Nel seguito sono esposti i meccanismi alla base della comunicazione a
pacchetto e del loro instradamento su rete Internet, e di come la
stratificazione funzionale dei protocolli si sostanzi in una architettura
software realizzata interfacciando strati via via più prossimi al mezzo di
comunicazione. Nel prossimo
capitolo sarà descritto come un programma (applicazione)
in esecuzione su di un computer ospite (host)
possa comunicare con un altro, posto ad una diversa estremità della rete
Internet.
una netta separazione di ruoli tra gli operatori di telecomunicazioni,
ed i fornitori di servizi;
una maggiore concorrenza tra fornitori di connettività da un lato, e
fornitori di servizi dall'altro;
possibilità di sviluppo di servizi innovativi, replicabili e
indipendenti.
Lo studio delle applicazioni Internet, pertanto, potrebbe essere svolto
in modo quasi del tutto indipendente dalla comprensione del funzionamento
della rete Internet; d'altra parte, una percezione di ciò che avviene dietro le quinte (e come vedremo, anche all'interno
del nostro computer di casa) è senz'altro di grande aiuto nelle fasi
progettuali e di utilizzo.
Lo origini di
Internet sono legate all'esigenza del Dipartimento della Difesa
(DoD) degli USA di far comunicare tra loro computer di diversa
fabbricazione. Alla base del funzionamento di Internet, troviamo le
caratteristiche di
poter continuare a funzionare anche in presenza di malfunzionamenti ed
anomalie;
assenza di un controllo centralizzato;
trasmissione numerica di unità informative autonome denominate pacchetti dati;
adozione di specifiche pubbliche e replicabili da parte di
sviluppatori indipendenti
In questo capitolo ci occupiamo appunto di descrivere i meccanismi di
funzionamento interno della rete Internet. Ma prima di tutto,
vanno definiti alcuni concetti di base.
Agli albori della telefonia, ossia nell'epoca dei telefoni a manovella,
con la cornetta appesa al muro, la comunicazione si basava sulla creazione
di un vero proprio circuito elettrico, grazie
all'operato di un centralinista umano, che collegava fisicamente tra loro
le terminazioni dei diversi utenti. Nel caso in cui intervengano più
centralinisti in cascata, la chiamata risulta instradata
attraverso più centralini. Da allora, il termine commutazione
di circuito individua il caso in cui
è necessaria una fasedi
setup precedente alla comunicazione vera e propria, in cui
vengono riservate le risorse;
nella fase di setup si determina anche l'instradamento
della chiamata nell'ambito della rete, che rimane lo
stesso per tutta la sua durata;
le risorse trasmissive restano impegnate in modo
esclusivo per l'intera durata della conversazione.
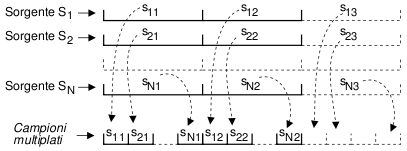
Le
cose non sono cambiate di molto (da un punto di vista concettuale) con
l'avvento della telefonia numerica: in tal caso, più segnali vocali sono campionati
e quantizzati
in modo sincrono, ed il risultato (numerico) è multiplato
in una trama PCM, in cui viene riservato
un intervallo temporale per ognuno dei flussi tributari.
Il
processo di multiplazione è tale per cui il flusso binario risultante da N tributari uguali, deve essere trasmesso ad una
velocità binaria pari ad Nvolte
quella del singolo tributario. Ad esempio nel caso del PCM, in cui si
estraggono per ogni sorgente 8000 campioni a secondo, e ognuno di questi è
quantizzato con 8 bit, si ottiene (per ogni tributario) un contributo di
La
trama PCM si ottiene multiplando assieme 32 tributari, e quindi la
velocità complessiva risulta essere di 64.000 * 32 = 2.048.000
bit/secondo, comunemente indicato come flusso a 2
Megabit, ovvero, in accordo alla nomenclatura ITU-T,
come circuito E1.
In realtà, due dei 32 intervalli temporali possono essere riservati ad informazioni di segnalazione, ma questo... potrà
essere oggetto di altri corsi.
Per ciò che ci riguarda, possiamo concludere questa brevissima
digressione, specificando che nell'attraversamento di nodi di
commutazione, più flussi PCM possono essere ulteriormente raggruppati,
producendo quella che viene indicata come gerarchia
digitale plesiocrona (PDH),
attualmente
sostituita dalla gerarchia digitale sincrona (SDH).
La trasmissione dei pacchetti avviene multiplandoli (ovvero, condividendo
lo stesso mezzo trasmissivo tra le diverse comunicazioni) in modo statistico, ovvero senza riservare con
esattezza risorse a questo o quel tributario. Infatti, in questo caso il
multiplatore si limita ad inserire i pacchetti ricevuti in apposite code,
da cui li preleva per poterli trasmettere in sequenza. La presenza di code
comporta
il determinarsi di un ritardo variabile ed impredicibile con esattezza
la possibilità che la coda sia piena, ed il pacchetto in ingresso
venga scartato
a meno di non adottare tecniche di prioritizzazione atte a
garantire la Qualità
del
Servizio (QoS).
Per contro, se ogni pacchetto reca con sé le informazioni necessarie al
suo recapito, la rete di trasmissione non necessita di una apposita fase
di setup dell'instradamento: nel caso della commutazione
di
pacchetto, ogni unità informativa fa caso a sè.
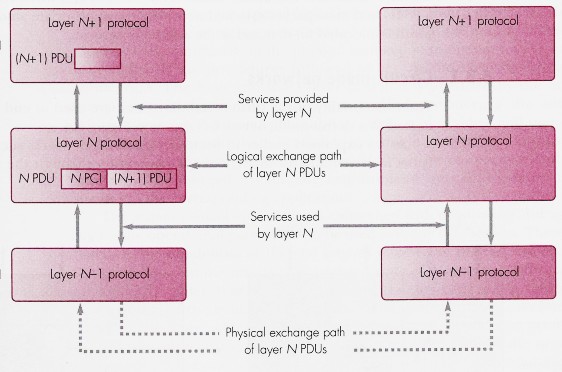
Nella figura (tratta da MMC) viene evidenziato come si possa stabilire una
relazione gerarchica tra le diverse funzioni, individuando un pila (stack) di strati (layer).
Le
entità di pari livello N sono da ritenersi
virtualmente in colloquio tra loro (tra pari, o peer),
mediante lo scambio logico di Protocol Data Unit
(PDU), mentre in effetti queste si avvalgono dei servizi offerti dallo
strato inferiore N-1, che a sua volta, offre
dei servizi allo strato superiore N+1.
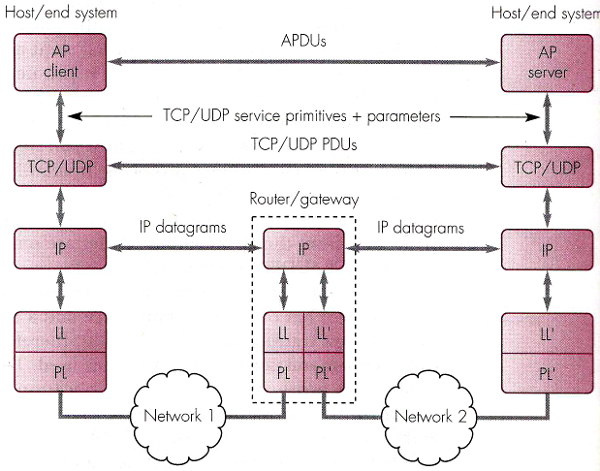
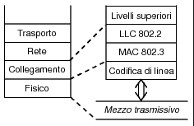
Il modello ISO/OSI individua sette
livelli
funzionali, di cui i più rilevanti per ciò che riguarda le
applicazioni Internet, sono quelli cosiddetti di
trasporto e di rete, indicati
rispettivamente come TCP (o UDP) e IP, mentre i tre livelli ISO-OSI
superiori vengono raggruppati in un unico strato applicativo,
per cui di fatto Internet è basata su di un modello a cinque livelli.
Il processo si ripete, invocando i servizi offerti dallo strato di rete
(IP), che ha il compito di recapitare i singoli pacchetti tramite i nodi di commutazione, o router,
di Internet. Viene quindi aggiunto un nuovo header (IP), che contiene un protocol field in grado di specificare quale entità
dello strato di trasporto (TCP, UDP) o servizio di rete (ICMP, IGMP)
viene incapsulata. Infine, viene aggiunto un header ulteriore (di link),
in cui un type field identifica il protocollo
di rete (nel nostro caso, IP) trasportato. La trama (frame)
così composta può essere effettivamente trasmessa sul mezzo che
interconnette i nodi della LAN, e recapitata a quello con l'indirizzo
di collegamento specificato nel Frame Header.
Non tutte le PDU dei diversi livelli sono indicate cone lo stesso nome di
pacchetti: nello stack Internet questo termine
è riservato alle PDU prodotte dallo strato di rete (a volte indicate anche
datagrammi), mentre quelle di
livello applicativo sono demoninate segmenti,
e quelle di livello di collegamento trame. In
questo modo si evita di fare confusione usando lo stesso termine per
oggetti differenti.
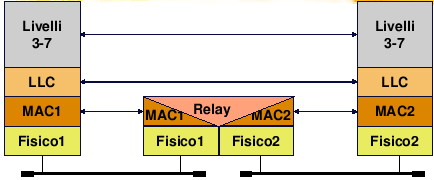
Nella figura sottostante, ovvero in quest'altra,
viene posto in evidenza come i router (ossia i dispositivi che interconnettono le diverse reti
di cui è composta Internet) si limitino a dialogare solo fino allo strato
di rete (IP) delle entità a cui sono collegate, senza cioè leggere nulla
più interno della intestazione IP.
ogni protocolloproto
(es HTTP, FTP) è associato di default ad un indirizzo di
trasporto (ad es porte TCP 80, 21), in accordo alle
corrispondenze registrate presso IANA,
indicate anche come porte
ben note. Viceversa, il numero di porta può anche essere
indicato in modo esplicito, con una sintassi del tipo fqdn:port
il Fully Qualified Domain Namefqdn si traduce, mediante interrogazione
al DNS, nell'indirizzo IP
necessario allo strato di rete per consegnare i pacchetti alla
LAN dove risiede l'host di destinazione
risorsa, e user,
costituiscono un sotto-indirizzamento la cui semantica è
definita nel contesto dell'applicazione che gestisce proto.
Ad es, se proto è mailto,
allora user è il destinatario; se
invece proto è http,
risorsa è una pagina web.
i 4 bytes x.y.w.z dell'indirizzo
IP sono utilizzati, all'interno della rete locale, dal
protocollo ARP per conoscere
l'indirizzo Ethernet dell'host di destinazione
lo strato di collegamento spesso è una LAN Ethernet, e
gli indirizzi sono detti
i 6 byte dell'indirizzo Ethernet vengono usati dallo strato di
collegamento per individuare un computer fisicamente connesso
alla stessa Local Area network (rete LAN)
Solo 2 dei tre bit di Flag sono usati, DF (Don't
Fragment) per richiedere alla rete di non frammentare il datagramma,
e MF (More Fragments) per indicare che seguiranno
altri frammenti. Il TTL (Time To Live) determina la massima
permanenza del pacchetto nella rete, in quanto ogni router attraversato ne
decrementa di uno il valore, finché questo non si azzera, ed il pacchetto
è scartato. Protocollo indica il tipo di pacchetto incapsulato,
ovvero a quale tipo di trasporto consegnare il datagramma all'arrivo (ad
es. TCP o UDP), in accordo ai codici
registrati presso IANA, ed infine Checksum serve per verificare
l'assenza di errori nell'header.
Gli Indirizzi IP di sorgente e destinazione individuano i computer
all'interno di Internet, e servono allo strato di rete per recapitare il
messaggio e la risposta associata, mentre il campo Opzioni
ha una lunghezza variabile, può essere omesso, e consente ad esempio di
richiedere il tracciamento della serie di router attraversati.
quelle massime, pongono un limite alla probabilità che qualche bit del
pacchetto inviato sia affetto da errori di trasmissione. Con i 16 bit
del campo TLEN, si ha un massimo di 65,535 byte, mai raggiunto nella
pratica. Dato che lo strato fisico delle reti attraversate impone spesso
una dimensione massima di pacchetto (Maximum
Transmission Unit o MTU) molto inferiore, lo strato di
trasporto tenta di consegnare allo strato IP segmenti di dimensione
sufficientemente ridotta, tale da non dover subire frammentazione.
Spesso la dimensione dei pacchetti IP viene posta pari a 1480 byte, ossia
la dimensione del payload Ethernet
di 1500 byte, meno i 20 di intestazione IP. La massima dimensione permessa
senza dover subire frammentazione da parte di qualche collegamento di
transito può essere scoperta adattando tecniche indicate come path
MTU discovery. Alcune interfacce di rete e dorsali di collegamento
permettono pacchetti di 9000 bytes detti jumbo
frame, che possiamo trovare ad es. in questocapture
ottenuto durante un test di velocità svolto con Iperf.
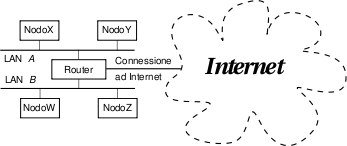
Quando l'indirizzo IP di destinazione è esterno
alla LAN di partenza, come nel caso (#3),
allora il datagramma è inviato a destinazione in modo indiretto,
per il tramite di un particolare router
presente nella LAN, il Default Gateway (R1
nella figura), che interconnette la LAN al resto di Internet. Di li in
poi, il pacchetto IP viene rilanciato di router in router, esaminando ogni
volta l'indirizzo di destinazione, ed inoltrando il pacchetto sulla
interfaccia nella direzione
corretta, via via fino a quello che ha accesso alla LAN di
destinazione.
La direzione giusta viene stabilita in base all'esame di
apposite tabelle di routing,
che possono modificarsi nel tempo, così come i collegamenti, possono
andare a volte fuori servizio. Per questi motivi, nulla vieta ai pacchetti
di una stessa comunicazione di seguire instradamenti alternativi, ed anzi
è proprio questo ciò che accade:
Pertanto,
i pacchetti IP possono giungere a destinazione in un
ordine diverso da quello di partenza.
Gli strati superiori (Trasporto ed Applicativo)
in esecuzione presso gli host di destinazione, svolgeranno quindi il
compito di ristabilire l'ordine corretto.
L'indirizzo di sottorete così ottenuto identifica un sottoinsieme di
indirizzi IP contigui, che nell'esempio sono tutti gli indirizzi tali che,
ponendo a zero gli ultimi 32-22=10 bit, equivalgono all'indirizzo
192.168.120.0. Questo insieme può essere partizionato in ulteriori
sotto-reti, adottando una maschera più lunga. Ad esempio, i computer con
indirizzo IP 192.168.120.X, appartengono alla
sottorete 192.168.120.0/24, contenuta dentro a quella con maschera /22.
In particolare, la sottorete con maschera di ventidue bit (/22),
contiene al suo interno le quattro LAN con maschera a 24 bit, ed indirizzo
di sottorete 192.168.120.0/24, 192.168.121.0/24,
192.168.122.0/24, 192.168.123.0/24.
Domanda: Si, ma come fa il
mittente a capire che il destinatario è nella sua stessa sottorete ?
Risposta: Mette in AND
l'indirizzo IP di destinazione con la Network Mask, e confronta il
risultato con l'AND del proprio indirizzo, per la stessa maschera. Se i
risultati coincidono, gli indirizzi appartengono alla stessa LAN
Esempio: 192.168.121.32
e 192.168.122.45, messi in AND ad una
maschera di lunghezza 22 bit, forniscono lo
stesso risultato, ovvero 192.168.120.0.
Morale, tutti i computer della stessa LAN, devono utilizzare la stessa
Network Mask!! Altrimenti, pur potendo comunicare tra loro in modo
diretto, necessiterebbero della presenza di un router.
Ad esempio, nel caso (#2), l'host mittente
LH4 si avvede che il destinatario LS1 ha un IP che appartiene ad una diversa
sottorete, e spedisce il pacchetto usando l'indirizzo MAC del
proprio Default Gateway R2. Questo, anzichè reindirizzare il pacchetto
verso R1 e di lì verso Internet, lo inoltra correttamente sull'interfaccia
che collega LS1.
Qui sotto, è mostrato un esempio di come potrebbero apparire le tabelle di
instradamento IP, per i router che interconnettono quattro diverse LAN.
Per i diversi indirizzi di sottorete, è indicato il router da utilizzare
per raggiungerla.
Le tabelle di instradamento dei router sono popolate a seguito di
continue comunicazioni con gli altri router di Internet. Nel caso di
esempio della figura soprastante, R1 annuncia ad R2, R3 e R4 la
raggiungibilità della rete 11.0.0.0/8, provocando in questi l'inserimento
dell'informazione che per raggiunere quella rete, occorre consegnare il
pacchetto a R1. Quando R4 annuncia la sua raggiungibilità per la rete
14.0.0.0/8, questo annuncio viene ri-propagato da R1, in modo che la rete
14 risulti raggiungibuile per il suo tramite. Quindi, in termini
semplificati, ogni router annuncia a quelli a lui collegati, quali
sottoreti può raggiungere, che così diventano raggiungibili anche da
questi secondi router, che a loro volta, propagano l'annuncio, assumendosi
l'incarico dell'inoltro.
Il compito dei protocolli
di
routing è quello di coordinare questo processo, rendendolo
efficiente, convergente, e pronto a recepire i cambiamenti di
configurazione.
Nel caso in cui un router si accorga di conoscere gli istradamenti per
tutte le sottoreti contenute sotto una stessa network
mask più corta, può legittimamente aggregare
gli instradamenti, ed annunciare la raggiungibilità dell'unica sottorete
più grande. Ad esempio, un router che avesse accesso alle reti 192.168.120.0/24,
192.168.121.0/24, 192.168.122.0/24,
192.168.123.0/24, annuncerà la raggiungibilità
per la sola rete 192.168.120.0/22, che le
racchiude tutte e quattro. In tal modo, si ottiene il risultato di semplificare
le tabelle di instradameno per i router più
interni di Internet.
Un
Sistema
Autonomo (AS) è un insieme di LAN, interconnesse da router, che
intendono apparire al resto di Internet come una unica entità, come ad
esempio è il caso di un ISP,
o di una azienda. Per questo, un sistema autonomo si interconnette con gli
altri solo mediante alcuni dei suoi router,
che annunciano all'esterno la raggiungibilità delle LAN interne. I
protocolli di routing eseguiti all'interno ed all'esterno sono diversi, e
prendono rispettivamente il nome di Interior
ed Exterior routing protocols; in pratica, il
protocollo di comunicazione ufficiale tra router di diversi AS, è il Border
Gateway Protocol (BGP).
Acronimo di Routing
Information
Protocol e normato dalla RFC
2453, è usato prevalentemente come protocollo interno,
ed anche se gravato di una lenta convergenza, viene ancora usato nelle
reti di piccole dimensioni, ed è largamente diffuso. Realizza un versione
distribuita dell'algoritmo di Bellman-Ford
per trovare i percorsi di minimo costo
all'interno di un grafo valutato, mediante la trasmissione periodica da
parte di ciascun router, verso i suoi vicini, di una lista di vettori
di
distanza relativi a tutte le destinazioni di cui conosce la
raggiungibilità. Il vettore di distanza è composto dalla terna (destinazione,
costo, tramite) in cui destinazione è
un prefisso di sottorete, tramite è
l'indirizzo IP del computer che annuncia il vettore di distanza, e costo rappresenta il numero di router da
attraversare (detti anche hop, o
salti) per raggiungere destinazione a partire
da tramite. Ad esempio, una sottorete connessa
direttamente viene annunciata come raggiungibile con costo nullo, ed un
router appena acceso conosce (e dirama) solo queste informazioni; man mano
che la sua tabella di routing si popola di nuove informazioni di
raggiungibilità, anche queste vengono ritrasmesse ai suoi vicini.
Quando un router riceve una tabella di vettori di distanza, aggiorna la
propria tabella di routing in accordo allo schema
per ogni destinazione presente nella tabella ricevuta
incrementa di uno il valore del costo dell'instradamento
se la propria tabella di routing non conosce come raggiungere la
destinazione
aggiungi una linea nella tabella di routing con il costo ed il
tramite
altrimenti (la destinazione è già raggiungibile)
se la tabella di routing usa lo stesso tramite per quella
destinazione
sostituisci il costo dell'instradamento con il nuovo valore
ricevuto
altrimenti (la dest è raggiungibile ma il tramite è diverso)
se il costo è inferiore a quello noto
sostituisci sia il costo che il tramite per quella
destinazione
il cui esito è esemplificato dalla figura seguente:
Si può dimostrare che in tal modo, dopo un certo numero di iterazioni, il
risultato è equivalente a quello ottenibile applicando l'algoritmo di Bellman-Ford
ad un grafo con costi non negativi, algoritmo che possiamo descrivere
come
BELLMAN-FORD(G, w, s) ; Given a graph G, a
weight function w, and a source node s
; G provides a set of vertex V[G] and
a set of edges (u,v) in E[G]
for each vertex v in V[G] ; for every node v in G
d[v] := inf ; set distance to v to a large number
p[v] := nil ; set parent of v to nil
d[s] := 0 ; set the source's distance to itself
to 0
for each vertex v in V[G] ; for every node v in G
for each edge (u,v) in the set E[G] ; for all the edges toward v
if d[v] > d[u] + w(u, v) ; if the distance to a node can be
updated
d[v] := d[u] + w(u, v) ; update the v's distance
p[v] := u ; update the v's parent
In cui p[v] è usato iterativamente per
ricostruire il percorso di minimo costo da s
a v, e d[v]
memorizza tale costo minimo.
Una soluzione piuttosto semplice al problema esposto è detta split
orizon, che prescrive per ciascun router di omettere di comunicare
ad ogni specifico vicino gli instradamenti appresi proprio da quel vicino,
evitando così di trarre in inganno chi è meglio informato. Per accellerare
la convergenza, a spese di un maggior traffico di rete, la variante poison
reverse prescrive di annunciare l'instradamento anche al router da
cui lo si è appreso, ma con costo 16.
Notiamo ora che il metodo descritto è in grado di impedire il conto fino
ad infinito per coppie di router, mentre non rompe il loop che potrebbe
crearsi tra tre o più router, almeno finché appunto il costo
dell'instradamento non raggiunga il valore di 16 per tutti. Allo scopo di
accellerare il processo, la tecnica dei triggered
update prevede di inviare delle notifiche non appena le informazione
di raggiungibilità cambiano.
Infine, il protocollo RIP prevede l'uso di timers sia per definire
l'intervallo dei messaggi emessi (30 sec), sia per rimuovere gli
istradamenti per i quali non si sono più ricevuti aggiornamenti per più di
3 minuti.
Ad un certo
punto dello sviluppo di Internet, sembrava quasi che gli indirizzi
IP stessero per esaurirsi di lì a poco. Vennero prese una serie di
contromisure, e si iniziò a fare un uso molto diffuso delle classi di indirizzi
privati. Si tratta di sottoreti che i router di Internet rifiutano
di inoltrare, e che quindi ognuno può usare nel suo privato, per creare
una LAN irraggiungibile da Internet.
Le classi di indirizzi privati sono descritte dagli indirizzi di sottorete
10.0.0.0/8, 172.16.0.0/12, e 192.168.0.0/16. Tutti gli altri indirizzi
(con le dovute eccezioni), sono per contro detti pubblici.
D'altra
parte, anche se i computer dotati di un IP privato possono comunque
inviare pacchetti diretti verso indirizzi di destinazione pubblici, ed in
questo senso uscire su Internet, per poter
ricevere pacchetti di risposta, occorre che adottino un indirizzo IP
mittente anch'esso pubblico: questo è appunto il ruolo svolto dal NAT
(Network Address Translator), che altro non è
che un router Rpotenziato, che si affaccia
sia sulla Internet pubblica (dove è raggiungibile con un IP pubblico), sia
sulla LAN privata, per la quale svolge il ruolo di Default Gateway. La sua
particolarità è che, oltre ad instradare i pacchetti, ne modifica gli
indirizzi.
Ad esempio nel caso del Source
NAT, l'IP privato di un computer sorgente A viene
sostituito con quello (pubblico) del NAT, ed al posto dell'indirizzo di trasporto originario, ossia della porta presso
la quale A desidera ricevere risposta, se ne inserisce
un altro scelto sempre dal NAT. A questo punto, il destinatario con IP
pubblico Bcrede di stare
parlando con il router R, anzichè con il computer A
dotato di IP privato. Quando torna un pacchetto di risposta, il NAT si
avvede che la porta di trasporto di destinazione è una di quelle scelte da
lui, e ne usa il valore (che ha memorizzato) per ritrovare l'indirizzo IP
e la porta originariamente usate dal computer A
con IP privato, sostituisce questi valori a quelli presenti nel pacchetto
di risposta, e finalmente lo consegna al mittente originario.
Il principale svantaggio di un NAT, è che i computer con IP privato
possono assumere solamente il ruolo di Client, ma non di Server, dato che
non possono ospitare servizi raggiungibili dall'esterno, ovvero per i
quali i pacchetti devono entrare prima di
uscire. A meno di non configurare il NAT in modo da redirigere
i pacchetti entranti ed indirizzati all'IP pubblico del NAT, verso un
computer ben preciso della rete privata, come nel caso di una DMZ
casalinga. Altrimenti, è possibile inviare il traffico entrante verso IP
privati differenti, scelti in base all'indirizzo di trasporto verso cui
sono indirizzati, realizzando così un Port
Forwarding.
In un capitolo successivo, è riportata una classificazione più
approfondita sui diversi tipi di NAT.
Tutti gli indirizzi che ricadono in questo prefisso
sono chiamati localhost,
corrispondono al computer stesso, e sono associati all'interfaccia lo. Se usato come indirizzo di destinazione,
il pacchetto non abbandona il computer, ed il kernel lo pone in
ingresso alla interfaccia lo. Un
programma che si pone in ascolto su uno di questi indirizzi, riceve
i pacchetti inviati da un diverso programma in esecuzione sullo
stesso computer.
0.0.0.0/0
Come il precedente, identifica il
proprio computer, ma viene usato da una applicazione
eseguita su di un computer connesso a più LAN, e che non
voglia fare distinzioni su come i pacchetti siano arrivati.
Infatti, una maschera di sottorete di lunghezza nulla determina la
corrispondenza per qualsiasi indirizzo
IP. Per questo, non può essere usato nelle tabelle di routing, se
non per selezionare il default gateway.
prefisso di sottorete usato come indirizzo
singolo
Se ad esempio la LAN di cui il computer fa parte è
rappresentata come 192.168.120.0/22, allora il singolo indirizzo
192.168.120.0 ottenuto concatenando al prefisso (nell'esempio di
22 bit) tutti zeri (nell'esempio 10 zeri) rappresenta ciascun
computer
della LAN, nel senso che per ognuno di essi indica sé stesso nella sottorete indicata;
pertanto, non può essere usato come indirizzo di destinazione;
Se invece l'estensione del prefisso è realizzata usando tutti
uni, ovvero ad es. fornendo la stringa binaria 11000000.10101000.01111011.11111111,
corrispondente
a 192.168.123.255, l'indirizzo ottenuto può essere usato come destinazione per raggiungere collettivamente
tutti i computer della stessa LAN, realizzando il cosiddetto indirizzamento broadcast
255.255.255.255
Anche in questo caso si tratta di un indirizzo
broadcast, che a differenza del precedente non tiene conto
della LAN in cui ci si trova, ma per il quale tutti i computer vi si
riconoscono comunque. D'altra parte, i pacchetti con questo IP come
destinazione non sono inoltrati dai router, e dunque restano
confinati alla LAN da cui hanno origine.
Come esempi applicativi, il caso più noto è quello associato
all'uso del comando ping
(vedi anche le esercitazioni),
impiegato
per verificare la connettività con un altro computer, inviando un
pacchetto ICMP di tipo Echo
request. Il computer di destinazione, se operativo ed
effettivamente raggiunto, risponde con un pacchetto ICMP
di tipo Echo reply, al che il comando ping in esecuzione sul primo computer, scrive a
video il tempo intercorso tra andata e ritorno, o Round
Trip Time (RTT). Il ciclo si ripete all'infinito, e viene
interrotto premendo control-c, al che il ping
stampa delle statistiche sui tempi rilevati, e termina.
Nel caso in cui il computer di destinazione (od una applicazione che
dovrebbe essere in ascolto su di una porta di trasporto) non possa essere
raggiunto (dal paccheto ICMP di tipo Echo
request, o da qualunque altro pacchetto IP), i router di
transito, od il computer di destinazione, possono generare un pacchetto ICMP di tipo 3 -
Destinazione irraggiungibile, il cui campo code
contiene un valore
che indica il possibile motivo della irraggiungibiità, come ad esempio
Code
Description
0
Network unreachable error.
1
Host unreachable error.
3
Port unreachable error (the designated protocol is
unable to inform the host of the incoming message).
4
The datagram is too big. Packet fragmentation is
required but the 'don't fragment' (DF) flag is on.
13
Communication administratively prohibited
(administrative filtering prevents packet from being forwarded).
in cui i codici Network e Host
unreachable sono generati dal router che dovrebbe consegnare il
pacchetto, Port unreachable è prodotto
dall'host di destinazione, quando sul numero di porta di destinazione non
è in ascolto nessun processo, mentre i codici Fragmentation
Required e Communication administratively
prohibited, sono generati dai router di transito, nei casi in cui
rispettivamente sarebbe richiesta la frammentazione del pacchetto, ma è
settato il bit "don't fragment", oppure sia
presente un firewall che impedisce il transito
di un pacchetto per quella destinazione.
In
tutti
i casi, il pacchetto ICMP di ritorno viene assemblato a partire da quello
(IP) di andata, come mostrato in figura. In particolare, l'intestazione IP
ricevuta, ed i primi 8 byte di ciò che segue (es TCP), viene prefissa
dalla intestazione ICMP, che è poi ulteriormente prefissa dalla
intestazione IP che serve a recapitare il pacchetto all'indietro. In
questo modo, il mittente originario ha tutti gli estremi per ri-associare
il messaggio ICMP alla connessione uscente che ha prodotto il pacchetto IP
originario.
Il tipo Time Exceeded è
sfruttato dalla utility traceroute (vedi esercitazione),
che invia verso la destinazione un pacchetto con un valore di TTL IP
particolarmente basso. Quando questo si azzera, il router lo scarta, ed
invia all'indietro, appunto, un pacchetto ICMP Time
Exceeded. Quindi, traceroute
incrementa il TTL, allo scopo di scoprire il prossimo router che scarterà
il pacchetto, finché questo non arriva a destinazione. Per una descrizione
approfondita, vedere [NG4].
Infine, il tipo Destinazione
irraggiungibile, codice Fragmentation
Required, viene usato nell'ambito di una procedura chiamata path MTU
discovery, volta a determinare qual'è la dimensione massima di
pacchetto che può essere inviata, senza che questo debba essere
frammentato. In questo caso, prima di iniziare il collegamento, il
computer sorgente invia verso la destinazione dei pacchetti IP grandi
con il bit don't fragment settato, e se il
pacchetto arriva a destinazione, tutto è filato liscio. Viceversa, se il
pacchetto incontra sezioni della rete che devono causare frammentazione,
viene generato appunto il messaggio ICMP Destination
unreachable, fragmentation required, ed il mittente capisce che
deve ridurre la dimensione di pacchetto; ripete quindi la procedura con il
pacchetto ridotto, finchè non va.
Nel campo Type è presente un codice
a 16 bit che indica il protocollo incapsulato (ad es. 0x0800 per
IPv4), mentre nei campi indirizzo sorgente e destinazione, trovano posto gli indirizzi Ethernet
(di 6 bytes ognuno) delle interfacce di rete agli estremi del
collegamento. La parte disegnata in rosa, rappresenta il preambolo
necessario al ricevitore per acquisire i sincronismi di trasmissione,
seguito da un codice Start
Frame Delimiter che segnala l'inizio della intestazione Ethernet.
Infine, il Frame Check Sequence (FCS)
è un ulteriore checksum che permette di verificare l'integrità della
trama.
Quando un computer della LAN osserva transitare sull'interfaccia di rete
un pacchetto che riporta il suo indirizzo
Ethernet nel campo destinazione, lo "tira su", e lo passa agli strati
superiori.
Domanda: Come fa il
mittente a conoscere l'indirizzo Ethernet del destinatario, di cui conosce
l'indirizzo IP?? Risposta: per mezzo dell'Address Resolution Protocol (ARP)
La richiesta ARP (2) è inviata in broadcast,
un pò come se qualcuno si affacciasse in corridoio, e gridasse: chi
ha questo IP ? Ciò si ottiene indirizzando la richiesta ARP verso
un indirizzo Ethernet di destinazione, pari ad una sequenza di uni. Le
interfacce di rete di tutti i computer della LAN, quando osservano
transitare un pacchetto Broadcast, sono
obbligate a riceverlo, e passarlo allo strato superiore, che valuta le
eventuali azioni da intraprendere. Host B quindi, dopo aver verificato che
il proprio IP è proprio quello richiesto, invia la sua risposta ARP (4) in
unicast, ossia usando l'indirizzo Ethernet di
Host A come destinazione, comunicando così il proprio indirizzo MAC, usato
come mittente.
No Time Source Destination Protocol
Info
------------------------------------------------------------------------------------------------
1 0.0000 Intel_54:3b:a5 Broadcast ARP Who has
192.168.120.1? Tell 192.168.120.40
2 0.0011 Asiarock_5d:78:5d Intel_54:3b:a5 ARP 192.168.120.1 is
at 00:13:8f:5d:78:5d
3 0.0012 192.168.120.40 192.168.120.1 DNS Standard query A
www.libero.it
4 0.1048 192.168.120.1 192.168.120.40 DNS response CNAME
vs-fe.iol.it A 195.210.91.83
5 0.1052 192.168.120.40 195.210.91.83 ICMP Echo (ping)
request
6 0.1316 195.210.91.83 192.168.120.40 ICMP Echo (ping)
reply
7 0.1362 192.168.120.40 192.168.120.1 DNS query PTR
83.91.210.195.in-addr.arpa
8 0.3933 192.168.120.1 192.168.120.40 DNS Standard query
response PTR vs-fe.iol.it
9 1.1042 192.168.120.40 195.210.91.83 ICMP Echo (ping)
request
10 1.1300 195.210.91.83 192.168.120.40 ICMP Echo (ping)
reply
11 1.1302 192.168.120.40 192.168.120.1 DNS query PTR
83.91.210.195.in-addr.arpa
12 1.1313 192.168.120.1 192.168.120.40 DNS Standard query
response PTR vs-fe.iol.it
13 5.1036 Asiarock_5d:78:5d Intel_54:3b:a5 ARP Who has
192.168.120.40? Tell 192.168.120.1
14 5.1036 Intel_54:3b:a5 Asiarock_5d:78:5d ARP 192.168.120.40
is at 00:16:6f:54:3b:a5
Innanzitutto, osserviamo (p 1-2) la richiesta-risposta ARP necessaria a
determinare l'indirizzo Ethernet del DNS, in modo da poter inoltrare verso
lo stesso, la richiesta (p 3-4) necessaria a risolvere il nome di dominio
www.libero.it in un indirizzo IP. Poi (p 5-6)
osserviamo la richiesta-risposta ICMP echo
(notiamo come il DNS introduca una latenza di 100 msec, ed il ping solo di
30 msec), fatta passare attraverso il Default Gateway, seguita a sua volta
(p. 7-8) da una richiesta di risoluzione inversa
al DNS, eseguita allo scopo di poter scrivere a schermo il nome di dominio
di chi ha risposto al ping; notiamo che stavolta, la latenza del DNS è di
200 msec. Dopo la seconda richiesta ICMP, osserviamo (p 11-12) una seconda
richiesta di risoluzione inversa indirizzata al DNS, che stavolta viene
servita in modo praticamente immediato, essendo la risposta già presente
nella cache del DNS locale. Per finire, osserviamo (p. 13-14) una
richiesta di risoluzione ARP, diretta stavolta dal Default Gateway verso
il computer su cui stiamo operando, ed originata probabilmente dallo
scadere della cache ARP del router.
Possiamo verificare come i pacchetti ARP siano privi di intestazione IP,
essendo la loro circolazione esclusivamente interna alla rete locale.
Notiamo infine, che l'assenza di un componente di autenticazione delle
informazioni contenute nelle risposte ARP, costituisce una vulnerabilità
per una rete LAN Switchata, che prende il nome di ARP
poisoning.
Il protocollo Ethernet
originario prevedeva la trasmissione a 10 Mbit/sec mediante un cavo
coassiale su cui si affacciavano tutti i
computer; lo stesso mezzo trasmissivo veniva quindi usato "a turno" dai
diversi computer, mediante ad una tecnica di accesso condiviso denominata
Carrier Sense Multiple Access, Collision Detect
(CSMA/CD),
attuata
dallo strato MAC 802.3, su cui non ci soffermiamo.
Per interconnettere tra loro due segmenti di LAN in modo che tutto il
traffico presente su di un segmento sia replicato sull'altro, si utilizza
un dispositivo detto Bridge,
che nel caso in cui i segmenti da interconnettere sono più di due, prende
il nome di Hub.
D'altra parte, nel caso in cui non si desideri inoltrare inutilmente trame
su segmenti presso i quali non è presente la destinazione, si preferisce
eseguire l'interconnessione usando uno Switch.
Attualmente, oltre a prevedere velocità di trasmissione di 100 Mbit/sec, 1
Gbit/sec e 10 Gbit/sec, adottando due coppie ritorte, o la fibra ottica, i
computer di una stessa LAN vengono sempre più spesso interconnessi secondo
una topologia a stella, o ad albero, i cui nodi di transito sono
denominati switch, ed i computer
sono interconnessi su collegamenti full-duplex (es. 100BASE-TX),
che cioè adottano due copie di conduttori, una per trasmettere ed una per
ricevere.
Gli switch sono dotati di più porte, ognuna delle quali gestisce le
comunicazioni con un diverso computer (oppure con un altro switch, od un
router). A differenza di un Hub, lo Switch non ritrasmette su tutte le
porte il traffico osservato su ciascuna di esse, ma opera un instradamento
inoltrando le trame solo in direzione della destinazione indicata
dall'indirizzo MAC. In questo modo, più computer di una stessa LAN possono
trasmettere simultaneamente, senza interferenze reciproche, in quanto i domini di
collisione restano separati per ognuna delle porte.
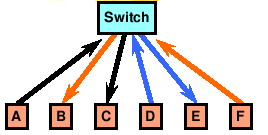
Lo switch non usa un proprio
indirizzo Ethernet, ma instrada
sulle porte in uscita le stesse identiche trame che riceve sulle porte in
ingresso. Quando un computer connesso allo switch trasmette verso una
destinazione per la quale lo switch non ha mai osservato traffico, le
trame sono ritrasmesse su tutte le porte;
d'altra parte, ogni switch attraversato prende nota
dell'indirizzo Ethernet del mittente, e popola una propria tabella
di instradamento, mettendo così in corrispondenza l'indirizzo con
la porta di provenienza.
Da quel momento in poi, ogni volta che lo switch riceverà un pacchetto
destinato ad un computer di cui conosce la porta di connessione,
ritrasmetterà il pacchetto solo su quella porta, evitando di disturbare
gli altri.
Allo scopo di accellerare il processo di apprendimento da parte dello
switch, è possibile che all'accensione i computer inviino dei pacchetti
ARP di annuncio, detti gratuitous ARP, in cui
affermano l'indirizzo MAC di se stessi. In tal modo, comunicano allo
switch il proprio indirizzo Ethernet; nel caso il computer abbia cambiato
la porta di connessione, lo switch provvede anche ad aggiornare la tabella
di instradamento.
Uno strumento per stimolare l'emissione di
richieste ARP, è l'uso del comando ping, che invia un pacchetto ICMP
(Internet Control message Protocol) di tipo Echo Request che, per raggiungere la destinazione,
suscita appunto una richiesta ARP. Nel caso in cui questa non sia
effettuata, è probabile che la risoluzione sia già stata acquista dal
proprio computer, e salvata nella cache: questo può essere investigato,
invocando il comando arp -a.
Come già specificato, lo strato di
trasporto esiste solo nei terminali posti ai
bordi della rete, sorgente e destinazione delle unità informative generate
dai processi applicativi (AP). Il paradigma Internet prevede due modalità
di trasporto, indicate come UDP
e TCP,
che si differenziano essenzialmente in quanto
UDP offre un servizio di trasporto a datagramma,
non garantisce la corretta consegna dei dati, e i pacchetti che
compongono la comunicazione vengono trasmessi uno alla volta in modo
indipendente;
TCP offre un servizio di trasporto a circuito
virtuale (anche se il sottostante strato IP offre un servizio
di rete a datagramma), gestisce le eventuali ritrasmissioni
delle unità non ricevute, ed effettua il riordino dei pacchetti fuori
sequenza. Nel TCP, esiste una fase precedente alla comunicazione vera e
propria, mediante la quale su entrambi gli estremi vengono predisposti
dei buffer, e viene inizializzata una informazione
di stato presso i due terminali, che tiene traccia dei
pacchetti inviati e ricevuti.
Per meglio illustrare la semantica dei termini datagramma
e circuito virtuale, e comprendere come lo
strato di trasporto possa arricchire la
modalità di trasferimento delle informazioni offerta dallo strato di rete,
facciamo di nuovo un passo indietro.
Quando abbiamo definito la multiplazione statistica per un
collegamento dati condiviso tra più comunicazioni, l'esempio mostrava solo
un collegamento tra due nodi. Se invece mittente e destinatario sono
collegati per il tramite di una rete, la trasmissione viene detta a commutazione
di
pacchetto, e sono definite due possibili diverse modalità di instradamento dei pacchetti da uno nodo di rete
all'altro.
contiene l'informazione dell'indirizzo di destinazione,
viaggia in modo indipendente dagli altri che fanno parte della stessa
comunicazione,
ogni nodo deve decidere da che parte reinviarlo,
i pacchetti di una stessa comunicazione possono essere consegnati in
un ordine diverso da quello con cui erano partiti.
In questo caso la trasmissione è detta senza
connessione, a rimarcare il fatto che non esiste una fase
iniziale, in cui si individua un unico instradamento, e si riservano delle
risorse.
Lo User
Datagram
Protocol (UDP) non aggiunge nulla a questa impostazione,
limitandosi in pratica a specificare le porte sorgente e
destinazione: il risultato è che il servizio di trasporto offerto è
detto anch'esso a datagramma, o senza connessione. Di lato è
riportato uno schema della intestazione UDP, di soli 8 bytes.
Un approccio del tutto
diverso, è quello delle reti a commutazione di pacchetto a
circuito virtuale, come la rete X.25,
una architettura ormai praticamente abbandonata, con origini precedenti ad
Internet; lo stesso concetto, è poi stato nuovamente applicato nell'ambito
delle reti ATM
ed MPLS.
In questo caso, l'instradamento viene determinato una volta per tutte
all'inizio della trasmissione, durante una fase di richiesta
di connessione, la cui esistenza determina appunto la
denominazione di servizio con connessione.
Dopodiché, i pacchetti di uno stesso messaggio seguono tutti lo stesso
percorso.
La commutazione di pacchetto a circuito virtuale
si basa su di una intestazione di pacchetto che, anziché presentare
l'indirizzo di rete del nodo di destinazione, contiene invece un identificativo
di
connessione, che individua un canale virtuale (CV)
tra coppie di nodi di rete, determinandone l'appartenenza ad una delle
diverse trasmissioni contemporaneamente in transito tra i due nodi.
L'identificativo del CV presente nel
pacchetto, funge da chiave di accesso alle
tabelle di routing presenti nei nodi, tabelle che sono ora generate nella
fase di richiesta di connessione iniziale, durante la quale vengono
inviati dei pacchetti di controllo che contengono l'indirizzo di rete del
nodo di destinazione, e che causano nei nodi attraversati la
memorizzazioine della porta di uscita, che sarà la stessa per tutti i
successivi pacchetti dati appartenenti ad uno stesso messaggio.
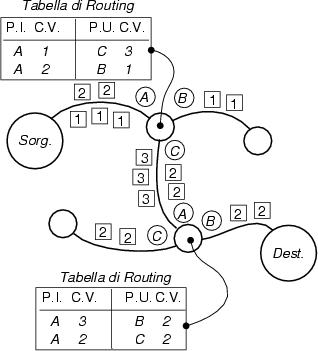
Facciamo
un esempio: una sorgente, a seguito della fase di instradamento, invia i
pacchetti con identificativo CV = 1 al nodo di
commutazione a cui è collegato. Consultando la propria tabella, il nodo
trova che il canale virtuale 1 sulla porta di ingresso (P.I.)
A si connette al CV3 sulla porta
di
uscita (P.U.) C. Ora i pacchetti escono da C
con CV = 3, ed una volta giunti al nodo
seguente sulla P.I. A, escono dalla P.U.
B con CV = 2, e giungono finalmente a
destinazione.
Nel collegamento tra due nodi, numeri di CV
diversi identificano le diverse comunicazioni in transito, ed uno stesso
numero di canale virtuale, può essere riutilizzato su porte differenti
dello stesso nodo anche nel contesto di comunicazioni diverse. La
concatenazione dei canali virtuali attraversati viene infine indicata con
il termine Circuito Virtuale, per similitudine con il caso di
commutazione di circuito: tale similitudine trae origine dal fatto che,
essendo l'instradamento lo stesso per tutti i pacchetti, questi viaggiano
per così dire in fila indiana, e sono
consegnati nello stesso ordine con cui sono partiti, un pò come se si
fosse tracciato un vero e proprio Circuito.
Osserviamo esplicitamente che il TCP non invia riscontri negativi,
ma solo positivi. Infatti, nel caso di
ricezione di un pacchetto corrotto, il comportamento del ricevitore è lo
stesso che per un pacchetto perso, per il quale non viene inviato nessun
riscontro. Al contrario, per ogni pacchetto (che nel contesto del
trasporto TCP è chiamato segmento) ricevuto
correttamente viene inviato un riscontro (ACK)
positivo, in mancanza del quale, una volta scaduto un timeout, il mittente
provvede a ritrasmettere il segmento.
L'intestazione
TCP ha anch'essa dimensioni minime di 20 byte, in cui troviamo, tra
le altre cose
i numeri delle porte sorgente e
destinazione, che individuano il processo applicativo che lo ha
prodotto, ed a cui è destinato il segmento;
i numeri di sequenza, espressi nei termini
di numero di bye trasmessi, che permettono
di
ri-ordinare i pacchetti ricevuti in base al Sequence
number, depositandoli al punto giusto, all'interno del
buffer di ricezione;
riscontrare i pacchetti ricevuti mediante l'Acknowledgement
number, in modo che il mittente possa rimuovere dai buffer
di trasmissione tutto ciò che è stato riscontrato, ovvero accorgersi
se manca qualche riscontro, e quindi ritrasmettere il segmento
corrispondente.
un gruppo di 8 bit detti flag, che se
posti ad 1 caratterizzano il tipo di pacchetto, come di apertura (SYN) o di chiusura (FIN, RST)
della connessione, ovvero contenente un riscontro (ACK),
o
dei dati urgenti (PSH, URG)
una dimensione di finestra, che indica
quanti byte potranno essere accettati, a partire da quello referenziato
dall'ACK number, e mediante la quale il
destinatario può modulare la velocità di trasmissione del mittente.
La dimensione minima della intestazione è di 5 gruppi di 4 bytes, ossia 20
bytes, a cui possono seguire delle opzioni,
nel qual caso il campo Data Offset è usato per
indicare la dimensione totale della intestazione come numero totale di
gruppi di 4 byte. L'uso di alcune delle opzioni possibili sono commentate
a proposito dell'esempio a fine capitolo.
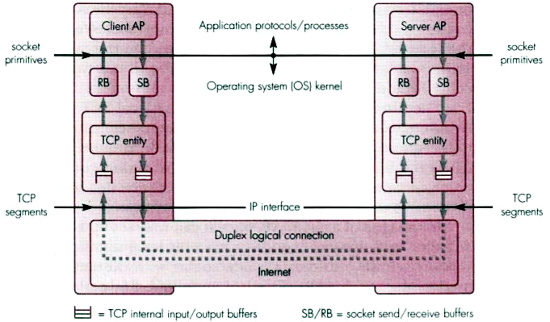
Nella figura che segue viene
evidenziato come i processi applicativi che risiedono nello user space, accedano
al servizio di trasporto offerto dagli strati inferiori che risiedono
all'interno del kernel,
per mezzo di primitive dette socket. Al suo
interno, l'implementazione della entità di trasporto (in questo caso, il
TCP) immagazzina i dati in transito da/verso lo strato applicativo nei send e receivebuffer
(SB e RB), le cui dimensioni dipendono dal sistema operativo, e dalla sua
disponibilità di memoria.
L'entità trasmittente, per dialogare con lo strato IP (che gli permette di
usufruire del servizio di rete), preleva i dati dal SB in unità chiamate segmenti, per depositarli in ulteriori memorie da
cui vengono inoltrati alla strato IP, ma anche conservati in modo da poter
ri-trasmettere gli eventuali pacchetti persi; l'entità ricevente invece,
utilizza memorie simili per conservare i segmenti ricevuti dallo strato
IP, in modo da poter sequenziare correttamente quelli ricevuti fuori
sequenza, e quando ne completa una serie ordinata, li deposita nel RB,
consentendo alla applicazione di prelevarli.
La dimensione dei segmenti che vengono passati allo strato IP, e che in
figura sono rappresentati dalle linee impilate nelle memorie in basso, è
detta Maximum Segment Size (MSS). Nel caso in
cui lo strato fisico si interfacci con una LAN Ethernet, la massima
dimensione del Payload della trama (ossia il pacchetto IP) è di 1500
bytes; pertanto in tal caso, tolti i 20 bytes della intestazione IP, ed i
20 bytes della intestazione TCP, restano 1500 - 40 = 1460 bytes per l'MSS.
Adottare un MSS più grande, obbligherà lo strato di rete ad operare una frammentazione, con conseguente scadimento
prestazionale; considerando poi che la presenza di opzioni negli header IP
e TCP, ne può aumentare le dimensioni, può essere opportuno adottare un
MMS inferiore a 1460 bytes.
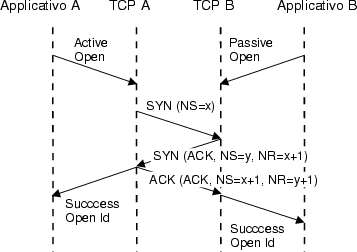
Come
illustrato nella figura a fianco, il lato server (applicativo B) a
seguito della sequenza
di system callsocket(), bind(),
listen(), accept(),
effettua una cosiddetta apertura passiva, ed
attende una richiesta di connessione. Il lato client (applicativo A), con
la connect(), invia un primo segmento di sincronizzazione, con il flag SYN
attivo, in cui comunica che intende iniziare a contare i byte trasmessi a
partire da x (Numero di
SequenzaNS=x).
Il server risponde inviando il riscontro (flag ACK
pari ad 1) del primo segmento ricevuto, in cui dichiara di essere in
attesa di ricevere il byte x+1 (Numero
di RiscontroNR=x+1); nello stesso
segmento, sincronizza anche (NS=y) il numero
di sequenza con cui conterà i dati inviati nelle risposte. A questo punto
sembrerebbe tutto terminato, ma resta invece da riscontrare al server la
ricezione del suo SYN, e questo avviene ad
opera del terzo segmento. Questa modalità di sincronizzazione, prende il
nome di stretta di mano a tre vie (three
way
handshake).
il primo è
quello basato su di una stima del round-trip
time (RTT) del collegamento, in modo da poter trasmettere con
continuità, come avviene per i protocolli di tipo Selective
Repeat. Man mano che vengono ricevuti i riscontri relativi ai
pacchetti inviati verso la medesima destinazione, la stima dell'RTT è
aggiornata, e la finestra modificata;
questa ampiezza massima può essere ridotta su intervento
del
ricevitore, allo scopo di realizzare un controllo
di flusso, riducendo la velocità del trasmettitore, fino
eventualmente ad azzerarla, oppure
può restringersi su iniziativa del trasmettitore,
qualora si avveda di una situazione di congestione.
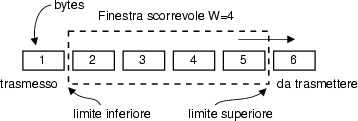
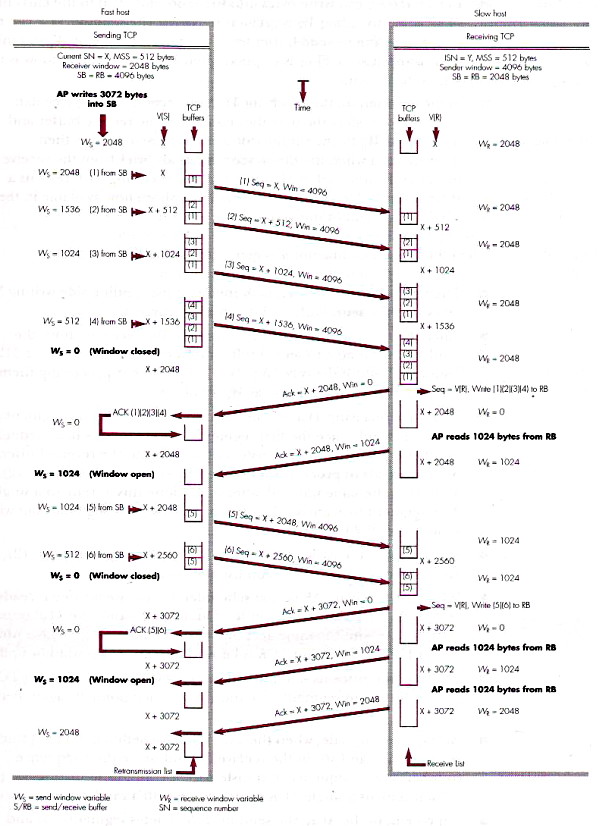
Una finestra simile è adottata anche dal lato ricevente del TCP, per
ricostituire l'ordine originario dei pacchetti, che possono essere
consegnati disordinatamente dallo strato IP di rete. Non appena il
ricevente acquisisce un segmento contiguo al limite inferiore, lo
trasferisce nel Receive Buffer, sposta il
limite inferiore in avanti, di tanti byte quanti ne ha ricevuti in modo
contiguo, ed invia un riscontro, con NR pari al più basso numero
di byte che ancora non è pervenuto. Ma se il Receive
Buffer non è stato ancora svuotato dallo strato applicativo,
l'entità ricevente non può liberare la coda dei segmenti provenienti dallo
strato di rete, e deve chiedere al trasmittente di azzerare l'ampiezza
della sua finestra di trasmissione.
RTO = RTT + 4D in cui
RTT = a*RTT + (1-a)*Re
D = a*D + (1-a)*|RTT - R|
dove a = 0.9
rappresenta il coefficente del filtro
passa-basso
IIR di primo ordine, che esegue lo smoothing
delle sequenze di osservazione. Così, il TCP si adatta alle condizioni di
carico della rete, ed evita di ri-spedire segmenti troppo presto, o di
attendere più del necessario. In particolare, nel caso di rete
congestionata, sia il ritardo degli ACK che la frequenza dei pacchetti
persi aumentano, e valori di timeout troppo ridotti potrebbero
peggiorare la situazione.
Una diversa causa di ritrasmissione si verifica quando la mancata
ricezione di un riscontro è dovuta alla perdita di un segmento in andata
(anziché del suo ACK), mentre invece i segmenti successivi sono consegnati
correttamente: in tal caso il ricevente continua a citare, nei suoi ACK,
sempre il numero di sequenza che indica il byte iniziale del segmento
mancante. La ricezione di tre ACK consecutivi fuori sequenza causa nel
mittente il convincimento che effettivamente un segmento sia andato perso
(e non solo ritardato), ma dato che almeno tre segmenti successivi sono
invece stati ricevuti correttamente, re-invia fiducioso il segmento perso,
anche se l'RTO non è ancora scaduto (o spirato).
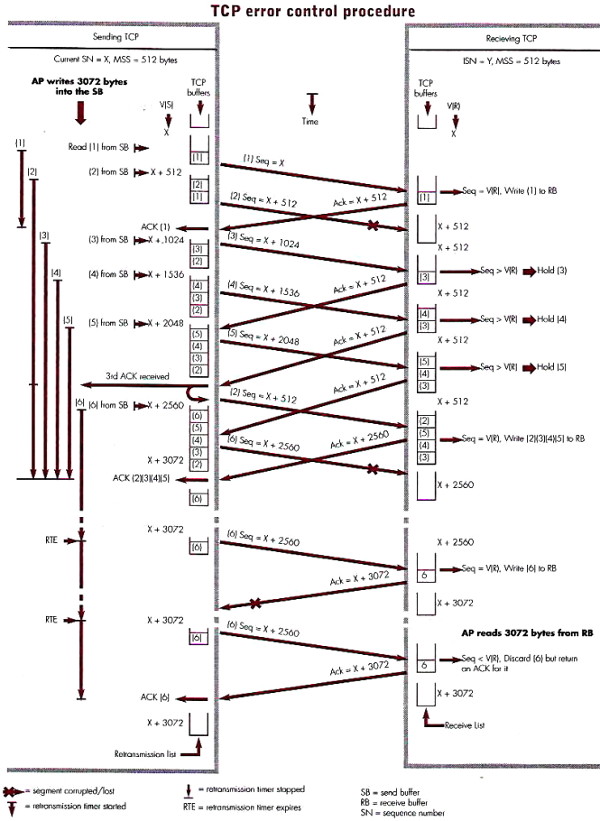
La figura seguente (tratta ancora da MMC) esemplifica
la procedura di controllo di errore, nel caso in cui
il Processo Applicativo AP del mittente
scriva 3072 bytes nel Send Buffer SB;
il Maximum Segment Size MMS sia pari a 512
per entrambe le entità, e dunque servano 6 segmenti per tramettere il
blocco di dati;
il mittente usi una Retransmission List
per mantenere in memoria i segmenti non ancora riscontrati, ed una Variabile di invio (Send)
V(S) dove memorizza il numero di sequenza del prossimo segmento da
inviare;
il ricevente usi una Receive List per
mantenere in memoria i segmenti ricevuti fuori sequenza, ed una Variabile
di Ricezione V(R) dove memorizza il prossimo numero di sequenza
che si aspetta di ricevere;
i segmenti 2 e 6 vengano persi, così come anche l'ultimo ACK.
Analizziamo ora ciò che accade:
il primo segmento è ricevuto correttamente, e dato che il suo numero
di sequenza è uguale a V(R), viene trasferito nel RB, la Receive
List è svuotata, V(R) si incrementa del MSS, e questo valore è
inviato come numero di riscontro nell'ACK. Alla ricezione dell'ACK, il
trasmettitore interrompe il Retrasmission Timer
del primo segmento;
il secondo segmento viene scartato dalla rete, e dato che per questo
non perviene nessun ACK, il suo timer continua ad incrementarsi. La
ricezione dei segmenti (3), (4), (5), tutti fuori sequenza (infatti Seq>V(R)), determina nel ricevente il loro
mantenimento nella Receive List, e l'invio
di riscontri contenenti sempre lo stesso valore di V(R)
=
X + 512, ad indicare che manca ancora il segmento (2);
alla ricezione del terzo ACK duplicato (in
quanto già ricevuto), il trasmettitore attua la procedura di fast
retransmit, e re-invia il segmento (2) senza attendere lo
scadere del timer (che viene resettato, e fatto ripartire). Questa volta
il segmento (2) è ricevuto correttamente, ed il ricevente trasferisce
tutto nel RB, svuota la receive list, pone V(R) =
X + 2560 pari al primo byte del prossimo segmento atteso, ed
usa questo valore per riscontrare tutto quanto ricevuto fino a quel
momento;
il trasmittente, alla ricezione dell'ACK, rimuove dalla Retrasmission
List tutti i segmenti riscontrati, ed elimina i rispettivi timer. Nel
frattempo, il segmento (6) è stato scartato, e dato che è l'ultimo della
comunicazione, il ricevente non invia nessun ACK, cosicché il suo timer
giunge a scadenza, ed il segmento viene ritrasmesso;
stavolta è l'ACK di (6) ad andare perso, sicché il trasmittente, dopo
un nuovo timeout, ritrasmette (6) per la terza volta. Il ricevente si
avvede che si tratta di un duplicato, in quanto Seq
<
V(R), ma lo riscontra ugualmente, per notificare il mittente
della sua corretta ricezione, in modo che possa essere svuotata la
Retransmission List, e il timer rimosso.
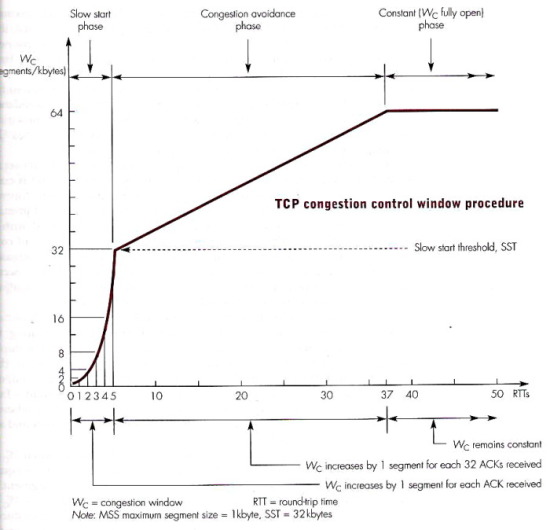
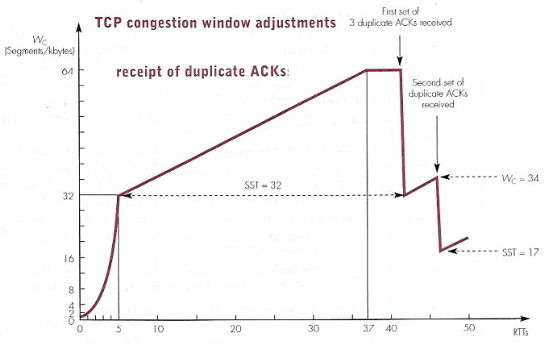
Il primo pacchetto in assoluto viene inviato con una strategia di tipo Send
and
Wait, ovvero adottando una finestra di dimensione pari ad un solo
segmento, e aspettandone dunque il riscontro, prima di inviarne un
secondo. Da quel momento, la connessione entra nella fase di slow
start, in cui l'ampiezza della finestra di trasmissione Wc
aumenta esponenzialmente nel tempo, in quanto è incrementata di un
segmento per ogni ACK ricevuto. Infatti, il primo ACK perviene dopo t0
+ RTT, e porta Wc a due segmenti, i cui riscontri pervengono ad
un istante t0 + 2RTT, portando l'ampiezza a 3 e poi a 4; i 4
ACK successivi arrivano quindi dopo t0 + 3RTT, e portano Wc
a 8. Dopo altri due RTT, Wc raggiunge la dimensione di 32
segmenti, determinando il raggiungimento della soglia
di slow start (SST) in un tempo pari a circa cinque volte il
valore dell'RTT.
Una volta raggiunto il valore di SST, la Wc viene incrementata
al ritmo di 1/ Wc segmenti per ogni segmento riscontrato, ossia
di un segmento per ogni Wc segmenti riscontrati, e dato che i
segmenti partono ad un ritmo di Wc per ogni RTT, questo
determina un aumento per Wc pari ad un segmento ogni RTT,
ovvero lineare nel tempo: questa fase è indicata con il termine di congestion avoidance. Al raggiungimento di una
seconda soglia per Wc (in figura, posta pari a 64) la procedura
di controllo congestione entra in una ulteriore fase, in cui il valore di
Wc è mantenuto costante, e Wc è detta pienamente
aperta.
In una rete congestionata, i nodi iniziano a scartare
pacchetti. Possono essere scartati i pacchetti di riscontro, o quelli
spediti. Nel primo caso, il segmento non riscontrato viene ritrasmesso, e
se arriva a destinazione, viene scartato dal ricevitore perché duplicato,
ma è riscontrato comunque, e dunque il trasmettitore si vede tornare
indietro degli ACK duplicati. Nel caso in cui vadano persi anche gli ACK
duplicati, il trasmettitore inizia a constatare lo scadere dei timer di
ritrasmissione.
Nel caso di perdita dei segmenti trasmessi, il TCP mittente interpreta la
ricezione di tre ACK duplicati per uno stesso segmento, come un indicatore
di una situazione di congestione. Anche se di fatto, la ricezione degli
ACK (per di più duplicati) indica che la rete è ancora in grado di
trasmettere, la perdita di un segmento trasmesso può segnalare l'inizio di
un fenomeno di congestione. Pertanto, il TCP reagisce
dimezzando la dimensione attuale della finestra di congestione, riducendo
così il numero di segmenti non riscontrati che è possibile trasmettere in
sequenza, e di conseguenza, riducendo il carico della rete. A questo
punto, Wc riprende a crescere, secondo una modalità detta di fast recovery, in accordo alle regole viste in
precedenza, ma ogni volta che vengono ricevuti 3 ACK duplicati, Wc
viene nuovamente dimezzata, e via di seguito.
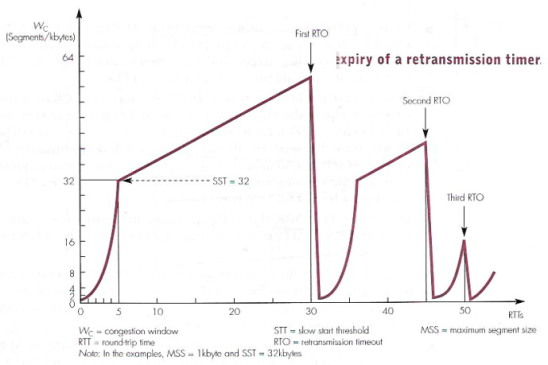
A questo meccanismo se ne aggiunge quindi un altro, legato alla perdita
dei riscontri, e basato sulla interpretazione dell'evento di scadenza
di un timeout, come segnale di un grave peggioramento
della congestione, in quanto ciò indica che sono andati persi tutti gli
ACK relativi ai segmenti che erano presenti nella stessa finestra di
trasmissione, oppure (ma nessuno può saperlo) tutti i segmenti stessi.
In questo caso il comportamento del TCP è quello di resettare la
procedura di controllo congestione, azzerando la dimensione di Wc,
e ri-partendo dalla fase di slow start, che
come abbiamo visto, inizia in modalità send and wait.
l'apertura di una connessione TCP con il three way handshake
caratterizzato dai flag SYN, SYN-ACK e ACK ai pacchetti 1-3
la presenza nelle intestazioni TCP di questi pacchetti dei campi
addizionali con le
opzioni
Maximum segment size: 1460 bytes - è la
dimensione dei segmenti prelevati dal Send
Buffer, che sommata alle intestazioni IP e TCP deve
risultare minore
della
MTU. Possiamo osservare che le due parti annunciano valori
differenti;
TCP SACK Permitted Option: True - RFC
2018 comunica al mittente la disponibilità a ricevere dei Selective
Acknoledge, che specificano uno o più intervalli di pacchetti
ricevuti, ma con numeri di sequenza maggiori di quello riscontrato
dall'ultimo ACK normale. Alla ricezione dei SACK, il mittente evita
di ritrasmettere i segmenti dichiarati già ricevuti;
Window scale: 2 (multiply by 4) - RFC
1323 permette di aumentare la massima dimensione della
finestra annunciata dal ricevente, che avendo a disposizione solo 16
bit nominali, non potrebbe superare il valore di65535 byte = 524280
bit. Nel caso di collegamenti con elevato prodotto
banda-ritardo la velocità di trasferimento sarebbe quindi
molto inferiore alla massima consentita: ad es. 1 Gbps con RTT di
100 msec consente di inviare 100 Mbit (108) durante un
RTT, e non solo 0.5 Mbit! L'opzione Window
Scale permette di shiftare i 16
bit della finestra fino a 14 posizioni a sinistra, permettendo di
definire finestre estese fino ad 1 Gbit.
la variazione della finestra annunciata dal ricevitore;
l'andamento dei numeri di sequenza, e di riscontro.
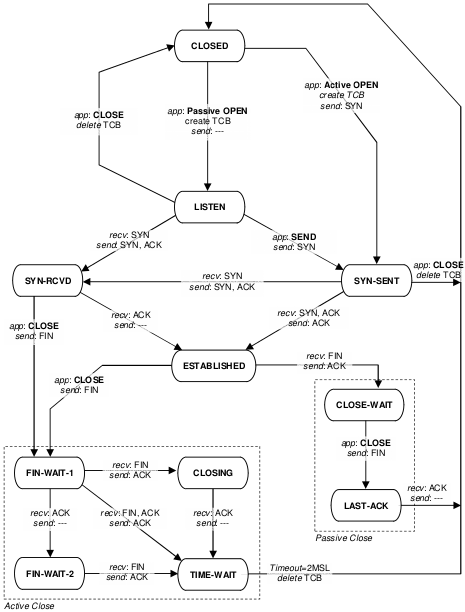
Partendo da closed, un programma server
si pone in listen (vedi capitolo
seguente) per poi arrivare a established
dopo aver terminato il three way handshake. Un
client invece effettua una active Open
iniziando con l'invio di un SYN. La chiusura
della
connessione può avvenire in modalità attiva o passiva a seconda di
quale delle due parti vi da inizio; lo stato di time-wait
non ritorna immediatamente a closed per evitare
di far arrivare alle nuove connessioni vecchi pacchetti di questa,
ma ritardati dalla rete.
Dal TCP al VoIP, dal DNS all'Email alla crittografia, tutto ciò che accade
dietro le quinte di Internet, completo di cattura del traffico.
Scopri
come effettuare il download,
ricevere gli aggiornamenti,
e contribuire!
 Descriviamo
innanzitutto cosa non è Internet,
illustrando brevissimamente i principi di funzionamento di una rete
telefonica pubblica (PSTN),
basata
sulla commutazione
di
circuito, e sulla multiplazione
a
divisione di tempo.
Descriviamo
innanzitutto cosa non è Internet,
illustrando brevissimamente i principi di funzionamento di una rete
telefonica pubblica (PSTN),
basata
sulla commutazione
di
circuito, e sulla multiplazione
a
divisione di tempo.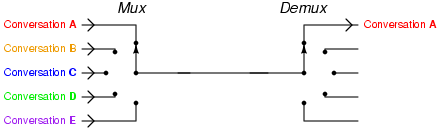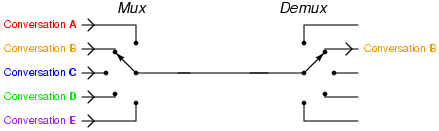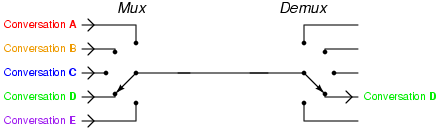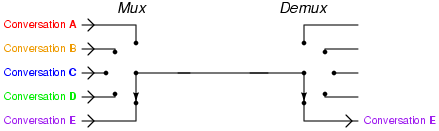 Le
cose non sono cambiate di molto (da un punto di vista concettuale) con
l'avvento della telefonia numerica: in tal caso, più segnali vocali sono
Le
cose non sono cambiate di molto (da un punto di vista concettuale) con
l'avvento della telefonia numerica: in tal caso, più segnali vocali sono 
 Il
processo di multiplazione è tale per cui il flusso binario risultante da
Il
processo di multiplazione è tale per cui il flusso binario risultante da 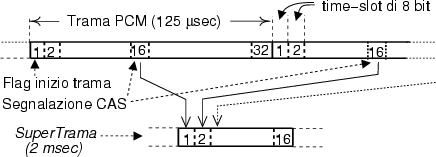 La
trama PCM si ottiene multiplando assieme 32 tributari, e quindi la
velocità complessiva risulta essere di 64.000 * 32 = 2.048.000
bit/secondo, comunemente indicato come
La
trama PCM si ottiene multiplando assieme 32 tributari, e quindi la
velocità complessiva risulta essere di 64.000 * 32 = 2.048.000
bit/secondo, comunemente indicato come 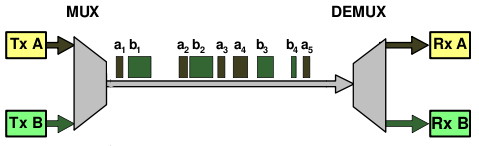

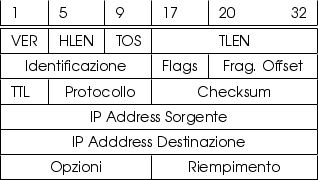 Si compone di un minimo di 20 byte,
in 5 file da 4. Il campo VER indica quale versione si sta
utilizzando, quella tuttora in uso è IPv4. HLEN e TLEN
indicano rispettivamente la lunghezza dell'header e di tutto il
pacchetto, mentre TOS codifica un
Si compone di un minimo di 20 byte,
in 5 file da 4. Il campo VER indica quale versione si sta
utilizzando, quella tuttora in uso è IPv4. HLEN e TLEN
indicano rispettivamente la lunghezza dell'header e di tutto il
pacchetto, mentre TOS codifica un 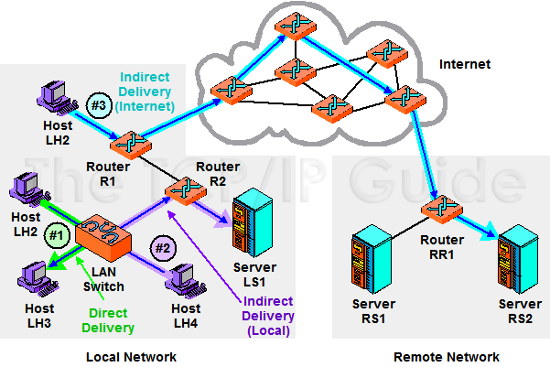


 I router che eseguono
il BGP mantengono aperta una connessione TCP con gli omologhi degli AS
adiacenti, detti
I router che eseguono
il BGP mantengono aperta una connessione TCP con gli omologhi degli AS
adiacenti, detti 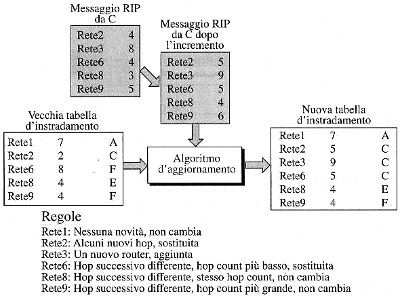

 D'altra
parte, anche se i computer dotati di un IP privato possono comunque
inviare pacchetti diretti verso indirizzi di destinazione pubblici, ed in
questo senso
D'altra
parte, anche se i computer dotati di un IP privato possono comunque
inviare pacchetti diretti verso indirizzi di destinazione pubblici, ed in
questo senso 
 In
tutti
i casi, il pacchetto ICMP di ritorno viene assemblato a partire da quello
(IP) di andata, come mostrato in figura. In particolare, l'intestazione IP
ricevuta, ed i primi 8 byte di ciò che segue (es TCP), viene prefissa
dalla intestazione ICMP, che è poi ulteriormente prefissa dalla
intestazione IP che serve a recapitare il pacchetto all'indietro. In
questo modo, il mittente originario ha tutti gli estremi per ri-associare
il messaggio ICMP alla connessione uscente che ha prodotto il pacchetto IP
originario.
In
tutti
i casi, il pacchetto ICMP di ritorno viene assemblato a partire da quello
(IP) di andata, come mostrato in figura. In particolare, l'intestazione IP
ricevuta, ed i primi 8 byte di ciò che segue (es TCP), viene prefissa
dalla intestazione ICMP, che è poi ulteriormente prefissa dalla
intestazione IP che serve a recapitare il pacchetto all'indietro. In
questo modo, il mittente originario ha tutti gli estremi per ri-associare
il messaggio ICMP alla connessione uscente che ha prodotto il pacchetto IP
originario.
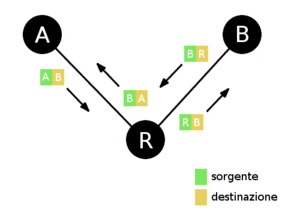
 Quando l'indirizzo IP di
destinazione ricade nella stessa sottorete (LAN) del mittente (o del
router che lo inoltra), i due computer (oppure computer e
Quando l'indirizzo IP di
destinazione ricade nella stessa sottorete (LAN) del mittente (o del
router che lo inoltra), i due computer (oppure computer e 
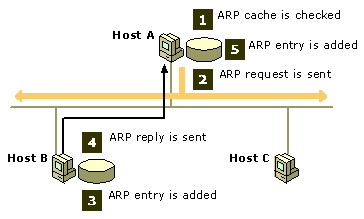 Ogni computer mantiene una cache (1) delle risoluzioni (gli indirizzi
MAC associati agli IP) già ottenute di recente, in modo da evitare il
ricorso ad ARP ogni volta. Le corrispondenze della cache sono mantenute
per un periodo breve, (es 10 minuti), e possono essere visualizzate con
il comando
Ogni computer mantiene una cache (1) delle risoluzioni (gli indirizzi
MAC associati agli IP) già ottenute di recente, in modo da evitare il
ricorso ad ARP ogni volta. Le corrispondenze della cache sono mantenute
per un periodo breve, (es 10 minuti), e possono essere visualizzate con
il comando 

 Facciamo
un esempio: una sorgente, a seguito della fase di instradamento, invia i
pacchetti con identificativo
Facciamo
un esempio: una sorgente, a seguito della fase di instradamento, invia i
pacchetti con identificativo 
 Come
illustrato nella figura a fianco, il lato server (applicativo B) a
seguito della
Come
illustrato nella figura a fianco, il lato server (applicativo B) a
seguito della