Prec Capitolo 11: Teoria
dell’informazione e codifica Su Capitolo 11: Teoria dell’informazione
e codifica Sezione 11.2: Codifica di
canale Segue
11.1 Codifica di sorgente↓
Una fonte informativa (o sorgente) può essere
per sua natura di tipo discreto, come nel caso di un documento scritto,
o di tipo continuo, come nel caso di un segnale analogico, ad esempio
audio e video. In base a considerazioni di tipo statistico, la sorgente
può essere caratterizzata da una grandezza, l’entropia, che
indica il tasso di informazione (in bit/secondo) intrinseco per
i messaggi prodotti dalla sorgente; d’altra parte, la descrizione in
modo nativo dei messaggi prodotti può risultare in una velocità di
trasmissione ben superiore!
Lo scopo della codifica di sorgente è
quello di individuare rappresentazioni alternative per le informazioni
prodotte dalla sorgente, in modo da ridurre la quantità di bit/secondo
necessari alla trasmissione, a valori quanto più possibile prossimi a
quelli dell’entropia, sfruttando le caratteristiche della sorgente, del
processo di codifica, e del destinatario dei messaggi, ovvero
- la particolare distribuzione statistica dei simboli o dei valori emessi dalla sorgente, che può permettere l’uso di un minor numero di bit per rappresentare i simboli più frequenti di altri;
- la dipendenza statistica presente tra simboli successivi, ovvero la presenza di un fenomeno di memoria intrinseco della sorgente, che rende possibile entro certi limiti la predizione dei valori futuri;
- l’introduzione di un ritardo di codifica, che permette di analizzare un intero intervallo temporale del messaggio;
- nel caso di segnali multimediali, l’esistenza di fenomeni percettivi legati alla fisiologia dell’apparato sensoriale, che possono guidare il codificatore nella scelta delle componenti di segnale da sopprimere, in quanto percettivamente non rilevanti.
Nel caso di sorgenti nativamente discrete, come
ad esempio documenti in formato elettronico, lo scopo della codifica di
sorgente è quello di permettere la ricostruzione integrale di
quanto trasmesso, che dunque viene detta senza perdita di
informazione. Nel caso invece di sorgenti continue, si ottiene una
sequenza numerica a seguito di un processo di campionamento e
quantizzazione, che determina l’insorgenza di una prima causa di distorsione
nel messaggio ricostruito, mentre la velocità binaria effettiva può
essere ulteriormente ridotta grazie allo sfruttamento dei fenomeni
percettivi: in tal caso il risultato della codifica viene detto con
perdita di informazione.
11.1.1 Codifica di sorgente discreta
Sorgente
senza memoria↓
Prendiamo in considerazione una sorgente
discreta e stazionaria, che emette una sequenza x(n)
composta di simboli xk
appartenenti ad un alfabeto di cardinalità L
(ossia con k = {1,
2, ⋯, L}), ognuno
contraddistinto dalla probabilità di emissione pk
= Pr(xk). Il termine senza memoria si
riferisce al fatto che, se indichiamo con xh,
xk una coppia di simboli emessi uno
dopo l’altro (ossia x(n) = xh, x(n + 1) = xk), la
probabilità del simbolo emesso per secondo non dipende dall’identità di
quello(i) emesso precedentemente, ossia p(xk ⁄ xh) = p(xk) = pk.
Definiamo informazione (espressa in bit)
associata all’osservazione del simbolo xk
il valore [431] [431] Per calcolare il logaritmo in
base 2, si ricordi che log2α
= (log10α)/(log102)≃3.32log10α.
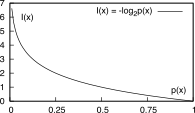 che rappresenta il grado di incertezza a riguardo del verificarsi
dell’evento xk
(prima che questo si verifichi), ovvero di quanto possiamo ritenerci
sorpresi nel venire a conoscenza dell’evento xk,
di cui riteniamo di conoscere la probabilità pk.
Osserviamo infatti che per come è fatta la funzione logaritmo, a bassi
valori di probabilità è associata una informazione elevata. La scelta di
usare il logaritmo in base 2 produce i seguenti risultati:
che rappresenta il grado di incertezza a riguardo del verificarsi
dell’evento xk
(prima che questo si verifichi), ovvero di quanto possiamo ritenerci
sorpresi nel venire a conoscenza dell’evento xk,
di cui riteniamo di conoscere la probabilità pk.
Osserviamo infatti che per come è fatta la funzione logaritmo, a bassi
valori di probabilità è associata una informazione elevata. La scelta di
usare il logaritmo in base 2 produce i seguenti risultati:
Ik = I(xk) = log2(1)/(pk)
= − log2pk bit
| Prob. | Informazione | Commento |
| pk | − log2pk | |
| 1 | 0 | L’evento certo non fornisce informazione |
| 0 | ∞ | L’evento impossibile dà informazione infinita |
| (1)/(2) | 1 | In caso di scelta binaria (es. testa o croce) occorre una cifra binaria (bit = binary digit) per indicare il risultato |
11.1.1.1 Entropia↓
Come in termodinamica al concetto di entropia si associa il grado di
disordine in un sistema, così per una sorgente informativa
l’entropia misura il livello di casualità dei simboli emessi.
Definiamo quindi entropia (indicata con H)
di una sorgente discreta S, il
valore atteso della quantità di informazione apportata dalla conoscenza
dei simboli (scelti tra L
possibilità) da essa generati
che pesando in probabilità il valore di informazione associato ai
diversi simboli, rappresenta il tasso medio di informazione per
simbolo delle sequenze osservabili. Come mostrato nell’esercizio che
segue, risulta che:
- se i simboli sono equiprobabili (pk = (1)/(L) con ∀k), la sorgente è massimamente informativa, e la sua entropia è la massima possibile per un alfabeto ad L simboli, e pari a HsMax = (1)/(L)∑Lk = 1log2L = log2L bit/simbolo;
- se i simboli non sono equiprobabili, allora Hs < log2L;
- se la sorgente emette sempre e solo lo stesso simbolo, allora Hs = 0.
Da queste osservazioni discende l’espressione
riassuntiva
(12.2)
0 ≤ Hs ≤ log2L
Per
dimostrare formalmente questo risultato, osserviamo innanzitutto che
Hs ≥ 0 in
quanto la (12.1↑)
comprende tutti termini positivi o nulli, essendo log2α
≥ 0 per α = 1⁄pk
≥ 1. Quindi, mostriamo che Hs
− log2L ≤ 0. Innanzitutto riscriviamo il
primo membro della diseguaglianza come
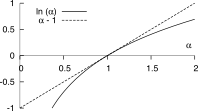 A questo punto utilizziamo la relazione
lnα ≤ α − 1 mostrata in
figura, con l’uguaglianza valida solo se α
= 1, ottenendo così
A questo punto utilizziamo la relazione
lnα ≤ α − 1 mostrata in
figura, con l’uguaglianza valida solo se α
= 1, ottenendo così
Hs − log2L
= ⎲⎳kpklog2(1)/(pk) − log2L⋅ ⎲⎳kpk
= ⎲⎳kpklog2(1)/(L⋅pk)
dato che ∑kpk
= 1. Quindi, esprimiamolo in termini dei logaritmi naturali,
tenendo conto che log2α = (lnα)/(ln2), e quindi
⎲⎳kpklog2(1)/(L⋅pk) = (1)/(ln2) ⎲⎳kpkln(1)/(L⋅pk)
Hs −
log2L
= (1)/(ln2) ⎲⎳kpkln(1)/(L⋅pk) ≤ (1)/(ln2) ⎲⎳kpk⎛⎝(1)/(L⋅pk) − 1⎞⎠
=
= (1)/(ln2)⎛⎝ ⎲⎳k(1)/(L) − ⎲⎳kpk⎞⎠
= (1)/(ln2)(1 − 1)
= 0
con il segno di uguale solo se (1)/(L⋅pk) = 1 ovvero pk
= (1)/(L⋅). Entropia
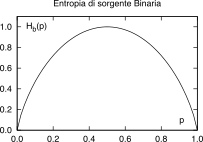
di sorgente binaria↓
Nel caso particolare delle sorgenti binarie, che
producono uno tra due simboli {x0,
x1} con
probabilità rispettivamente p0
= p, p1 = q
= 1 − p, la formula dell’entropia fornisce l’espressione
il cui andamento è mostrato nella figura 11.3↓, in funzione di p.
I due simboli {x0,
x1} possono
essere rappresentati dalle 2 cifre binarie {0, 1},
che in questo caso chiamiamo binit, per non confonderli con la
misura dell’informazione (il bit). Osserviamo quindi che se p
≠ .5 risulta Hb(p) <
1, ossia la sorgente emette informazione con un tasso inferiore
a un bit/simbolo, mentre a prima vista non potremmo usare meno di un
binit per rappresentare ogni simbolo binario, introducendo una
ridondanza↓
pari a 1 − Hb(p) (graficata) [432] [432] Si presti attenzione sulla
differenza: la ridondanza della codifica di sorgente
indica i binit/simbolo che eccedono il valore dell’entropia,
mentre la ridondanza della codifica di canale indica il
rapporto tra binit di protezione e quelli di effettivamente emessi
dalla sorgente, come definito a pag. 1↑..
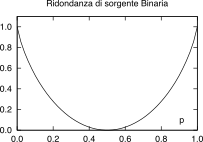
Esempio Consideriamo
il caso di una sorgente con p0
= 0.8 e p1 = 0.2.
L’applicazione della (12.3↑)
fornisce un valore Hb(0.8) = .8log2(1)/(.8) + .2log2(1)/(.2) = 0.72 bit/simbolo,
minore del valore di 1 bit/simbolo che si sarebbe ottenuto nel caso di
equiprobabilità.
L’applicazione della (12.2↑) al caso di una sorgente che emette
simboli non equiprobabili ed appartenenti ad un alfabeto di
cardinalità L, determina per la
stessa un valore di entropia HL
< log2L bit/simbolo: se i simboli sono
codificati utilizzando ⌈log2L⌉ binit/simbolo [433]
[433] La notazione ⌈α⌉ indica l’intero superiore ad α: ad esempio, se α
= 3.7538, si ha ⌈α⌉ = 4., otteniamo
una ridondanza pari a ⌈log2L⌉ − HL.
Esempio Consideriamo
il caso di una sorgente quaternaria con p0
= 0.5, p1 = 0.25,
p2 = 0.125, p3
= 0.125. L’applicazione della (12.1↑) fornisce H4
= 1.75 bit/simbolo, inferiore ai 2 bit/simbolo che si
sarebbero ottenuti nel caso di simboli equiprobabili.
11.1.1.2 Intensità informativa e codifica binaria ↓
Continuiamo a riferirci ad una sorgente discreta
e senza memoria, caratterizzata da una entropia Hs
bit/simbolo, ed i cui simboli xk
sono emessi ad una frequenza fs
simboli/secondo: il flusso informativo prodotto è dunque
caratterizzato da una intensità o velocità informativa
pari a
 Volendo trasmettere tale informazione attraverso un canale binario
(vedi § 11.2.1↓),
occorre che l’elemento indicato nella figura a lato come codificatore
binario faccia corrispondere ad ogni simbolo xk
una univoca sequenza di Nk
bit (d’ora in poi indicata come codeword↓ appartenente ad
un codebook↓) [434] [434] Mettere in corrispondenza i
diversi simboli di sorgente con una loro codifica binaria è detta codifica
per blocchi, discussa al § 11.1.1.4↓, dove si mostra anche la
possibilità di emettere le codeword in corrispondenza di più
di un simbolo di sorgente., scelti in uno dei modi
descritti nel seguito, producendo una velocità di trasmissione
binaria di fb binit⁄sec. Dal punto di
vista del canale, il messaggio è prodotto da una nuova sorgente, i cui
simboli binari hanno probabilità p
e 1 − p, e dunque caratterizzata
da una entropia Hb(p) bit⁄binit
≤ 1. Dato che l’intensità informativa in ingresso ed in uscita
dal codificatore deve essere la stessa [435] [435] Essendo
la corrispondenza tra xk
ed Nk
univoca, non vi è perdita di informazione., la
velocità binaria fb
della nuova sorgente rispecchia il vincolo
Volendo trasmettere tale informazione attraverso un canale binario
(vedi § 11.2.1↓),
occorre che l’elemento indicato nella figura a lato come codificatore
binario faccia corrispondere ad ogni simbolo xk
una univoca sequenza di Nk
bit (d’ora in poi indicata come codeword↓ appartenente ad
un codebook↓) [434] [434] Mettere in corrispondenza i
diversi simboli di sorgente con una loro codifica binaria è detta codifica
per blocchi, discussa al § 11.1.1.4↓, dove si mostra anche la
possibilità di emettere le codeword in corrispondenza di più
di un simbolo di sorgente., scelti in uno dei modi
descritti nel seguito, producendo una velocità di trasmissione
binaria di fb binit⁄sec. Dal punto di
vista del canale, il messaggio è prodotto da una nuova sorgente, i cui
simboli binari hanno probabilità p
e 1 − p, e dunque caratterizzata
da una entropia Hb(p) bit⁄binit
≤ 1. Dato che l’intensità informativa in ingresso ed in uscita
dal codificatore deve essere la stessa [435] [435] Essendo
la corrispondenza tra xk
ed Nk
univoca, non vi è perdita di informazione., la
velocità binaria fb
della nuova sorgente rispecchia il vincolo
R = fs⋅Hs
bit/secondo
fb ≥ fb⋅Hb(p) = fs⋅Hs
= R
Il rapporto =
(fb)/(fs) ≥ Hs
rappresenta il numero medio di cifre binarie emesse per ciascun
simbolo della sorgente, e può essere valutato a partire dalle
probabilità pk
dei simboli xk,
come = ∑kpkNk.
Il primo teorema di Shannon↓ [436] [436] http://it.wikipedia.org/wiki/Primo_teorema_di_Shannon,
o della codifica di sorgente, afferma che esiste un modo
di scegliere gli Nk
binit associati ai simboli xk
tale che [437] [437] In effetti la (12.4↓) sussiste qualora il codificatore
non operi indipendentemente su ogni simbolo di sorgente, ma più in
generale possa emettere i binit in corrispondenza di sequenze di xk via via
più lunghe.
(12.4)
Hs ≤
≤ Hs + ϵ
con ϵ piccolo a piacere, e che si
annulla in corrispondenza della codifica ottima, per la quale
risulta = Hs.
Ma non dice come fare. Rappresenta l’efficienza del processo di
codifica binaria, ed è definito come
η = (Hs)/() = (R)/(fb)
= Hb(p) ≤ 1
ovvero quanti bit di sorgente sono trasportati da ogni binit di codifica [438] [438] Ad esempio, un valore η = 0.33 indica che ogni binit
trasporta solo 1⁄3
di bit.. D’altra parte, sappiamo già che se i binit
emessi a velocità fb
assumono i valori 0 o 1 in modo equiprobabile, allora Hb⎛⎝(1)/(2)⎞⎠ = 1,
ovvero fb = R
e = Hs,
e dunque il problema di individuare un codice ottimo sembrerebbe quello
di trovare un insieme di parole di codeword tali da rendere le
cifre binarie equiprobabili, con il vincolo di mantenere il codice decifrabile,
ovvero tale da rispettare la regola del prefisso. Ma andiamo con
ordine. 11.1.1.3 Codifica con lunghezza di parola variabile
Mostriamo mediante un esempio come scegliendo codeword più lunghe
per rappresentare i simboli meno probabili, e più corte
per i simboli più frequenti, si può subito ottenere un miglior
rendimento del codice. Consideriamo infatti una sorgente con alfabeto di
cardinalità L = 4, ai cui simboli
competono le probabilità riportate alla seconda colonna della tabella.
In questo caso l’entropia vale
| Simbolo | Prob. | Codeword | Nk |
| x1 | .5 | 0 | 1 |
| x2 | .25 | 10 | 2 |
| x3 | .125 | 110 | 3 |
| x4 | .125 | 111 | 3 |
Hs
=
⎲⎳kpklog2(1)/(pk)
=
(1)/(2)log22 + (1)/(4)log24 + (2)/(8)log28 = (1)/(2) + (1)/(2) + (2)/(8)3 = 1.75
bit/simbolo
Se il codificatore di sorgente adotta le corrispondenze mostrate nella
terza colonna della tabella, a cui competono le lunghezze in binit
riportate quarta colonna, il numero medio di binit/simbolo
prodotto dalla codifica binaria risulta pari a
N = E{L} = ⎲⎳kNkpk
= 1⋅(1)/(2) + 2⋅(1)/(4)
+ 3⋅(2)/(8) = 1.75
binit/simbolo
Il risultato ottenuto Hs
= , ovvero il migliore
possibile, non è per nulla scontato, e mostriamo appresso come dipenda
sia dalla particolare scelta fatta per le codeword, sia dal particolare
tipo delle pk
dell’esempio, tutte potenze negative di due (essendo 0.5
= 2 − 1, 0.25 = 2 − 2,
0.125 = 2 − 3). Regola
del prefisso↓
Perché un insieme di codewords possa costituire
un codice di sorgente, esse devono poter essere riconosciute
come distinte presso il ricevitore, e questo è possibile a patto
che nessuna di esse sia uguale all’inizio di una codeword più
lunga. Si può mostrare che ciò è possibile purché le lunghezze Nk
delle codeword soddisfino la disuguaglianza di Kraft [439]
[439] https://en.wikipedia.org/wiki/Kraft's_inequality↓, espressa come
(12.5)
K = L⎲⎳k
= 12 − Nk ≤ 1
Esempio Nella tabella sono riportati quattro possibili codici
(A,B,C,D) per la sorgente quaternaria già discussa, assieme
al corrispettivo valore di
e K.
| Simb. | pk | A | B | C | D |
| x1 | .5 | 00 | 0 | 0 | 0 |
| x2 | .25 | 01 | 1 | 01 | 10 |
| x3 | .125 | 10 | 10 | 011 | 110 |
| x4 | .125 | 11 | 11 | 0111 | 111 |
| 2.0 | 1.25 | 1.875 | 1.75 | ||
| K | 1.0 | 1.5 | 0.9375 | 1.0 | |
Le
codeword del codice B producono un valore K
= 1.25 > 1, e dunque rappresentano un codice
ambiguo [440] [440] Ad
esempio, la sequenza 10110010
potrebbe essere interpretata come x3x4x1x1x3
oppure x2x1x4x1x1x2x1
o x3x2x2x1x1x3:
difatti violano sia la regola del prefisso, che il limite (12.5↑). Il codice C invece è
non ambiguo [441] [441] Nonostante
il codice C non soddisfi
la regola del prefisso, non è ambiguo in quanto lo zero indica
comunque l’inizio di una nuova codeword., essendo K < 1,
ma presenta una efficienza (Hs)/()
= 0, 9 < 1 e dunque
subottimale. Infine, il codice D è quello analizzato al
precedente paragrafo, ed effettivamente risulta una scelta ottima,
dato che (Hs)/() = 1 e le sue
codeword soddisfano la (12.5↑).
Indichiamo con questo termine un codice che soddisfa la regola del
prefisso, e per il quale (Hs)/()=1: ciò equivale a dire che
i valori delle probabilità di simbolo devono risultare potenze
negative di due, ovvero pk
= 2 − Nk. In tal caso la (12.5↑)
è verificata con il segno di uguale [442] [442] Infatti
ora la (12.5↑)
si scrive K = ∑Lk = 12 − Nk
= ∑Lk
= 1pk = 1.,
e scegliendo le lunghezze di codeword proprio pari a Nk
= log2(1)/(pk),
possiamo verificare come l’espressione che calcola = ∑kpkNk
coincida con quella che fornisce Hs
= ∑kpklog2(1)/(pk), ovvero ogni simbolo è
codificato con una codeword lunga tanti binit quanti sono i bit di
informazione che trasporta. Per individuare un codice che si
avvicini a questa proprietà si può realizzare la tecnica di Huffman
presentata appresso, mentre per modificare le pk
si ricorre alla codifica per blocchi di simboli.
Si tratta di un algoritmo che permette di
realizzare un codice a lunghezza variabile che soddisfa la regola del
prefisso, adotta codeword più lunghe ai simboli meno probabili, ed
uniforma, per quanto possibile, la probabilità delle cifre binarie. Si
basa [443] [443] Vedi http://en.wikipedia.org/wiki/Huffman_coding
sulla costruzione di un albero binario, i cui rami sono etichettati con
1 e 0, e può essere descritto come segue:
- crea una lista contenente i simboli della sorgente, ordinati per valore di probabilità decrescente, ed associa ad ognuno di essi un nodo-foglia dell’albero;
- finché c’è più di un nodo
nella lista:
- rimuovi dalla lista i due nodi con la probabilità più bassa;
- crea un nuovo nodo interno all’albero con questi due nodi come figli, e con probabilità pari alla somma delle loro probabilità;
- aggiungi il nuovo nodo alla lista;
- il nodo rimanente è la radice, e l’albero è completo;
- assegna cifre binarie diverse ad ogni coppia di rami a partire dalla radice, concatenando le quali ottieni le codeword per i simboli sulle foglie
Si può dimostrare che il codice di Huffman
generato in questo modo è il migliore possibile nel caso in cui la
statistica dei simboli di sorgente sia nota a priori, nel senso che
produce una codifica con il minor numero possibile di binit/simbolo
medi. La codifica di Huffman è ampiamente utilizzata nel contesto di
altri metodi di compressione (metodo deflate
di pkzip, § 11.1.1.7↓) e di codec multimediali (jpeg
e mp3, cap. 12↓), in virtù della sua semplicità, velocità,
ed assenza di brevetti.
Ovviamente ci deve essere un accordo a priori tra
sorgente e destinatario a riguardo delle corrispondenze tra parole di
codice e simboli (o blocchi di simboli) della sorgente. Nel caso in cui
ciò non sia vero, oppure nel caso in cui la statistica dei simboli della
sorgente sia stimata a partire dal materiale da codificare, occorre
inviare all’inizio della comunicazione anche la tabella di
corrispondenza, eventualmente in forma a sua volta codificata.
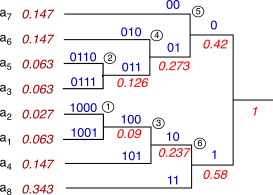
Esempio una sorgente con L
= 8 simboli è caratterizzata dalle probabilità di simbolo
riportate in figura, a partire dalle quali si realizza un codice di
Huffman mediante la costruzione grafica riportata, in cui le
probabilità sono scritte sotto i rami ed accanto ai simboli,
mentre i binit sopra. Dopo aver ordinato i simboli in base
alle probabilità, si individuano i due nodi a prob. più bassa come a1 e a2,
che assommano prob. 0.09; dunque la coppia ora meno probabile è a3 con a5,
che cumulano prob. 0.126. Quindi, le due prob. minori divengono
quelle di a4 e
della coppia a1a2,
per un totale di 0.237, e poi è il turno di raggruppare a6
con a3a5,
per un totale di 0.273. Quest’ultimo nodo viene allora combinato con
a7 con
prob. complessiva 0.42, quindi è il turno di a8
con a1a2a4
che totalizzano 0.58, ed infine questo nodo è collegato con il (5).
A questo punto, partendo dalla radice a destra, si assegna un binit
pari a 0 o 1 ad ogni coppia di rami, ripetendo l’assegnazione per le
coppie discendenti, fino al risultato mostrato.
|
 |
Questa variante permette di costruire e
modificare l’albero di codifica [444] [444] Presso
Wikipedia si trova una descrizione dell’algoritmo di Vitter
http://en.wikipedia.org/wiki/Adaptive_Huffman_coding
man mano che i simboli sono trasmessi. In questo modo, se un carattere è
già presente nel codebook, viene trasmessa la codeword corrispondente,
mentre se non lo è, viene trasmesso il codice del carattere, ed
aggiornato il codebook. Lo stesso processo si svolge anche dal lato
ricevente, permettendo una codifica in tempo reale, e l’adattamento a
condizioni di variabilità nei dati. Ovviamente, il metodo inizia ad
essere efficiente solo dopo aver accumulato sufficienti informazioni
statistiche.
11.1.1.4 Codifica per blocchi↓
Riprendiamo la discussione iniziata a pag. 1↑ relativa al codice binario ottimo per una
sorgente L − aria senza memoria
con simboli ak a
probabilità pk,
notando che se la lunghezza Nk
delle codeword viene scelta in modo tale che
si può mostrare che la condizione (12.5↑) è soddisfatta. Inoltre, moltiplicando i
membri di (12.6↑)
per pk e
sommando su k si ottiene
Hs ≤
≤ Hs + 1
da cui si osserva che è possibile ottenere (Hs)/()≃1 solo se Hs≫1
oppure se Nk≃log2(1)/(pk). Altrimenti, possiamo
ricorrere al trucco di trasformare la nostra sorgente ad
L simboli in una equivalente con Ln simboli, ottenuti
concatenando n simboli della
sorgente originaria. Dato che questi ultimi sono indipendenti, la nuova
sorgente esibisce una entropia Hbloccos
= nHs, e la regola di codifica (12.6↑) produce ora il risultato nHs
≤ n ≤ nHs
+ 1 in cui n
è il numero medio di binit per blocco. Dividendo per n,
otteniamo infine
(12.7)
Hs ≤
≤ Hs + (1)/(n)
che rappresenta una diversa forma del teorema (12.4↑) con ϵ = (1)/(n), e che permette di
ottenere → Hs
se n → ∞, avvicinandosi alle
condizioni di codifica ottima per qualsiasi distribuzione delle pk.
Per applicare questo metodo ad un caso pratico, consideriamo una
sorgente binaria senza memoria con le pk
mostrate in tabella, e raggruppiamone i simboli a coppie, a cui
competono probabilità di emissione ottenute moltiplicando le probabilità
originarie [445] [445] operazione resa possibile in
conseguenza della indipendenza statistica tra i simboli binari,
e quindi codifichiamo i nuovi simboli quaternari con il codice a
lunghezza variabile già esaminato.
| Simbolo | Prob. | Codeword |
| x1 | .8 | 1 |
| x2 | .2 | 0 |
| x1x1 | .64 | 0 |
| x1x2 | .16 | 10 |
| x2x1 | .16 | 110 |
| x2x2 | .04 | 111 |
Mentre il valore dell’entropia della sorgente
binaria originale è ancora quello calcolato nel primo esempio a pag. 1↑
e pari a Hb = 0.72
bit a simbolo, la lunghezza media del nuovo codice risulta ora
N = 1⋅0.64
+ 2⋅0.16 + 3⋅0.16 + 3⋅0.04 = 1.58 binit
ogni 2 simboli, ossia pari ad una media di 0.79 binit/simbolo binario,
effettivamente più vicina al valore di Hb
= 0.72. Compromesso
velocità-ritardo↓
Come indicato dalla (12.7↑), realizzando blocchi via via più lunghi
è possibile ridurre la velocità media di codifica N (in binit/simbolo)
rendendola sempre più vicina all’entropia, ovvero
min[] = Hs + ε
in cui ε
→ 0 se la lunghezza
del blocco tende ad infinito. D’altra parte, all’aumentare della
dimensione del blocco aumenta di egual misura il ritardo che
intercorre tra l’emissione di un simbolo e la sua codifica, e di
questo va tenuto conto, nel caso sussistano dei vincoli temporali
particolarmente stringenti sulla consegna del messaggio. Qualora una sorgente discreta ad L
simboli esibisca un valore di entropia inferiore a log2L,
la velocità binaria in uscita dal codificatore di sorgente può essere
ridotta adottando una codifica a blocchi, e utilizzando per i nuovi
simboli un opportuno codice di Huffman.
Esercizio Si
ripeta il calcolo del numero medio di binit/simbolo, adottando lo
stesso codice a lunghezza variabile usato finora, per codificare i
simboli emessi dalla sorgente binaria Markoviana di primo ordine
analizzata all’esempio seguente, e mostrare come in questo caso si
riesca ad ottenere una velocità media pari a 0.72
bit/simbolo. Sperimentare quindi la costruzione di un codice di
Huffman basato sul raggruppamento di tre simboli di sorgente, per
verificare se ci si riesce ad avvicinare di più al valore limite
indicato dalla entropia, come vedremo pari a 0.58
bit/simbolo.
11.1.1.5 Sorgente con memoria↓
Rimuoviamo ora l’ipotesi di indipendenza
statistica tra i simboli emessi. In questo caso indichiamo con x
= {x(1), x(2), …, x(N)} una
sequenza di N di simboli, la cui
probabilità congiunta si calcola come
p(x) = p(x1)p(x2
⁄ x1)p(x3
⁄ x1, x2)…p(xN ⁄ x1,
x2, …xN − 1)
≠ N∏k = 1p(xk)
dato che appunto la dipendenza statistica comporta l’uso delle
probabilità condizionali. In questo caso, l’espressione dell’entropia si
modifica in
HN = Ex{I(x)} = − (1)/(N)
⎲⎳
per tutte le x p (
x )log2p(x) bit/simbolo
dove la sommatoria si intende replicata N
volte, in modo da eseguire la media statistica su tutte le possibili
sequenze x di lunghezza N.
La grandezza HN
prende il nome di entropia a blocco↓,
e si dimostra che al crescere di N
il suo valore è non crescente, ossia HN
+ 1 ≤ HN ≤ HN − 1,
mentre per N → ∞, HN tende ad un valore
H∞ ≤ Hs,
in cui l’uguaglianza è valida solo per sorgenti senza memoria. Sorgente
Markoviana↓
Se oltre ad un certo valore NMax
= M la sequenza HN
non decresce più, allora la sorgente è detta a memoria finita o
di Markov di ordine M,
caratterizzata dal fatto che le probabilità condizionate dipendono solo
dagli ultimi M simboli emessi.
Esempio Analizziamo il caso di una sorgente binaria di
Markov del primo ordine, per la quale sono definite le probabilità mostrate a lato,
 ed a cui
corrisponde il diagramma di transizione mostrato. In questo
caso, l’ultimo simbolo emesso determina lo stato della
sorgente, condizionando così i valori delle probabilità di
emissione di un nuovo simbolo: con i valori dell’esempio, si
osserva come la sorgente preferisca continuare ad
emettere l’ultimo simbolo prodotto, piuttosto che l’altro.
ed a cui
corrisponde il diagramma di transizione mostrato. In questo
caso, l’ultimo simbolo emesso determina lo stato della
sorgente, condizionando così i valori delle probabilità di
emissione di un nuovo simbolo: con i valori dell’esempio, si
osserva come la sorgente preferisca continuare ad
emettere l’ultimo simbolo prodotto, piuttosto che l’altro.
p(0
⁄ 0)
= 0.9
p(1 ⁄ 0) = 0.1
p(0 ⁄ 1)
= 0.4
p(1
⁄ 1)
= 0.6
Sotto un certo punto di vista, è come se ora vi
fossero LM
diverse sorgenti (nel caso dell’esempio, 21
= 2), ognuna con delle probabilità di emissione differenti in
base allo stato Si
(o memoria) in cui si trova. Perciò, in questo caso l’entropia di
sorgente può essere calcolata applicando la (12.3↑) ad ognuno dei possibili stati, ottenendo
dei valori di entropia condizionata↓
H(x ⁄ Si), ed il valore dell’entropia di
sorgente può essere ottenuto come valore atteso dell’entropia
condizionata rispetto alle probabilità di trovarsi in ognuno degli stati
del modello Markoviano.
Tornando
all’esempio, i valori di entropia condizionata risultano pari a
H(x
⁄ 0)
= − 0.9log20.9
− 0.1log20.1 = 0.47
H(x ⁄ 1)
= − 0.4log20.4 −
0.6log20.6 = 0.97
bit/simbolo, mentre il valore della probabilità di trovarsi in uno
dei due stati si ottiene risolvendo il sistema
⎧⎨⎩
p(0)
= p(0
⁄ 0)p(0) + p(0
⁄ 1)p(1)
1 = p(0) + p(1)
in cui la prima equazione asserisce che la probabilità di trovarsi
in S0 è pari alla
somma di quella di esserci già, per quella di emettere ancora zero,
più la probabilità di aver emesso uno, ed ora emettere zero.
Sostituendo i valori, si ottiene p(0) = 0.8
e p(1) = 0.2, ossia gli stessi valori
dell’esempio binario senza memoria. Ma mentre in quel caso il valore
dell’entropia risultava pari a 0.72
bit/simbolo, ora si ottiene
H = p(0)H(x
⁄ 0) + p(1)H(x
⁄ 1) = 0.58
bit/simbolo
mostrando come la presenza di memoria aumenti la predicibilità delle
sequenze emesse dalla sorgente.
Esercizio Si ripeta il calcolo dell’entropia per un modello di
Markov del primo ordine, caratterizzato dalle probabilità p(0) = p(1) = 0.5
e p(1 ⁄
0) = p(0
⁄ 1) = 0.01, mostrando che
in questo caso si ottiene una entropia di 0.08 bit/simbolo.
11.1.1.6 Codifica per sorgenti con memoria
La
discussione appena svolta ha evidenziato come nel caso di sorgenti con
memoria i valori di entropia si riducano ulteriormente, e
conseguentemente anche la velocità di codifica, a patto di accettare un
maggior ritardo legato all’uso di codici a blocchi. A volte però la
dimensione dei blocchi da prendere in considerazione può risultare
eccessiva, producendo spropositate tabelle di codeword. Inoltre si può
ritenere di non conoscere la statistica della sorgente, e di non
desiderare effettuarne una stima, ed evitare di trasmettere la tabella
di codeword. In questi casi, può essere opportuno adottare tecniche
diverse dalle precedenti, come le due riportate appresso.
↓Prendendo
come esempio tipico il caso della trasmissione fax, in cui si ha a che
fare con un segnale di immagine in bianco e nero, scansionato per righe,
che è assimilabile ad una sorgente binaria che emetta uno zero per il
bianco, ed un uno per il nero: per la natura delle immagini scansionate,
tipicamente ci saranno lunghe sequenze di uni o di zeri, e dunque si può
assumere valido un modello di sorgente Markoviano di primo ordine, con
elevate probabilità condizionate di restare nello stesso stato.
Le lunghe sequenze di bit tutti uguali vengono
dette run (corse), e la codifica run-length consiste
effettivamente nel trasmettere una parola di codice che indica il numero
(length) di questi bit uguali. In questo caso quindi, la codeword
è di lunghezza fissa (ad esempio k + 1
binit, il primo dei quali indica se il run è tutto di uni o di zeri), e
rappresenta un numero variabile (da 0 a 2k − 1) di binit di
sorgente. Se ad esempio k = 6
binit, questi 6+1 = 7 binit possono codificare fino a 64 bit di
immagine: un bel risparmio! [446] [446] In
realtà, nel caso specifico del fax le cose non stanno esattamente in
questi termini: infatti, anziché usare una parola di lunghezza fissa
di k binit, l’ITU-T ha
definito un apposito codebook http://www.itu.int/rec/T-REC-T.4-199904-S/en
che rappresenta un codice di Huffman a lunghezza variabile, in modo
da codificare le run length più frequenti con un numero ridotto di
bit.
Questa ulteriore tecnica si basa sul fatto che
un elevato grado di dipendenza statistica dei messaggi comporta la
possibilità di predire in qualche modo i simboli a venire, in
base all’identità di quelli già emessi. La differenza tra la sequenza
predetta x̃(n) e quella effettiva x(n)
è una nuova sequenza indicata come errore di predizione e(n) = x̃(n) − x(n)
che, se il predittore ci azzecca per la maggior parte del tempo,
è quasi tutta nulla.
Nella figura seguente mostriamo l’applicazione
della tecnica al caso di sequenze binarie, per le quali l’operazione di
differenza è realizzata tramite una somma modulo due e(n) = x̃(n)⊕x(n),
in modo che nel caso di predizione corretta, l’errore sia nullo;
possiamo verificare l’effettiva invertibilità del processo di predizione
binaria confrontando lo schema mostrato con quello proposto per la
codifica differenziale al § 14.4↓.

Il predittore conserva uno stato interno
che rappresenta gli ultimi bit di ingresso, in base ai quali determina [447] [447] Il lettore più curioso si
chiederà a questo punto, come è fatto il predittore. Molto
semplicemente, scommette sul prossimo simbolo più probabile,
in base alla conoscenza di quelli osservati per ultimi, ed ai
parametri del modello markoviano: se questo simbolo possiede una
probabilità a priori > 0.5, allora la maggioranza delle
volte la predizione sarà corretta, ed il metodo inizia a consentire
una riduzione di velocità. Nel caso di sorgenti continue, troveremo
invece alcune particolarità aggiuntive. la stima x̃(n); l’errore e(n)
che è frequentemente nullo, e che viene sottoposto a codifica
run-length, è re-inserito anche nel predittore, in modo che questo possa
ri-determinare l’ultimo simbolo di ingresso x(n) = e(n)⊕x̃(n),
ed aggiornare il proprio stato interno. La medesima formula di
ricostruzione viene applicata anche in uscita del predittore di
ricezione, che condivide con quello di trasmissione la conoscenza dello
stato iniziale del segnale trasmesso, in modo da evolvere allo stesso
modo.
Notiamo come la codifica run-length non preveda
l’esistenza di un accordo a priori tra trasmettitore e ricevitore, a
parte il comune stato di partenza ad inizio messaggio, mentre la
codifica predittiva necessita solo di un accordo in merito alla
struttura del predittore. Per contro, in presenza di errori di
trasmissione i due predittori restano disallineati, finché non si inizia
a co-decodificare un nuovo messaggio. Ma lo stesso problema è comune
anche al caso di codifica a lunghezza di parola variabile, ed a quello
di Huffman dinamico.
11.1.1.7 Compressione basata su dizionario↓
Nella comune accezione del termine, un
dizionario è costituito da un array di stringhe, popolato con le
parole esistenti per un determinato linguaggio. Anziché operare
carattere per carattere, un codificatore di sorgente testuale può
ricercare la posizione nel dizionario delle parole del messaggio, e
quindi trasmettere l’indice della parola: per un dizionario di 25.000
termini bastano 15 bit di indirizzamento, ottenendo un rapporto di
compressione variabile, in funzione della lunghezza della parola
codificata.
Metodo
di Lempel-Ziv-Welsh↓
Per evitare di dover condividere la conoscenza
dell’intero dizionario tra sorgente e destinatario, che tra l’altro
potrebbe essere assolutamente sovradimensionato rispetto alle
caratteristiche dei messaggi da trattare, il metodo lzw
prevede che il codificatore generi il dizionario in modo graduale, man
mano che analizza il testo, e che il decodificatore sia in grado di
replicare questa modalità di generazione. Inoltre, il dizionario non è
vincolato a contenere le reali parole del messaggio, ma
semplicemente ospita le sequenze di caratteri effettivamente osservati,
di lunghezza due, tre, quattro...
Operando su di un alfabeto ad L
simboli, rappresentabili con n = ⌈log2L⌉ bit, il dizionario iniziale conterrà
i simboli di sorgente alle prime L
posizioni, e posti liberi
nelle restanti 2n − L −
1 posizioni [448] [448] Ad
esempio con L=96 simboli si ha n=7 bit, ed un dizionario iniziale
con 128 posizioni, di cui 96 occupate e 32 libere..
Ogni carattere letto in ingresso viene accodato in una stringa,
ed il risultato confrontato con le stringhe già presenti nel dizionario.
Nel caso non si verifichi nessuna corrispondenza, viene aggiunta una
nuova voce di dizionario, e quindi viene trasmesso il codice associato
alla sua parte iniziale, escludendo cioè il simbolo concatenato per
ultimo, e che ha prodotto l’occorrenza della nuova voce.
Nel caso invece
in cui la stringa sia già presente (e questo in particolare è vero per
la stringa di lunghezza uno corrispondente al primo simbolo analizzato)
non si emette nulla, ma si continuano a concatenare simboli fino ad
incontrare una stringa mai vista. Presso Wikipedia [449]
[449] http://en.wikipedia.org/wiki/Lempel-Ziv-Welch
è presente un esempio di risultato della codifica.
w = NIL;
while (read a
char c) do
if (wc
exists in dictionary) then
w = wc;
else
add wc to
the dictionary;
output
the code for w;
w = c;
endif
done
output the
code for w;
La parte iniziale del testo, ovviamente, ha una
alta probabilità di contenere tutte coppie di caratteri mai viste prima,
e quindi in questa fase vengono semplicemente emessi i codici associati
ai simboli osservati. Con il progredire della scansione, aumenta la
probabilità di incontrare stringhe già osservate e sempre più lunghe.
Ogni volta che viene esaurito lo spazio residuo per i nuovi simboli,
viene aggiunto un bit alla lunghezza della codeword, ovvero viene
raddoppiata la dimensione del vocabolario. Man mano che viene analizzato
nuovo materiale, aumenta la lunghezza delle stringhe memorizzate nel
dizionario, che riflette l’effettiva composizione statistica del
documento in esame, ivi compresa la presenza di memoria; allo stesso
tempo, la dimensione del dizionario (e la lunghezza delle codeword)
resta sempre la minima indispensabile per descrivere il lessico
effettivamente in uso. Alla fine del processo, il dizionario ottenuto
viene aggiunto in testa al file compresso, seguito dalle
codeword risultanti dall’algoritmo.
L’algoritmo lzw
è usato nel programma di compressione Unix compress, per la
realizzazione di immagini gif e tiff, ed incorporato in altri software,
come ad esempio Adobe Acrobat.
L’ultimo metodo di compressione senza perdite
che esaminiamo è quello che è stato introdotto dal programma pkzip,
e quindi formalizzato nella rfc 1951 [450]
[450] http://tools.ietf.org/html/rfc1951,
e tuttora ampiamente utilizzato per le sue ottime prestazioni e
l’assenza di brevetti. Usa una variante dell’algoritmo lzw,
al cui risultato applica poi una codifica di Huffman. Deflate
opera su blocchi di dati con dimensione massima 64 Kbyte, ognuno dei
quali può essere replicato intatto (come nel caso in cui i bit siano già
sufficientemente impredicibili), oppure essere compresso con un codice
di Huffman statico, oppure ancora dinamico.
Per quanto riguarda la variante di lzw,
essa consiste nel non costruire esplicitamente il dizionario, ma
nell’usare invece dei puntatori all’indietro per specificare che
una determinata sotto-stringa di ingresso, è in realtà la ripetizione di
un’altra già osservata in precedenza. In questo caso, anziché emettere
il codice (di Huffman) associato al byte corrente, si emette (il codice
di Huffman del) la lunghezza della stringa da copiare, e la distanza
(nel passato) della stessa. Quindi in pratica, anziché usare una
codeword di lunghezza fissa per indicizzare gli elementi del dizionario
come per lzw, viene usato un puntatore
di lunghezza variabile, privilegiando le copie della sottostringa
corrente più prossime nel tempo, oppure quelle con un maggior numero di
caratteri uguali.
11.1.2 Codifica con perdite di sorgente continua↓
Come verrà mostrato ai § 11.2.3↓ e 11.2.4↓, un segnale r(t)
di potenza S ricevuto mediante un
canale alla cui uscita sia presente un filtro con banda W
ed rumore n(t) gaussiano bianco di potenza N
non può convogliare un tasso di informazione R
più elevato della capacità di canale pari a C
= Wlog2⎛⎝1 + (S)/(N)⎞⎠ bit
per secondo. Nel caso discreto e senza perdite trattato finora, C
pone semplicemente un limite massimo al tasso di informazione che può
essere trasmesso. Viceversa, nel caso di una sorgente continua x(t),
abbiamo due strade possibili: intraprendere un processo di campionamento
e quantizzazione per produrre un segnale numerico con velocità R
≤ C, incorrendo così in una distorsione di
quantizzazione D tanto minore
quanto maggiore è la R consentita,
oppure effettuare una trasmissione analogica in cui
- il rumore al ricevitore può essere visto come una distorsione d(t) = n(t) = x(t) − r(t) di potenza D = N
- l’entità della distorsione D può essere ridotta aumentando (S)/(N) oppure W, e quindi C, permettendo così l’aumento del tasso di informazione R trasferito.
Nel caso continuo pertanto, sia che la sorgente
sia quantizzata o che sia trasmessa come segnale analogico, sussiste un
legame diretto tra la distorsione ed il tasso informativo, di cui
discutiamo ora.
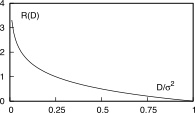
11.1.2.1 Curva velocità-distorsione↓
La valutazione della dipendenza tra D
ed R si avvale di una serie di
sviluppi teorici [451] [451] http://en.wikipedia.org/wiki/Rate-distortion_theory
che prendono come caso-tipo quello di una sorgente x(t)
gaussiana, stazionaria, ergodica e bianca, con potenza σ2x.
In tal caso si ottiene che la minima distorsione conseguibile in
corrispondenza di una velocità di trasmissione (rate) pari ad R, assume un valore pari a
Questa espressione risulta poi essere il più grande valore minimo
possibile per una potenza σ2x
assegnata, dato che per sorgenti non gaussiane, oppure gaussiane ma non
bianche, si possono ottenere valori inferiori. D’altra parte, invertendo
la (12.8↑)
si ottiene la curva R(D)G, che descrive la
minima velocità R necessaria per
trasmettere i campioni di una sorgente gaussiana con distorsione D e potenza σ2x
assegnate
R(D)G = ⎧⎨⎩
− (1)/(2)log2(D)/(σ2x)
se 0 ≤ D ≤ σ2x
0
se
D ≥ σ2x
la cui seconda riga può essere interpretata osservando che, se la
distorsione è superiore alla potenza di segnale, non occorre trasmettere
proprio nulla, dato che tanto il ricevitore può ri-generare un segnale
di errore, a partire da un rumore gaussiano di potenza D
prodotto in loco. 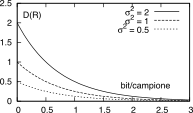
Il valore D(R)G
costituisce un limite superiore per ciò che riguarda la
 distorsione ottenibile ad una certa velocità R,
utile per rapportare le prestazioni del codificatore della nostra
sorgente con quelle migliori ottenibili per la sorgente più difficile,
ossia la gaussiana. Allo stesso tempo, è definito un limite
inferiore D(R)L (ossia, la minima
distorsione sotto cui non si può scendere per un dato R)
per sorgenti non gaussiane e senza memoria, in modo da
poter scrivere
in cui Q è la potenza
entropica (12.12↓)
e risulta Q < σ2x
per sorgenti non gaussiane.
distorsione ottenibile ad una certa velocità R,
utile per rapportare le prestazioni del codificatore della nostra
sorgente con quelle migliori ottenibili per la sorgente più difficile,
ossia la gaussiana. Allo stesso tempo, è definito un limite
inferiore D(R)L (ossia, la minima
distorsione sotto cui non si può scendere per un dato R)
per sorgenti non gaussiane e senza memoria, in modo da
poter scrivere
in cui Q è la potenza
entropica (12.12↓)
e risulta Q < σ2x
per sorgenti non gaussiane.
In definitiva, per una determinata sorgente per la
quale sono disponibili diversi codificatori, potremmo ottenere una
famiglia di curve del tipo di quelle mostrate in figura.
11.1.2.2 Entropia di sorgente continua↓
Nel caso discreto abbiamo apprezzato come
l’entropia fornisca un potente strumento per valutare il tasso
informativo intrinseco di una sorgente, supportando così la ricerca di
metodi di riduzione della ridondanza al fine di avvicinare la velocità
di trasmissione alla entropia effettiva. Ci chiediamo allora se anche
nel caso continuo possa essere definita una entropia, e come questa
possa aiutarci nello stabilire dei limiti prestazionali. Estendendo
formalmente al caso continuo la definizione trovata per le sorgenti
discrete, si ottiene l’espressione
che è indicata con la h minuscola
per distinguerla dal caso discreto, e che viene detta entropia
differenziale↓
o relativa perché il suo valore può risultare positivo, negativo
o nullo, in funzione della dinamica della variabile aleatoria X.
Esempio Se
calcoliamo il valore di entropia differenziale per un processo i cui
valori sono descritti da una variabile aleatoria a distribuzione
uniforme px(x) = (1)/(A)rectA(x),
otteniamo il risultato h(X) = − (1)/(A)∫(A)/(2) − (A)/(2)log2⎛⎝(1)/(A)⎞⎠dx =
log2A il cui valore effettivo, appunto,
dipende dal valore di A.
Sebbene inadatta ad esprimere il contenuto
informativo assoluto [452] [452] In effetti esiste una misura di entropia assoluta
per sorgenti continue, che però ha la sgradevole caratteristica di
risultare sempre infinita. Infatti, approssimando la (12.10↑) come limite a cui tende una
sommatoria, e suddividendo l’escursione dei valori di x
in intervalli uguali Δx,
possiamo scrivere
habs(x)
= limΔx →
0 ⎲⎳ip(xi)Δxlog2(1)/(p(xi)Δx)
= limΔx → 0 ⎲⎳i⎡⎣p(xi)Δxlog2(1)/(p(xi))
+ p(xi)Δxlog2(1)/(Δx)⎤⎦
= h(x)
+ h0
in cui h(x) è proprio la (12.10↑) mentre h0
= − limΔx
→ 0log2Δx∫∞
− ∞p(x)dx = − limΔx → 0log2Δx
= ∞. D’altra parte, la differenza tra le entropie assolute
di due sorgenti z e x
risulta pari a habs(z) −
habs(x) = h(z) − h(x) + h0(z) − h0(x), in cui la seconda differenza
tende a − log2(Δz)/(Δx) che, se z
ed x hanno la medesima
dinamica, risulta pari a zero. di una sorgente
continua, l’entropia differenziale può comunque essere utile per
confrontare tra loro due sorgenti con uguale varianza σ2x;
in particolare, il massimo valore di h(X)
per σ2x assegnata è ottenuto
in corrispondenza di un processo gaussiano [453]
[453] Questo risultato si ottiene massimizzando la (12.10↑) rispetto a p(x)
mediante il metodo dei moltiplicatori di Lagrange
http://it.wikipedia.org/wiki/Metodo_dei_moltiplicatori_di_Lagrange,
in modo da tener conto dei vincoli espressi dalle condizioni ∫px(x)dx
= 1 e ∫x2px(x)dx
= σ2x. Notiamo
esplicitamente la differenza rispetto al caso continuo, in cui la
d.d.p. che rende massima l’entropia, è invece quella uniforme.,
e risulta pari a
ed è per questo motivo che, a parità di velocità R
e di potenza σ2x,
il processo gaussiano incorre nella massima distorsione minima (12.8↑).
Associata alla definizione di entropia differenziale, sussiste quella di
potenza entropica↓
Q, scritta come
che per sorgenti gaussiane fornisce QG
= σ2x,
mentre per altri tipi di statistiche, si ottiene un valore minore.
Applicando questa definizione alla (12.9↑) osserviamo come il limite inferiore di
distorsione D(R)L si riduce al
diminuire di h(X). 11.1.2.3 Sorgente continua con memoria↓
Come per il caso di sorgenti discrete, anche per
quelle continue l’esistenza di una dipendenza statistica tra i valori
prodotti riduce la quantità di informazione emessa, al punto che a
parità di distorsione, questa può essere codificata a velocità ridotta;
oppure, a parità di velocità, può essere conseguita una distorsione
inferiore. Anche stavolta, la sorgente più difficile (ossia a
cui compete la massima distorsione minima) è quella gaussiana,
per la quale risulta che la minima distorsione per σ2x
assegnata può esprimersi come
in cui 0 ≤ γ2x ≤ 1 rappresenta una
misura di piattezza spettrale [454] [454] Si può
mostrare che γ2x
può essere interpretato come il rapporto tra la media aritmetica e
la media geometrica della densità spettrale di potenza Px(f) del processo x(t):
indicando con Sk = Px(fk), k
= 1, 2, ⋯, N, i campioni equispaziati della densità
spettrale valutati a frequenze positive fk
tra zero e la massima frequenza del processo, si ha
γ2x = limN
→ ∞((N∏k = 1Sk)1⁄N)/((1)/(N)N⎲⎳k = 1Sk)
Nel caso di un processo bianco, per il quale i valori Sk
sono tutti uguali, le due medie coincidono, e γ2x
= 1. Altrimenti, γ2x
risulta tanto più piccolo quanto più i valori Sk
si discostano dal loro valore medio., che vale uno nel
caso senza memoria, ovvero di processo bianco, e si riduce nel
caso di un segnale i cui valori sono correlati tra loro, ed a cui
corrisponde una densità spettrale colorata. Nel caso non gaussiano, infine, la (12.13↑) si riscrive sostituendo al posto di σ2x la potenza entropica
Q espressa dalla (12.12↑), ottenendo valori D(R)
ancora inferiori.
L’applicazione dei principi relativi alla codifica
di sorgente al caso specifico dei messaggi multimediali (audio e video)
viene trattata al capitolo 12↓.
Prec Capitolo 11: Teoria
dell’informazione e codifica Su Capitolo 11: Teoria dell’informazione
e codifica Sezione 11.2: Codifica di
canale Segue
 Nato più di 20 anni fa, un progetto di
Nato più di 20 anni fa, un progetto di