 Lo strato applicativo di Internet
Lo strato applicativo di Internet Lo strato applicativo di Internet
In questa sezione (senza pretese), riportiamo descrizioni, commenti e riferimenti per l'uso di base di Linux come strumento di studio, di lavoro e di sviluppo
Il sistema operativo GNU/Linux si sviluppa a seguito della convergenza tra due progetti informatici, intrapresi da Linus Torvald e Richard Stallman. Torvald nel 1991 (all'età di 17 anni), ispirandosi a Minix, intraprese la realizzazione ex-novo di un kernel Unix, distribuendone i sorgenti via Internet e, avvalendosi della GPL che ne permetteva la modifica, riuscì ad coinvolgere sviluppatori distribuiti su tutto il pianeta. La licenza GPL era stata formalizzata nel 1989 da Stallman, che dall'83 aveva iniziato il progetto GNU, anch'esso con l'intento di realizzare un sistema operativo Unix liberamente modificabile. Ma a differenza di Torvald, che si era focalizzato sul controllo dell'hardware, Stallman avevo approcciato la sfida partendo dai comandi e dalle utility (come ad esempio il compilatore), dimodoché la sinergia tra le due iniziative fu completa, e diede origine all'attuale sistema GNU/Linux, che con tutta probabilità è destinato ad una continua evoluzione migliorativa, in virtù delle quattro libertà fondamentali garantite dalla licenza di software libero:
Svolgiamo qui una breve digressione a riguardo del sistema degli utenti offerto da Linux, e di come questo si riallacci alle questioni inerenti il lancio di processi server.
Ad ogni file presente sul disco, sono associati degli attributi, mostrati eseguendo il comando ls con l'opzione -l:
| [alef@localhost ~]$ ls -l totale 436 drwxrwxr-x 2 alef alef 4096 22 gen 16:04 autosave -rw------- 1 alef alef 96703 19 gen 16:06 autosave.xmi drwxrwxr-x 2 alef alef 4096 18 gen 09:37 bin drwxrwxr-x 2 alef alef 4096 12 dic 17:09 citta_utopia -rw-r--r-- 1 root root 129142 13 dic 14:38 enum+39069090611.cap drwxrwxr-x 3 alef alef 4096 31 ott 18:37 images drwxrwxr-x 12 alef alef 4096 25 gen 00:17 infocom drwxrwxr-x 4 alef alef 4096 24 gen 23:34 t |
Il primo carattere indica in qualche modo il tipo di file, e nel caso di una directory, prende il valore d, mentre per un file regolare, si ha un trattino -. Seguono 3 triple di caratteri del tipo rwx, in cui una o più lettere possono essere sostituite da -. Ogni tripla rwx è una rappresentazione leggibile di tre bit, che se posti ad uno od a zero, rappresentano rispettivamente la possibilità (o meno) per il file di essere letto (read), scritto (write) ed eseguito (executed); la prima tripla assegna questi privilegi al proprietario del file, la seconda agli utenti che fanno parte del gruppo a cui appartiene anche il file, e la terza tripla definisce i diritti per tutti gli altri. Ma per dare un senso alla spiegazione appena fornita, occorre prima illustrare l'organizzazione degli utenti in Linux.
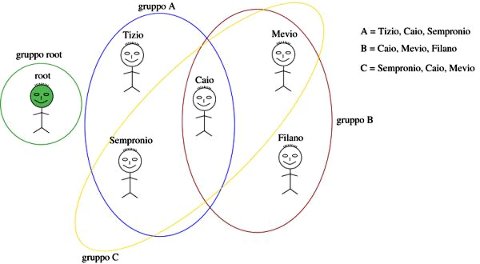
Molto spesso, un utente appena definito appartiene ad un solo gruppo, con nome uguale a quello dell'utente. La creazione di un nuovo gruppo (vuoto) denominato (as es.) topolinia può avvenire ad opera dell'utente root, eseguendo il comando addgroup topolinia, mentre l'inserimento (ad es.) dell'utente (esistente) pippo nel gruppo topolinia avviene eseguendo il comando adduser pippo topolinia.
Il proprietario del file è quello il cui nome compare nella terza colonna; in Linux, ogni utente può appartenere ad uno o più gruppi, mentre i files possono appartenere ad un solo gruppo, descritto dal nome che compare nella quarta colonna. Se un utente vuole operare su di un suo file, si applicano i diritti descritti dal primo gruppo di lettere; se invece il file non è suo, ci sono due possibilità:
Per impostare il proprietario e il gruppo del file prova.txt si può usare il comando chown (change owner)
| chown utente.gruppo prova.txt |
mentre per modificare i tre gruppi di permessi, si usa il comando chmod
| chmod ABC prova.txt |
in cui ABC rappresenta un numero di tre cifre ottali, ognuna delle quali codifica i tre bit dei permessi rwx, dando alla r peso 4, alla w peso 2 ed alla x peso 1, in accordo allo schema
| Permessi | ABC | Descrizione |
| rw-r--r-- | 644 | L'utente proprietario può accedere al file in lettura e scrittura (4+2=6), mentre sia gli appartenenti al gruppo, sia gli altri utenti, possono solo accedervi in lettura. |
| rwxr-x--- | 750 | L'utente proprietario può accederre al file in lettura, scrittura ed esecuzione (4+2+1=7); gli utenti appartenenti al gruppo possono accedervi in lettura e in esecuzione (4+1=5); gli altri utenti non possono accedervi in alcun modo. |
| rw------- | 600 | L'utente proprietario può accedere al file in lettura e scrittura (4+2=6), mentre tutti gli altri non possono accedervi affatto. |
Si tratta di un utente particolare, il cui nome è appunto root (radice), al quale non si applicano le restrizioni definite dai privilegi necessari per l'accesso ai files, e che quindi può compiere qualunque operazione sugli stessi. In particolare, le operazioni che determinano conseguenze che interessano l'intero computer, e non il singolo utente, possono essere intraprese solamente dall'utente root.
Per eseguire un programma, non è sufficiente che il suo codice eseguibile sia contenuto in un file, ma devono essere verificate due altre condizioni, ovvero
Quando un programma viene eseguito, eredita l'identità ed il gruppo dell'utente che lo ha lanciato; in particolare, il programma potrà eseguire solo le operazioni che sono possibili per tale utente: potrà cioé leggere/scrivere solo le directory ed i files che sono a loro volta da questi leggibili/scrivibili. Quindi, anche se un programma appartiene a root (che è il super utente di amministrazione, che può fare qualunque cosa, senza rispetto per i permessi vigenti), quando questo viene lanciato da un "utente normale", i diritti del programma sono gli stessi dell'utente che lo ha lanciato.
I programmi demoni che realizzano la funzione di server, e che si pongono in ascolto sulle porte ben note con un indirizzo di trasporto inferiore a 1024, per poter utilizzare queste porte, devono essere eseguiti assumendo i privilegi di root, cosa possibile solo se è root stesso a mandarli in esecuzione. Il motivo di questa scelta risiede nella considerazione che, essendo tali programmi in grado di rispondere a richieste di servizio esterne, devono essere sotto il diretto controllo dell'amministratore del computer.
D'altra parte (forse per non essere continuamente chiamato in causa) root può delegare la possibilità di lanciare il programma ad un utente qualunque: ciò avviene agendo su di un ulteriore attributo del file, il bit suid (Set User IDentity), che quando è settato, permette al programma di acquisire i privilegi del suo proprietario, anzichè quelli di chi l'ha lanciato. Generalmente in questi casi il programma, dopo aver completato le operazioni per le quali sono necessari i privilegi di root, come ad esempio aprire socket su porte ben note ed aprire i files di log, cede i propri privilegi, e torna ad assumere quelli di un utente non privilegiato, invocando la system call setuid(). In questo modo, se durante il proseguimento della sua esecuzione si dovesse verificare una qualche situazione non prevista, tale da indurre il programma ad effettuare operazioni che potrebbero compromettere la sicurezza del sistema, il programma stesso non potrà arrecare danni a nessuna configurazione critica, proprio in virtù dei bassi privilegi di cui gode. Quanto esposto, è una delle ragioni della scarsa attaccabilità di un sistema Unix, rispetto ad altri.
Quando un utente non privilegiato ha necessità di accedere a delle risorse concesse solo a root, oppure di eseguire un programma come root, deve diventare root mediante il comando
| su - |
ed inserire la password di root; l'opzione meno (-) provoca l'esecuzione del .bashrc di root, e quindi l'assegnazione di valori per le variabili di ambiente definite per root. Al termine delle operazioni, l'utente può tornare in sé con la combinazione di tasti Control-d. Nel caso si dimentichi di farlo, continuerà a lavorare come root, con il rischio di modificare inavvertitamente files importanti, o di creare files che poi come utente non privilegiato, non riuscirà più a modificare.
Questa rigida suddivisione di ruoli tra super-utente e utenti non privilegiati, oltre che offrire una maggiore sicurezza, affonda le sue radici nel tempo in cui un unico computer era usato allo stesso tempo da utenti diversi, ed era amministrato da una terza persona. Attualmente, è molto più probabile che il computer sia usato da una unica persona, contemporaneamente utente ed amministratore; oppure, che chi possiede la password di root non desideri "darla in giro" così facilmente, e nemmeno dover ogni volta andare ad immetterla di persona. Inoltre, l'utente root potrebbe voler esplicitamente delegare a qualche utente non privilegiato, l'esecuzione di alcuni compiti particolari. Per questi motivi, si è nel tempo affermato il meccanismo previsto dal comando sudo (Super User DO), che permette ad un utente non privilegiato di assumere l'identità di root per il tempo strettamente necessario alla esecuzione di un comando, immettendo
| sudo comando |
seguito dalla propria (di utente non privilegiato) password; infatti, in questo caso occorre solamente sincerarsi che l'utente sia proprio lui, in quanto abilitato ad eseguire quel comando con i privilegi di root, e non qualcun altro che per caso passa davanti al computer lasciato incustodito da chi aveva acceduto inizialmente. Al termine della esecuzione del comando, l'utente riprende automaticamente la propria identità. L'utente root può, editando il file /etc/sudoers, abilitare i diversi utenti ad eseguire uno o più comandi con i privilegi di root. Una configurazione particolarmente permissiva di questo file, permette di far fare tutto a tutti, ed è quella usata ad esempio nella distribuzione Ubuntu.
Benchè anche con un sistema Linux, si possa fare praticamente tutto senza togliere la mano dal mouse, l'uso dei comandi da tastiera permette da un lato di comprendere meglio ciò che succede, e dall'altro costituisce spesso il modo più rapido di eseguire un comando, indipendentemente dall'interfaccia grafica, a partire dalla memoria della sua sintassi. In rete esistono diversi tutorial relativi a questi aspetti, come MPL, Appunti di Informatica Libera, IGL, a cui è sicuramente opportuno far riferimento per una trattazione più dettagliata rispetto a quella che brevissimamente riassumiamo qui. Si tenga comunque presente che è prassi comune, in caso di dubbio, invocare i comandi con l'opzione -h oppure --help, per avere un breve riassunto della modalità di invocazione.
| comando | utilizzo |
| man comando | visualizza la manpage del comando, che ne spiega la funzione, e le opzioni possibili |
| apropos chiave | visualizza i comandi per i quali chiave compare nella rispettiva manpage |
| which comando | mostra in quale directory (tra quelle elencate in $PATH) si trova il comando |
| echo $VAR | mostra il valore della variabile di ambiente VAR, che può essere assegnato mediante il comando set VAR=valore |
| set VAR=valore | assegna valore a VAR - anche se 'set' è opzione, e lo stesso risultato si ottiene con 'VAR=valore'. Scrivendo poi (ad es.) VAR=$VAR:elevato, otteniamo che VAR contiene 'valore:elevato' |
| ls | mostra (lista) i contenuti di una directory |
| pwd | print working directory - dice dove ci si trova |
| cd path | change directory - per spostarsi, in modo assoluto (sui path che iniziano per /) oppure relativo (path che iniziano con il nome di sotto-directory, oppure ../ per specificare la directory padre) |
| cp file1 file2 | copy - copia file1 in file2. In generale, nei comandi dove compaiono due argomenti, il primo indica quello di partenza (esistente), ed il secondo quello che viene creato |
| mv file1 file2 | move - rinomina file1 in file2 |
| rm file | remove - cancella (irreversibilmente!) un file |
| mkdir dir | make directory - crea una directory |
| rmdir dir | remove directory - rimuove una directory (se è vuota) |
| tar | tape archive - comprime/scomprime un archivio con estensione .tar o .tar.gz o .tgz (ma esiste anche zip/unzip) |
| ln -s file1 file2 | link - crea un collegamento simbolico file2 che punta al file esistente file1 |
| mount cosa dove | rende visibile il device o partizione cosa, come contenuto del path dove nel filesystem |
| cat file1 [file2 ..] |
concatenate - stampa a schermo il contenuto di un file di testo. Se invocato con più argomenti, li stampa uno dopo l'altro, e se stdout è rediretto su di un file, si ottiene il risultato di concatenarli tra loro (da cui, il nome del comando) |
| tail file | (coda) - visualizza le ultime 10 linee di file. Molto utile l'opzione -f che non ritorna, e che dopo le ultime 10 linee, visualizza anche le aggiunte che qualche altro programma fa al file |
| less file | visualizza un file di testo, e permette di navigarci all'interno mediante le frecce della tastiera, o Pgup/Pgdown, o Home/End. Per cercare una stringa dentro il file, inserire /stringa |
| sort | ordina stdin e scrive il risultato su sdtout, molto utile se messo in pipe con altri comandi, o se si fa uso della redirezione di ingresso/uscita |
| df | disk full - mostra l'occupazione del disco, mentre du (disk usage) mostra le dimensioni di files/directory |
| chmod modo file | change mode - modifica i permessi associati al file |
| chown utente.gruppo | change owner - modifica il proprietario di un file, settando utente e gruppo (facoltativo) |
| passwd | permette di cambiare la propria password |
| su utente | permette di diventare un altro utente, fornendo la sua password. Se l'utente non è specificato, si diviene root; se viene inserita l'opzione - (meno) verrano usate le variabili di ambiente di quell'utente |
| lpq | line printer queue - mostra la coda dei lavori da stampare |
| lprm numero | line printer remove - rimuove una stampa dalla coda. Utile qualora si richieda una stampa per errore, e poi ci si ripensi |
| kill -segnale pid | invia un segnale al processo pid |
| ps ax | processes - visualizza un elenco dei processi in esecuzione sul computer. Sono a volte utili anche le opzioni u per conoscere l'utente i cui privilegi gli sono riconosciuti, f per capire chi è figlio di chi, w per mostrare il comando per intero e non troncarlo alla larghezza della finestra |
| grep stringa file | cerca in file l'occorrenza di stringa. Molto utile se messo in pipe con l'uscita di un altro comando, ad esempio ps, nel qual caso non occorre specificare file, dato che viene usato stdin. Se per file si specifica *, la stringa è cercata in tutti i file della directory, mentre specificando l'opzione -nr, la ricerca avviene in modo recursivo anche in tutte le sotto-directory, e vengono stampati i numeri di linea in cui si è trovata l'occorrenza di stringa. |
| top | mostra interattivamente i processi correnti, dando la possibilità di ordinarli in base ad esempio all'uso di CPU, di memoria o di durata |
Inoltre, la comunità Debian ha prodotto una simpatica Quick
Reference Card, da stampare su di un
solo foglio.
Diversi dei comandi riportati possono accettare come argomento più di un singolo nome di file. In tal caso può essere utile descrivere un insieme di files dai nomi simili, per mezzo di caratteri jolly, in grado di corrispondere a caratteri qualunque: in particolare, il simbolo * (asterisco) corrisponde ad una qualsiasi stringa, mentre il simbolo ? (punto interrogativo) corrisponde ad un singolo carattere qualunque. Quindi ad esempio, possiamo scrivere
| cat * # concatena tutti i files presenti cat fi* # concatena tutti i files presenti, che iniziano per "fi" cat fi?e # concatena tutti i files con nome ad es pari a file, fice, fide, fine, fife... |
Ogni file è contenuto all'interno di una directory, che a sua volta può contenere altre sotto-directory. Il termine directory, ad un certo punto della storia, è stato tradotto in italiano come "cartella". Il filesystem rappresenta l'ordinamento gerarchico di tutte le directory presenti sul disco. Possiamo spostarci da una directory all'altra mediante il comando cd (change directory). Tra le directory, notiamo
Nel mondo Linux e Unix, si è sviluppata una iniziativa per rendere la struttura gerarchica delle directory il più possibile simile tra sistemi diversi, in modo da favorire l'interoperabilità delle piattaforme. Questo ha portato ad una specializzazione delle diverse directory, in accordo a questa tabella:
| Directory | Utilizzo |
| /bin | qui risiedono molti dei files eseguibili |
| /etc | contiene tutti i files di configurazione, spesso suddivisi in directory individuali per i diversi programmi |
| /lib | ospita le librerie, spesso in forma di shared object (estensione .so), ed i links alle versioni specifiche delle stesse |
| /home | contiene le sottodirectory associate alle case dei diversi utenti |
| /proc | rappresenta un filesystem virtuale, che non esiste fisicamente, ma i cui files sono creati al volo dal kernel quando vengono visitati. Costituisce una modalità di comunicazione tra user-space e kernel |
| /sbin | ospita files eseguibili solo da root |
| /var | contiene files e sotto-directory i cui contenuti possono variare di molto, come ad esempio /var/log per i files di registro, e /var/spool per l'email e le code di stampa |
| /usr | acronimo di Unix System Resources, è stata definita inizialmente per ospitare dati condivisi tra diversi computer, e non dovrebbe contenere configurazioni specifiche |
A volte, parte di questa struttura viene ripetuta ricorsivamente, così ad esempio all'interno della /usr, è possibile trovare /usr/bin, /usr/etc, /usr/lib... ma anche cose più specifiche, come /usr/src per i files sorgente, /usr/include per i .h, /usr/share/doc con la documentazione dei pacchetti installati. Infine, in /usr/local trovano spesso posto dei files creati dall'utente, od importati in forma di sorgente.
La shell, ed alcuni programmi, attribuiscono a tasti particolari, funzioni particolarmente utili. Mentre dialoghiamo con la shell
Durante l'osservazione del risultato ottenuto con il comando less:
Shell vuol dire conchiglia, significando con ciò la sua funzione di racchiudere l'utente. Infatti, la shell è il programma che interpreta ed esegue i comandi immessi dall'utente dentro una finestra terminale, e viene eseguito automaticamente dal sistema quando un utente effettua il login. Dunque, quando viene aperto un terminale, viene parallelamente eseguito un programma shell, i cui stream stdin, stdout e stderr vengono associati al terminale stesso.
Quando viene impartito un comando mediante un terminale, questo viene analizzato dalla shell, per vedere se si tratta di un comando interno, ovvero che la shell stessa può eseguire in modo autonomo: l'elenco dei comandi interni può essere scoperto invocando help. Altrimenti (non è un comando interno), viene effettuata una ricerca nell'ambito delle directory specificate dalla variabile di ambiente PATH, per trovare un eseguibile denominato come il comando invocato. Se invece il comando inizia per ./, oppure con un diverso path (relativo o assoluto), allora la shell cerca (nella directory corrente od in quella indicata) un file con nome pari al comando, con il bit di esecuzione settato, e contenente un programma compilato, oppure uno script.
I comandi da far eseguire alla shell sono immessi da tastiera, oppure sono contenuti, uno dopo l'altro, all'interno di un file che pur essendo di solo testo, viene reso eseguibile, ad es. mediante il comando chmod 755. Un file del genere viene chiamato file di comandi o script, e contiene una sequenza di comandi ed istruzioni dello stesso tipo di quelle che potremmo immettere da tastiera, assieme ad istruzioni di controllo, come quelle di loop (es. for) e diramazione (es if), dimodoché uno script costituisce un vero e proprio programma. Uno script può essere eseguito fornendone il nome come opzione al comando che esegue una nuova shell (ossia bash script), oppure inserendo alla prima linea la stringa #!/bin/bash e rendendolo eseguibile con chmod 755 script.
A differenza dei programmi as es. in C, a cui corrisponde del codice eseguibile solo dopo un processo di compilazione e linking che produce il codice assembler corrispondente, uno script viene detto programma interpretato perché manca la fase di compilazione, e la shell è chiamata ad interpretarlo, in quanto si limita ad eseguire uno dopo l'altro una serie di comandi, ad ognuno dei quali corrisponde del codice già compilato, senza nessuna preoccupazione a riguardo di una possibile ottimizzazione complessiva. Non per nulla, script in inglese significa copione, che viene per l'appunto interpretato dalla shell!
Esistono diverse shell sotto Unix, ma la più diffusa con Linux è bash, o Bourne Again Shell, per il quale un buon riferimento è [GAB]. Come un qualunque linguaggio di programmazione che si rispetti, anche la shell ha le sue variabili, che prendono il nome di variabili di ambiente.
Le variabili di ambiente prendono questo nome per il fatto che esistono al difuori di un determinato programma, e costituiscono in tal senso una sorta di "ambiente" in cui il programma viene eseguito. Nell'ambiente definito da una finestra terminale, e quindi delimitato da una shell interattiva, possiamo assegnare un valore ad una variabile di ambiente mediante la classica sintassi in cui compare il segno di uguale (senza spazi). Per accedere invece al suo valore, occorre prefissarne il nome con il segno $. Ad esempio
| ~$ SEDE=Latina # assegnamo un valore alla variabile
SEDE ~$ echo $SEDE # chiediamo la stampa del suo valore Latina # il valore è stampato |
Due programmi eseguiti in sequenza possono passarsi dei valori mediante le variabili di ambiente, se il primo le setta, ed il secondo le legge. In particolare, attribuendo loro un valore mediante la sintassi
| ~$ export SEDE=Cisterna |
ne definiamo l'ereditarietà, ovvero estendiamo l'ambiente in cui sono definite, permettendone la lettura anche da parte dei processi figli. Alcuni esempi di variabili di ambiente, possono essere ottenuti con il comando man environ; mentre la lista di quelle attualmente definite, si ottiene con il comando env. Infine, un metodo per definire uno stesso insieme di variabili di ambiente nell'ambito di script differenti, è di creare un unico script con tutte le definizioni, e poi includere tale file dove occorre, mediante il comando source, abbreviato come . (punto).
Creiamo un file con gedit prova.sh e inseriamo i seguenti comandi
| echo 'A=primo' > inc echo 'B=secondo' >> inc echo "le variabili A e B sono ancora vuote: $A $B" echo "ora le poniamo in essere" . inc echo "infatti ora troviamo A = $A e B = $B" rm inc |
ed eseguiamo lo script invocando bash prova.sh, verificandone il corretto funzionamento. Se però ora proviamo nuovamente a leggere la variable con echo $A troviamo... che è vuota! Infatti, le inizializzazioni dello script sono relative all'ambiente della shell eseguita per interpretare il file, e dunque scompaiono assieme al termine di quella shell. Suggerimento: aggiungere in coda al file il comando ps f, in modo da verificare la presenza di una shell figlia.
Dopo aver chiuso la shell entro la quale abbiamo definito delle nuove variabili di ambiente, queste cessano di esistere. Ci chiediamo allora: da dove hanno origine quelle che osserviamo già esistenti, quando apriamo una nuova finestra terminale ? Hanno due origini:
Una variabile d'ambiente particolarmente importante, è PATH, che contiene una serie di percorsi nel filesystem separati da due punti, che indicano in quali directory va a cercare la shell, per tentare di eseguire un comando immesso da tastiera. Le directory vengono esaminate nell'ordine con cui compaiono, per cui possono esistere due eseguibili con lo stesso nome, in due diverse directory, ma verrà sempre eseguito quello ospitato nella directory esaminata per prima.
Se vogliamo eseguire un comando presente nella directory in cui ci troviamo, occorre lanciarlo come ./programma. Non è consigliabile inserire ./ nel PATH, perché potremmo inavvertitamente mascherare un programma preesistente con lo stesso nome.
Altre variabili famose, sono $HOME, $LD_LIBRARY_PATH, $DISPLAY...
 Ogni programma al momento della sua esecuzione
ha tre file già aperti, denominati standard
input, standard output e standard error (stdin,
stdout, stderr)
che di default, sono collegati all'input da tastiera, all'output su
schermo, ed all'output dove scrivere gli errori (sempre lo schermo). E'
molto
facile
redirigere l'uscita, anziché sullo schermo, dentro un file, così come
redirigere il contentuto di un file, come se fosse immesso da tastiera,
mediante i simboli < e > (minore e maggiore). Ad
esempio:
Ogni programma al momento della sua esecuzione
ha tre file già aperti, denominati standard
input, standard output e standard error (stdin,
stdout, stderr)
che di default, sono collegati all'input da tastiera, all'output su
schermo, ed all'output dove scrivere gli errori (sempre lo schermo). E'
molto
facile
redirigere l'uscita, anziché sullo schermo, dentro un file, così come
redirigere il contentuto di un file, come se fosse immesso da tastiera,
mediante i simboli < e > (minore e maggiore). Ad
esempio:
| ~$ ls > pippo.txt # standard ouput
rediretto sul file pippo.txt, nuovo o
sovrascritto ~$ ls ../ >> pippo.txt # ora l'output è concatenato al file preesistente ~$ comando 2> errori.txt # standard error del programma comando rediretto su errori.txt ~$ sort < pippo.txt > pluto.txt # sort accetta pippo.txt come input, e devia l'output su pluto.txt |
Le pipe (tubature) permettono di costruire comandi più complessi a partire da quelli a disposizione, redirigendo l'uscita di uno verso l'ingresso dell'altro, semplicemente immettendo i due comandi sulla stessa riga, separati dal simbolo di barra (es comando1 | comando2). Ad esempio, possiamo provare ad immettere
| ~$ cd / # ci portiamo alla root del file
system ~$ ls -R # scopriamo tutti i files nel nostro computer <control>-c # interrompiamo lo scroll ~$ ls -R | less # l'uscita di ls viene diretta in ingresso a less, # che ne effettua la paginazione ~$ ls | sort # l'uscita di ls viene diretta in ingresso a sort, # che ne effettua l'ordinamento |
Ad ogni processo in esecuzione, viene assegnato un numero chiamato PID (Process IDentifier), che lo identifica univocamente, e che permette di interagire con lo stesso, ad esempio inviandogli segnali o terminandolo. Ad ogni processo, corrisponde una directory nel filesystem virtuale /proc.
Per conoscere il PID dei processi in esecuzione si utilizza il comando ps, che senza altre opzioni, indica solamente i processi lanciati a partire dalla shell corrente. Un gruppo di opzioni comunemente usate, è ps auxf, che (a) li mostra tutti, indicandone (u) l'utente che li ha lanciati, comprendendo anche (x) quelli lanciati da un altro processo non-shell, e (f) mostrando chi è figlio di chi. Oltre al PID, ps mostra in una serie di colonne, diversi altri parametri associati ai processi, come l'occupazione di memoria, il tempo totale di esecuzione, lo stato.
Un diverso modo per valutare l'attività del sistema, è di eseguire il comando top, disponibile assieme alle utilities del package procps. Mediante top, si ha una schermata in real-time in cui i processi sono ordinati in base all'ammontare di risorse impiegate, come ad esempio la CPU, o la memoria. Mentre top è in esecuzione, si può (con il tasto k) inviare un segnale ad un processo, indicandone il numero, ad esempio per terminarlo. Attualmente, esistono applicazioni grafiche che svolgono la stessa funzione, come ad es. il gnome system monitor.
Il comando designato ad inviare segnali ad un processo è kill, che con l'opzione -9 causa la terminazione del processo.
Un processo può essere lanciato sullo sfondo (in background) se viene invocato con una & alla fine del comando: in tal modo, si ri-ottiene il prompt dei comandi, e si può eseguire qualche altro comando. Ovviamente, la cosa ha un senso purché il programma mandato in background, non richieda un input da tastiera! Per riportare il programma sotto il controllo della tastiera, si può eseguire il comando fg (foreground). Si può mandare un comando (già lanciato in modalità interattiva) in background, prima interrompendolo (premendo control-z), e quindi digitando bg (che sta per background, appunto). Infine, si può interrompere un programma che è eseguito in foreground, con la combinazione di tasti control-c. Per terminare un programma in background senza riportarlo in foreground, si può verificare il suo pid mediante il comando ps ax, e quindi usare il comando kill pid, oppure kill -9 pid, se il programma non termina.
Un programa di utente, oltre alle istruzioni macchina prodotte dalle proprie linee di codice, può eseguire codice contenuto in librerie, e codice che viene eseguito all'interno del kernel del sistema operativo, come ad esempio per accedere a delle risorse fisiche, all'hardware, od alla rete. L'invocazione di questo codice esterno è indicata come system call, che spesso in realtà non esegue direttamente una funzione offerta dal kernel, ma invoca una funzione di libreria (come per la glibc) che risiede nello spazio di utente, e che a sua volta invoca la funzionalità del kernel.
La compilazione di un programma di utente che invoca delle system call non può avere successo se questo non include, nella parte iniziale, i riferimenti ai files .h (gli header files) che contengono le definizioni di tipo di dato ed i prototipi delle chiamate a funzione, in modo che il compilatore possa verificare la correttezza formale delle chiamate, e produrre un codice oggetto che potrà linkarsi con successo alle funzioni esterne.
Per osservare le chiamate di sistema che vengono effettuate da un processo, Linux offre il comando strace, con cui lanciare il programma. In alternativa, si può attaccare strace ad un programma già in esecuzione, utilizzando l'opzione -p.
Il cuore operativo della architettura di un computer è la CPU, che esegue le istruzioni in linguaggio macchina presenti nel codice eseguibile, ed alcuni flag della CPU inibiscono o meno l'esecuzione di alcune istruzioni. Ad esempio, i programmi utente non possono accedere a regioni di memoria estranee allo spazio di indirizzamento che compete a ciascuno di essi, evitando così che errori di programmazione in uno di questi provochino conseguenze su altri programmi. Al contrario, quando la CPU si trova in Supervisor mode, come quando viene eseguito il kernel, il codice macchina può eseguire qualunque operazione - pertanto, si assume che il codice del kernel sia esente da errori!
 I
diversi programmi contemporaneamente in esecuzione sono in effetti
eseguiti uno alla volta a rotazione, intervallati dalla esecuzione del
kernel, che può ad esempio, in caso di necessità, decidere di spostare
parte della memoria usata da un programma utente nella partizione
di swap, per poi recuperarla successivamente - mentre la memoria
usata dal kernel non viene mai swappata.
Al kernel è poi delegato il compito di dialogare direttamente con
l'hardware presente, mentre i programmi applicativi possono farlo solo
per suo tramite, in modo che non debbano essere modificati in presenza
di una nuova versione di hardware.
I
diversi programmi contemporaneamente in esecuzione sono in effetti
eseguiti uno alla volta a rotazione, intervallati dalla esecuzione del
kernel, che può ad esempio, in caso di necessità, decidere di spostare
parte della memoria usata da un programma utente nella partizione
di swap, per poi recuperarla successivamente - mentre la memoria
usata dal kernel non viene mai swappata.
Al kernel è poi delegato il compito di dialogare direttamente con
l'hardware presente, mentre i programmi applicativi possono farlo solo
per suo tramite, in modo che non debbano essere modificati in presenza
di una nuova versione di hardware.
Il kernel di Linux è di tipo monolitico, ma questo non significa che sia tutto di un pezzo! Al contrario, il controllo specifico dei diversi tipi di harware è delegato a sotto-componenti del kernel dette moduli, dei quali risultano in esecuzione solo quelli che gestiscono l'hardware effettivamente presente, riducendo così la memoria occupata dal kernel. L'invocazione dei moduli necessari avviene di norma in modo automatico, interrogando i vari bus di sistema, o mediante hotplug per le unità rimovibili. Quindi, sarà possibile interrogare quali sono in uso, rimuoverli e ricaricarli (ad es. per facilitarne lo sviluppo).
Quando un computer Linux viene avviato, dopo una serie di operazioni necessarie a caricare il kernel dalla partizione di disco corretta, il primo programma ad essere eseguito è init, che nella impostazione classica di Unix SystemV (quinto), determina il dafarsi in base all'esame del file /etc/inittab, che però in Ubuntu non è più presente. Nel file inittab viene definito, tra le altre cose, il runlevel iniziale del sistema, che consiste in un numero tra zero e sei, e che determina quali processi debbano essere attivati, e quali arrestati. Questi processi particolari prendono il nome di servizi. Ad ogni servizio che può essere avviato, corrisponde uno script presente nella directory /etc/init.d, che può essere invocato con le opzioni start, stop, restart, status, ed altre.
Per ogni runlevel N, esiste una directory /etc/rcN.d, che contiene una serie di link simbolici agli script presenti in /etc/init.d: i link non esistono per tutti i file, ma solo per quelli rilevanti per quel runlevel. Questi link simbolici prendono lo stesso nome dello script target, prefisso con una lettera ed un numero. La lettera può essere una S oppure una K, significando Kill o Start di quel servizio, mentre il numero serve a stabilire un ordine temporale per la partenza/uccisione dei diversi servizi. Gli script presenti in /etc/init.d possono essere invocati in qualunque momento, anche dopo il boot, per avviare o terminare i servizi in modo pulito.
Ad esempio, per avviare un servizio scriveremo sudo /etc/inid.d/nomeservizio start, oppure stop per arrestarlo. Alcune distribuzioni Linux (Red Hat, Fedora, Ubuntu), permettono di usare anche la sintassi service nomeservizio start, un pò più elegante, ma del tutto equivalente alla modalità precedente, tanto è vero che se si va a vedere, gli script di avvio sono ancora tutti al loro posto.
Una particolarità della modalità di avvio SystemV è che i servizi sono madati in esecuzione uno dopo l'altro, ed ogni servizio è avviato solo dopo che il precedente ha completato la propria inizializzazione, provocando un lentezza intrinseca del processo. Recentemente sono state proposte delle alternative, come Initng, oppure Upstart, che è usato da Ubuntu, e che ha il vantaggio di essere compatibile con gli script di SystemV. Con Upstart la sequenza di boot opera in modo asincrono e si basa su eventi, il cui verificarsi determina il lancio dei servizi, permettendo l'avvio concorrente di tutti quelli che non presentano dipendenze reciproche. Di fatto upstart sostituisce le funzioni di init, ed il suo funzionamento event-driven gli permette di gestire correttamente anche la detezione di nuovo hardware (es. pen-drive, carte pcmcia) e il caricamento di firmware nei dispositivi.
Gli strumenti grafici per la configurazione degli script di init, e che permettono di lanciare/arrestare i servizi, ovvero fare in modo che questi partano (o meno) al momento del boot, sono piuttosto specifici delle diverse distribuzioni, come ad esempio descritto presso il wiki di Ubuntu; uno strumento abbastanza semplice ed efficace per impostare i servizi da far partire (o meno) è BUM (Boot-Up Manager), presente nei repository di Ubuntu.
Si tratta di uno script che viene eseguito dopo che sono stati lanciati tutti gli altri processi da eseguire all'avvio. Qualora si intenda personalizzare il comportamento del proprio computer eseguendo dei comandi particolari, ad es. per modificare le impostazioni della rete, ma senza per questo andare a toccare altri file di sistema, questo è un buon posto dove inserire i comandi relativi.
A differenza di Windows, Linux continua a funzionare anche in assenza della interfaccia grafica. Oltre all'ambiente grafico, in Linux sono contemporaneamente in esecuzione diversi terminali testuali (i processi getty mostrati dal comando ps ax) cui si può accedere con la combinazione di tasti control-alt-Fn; con F6 si torna quindi all'ambiente grafico.
 Le
applicazioni grafiche si basano su di una architettura client-server,
in cui il programma applicativo chiede al server grafico di generare
l'output. Il server grafico può anche risiedere su di una altra
macchina: ad es, se mi collego via rete sul terminale di una macchina
remota, e vi eseguo un programma grafico, posso visualizzare la
relativa finestra sul mio computer. Un comando che svolge in
modo semplice questa funzione è
Le
applicazioni grafiche si basano su di una architettura client-server,
in cui il programma applicativo chiede al server grafico di generare
l'output. Il server grafico può anche risiedere su di una altra
macchina: ad es, se mi collego via rete sul terminale di una macchina
remota, e vi eseguo un programma grafico, posso visualizzare la
relativa finestra sul mio computer. Un comando che svolge in
modo semplice questa funzione è
| ssh -X computer_remoto |
che apre una shell remota, e permette di mandare in esecuzione programmi con output grafico, che sono mostrati nel mio desktop.
Il nome storico del server grafico è X Window System X11, noto anche come X11 o X. Interfacciandosi direttamente all'hardware (mouse, tastiera, video), è concettualmente parte del sistema operativo, ed usa dei driver specifici per controllarlo. Come mostrato dalla figura a sinistra, i programmi che producono un risultato grafico e/o accettano l'input da tastiera o dal mouse, non lo fanno direttamente, ma richiedendo l'intercessione dell'X Server, che offre delle primitive di controllo molto basilari.
 |
 |
Fortunatamente, non occorre che un programma grafico conosca il protocollo con cui dialogare direttamente con il server X, ma ne delega l'uso alle procedure offerte dalla libreria Xlib. Dato che anche Xlib offre funzioni di livello piuttosto basso, con il tempo sono stati sviluppati dei widget toolkit come Motif, Gtk+, Qt, Fltk... che facilitano la realizzazione degli elementi grafici.
E' il componente che realizza l'astrazione delle finestre, gestendo
Anche se intercambiabili, gli Window Manager sono spesso legati a particolari Widget Toolkit e Desktop Environment, e la loro combinazione determina l'effetto finale del desktop della distribuzione che scegliamo di installare:
| Window manager | Kwin | Metacity | Xfwm |
| Widgets toolkit | Qt | Gtk+ | Gtk+ |
| Desktop Environment | Kde | Gnome | Xfce |
| Distribuzione | Kubuntu | Ubuntu | Xubuntu |
L'ambiente desktop estende le funzionalità offerte da Window Manager e Widgets offrendo un insieme di programmi ed elementi visuali che cooperano alla realizzazione della metafora della scrivania, prevedendo
L'interoperabilità tra applicazioni che usano librerie grafiche diverse è studiata dal progetto freedesktop.org, mentre tra i diversi DE esistenti, i più diffusi per Linux sono
Un sistema GNU/Linux è il risultato di un puzzle di applicazioni, processi e demoni della più disparata origine e ciclo di sviluppo. La realizzazione di una particolare distribuzione Linux necessita di un lavoro di selezione di quali programmi includere, e di armonizzazione del loro funzionamento. La natura dell'OpenSource fa si che ogni distribuzione può potenzialmente essere presa come punto di partenza per un'altra, dando luogo ad una vera a e propria dinastia di discendenti. Le distro esistenti da più tempo, e che continuano sia ad essere supportate che a produrre distro derivate, sono Slackware, RedHat/Fedora, e Debian/Ubuntu, e quest'ultima è innegabilmente la più diffusa.
Mentre i programmi inclusi continuano ad essere sviluppati e corretti, una particolare versione di distribuzione a sua volta rilascia gli aggiornamenti dei programmi inclusi, per mezzo di un sistema di repository, che vengono periodicamente consultate dai programmi di aggiornamento automatico. Gli stessi repository consentono anche di installare componenti inizialmente non presenti, assieme a quelli da cui essi dipendono. Ad es. Debian (e quindi Ubuntu) si basa sul formato apt, che offre per il suo utilizzo sia un insieme di comandi da terminale, sia applicazioni grafiche come Synaptic.
Le diverse versioni di una stessa distribuzione sono intervallate da un periodo di sviluppo durante il quale si rivede la composizione delle applicazioni fornite, inserendone di promettenti e scartando quelle meno utili o superate, mentre dopo l'uscita di una nuova versione, i suoi aggiornamenti sono mantenuti per un periodo di supporto che dura tipicamente tra i due ed i cinque anni.
Così come Ubuntu è derivata da Debian, tutti possono creare la propria distribuzione a partire da una esistente, dopo averla personalizzata ed aver inserito i programmi che la caratterizzano. O se vogliamo essere ancora più originali, possiamo anche crearla da zero!
Si tratta della possibilità di eseguire programmi in momenti specifici della giornata, come ad es. durante la notte, oppure ogni ora, od una volta la settimana, al mese, all'anno. Il servizio cron viene fatto partire all'avvio del computer, ed ogni minuto ispeziona una serie di directory e di files, in cui trova scritti i programmi da eseguire, quando, e per conto di chi; se per qualcuno di questi ci si trova nel minuto richiesto, viene eseguito. Il file mediante il quale l'utente root definisce i compiti ricorrenti da eseguire è /etc/crontab, mentre nella directory /etc/cron.d possono essere presenti altri files con lo stesso formato, che aderisce alla sintassi
| .---------------- minuto (0 - 59) | .------------- ora (0 - 23) | | .---------- giorno del mese (1 - 31) | | | .------- mese (1 - 12) OPPURE jan,feb,mar,apr ... | | | | .---- giorno (0 - 7) OPPURE sun,mon,tue,wed,thu,fri,sat | | | | | * * * * * utente comando_da_eseguire |
in cui i primi 5 campi definiscono l'istante di partenza del comando, oppure il carattere * ad indicare qualsiasi (minuto, ora, giorno..), ed il sesto individua l'identità con i cui questo deve essere eseguito. Sebbene il comando da eseguire possa essere un programma qualunque, spesso si tratta di run-parts, che provvede ad eseguire tutti i comandi che si trovano nella directory che gli viene indicata. Un tipico file /etc/crontab ha l'aspetto (le righe che iniziano con # sono commenti)
| # /etc/crontab: system-wide crontab SHELL=/bin/sh PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin # m h dom mon dow user command 17 * * * * root cd / && run-parts --report /etc/cron.hourly 25 6 * * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily ) 47 6 * * 7 root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.weekly ) 52 6 1 * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.monthly ) |
e le directory /etc/cron/hourly, /etc/cron/daily, /etc/cron/weekly e /etc/cron/montly contengono programmi da eseguire ogni ora, giorno, settimana o mese, inseriti lì dai demoni server che vengono installati, e che provvedono ad eseguire funzioni di manutenzione, come ad esempio la rotazione dei file di log. All'inizio di /etc/crontab, notiamo l'inizializzazione di variabili di ambiente che saranno poi usate dai programmi invocati. L'eventuale output prodotto verso stdout dai programmi lanciati da cron, se non rediretto altrove, viene inviato per email all'utente la cui identità è stata usata per eseguire il programma; in alternativa, viene inviato all'utente indicato dalla variabile di ambiente MAILTO (se definita).
I normali utenti non privilegiati (eventualmente filtrati mediante i files /etc/cron.allow e /etc/cron.deny) non editano un file specifico, ma lo creano mediante il comando crontab, che poi lo copia in un percorso apposito.
Il meccanismo illustrato ha l'inconveniente che, se il computer è spento al momento in cui dovrebbe essere eseguito uno dei comandi previsti, questo salta il giro. Per ovviare a ciò è stato definito il comando anacron, che esegue i programmi non più frequentemente che una volta al giorno, e che si basa sul contento del file /etc/anacrontab, che a sua volta replica i comandi presenti in /etc/crontab e che richiedono una cadenza giornaliera o più. Pertanto, nell'esempio mostrato sopra, cron evita di scandagliare le directory daily, weekly e monthly se si accorge che esiste l'eseguibile anacron. Quest'ultimo, se si rende conto che un compito è scaduto, lo esegue anche se in ritardo, e poi ricorda quando l'ha eseguito.
Una ulteriore possibilità di prenotare l'esecuzione (non ricorrente) di un comando ad un momento prestabilito, è mediante il comando at.
E' quello che ci permette di acquisire qualche informazione in più a riguardo del comportamento dei programmi in esecuzione. Anzichè lasciare che ognuno di questi risolva il problema in modo autonomo, ad esempio scrivendo su schermo, o su di un file disperso in una qualche directory, Linux prevede che i messaggi di notifica siano inviati tutti ad una unica entità server (syslogd), offrendo così all'amministratore di sistema l'opportunità di centralizzare il controllo di come gestirli, permettendo di
Questo meccanismo è stato inizialmente definito nel 1980 come un componente di Sendmail, e dato che prevede anche la comunicazione via rete, è stato formalizzato da IETF nella RFC 5424.
Il demone syslogd determina il suo comportamento sulla base del contenuto del file di configurazione /etc/syslog.conf, in cui si trovano una serie di direttive del tipo
|
selettore
azione _______|_______ ___________________|_________________ / \ / \ facility.priority file, device, utente o @computer_remoto |
in cui
La sintassi effettiva in realtà permette cose ancora più raffinate, come (ad es.) specificare tutte le facility e/o priority mediante la wildcard *, indicare diverse facility (separate da virgole) o diversi selettori (separati da ;) per la stessa azione... di seguito, alcune righe di esempio tratte da un file /etc/syslog.conf reale:
| # First some standard logfiles. Log by facility. auth,authpriv.* /var/log/auth.log *.*;auth,authpriv.none -/var/log/syslog daemon.* -/var/log/daemon.log mail.* -/var/log/mail.log # Logging for the mail system. Split it up so that # it is easy to write scripts to parse these files. mail.info -/var/log/mail.info mail.warning -/var/log/mail.warn mail.err /var/log/mail.err # Some `catch-all' logfiles. *.=debug;\ auth,authpriv.none;\ mail.none -/var/log/debug *.=info;*.=notice;*.=warning;\ auth,authpriv.none;\ mail,daemon.none -/var/log/messages # Emergencies are sent to everybody logged in. *.emerg * |
Il primo gruppo di direttive distribuisce i messagi delle facility auth, authpriv, daemon e mail su file diversi; il - davanti ai nomi di file permette la bufferizzazione delle operazioni di scrittura, mentre la priority none inibisce la scrittura per qualunque priority della facility.
Il secondo gruppo di direttive separa i messaggi delle facility mail su diversi file, a seconda della loro priority. Il terzo gruppo usa il file /var/log/debug per accumulare i messaggi con priorità esattamente debug, tranne che se provenienti dalle facility auth, authpriv e mail; quindi usa /var/log/messages per registrare i messaggi meno gravi. Infine, l'ultima riga invia tutti i messaggi con priority emerg sul terminale di chiunque sia collegato.
Per ogni messaggio ricevuto da syslogd, tutte le regole sono applicate dalla prima all'ultima, e sono eseguite le azioni associate a tutti i selettori verificati; pertanto, è possibile che lo stesso evento sia registrato su più di un file di log.
Dopo aver discusso come vengono smistati i messaggi di log, non resta che descrivere la API usata dai programmi per dialogare con syslogd. In linguaggio c questo si ottiene mediante chiamate alla libreria syslog, e per altri linguaggi, alla sua equivalente. All'inizio delle operazioni, il programma esegue una chiamata
| openlog(const char *ident, int option, int facility); |
che definisce la stringa ident (in genere, il nome del programma) che sarà citata in tutti i record dei messaggi provenienti da quel programma, e la facility associata ai suoi messaggi. Quindi ogni volta che durante la sua esecuzione deve essere notificato un messaggio, viene eseguita la chiamata
| syslog(int priority, const char *format, ...); |
mediante la quale si imposta la priority dello stesso in funzione del suo livello di gravità, e quindi si seguono le regole di formattazione della istruzione printf() per generare il testo del messaggio.
I files prodotti da syslogd mostrano, ad ogni linea, la data e l'ora a cui si riferisce l'evento registrato, chi lo ha prodotto, ed infine il messaggio stesso. Essi si trovano nella directory /var/log, ed un modo per monitorarli e seguirne così l'evoluzione, è mediante il comando
| tail -f nomedelfile |
che dopo aver stampato a schermo le ultime dieci linee, non restituisce il controllo alla tastiera, ma prosegue a mostrare le nuove linee man mano che arrivano. Un file in cui provare a guardare per scoprire eventuali problemi inattesi, è /var/log/messages.
Non tutti i programmi fanno però uso di syslogd: ad esempio il server web Apache, per questioni di sicurezza e di efficienza, provvede in proprio a scrivere i propri log in /var/log/apache2/access.log ed /var/log/apache2/error.log in cui registra rispettivamente le visite ricevute e gli errori. Anche se, esiste comunque la possibilità di configurare apache in modo che utilizzi syslog.
Il problema con i files di log è che, lasciati a se stessi, crescono e crescono indefinitivamente, occupando sempre più spazio, e rendendo difficoltosa la loro stessa lettura. La soluzione fornita dal programma logrotate è di rinominare periodicamente i files di log aggiungendo in coda al loro nome una estensione numerica, spostando allo stesso tempo le copie più vecchie in files con estensione numericamente maggiore, e cancellando il file più vecchio, secondo lo schema
| file.log.5 -> rimosso file.log.4 -> file.log.5 file.log.3 -> file.log.4 file.log.2 -> file.log.3 file.log.1 -> file.log.2 file.log -> file.log.1 |
in modo che ora il file.log originario è vuoto, e pronto a ricevere nuovi messaggi.
logrotate viene invocato giornalmente da cron, e basa il suo operato su ciò che trova scritto nel file di configurazione /etc/logrotate.conf. In particolare, si può richiedere, per ogni file di log, di
Inoltre, /etc/logrotate.conf può richiedere di includere anche le direttive di configurazione presenti in una directory specificata, che poi è /etc/logrotate.d, dove (al momento della loro installazione) i programmi che prevedono di produrre dei files di log inseriscono i rispettivi files di configurazione.
Una ultima questione: come può un amministratore di sistema, accorgersi che qualcosa nel suo computer inizia a dare segni di cedimento (per deterioramento dell'hardware, errori dei suoi utenti, od attacchi alla sicurezza)? Come può passare gran pare del suo tempo a verificare cosa succede nei files di log? La risposta ovviamente è che non può, e per questo esistono infatti dei programmi di analisi dei files di log, che rilevano in modo automatico le condizioni anomale, e compilano statistiche sui dati letti (come ad esempio, sul volume di email scambiate, o della pagine web servite). Un programma di tal genere, e che invia per email i risultati delle sua analisi all'utente root, è logwatch, che viene anch'esso mandato in esecuzione giornalmente ad opera di cron (prima di logrotate), ed opera in accordo a ciò che trova scritto nei propri file di configurazione, presenti nella directory /usr/share/logwatch/.
Anche Linux, come tutti gli altri sistemi operativi, offre una interfaccia grafica per configurare i parametri di rete, ma in molte occasioni può essere più semplice, più rapido, e più sicuro, usare delle applicazioni che dialogano direttamente con il kernel sia per impostarne i parametri, che per interrogarlo a riguardo di quale ne sia il valore corrente. Storicamente, le applicazioni con questo compito erano ifconfig e route, ma a partire dal 1999, si è iniziato a preferire a queste i comandi offerti dalla suite iproute, che offrono una sintassi più consistente, e simile a quella dei router Cisco. Questi comandi sono espressi mediante frasi composte da più parole, ordinate in modo da definire una sintassi in grado appunto di esprimere le azioni di configurazione ed interrogazione necessarie alla gestione della connessione in rete.
Tutte le frasi iproute iniziano con la parola ip, che rappresenta il programma eseguibile che ne implementa la sintassi. Inserendo da terminale il comando ip da solo, sono mostrati i suggerimenti su come proseguire nella costruzione della frase, ossia
| Usage: ip [ OPTIONS ] OBJECT { COMMAND | help } ip [ -force ] [-batch filename where OBJECT := { link | addr | addrlabel | route | rule | neigh | ntable | tunnel | maddr | mroute | monitor | xfrm } OPTIONS := { -V[ersion] | -s[tatistics] | -d[etails] | -r[esolve] | -f[amily] { inet | inet6 | ipx | dnet | link } | -o[neline] | -t[imestamp] } |
Senza approfondire qui la semantica di tutte le opzioni possibili, notiamo come la seconda parola (OBJECT) definisca su che cosa intendiamo operare, e può essere (oltre ad altre cose)
mentre la terza parola (COMMAND) è un verbo che esprime l'azione che desideriamo compiere su OBJECT; per conoscere le azioni possibili, possiamo immettere una frase incompleta, in cui al posto del verbo si usa la parola help, come ad esempio ip addr help.
Come esempio di applicazione molto semplice, supponiamo di voler verificare il corretto funzionamento della nostra interaccia di rete, assegnando quindi alla stessa un indirizzo IP nell'ambito di una determinata sottorete, e di definire il Default Gateway tramite il quale accedere al resto di Internet. In tal caso, possiamo innanzitutto immettere il comando ip link che ci mostra per ogni interfaccia presente, il corrispondente indirizzo Ethernet, e la presenza o meno di una rete connessa a quella interfaccia. Ad esempio, sul mio portatile ottengo
| alef@alef:~$ ip link 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 2: eth0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc pfifo_fast state DOWN qlen 1000 link/ether 00:13:d3:f0:9c:04 brd ff:ff:ff:ff:ff:ff 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:16:6f:54:3b:a5 brd ff:ff:ff:ff:ff:ff 4: pan0: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN link/ether 02:48:e4:71:52:e4 brd ff:ff:ff:ff:ff:ff |
in cui lo è l'interfaccia di loopback, eth0 quella di rete cablata, eth1 l'interfaccia wireless e pan0 l'interfaccia della Personal Area Network bluetooth. Per ognuna di queste, nella seconda linea è riportato il valore dell'indirizzo ethernet ad essa relativo, mentre nella prima linea viene indicato tra le altre cose un indice di interfaccia, il suo nome, l'MTU mtu, la disciplina di coda qdisc (pfifo_fast), la lunghezza di coda qlen, ed un insieme di flag racchiusi tra parentesi acute, che possono (anche) valere
Per associare un indirizzo IP (as es. 192.168.0.123) ad una interfaccia (es. eth1) usiamo ora il comando
| ip addr add 192.168.0.123/24 dev eth1 |
mediante il quale definiamo anche una network mask (ad esempio) di 24 bits; per verificare il buon esito dell'operazione, impartiamo il comando ip addr senza ulteriori specificazioni, ottenendo (a parte le informazioni sulle altre interfacce)
| alef@alef:~$ ip addr 3: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:16:6f:54:3b:a5 brd ff:ff:ff:ff:ff:ff inet 192.168.0.123/24 brd 192.168.0.255 scope global eth1 inet6 fe80::216:6fff:fe54:3ba5/64 scope link valid_lft forever preferred_lft forever |
che oltre a confermarci l'indirizzo IP e quello MAC, ci mostra tra le altre cose anche l'indirizzo di broadast, l'indirizzo IPv6, e la disciplina di coda applicata. Per rimuovere l'assegnazione di tale indirizzo all'interfaccia, il comando è
| ip addr del 192.168.0.123/24 dev eth1 |
Non resta ora che definire qual'è il nostro default gateway, mediante il comando
| ip route add default via 192.168.0.1 dev eth1 |
che istruisce il kernel ad inviare all'host con indirizzo 192.168.0.1 i pacchetti IP destinati fuori della nostra LAN, tramite l'interfaccia eth1 precedentemente configurata. Per verificare il contenuto della tabella di routing, si può immettere il comando ip route senza ulteriori parametri, ottenendo qualcosa del tipo
| alef@alef:~$ ip route 192.168.0.0/24 dev eth1 proto kernel scope link src 192.168.0.123 metric 2 default via 192.168.0.1 dev eth1 proto static |
che ci conferma come i computer della LAN siano raggiungibili direttamente, mentre per gli altri si passi per il DG impostato. Infine, per rimuovere l'impostazione relativa al Defaul Gateway, il comando è
| ip route del default |
Utilizzando il comando ip addr add, assegnare alla interfaccia eth0 i due indirizzi 10.x.y.1/8 e 10.w.z.2/8, con x, y, w, z scelti a caso tra 1 e 254. Osservare il risultato del comando ip route prima delle assegnazioni, dopo la prima, e dopo la seconda. Pingare prima un indirizzo, e poi l'altro, ed osservare l'output. Ripetere il ping dopo aver rimosso un indirizzo. Qualcun altro ha inserito il nostro stesso indirizzo? In caso contrario, convinciamo il nostro vicino a farlo, ed osserviamone l'effetto.
Poniamo che qualcuno abbia configurato il nostro computer come default gateway, e quindi il suo traffico uscente sia incapsulato in trame ethernet indirizzate a noi. Il kernel, osservando un indirizzo IP di destinazione che non ci appartiene, scarterà il pacchetto inviando un messaggio icmp destination unreachable. A meno che... non si abiliti il kernel ad inoltrare il pacchetto, ad esempio sfruttando l'interfaccia offerta dal filesystem /proc, con il comando
| echo "1" > /proc/sys/net/ipv4/ip_forward |
dopodiché i pacchetti per altre destinazioni inizieranno a ri-uscire dal nostro computer, in base alle informazioni di routing note (ad esempio, inviandoli al proprio DG). Per consentire l'apprendimento di instradamenti differenti, a seguito di informazioni scambiate con altri router, si possono quindi eseguire i demoni di routing sviluppati ad es. nel progetto Quagga.
Il kernel di Linux è in grado di intercettare e manipolare i pacchetti in transito grazie ai servizi offerti dal componente Netfilter, con cui si può comunicare per mezzo dell'interfaccia utente offerta dal comando iptables, oppure utilizzando interfacce grafiche come ad es. Firestarter. In tal modo si possono definire filtri che analizzando il valore dei campi dei pacchetti (sia a livello di rete che di trasporto), ne permettono o meno il transito (ad es. bloccando quelli diretti verso porte non consentite), rifiutano di inoltrare alcuni protocolli (ad es. icmp), o realizzando funzioni NAT ri-scrivendo le intestazioni dei pacchetti in transito mascherando così le reali sorgenti/destinazioni di traffico. La sintassi che esprime le regole di filtraggio è declinata mediante le opzioni ed i parametri del comando iptables, per cui ad esempio immettendo (da root)
| iptables -t filter -I INPUT -p tcp --dport 80 -j REJECT |
si ottiene il risultato di produrre un icmp
port unreachable
in risposta ai pacchetti in ingresso, e diretti verso la porta 80: per
sperimentarne il funzionamento, seguire le indicazioni del prossimo
capitolo. L'opzione -t
permette di specificare una tra 3 tabelle:
mentre l'opzione -I referenzia il tipo di traffico a cui applicare la regola, a scelta (per la tabella filter) tra
Le regole definite per una stessa tabella e tipo sono valutate (per ogni pacchetto) una dopo l'altra, e per questo le regole per uno stesso tipo di traffico sono collettivamente indicate come chains (catene). Quando si verifica una corrispondenza, si esegue l'azione (target) indicata mediante l'opzione -j (jump), come ad esempio
Alcuni di questi target interrompono la verifica delle successive regole della stessa catena, permettendo di definire il comportamento di un firewall impostando la sequenza delle regole in due modi possibili:
Il comando per elencare le regole impostate è iptables -L (list), mentre quello per rimuoverle tutte è iptables -F (flush).
Un ulteriore intervento sul transito dei pacchettti nel kernel è costituito dalla possibilità di imporre una sagomatura del traffico attuata per mezzo dell'adozione di particolari discipline di coda, utilizzando l'interfaccia offerta dal comando tc (traffic control). Ciò permette ad es. di limitare la velocità di trasmissione dei dati, sia in modo complessivo, che particolareggiato ad alcune classi di traffico, rispetto alle quali i pacchetti in transito possono essere classificati per mezzo di apposite regole di iptables, in modo da evitare ad es. che traffico più aggressivo ma meno sensibile al ritardo, possa competere in modo indesiderabile con traffico ad es. VoIP.
Rimandando ad una prossima edizione un approfondimento dell'argomento, descriviamo brevissimamente il caso senza classi, che impone una disciplina di coda token bucket a tutto ciò che attraversa una interfaccia, mediante il comando (eseguito come root)
| tc qdisc add dev eth0 root tbf rate 220kbit latency 50ms burst 1540 |
Possiamo sperimentare l'effetto eseguendo iperf su di un computer come server, misurare il throughput a partire da un diverso computer, quindi imporre una limitazione di velocità mediante il comando su indicato, e infine verificarne l'operatività ripetendo il test con iperf. Inoltre, confrontando il risultato della cattura del traffico per i due casi, potranno essere apprezzati i meccanismi di controllo di flusso e congestione attuati dal TCP.
Per rimuovere la disciplina di coda il comando è
| tc qdisc del dev eth0 root tbf rate 220kbit latency 50ms burst 1540 |
mentre per interrogare le discipline in atto si impartisce sudo tc -d qdisc.

Dal TCP al VoIP, dal DNS all'Email alla crittografia, tutto ciò che accade
dietro le quinte di Internet, completo di cattura del traffico.
Scopri
come effettuare il download,
ricevere gli aggiornamenti,
e contribuire!
