bit di uscita (sequenza {b}) in base alla conoscenza di K
simboli di ingresso (sequenza {a}), ognuno composto da k
bit.

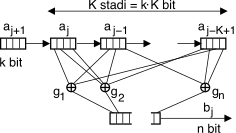
Diagramma
di transizione↓
Una volta definito il meccanismo di calcolo di bj a partire da aj, il codificatore
può essere descritto mediante un diagramma di transizione,
costituito da 2(K
− 1)k stati
S associati a tutte le possibili
combinazioni di bit degli ultimi K − 1
simboli di ingresso; ad ogni stato competono quindi 2k
transizioni, una per ogni possibile nuovo aj
di ingresso, ed ognuna delle quali termina sul nuovo stato che si è
determinato. Ad ogni transizione, è infine associato in modo univoco il
gruppo di n bit bj(aj, Sj) da emettere in uscita [491] [491] Lo
stesso valore di bj
potrebbe essere prodotto da più di una delle 2k⋅K
diverse memorie del codificatore..
Per fissare le idee, consideriamo un codice
convoluzionale che produca due bit per ogni bit di ingresso, in funzione
dei due bit precedenti, ovvero CC(n,
k, K) = CC(2,
1, 3) con g1
= [
1
1 1
] e g2
= [
1
0 1
], caratterizzato da un
coding rate Rc = (k)/(n) = (1)/(2),
e mostrato nella parte sinistra della figura 11.21↓.
A questo corrisponde il diagramma di transizione mostrato al centro, in
cui le transizioni tra stati sono tratteggiate o piene, in
corrispondenza rispettivamente dei valori aj
pari a zero o ad uno, e sono etichettate con la coppia di bit in uscita
bj, calcolabile
mediante i vettori generatori g1, 2,
come risulta dalla tabella della verità mostrata a destra.
Come si può notare, ogni stato ha solo due transizioni, e quindi
solo due valori di uscita (la metà dei 4 possibili con due bit);
inoltre, questi valori differiscono in entrambi i bit [492] [492] La
dipendenza di bj
da (aj,
Sj)
è legata alla scelta dei generatori gi.
Nel caso in cui un valore bj(i)
sia sempre uguale ad uno dei k
bit di aj,
il codice è detto sistematico. La scelta dei gi
può essere effettuata mediante simulazioni numeriche, per
individuare l’insieme che determina le migliori prestazioni..
|
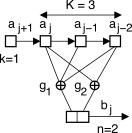
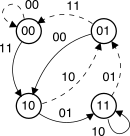 |
Figura 11.21 Architettura
del codice convoluzionale CC(2, 1, 3),
diagramma di transizione e tabella della verità.
Qualora si ponga in ingresso la sequenza {a} = {...010100}( [493] [493] Per comodità di
rappresentazione, il bit più a destra nella sequenza {a}
è il primo in ordine di tempo ad entrare nel codificatore.),
è possibile osservare che la sequenza di stati risulta {S} = {..., 01, 10, 01, 10, 00},
mentre quella di uscita è {b} = {..., 10,
00, 10, 11}, semplicemente
seguendo il diagramma di transizione, a partire dallo stato iniziale 00. D’altra parte, è possibile anche il
procedimento opposto: conoscendo {b}, si può risalire ad {a},
percorrendo di nuovo le transizioni etichettate con i simboli bj.
In definitiva, osserviamo come ad ogni coppia ({a}, {b}) sia
biunivocamente associata una sequenza di stati {S}.
Diagramma
a traliccio↓
Per meglio visualizzare le possibili sequenze di
stati, costruiamo il diagramma a traliccio (trellis)
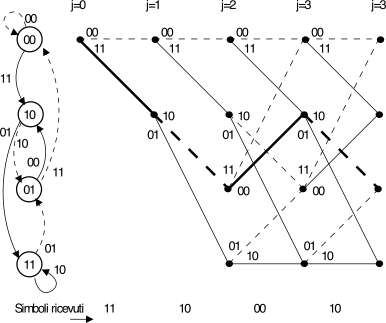
del codificatore, mostrato a sinistra di fig. 11.22↓
riportando sulle colonne i possibili stati attraversati ai diversi
istanti j, collegando i nodi
del traliccio con transizioni piene o tratteggiate nei casi in cui siano
relative ad ingressi pari ad 1 o 0,
e riportando sulle transizioni stesse i valori di uscita. Con
riferimento alla sequenza codificata {b}
riportata in basso, l’effettiva successione di stati {S}
è rappresentata dalle linee più spesse.
Consideriamo ora il caso in cui la sequenza codificata {b}
venga trasmessa su di un canale, e che sia ricevuta con errori.
In generale, non sarà più possibile rintracciare una sequenza di stati
tale da produrre esattamente la sequenza ricevuta {b̃},
ed il problema diviene quello di individuare la sequenza di stati {S}
tale da produrre una {b̂} la più
vicina possibile a {b̃}.
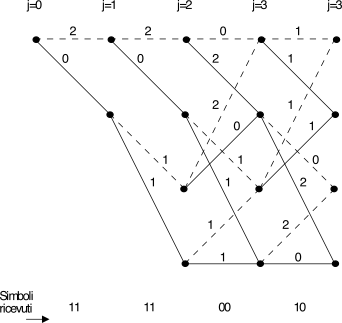
 Allo
scopo di misurare questa differenza, utilizziamo la distanza di
Hamming dH(^b,
b̃) che rappresenta il numero di bit diversi tra {b̃} e le possibili {b̂}( [494] [494] Questo caso viene indicato
con il termine hard-decision decoding in quanto il
ricevitore ha già operato una decisione (quantizzazione)
rispetto a b̃. Al contrario,
se i valori ricevuti sono passati come sono al
decodificatore di Viterbi, questo può correttamente valutare le
probabilità p(b̃ ⁄ ^b)
ed operare in modalità soft decoding, conseguendo
prestazioni migliori.), e etichettiamo gli archi del
traliccio con le dH(^bj,
b̃j) tra il simbolo da emettere ^bj
e quello osservato in ricezione b̃j
(vedi lato destro di fig. 11.22↑).
In tal modo, per ogni particolare sequenza di stati {S}
è possibile determinare un costo pari alla somma delle dH(^bj,
b̃j) relative alle transizioni
attraversate dal traliccio [495] [495] Ad
esempio, con riferimento alla fig. 11.22↑,
la {S} = {00, 10,
11, 01, 10} ha un costo
pari a 3.. Pertanto, la sequenza {b̂}
più vicina a {b̃}, ossia tale che
Allo
scopo di misurare questa differenza, utilizziamo la distanza di
Hamming dH(^b,
b̃) che rappresenta il numero di bit diversi tra {b̃} e le possibili {b̂}( [494] [494] Questo caso viene indicato
con il termine hard-decision decoding in quanto il
ricevitore ha già operato una decisione (quantizzazione)
rispetto a b̃. Al contrario,
se i valori ricevuti sono passati come sono al
decodificatore di Viterbi, questo può correttamente valutare le
probabilità p(b̃ ⁄ ^b)
ed operare in modalità soft decoding, conseguendo
prestazioni migliori.), e etichettiamo gli archi del
traliccio con le dH(^bj,
b̃j) tra il simbolo da emettere ^bj
e quello osservato in ricezione b̃j
(vedi lato destro di fig. 11.22↑).
In tal modo, per ogni particolare sequenza di stati {S}
è possibile determinare un costo pari alla somma delle dH(^bj,
b̃j) relative alle transizioni
attraversate dal traliccio [495] [495] Ad
esempio, con riferimento alla fig. 11.22↑,
la {S} = {00, 10,
11, 01, 10} ha un costo
pari a 3.. Pertanto, la sequenza {b̂}
più vicina a {b̃}, ossia tale che
dH(^b,
b̃) = min{S}{ ⎲⎳jdH(bj,
b̃j)}
può essere individuata come quella associata alla sequenza di stati {Ŝ} di minimo costo [496] [496] Qualora
la distanza tra b̃j
ed un possibile ^bj
sia espressa come probabilità condizionata p(b̃j
⁄ ^bj),
il processo di decodifica è detto di massima verosimiglianza↓..
Dato che da ogni stato si dipartono 2k
archi, ad ogni istante il numero di percorsi alternativi aumenta di un
fattore 2k, crescendo
molto velocemente all’aumentare di j.
L’enumerazione completa dei percorsi può essere però evitata,
notando che quando due percorsi con costi diversi si incontrano in uno
stesso nodo, quello di costo maggiore sicuramente non è
la parte iniziale del percorso di minimo costo, e quindi può essere
eliminato.
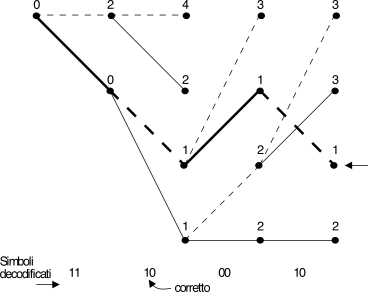
Una freccia posta all’estremità destra della
figura indica la minima dH(^b,
b̃), associata al percorso a tratto spesso, e che
permette di individuare la {b̃},
che come si vede è quella esatta.
Tralasciamo ora di approfondire la teoria che
consente l’analisi dettagliata dell’algoritmo, e ci limitiamo alle
seguenti
- l’esempio fornito si mostra in grado di correggere un errore pur impiegando un coding rate pari ad (1)/(2), migliore (ad es.) di quello ⎛⎝(1)/(3)⎞⎠ del codice a ripetizione;
- la dH del miglior percorso corrisponde al numero di bit errati (nel caso in cui siano stati corretti) nella b̃ ricevuta;
- si verifica errore (cioè {b̂} ≠ {b}) se esiste una b̂ ≠ b tale che dH(^b, b̃) è minore di dH(b, b̃);
- le capacità di correzione del codice migliorano aumentando la dH tra le possibili sequenze {b} [497] [497] La minima distanza tra le sequenze codificate è indicata come dmin, e può essere trovata come la dH tra una {b0} tutta nulla ({b0} = {...000000000}) e quella con il minor numero di uni, che si diparte e ritorna (nel traliccio) dallo/allo stato 00.;
- la dH tra diverse {b} aumenta con (K)/(k), in quanto la matrice di transizione tra stati diviene più sparsa, ed i valori di {b} sono più interdipendenti;
- se il miglioramento di cui sopra è ottenuto aumentando K, ciò equivale ad estendere nel tempo la memoria del codificatore, ma senza per questo alterare il tasso di codifica Rc = (k)/(n).
Prec Sezione 11.2: Codifica di
canale Su
Capitolo 11: Teoria dell’informazione e codifica Capitolo
12: Codifica di sorgente multimediale Segue
 Nato più di 20 anni fa, un progetto di
Nato più di 20 anni fa, un progetto di