Prec Sezione 17.4: Sistemi di
servizio orientati al ritardo Su Capitolo 17: Sistema di servizio,
teoria del trafficoe delle reti Capitolo
18: Reti a pacchetto Segue
17.5 Reti per trasmissione dati↓
In questa sezione illustriamo le particolarità
legate alle trasmissioni dati, e come queste possano essere
vantaggiosamente sfruttate per conseguire la maggiore efficienza
che i sistemi di servizio a coda presentano rispetto a quelli orientati
alla perdita. Le particolari modalità e funzioni legate
alle trasmissioni dati saranno classificate secondo uno schema che ne
consente il confronto in termini di prestazioni e vincoli sulla
realizzazione della rete. Infine, verranno formalizzate le esigenze
legate alla soluzione dei problemi di trasmissione dati, introducendo i
concetti legati alle architetture protocollari, assieme ad
alcuni esempi reali.
Le trasmissioni dati si prestano bene a
comunicazioni in cui siano possibili ritardi temporali variabili,
attuando una filosofia di tipo ad immagazzinamento e rilancio (store and forward) basata sul suddividere
il messaggio in unità informative elementari denominate pacchetti,
che possono essere inoltrati sulla rete di comunicazione, assieme a
quelli prodotti da altre trasmissioni. L’applicazione della stessa
metodologia a trasmissioni (ad esempio) vocali non è per nulla semplice,
in quanto la presenza di un ritardo variabile per la trasmissione dei
pacchetti comporta problemi non trascurabili, a meno di attuare speciali
meccanismi di priorità e prenotazione della banda, tuttora oggetto di
ricerca.
17.5.1 Il pacchetto dati↓
Discutiamo
brevemente, in termini generali, i possibili contenuti di un pacchetto
dati; il suo formato effettivo dipenderà dal particolare protocollo di
trasmissione adottato.
La prima osservazione da fare è che la
suddivisione del messaggio in pacchetti comporta un aumento delle
informazioni da trasmettere, in quanto ognuno di questi dovrà contenere
informazioni addizionali per consentire un suo corretto recapito e la
sua ricombinazione con gli altri pacchetti dello stesso messaggio.
Occorre inoltre affrontare gli ulteriori problemi tipici di una
comunicazione dati, ovvero come contrastare gli errori di trasmissione,
e come gestire le risorse di rete.
In termini generali, un pacchetto è composto da una intestazione
(header), dalla parte di messaggio che
 trasporta (dati), e da un campo codice di parità (crc)
necessario a rivelare l’occorrenza di errori di trasmissione [870]
[870] La sigla CRC significa Cyclic Redundancy Check
(controllo ciclico di ridondanza) ed indica una parola binaria i cui
bit sono calcolati in base ad operazioni algebriche (vedi § 8.4.3.3↑) attuate sui bit di cui il resto
del messaggio è composto. Dal lato ricevente sono eseguite le stesse
operazioni, ed il risultato confrontato con quello presente nel CRC,
in modo da controllare la presenza di errori di trasmissione. .
L’header a sua volta può essere suddiviso in campi, in cui
trovano posto (tra le altre cose) gli indirizzi del destinatario
e della sorgente, un codice di controllo che causa in chi lo
riceve l’esecuzione di una procedura specifica, un numero di
sequenza che identifica il pacchetto all’interno del messaggio
originale, ed un campo che indica la lunghezza del pacchetto.
Nonostante la presenza delle informazioni aggiuntive [871]
[871] L’entità delle informazioni aggiuntive rispetto a
quelle del messaggio può variare molto per i diversi protocolli, da
pochi bit a pacchetto fino ad un 10-20% dell’intero pacchetto (per
lunghezze ridotte di quest’ultimo)., la trasmissione a
pacchetto consegue una efficienza maggiore di quella a circuito, in
quanto è attuata mediante sistemi a coda.
trasporta (dati), e da un campo codice di parità (crc)
necessario a rivelare l’occorrenza di errori di trasmissione [870]
[870] La sigla CRC significa Cyclic Redundancy Check
(controllo ciclico di ridondanza) ed indica una parola binaria i cui
bit sono calcolati in base ad operazioni algebriche (vedi § 8.4.3.3↑) attuate sui bit di cui il resto
del messaggio è composto. Dal lato ricevente sono eseguite le stesse
operazioni, ed il risultato confrontato con quello presente nel CRC,
in modo da controllare la presenza di errori di trasmissione. .
L’header a sua volta può essere suddiviso in campi, in cui
trovano posto (tra le altre cose) gli indirizzi del destinatario
e della sorgente, un codice di controllo che causa in chi lo
riceve l’esecuzione di una procedura specifica, un numero di
sequenza che identifica il pacchetto all’interno del messaggio
originale, ed un campo che indica la lunghezza del pacchetto.
Nonostante la presenza delle informazioni aggiuntive [871]
[871] L’entità delle informazioni aggiuntive rispetto a
quelle del messaggio può variare molto per i diversi protocolli, da
pochi bit a pacchetto fino ad un 10-20% dell’intero pacchetto (per
lunghezze ridotte di quest’ultimo)., la trasmissione a
pacchetto consegue una efficienza maggiore di quella a circuito, in
quanto è attuata mediante sistemi a coda.
Può sembrare vantaggioso mantenere la dimensione
dei pacchetti elevata, riducendo così la rilevanza delle informazioni
aggiuntive, ma si verificano controindicazioni. Infatti, suddividere
messaggi lunghi in pacchetti più piccoli garantisce l’inoltro di (altre)
comunicazioni più brevi
durante la trasmissione di messaggi lunghi, che altrimenti bloccherebbero
i sistemi di coda se realizzate con un unico “pacchettone”: in figura è
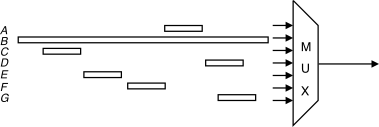 mostrato un esempio in cui B,
presentandosi in ingresso al multiplexer con lieve anticipo rispetto
agli altri pacchetti più piccoli, ne impedisce l’inoltro, monopolizzando
la linea di uscita per tutta la durata della sua trasmissione.
mostrato un esempio in cui B,
presentandosi in ingresso al multiplexer con lieve anticipo rispetto
agli altri pacchetti più piccoli, ne impedisce l’inoltro, monopolizzando
la linea di uscita per tutta la durata della sua trasmissione.
Infine, all’aumentare della lunghezza di un
pacchetto aumenta proporzionalmente la probabilità di uno (o più) bit
errati (vedi anche la formula (10.76↑) a pag. 1↑ e la discussione al § 8.5.2.3↑), e dunque l’uso di dimensioni
contenute riduce le necessità di ritrasmissione.
17.5.2 Modo di trasferimento delle informazioni
È definito in base alla specificazione di 3
caratteristiche che lo contraddistinguono: lo schema di
multiplazione, il principio di commutazione e l’architettura
protocollare.
17.5.2.1 Schema di multiplazione↓
Al § 19.3.1↓
è descritto uno schema a divisione di tempo che prevede l’uso di una trama
in cui trovano posto diverse comunicazioni vocali [872]
[872] Come nel PCM telefonico, vedi § 19.3.1↓, e che necessita di
un funzionamento sincronizzato (o quasi) dei nodi di rete. La
trasmissione a pacchetto invece non prevede l’uso esclusivo di
risorse da parte delle singole comunicazioni, e non fa uso di
una struttura di trama e pertanto occorrono soluzioni particolari per
permettere la delimitazione dei pacchetti.
Ad esempio, i protocolli hdlc ed x.25 [873] [873] A
riguardo di questi due protocolli ormai fuori moda, si veda ad es.
https://it.wikipedia.org/wiki/High-Level_Data_Link_Control e https://it.wikipedia.org/wiki/X.25
 presentano pacchetti di dimensione variabile, e fanno uso di un byte di
flag (vedi pag. 1↑)
costituito dalla sequenza 01111110 in
testa ed in coda, per separare tra loro i pacchetti di comunicazioni
differenti. Per evitare che i dati “propri” del pacchetto possano
simulare un flag, in trasmissione viene inserito un bit 0 dopo 5
uni di fila, che (se presente) viene rimosso al ricevitore. Se dopo 5
uni c’è ancora un 1 (e poi uno zero), allora è un flag.
presentano pacchetti di dimensione variabile, e fanno uso di un byte di
flag (vedi pag. 1↑)
costituito dalla sequenza 01111110 in
testa ed in coda, per separare tra loro i pacchetti di comunicazioni
differenti. Per evitare che i dati “propri” del pacchetto possano
simulare un flag, in trasmissione viene inserito un bit 0 dopo 5
uni di fila, che (se presente) viene rimosso al ricevitore. Se dopo 5
uni c’è ancora un 1 (e poi uno zero), allora è un flag.
https://it.wikipedia.org/wiki/High-Level_Data_Link_Control e https://it.wikipedia.org/wiki/X.25
Nel caso in cui il pacchetto invece abbia una dimensione
fissa [874] [874] Un
modo di trasferimento con pacchetti di dimensione fissa è l’ATM (Asynchronous
Transfer Mode) che viene descritto al § 18.2↓., ci si trova ad
 operare in una situazione simile a quella in presenza di trama, tranne
che... la trama non c’è, e dunque l’ordine dei pacchetti è qualsiasi, ma
viene meno l’esigenza dei flag di delimitazione.
operare in una situazione simile a quella in presenza di trama, tranne
che... la trama non c’è, e dunque l’ordine dei pacchetti è qualsiasi, ma
viene meno l’esigenza dei flag di delimitazione.
In entrambi i casi (lunghezza di pacchetto fissa o variabile) i nodi
della rete non necessitano di operare in sincronismo tra loro; lo schema
 di multiplazione è quindi detto a divisione di tempo↓
senza organizzazione di trama, asincrono, con etichetta. Il
termine etichetta (o label) indica che ogni pacchetto deve
recare con sé le informazioni idonee a ricombinarlo assieme agli altri
dello stesso messaggio.
di multiplazione è quindi detto a divisione di tempo↓
senza organizzazione di trama, asincrono, con etichetta. Il
termine etichetta (o label) indica che ogni pacchetto deve
recare con sé le informazioni idonee a ricombinarlo assieme agli altri
dello stesso messaggio.
17.5.2.2 Principio di commutazione↓
È definito in base a come sono realizzate le due funzioni di instradamento,
ovvero come individuare un percorso nella rete, e di attraversamento,
ossia come permettere l’inoltro del messaggio tra le porte di ingresso e
di uscita del commutatore.
Se l’instradamento↓ (routing)↓
viene determinato una volta per tutte all’inizio del collegamento, il
modo di trasferimento viene detto con connessione. Se al
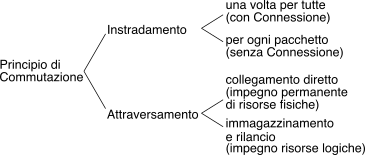 contrario l’instradamento avviene in modo indipendente per ogni
pacchetto, il collegamento è detto senza connessione ed ogni
pacchetto di uno stesso messaggio può seguire percorsi differenti.
contrario l’instradamento avviene in modo indipendente per ogni
pacchetto, il collegamento è detto senza connessione ed ogni
pacchetto di uno stesso messaggio può seguire percorsi differenti.
L’attraversamento di un nodo di rete
consiste invece nel demultiplare le informazioni in ingresso e
multiplarle di nuovo su uscite diverse: ciò può avvenire mediante un collegamento
diretto o per immagazzinamento e rilancio.
Sulla base di queste considerazioni, definiamo:
l’instradamento avviene una volta per tutte
prima della comunicazione, e l’attraversamento impegna in modo
permanente ed esclusivo le risorse fisiche dei
nodi della rete; è il caso della telefonia, sia pots
che pcm [875]
[875] Nel caso del pots
(vedi § 19.9.1↓)
si creava un vero e proprio circuito elettrico (vedi anche pag. 1↓), e le risorse fisiche impegnate sono
gli organi di centrale ed i collegamenti tra centrali, assegnati per
tutta la durata della comunicazione in esclusiva alle due parti in
colloquio. Nel caso del pcm (vedi
§ 19.3.1↓),
le risorse allocate cambiano natura (ad esempio consistono anche
nell’intervallo temporale assegnato al canale all’interno della
trama) ma ciononostante vi si continua a far riferimento come ad una
rete a commutazione di circuito..
L’instradamento è determinato una volta per tutte prima
dell’inizio della trasmissione, durante una fase di setup delle
risorse della rete ad essa necessarie, e conseguente ad una richiesta
di connessione da parte del nodo sorgente. I pacchetti di uno
stesso messaggio seguono quindi tutti uno stesso percorso, e
l’attraversamento si basa sull’impegno di risorse logiche [876]
[876] Le risorse impegnate sono dette logiche in
quanto corrispondono ad entità concettuali (i canali virtuali
descritti nel seguito). ed avviene per immagazzinamento
e rilancio. La trasmissione ha luogo dopo aver contrassegnato ogni
pacchetto con un identificativo di connessione (ic)
che individua un canale virtuale↓ [877]
[877] Il termine Canale Virtuale simboleggia il
fatto che, nonostante i pacchetti di più comunicazioni viaggino
“rimescolati” su di uno stesso mezzo, questi possono essere
distinti in base alla comunicazione a cui appartengono, grazie ai
differenti IC (numeri) con
cui sono etichettati; pertanto, è come se i pacchetti di una
stessa comunicazione seguissero un proprio canale virtuale
indipendente dagli altri.tra coppie di nodi di
rete, e che ne identifica l’appartenenza ad uno dei collegamenti in
transito.
L’intestazione del pacchetto può essere ridotta, al limite, a contenere
il solo ic del canale virtuale.
L’attraversamento avviene consultando apposite tabelle (di routing),
generate nella fase di setup che precede quella di trasmissione, in cui
è indicata la porta di uscita per tutti i pacchetti appartenenti ad uno
stesso messaggio. Facciamo un esempio, riferendoci allo schema di fig. 17.21↓:
una sorgente, a seguito della fase di instradamento, invia i pacchetti
con identificativo ic = 1 al primo
nodo individuato dal routing. Consultando la propria tabella, il nodo
trova che il canale virtuale 1 sulla porta di ingresso (p.i.) A
si connette al c.v. 3 sulla porta di uscita (p.u.)
C. Ora i pacchetti escono da C con ic
= 3 ed una volta giunti al nodo seguente sulla p.i.
A, escono dalla p.u.
B con ic
= 2 e giungono finalmente a destinazione. Notiamo che su di un
collegamento tra due nodi, i numeri dei canali virtuali
identificano in modo univoco il collegamento a cui appartengono i
pacchetti, mentre uno stesso numero di canale virtuale può essere
riutilizzato su porte differenti [878] [878] I
numeri di c.v. sono negoziati tra ciascuna coppia di nodi durante la
fase di instradamento, e scelti tra quelli non utilizzati da altre
comunicazioni già in corso. Alcuni numeri di c.v. inoltre possono
essere riservati, ed utilizzati per propagare messaggi di
segnalazione inerenti il controllo di rete..

La concatenazione dei canali virtuali attraversati
viene infine indicata con il termine Circuito Virtuale per
similitudine con il caso di commutazione di circuito, con la differenza
che ora il percorso individuato è definito solo in termini di tabelle e
di etichette, e non di risorse fisiche (tranne che per la memoria della
tabella).
Al termine della comunicazione, sul circuito
virtuale viene inviato un apposito pacchetto di controllo, che provoca
la rimozione del routing dalle tabelle.
Durante la fase di instradamento, il percorso
nella rete è determinato in base alle condizioni di traffico del
momento, ed eventualmente la connessione può essere rifiutata nel caso
in cui la memoria di coda nei nodi coinvolti sia quasi esaurita, evento
indicato con il termine di congestione.
D’altra parte, se alcune sorgenti origine dei
Canali Virtuali già assegnati e che si incrociano in uno stesso nodo
intermedio, iniziano ad emettere pacchetti a frequenza più elevata del
previsto, il nodo intermedio si congestiona (ossia esaurisce la memoria
di transito) ed inizia a perdere pacchetti, penalizzando tutti i
Canali Virtuali che attraversano il nodo.
Per questo motivo, sono indispensabili strategie
di controllo di flusso che permettano ai nodi di regolare
l’emissione delle sorgenti. Il controllo di flusso è attuato anch’esso
mediante pacchetti (di controllo), privi del campo di dati, ma
contenenti un codice identificativo del comando che rappresentano. Ad
esempio, un nodo non invia nuovi pacchetti di un circuito virtuale
finché non riceve un pacchetto di riscontro relativo ai
pacchetti precedenti. D’altra parte, nel caso di una rete congestionata,
la perdita di pacchetti causa il mancato invio dei riscontri relativi, e
dunque i nodi a monte cessano l’invio di nuovi pacchetti [879]
[879] In realtà vengono prima fatti dei tentativi di
inviare nuovamente i pacchetti “vecchi”. Questi ultimi infatti sono
conservati da chi li invia (che può anche essere un nodo
intermedio), finché non sono riscontrati dal ricevente. Quest’ultimo
fatto può causare ulteriore congestione, in quanto restano impegnate
risorse di memoria “a monte” della congestione che così si
propaga.. Dopo un certo periodo di tempo (timeout) il collegamento è giudicato
interrotto e viene generato un pacchetto di Reset da inviare sul
canale virtuale, e che causa, nei nodi attraversati, il rilascio delle
risorse logiche (tabelle) relative al Canale Virtuale.
Discutiamo ora invece di un ulteriore possibile
principio di commutazione:
Anche in questo caso, l’attraversamento
dei nodi avviene per immagazzinamento e rilancio↓,
mentre la funzione di instradamento↓ è
svolta in modo distribuito tra i nodi di rete per ogni pacchetto,
il quale (chiamato ora datagramma) deve necessariamente
contenere l’indirizzo completo della destinazione. Infatti, in questo
caso manca del tutto la fase iniziale del collegamento, in cui prenotare
l’impegno delle risorse (fisiche o logiche) che saranno utilizzate [880] [880] Per questo motivo, il
collegamento è detto senza connessione..
Semplicemente, non è previsto alcun impegno a priori, ed ogni pacchetto
costituisce un collegamento individuale che impegna i nodi di rete solo
per la durata del proprio passaggio. L’instradamento avviene mediante
tabelle presenti nei nodi, di tipo sia statico che dinamico (nel qual
caso tengono conto delle condizioni di carico e di coda dei nodi
limitrofi) che indicano le possibili porte di uscita per raggiungere la
destinazione scritta sul pacchetto. Quest’ultimo quindi viene fatto
uscire senza nessuna alterazione dalla porta di uscita.
Uno dei maggiori vantaggi dei datagrammi rispetto
ai circuiti virtuali è una migliore resistenza ai guasti e
malfunzionamenti: in questo caso infatti, a parte una eventuale
necessità di ritrasmettere i pacchetti persi, il collegamento prosegue
attraverso percorsi alternativi; inoltre l’elevato numero di percorsi
alternativi, può permettere (in condizioni di carico leggero) di
soddisfare brevi richieste di trasmissione a velocità elevate. Allo
stesso tempo, in presenza di messaggi molto brevi, l’invio di un singolo
datagramma è più che sufficiente, mentre nel caso a circuito virtuale le
fasi di instaurazione ed abbattimento sarebbero state un lavoro in più
da svolgere (tanto che ad es. l’X.25, che è nato a c.v., prevede anche
il funzionamento a datagramma).
Consegna ordinata e congestione↓
Uno dei maggiori problemi legati all’uso di
datagrammi è che l’ordine di arrivo dei pacchetti può essere diverso da
quello di partenza, potendo questi seguire percorsi differenti. Per
questo motivo, nei datagrammi è presente un numero di sequenza
che si incrementa ad ogni pacchetto trasmesso, ed alla destinazione sono
predisposti dei buffer↓ [881] [881] Il
termine buffer ha traduzione letterale “respingente,
paracolpi, cuscinetto” ed è a volte espresso in italiano dalla
locuzione memoria tampone. di memoria
nei quali ricostruire l’ordine esatto dei pacchetti.
Nel caso di un pacchetto mancante, il ricevente
non sa se questo è semplicemente ritardato oppure è andato perso,
rendendo problematico il controllo di flusso. In questo caso si produce
un impegno anomalo dei buffer di ingresso, che non possono essere
rilasciati perché incompleti, e ciò può causare il rifiuto
dell’accettazione di nuovi pacchetti, provocando un impegno anomalo
anche per i buffer di uscita di altri nodi, causando congestione [882]
[882] La soluzione a questa “spirale negativa” si basa
ancora sull’uso di un allarme a tempo (timeout), scaduto il quale si
giudica interrotto il collegamento, e sono liberati i buffer..
Prima di effettuare un trasferimento a datagramma,
è opportuno (a parte il caso di messaggi composti da un singolo
datagramma) verificare la disponibilità del destinatario finale, e
preavvisarlo di riservare una adeguata quantità di memoria. Ad esempio,
in Internet avviene proprio questo (vedi pag. 1↓).
Proseguiamo la descrizione delle reti per dati con
l’ultima caratteristica di un modo di trasferimento:
17.5.2.3 Architettura protocollare↓
Definisce la stratificazione delle funzioni di
comunicazione, sia per gli apparati terminali che per i nodi di
transito, e di come queste interagiscono reciprocamente sia tra nodi
diversi, che nell’ambito di uno stesso nodo. Alcune di queste sono già
state introdotte, e le citiamo per prime, seguite da quelle più
rilevanti illustrate di seguito:
- il controllo di flusso, che impedisce la saturazione dei buffer;
- la consegna ordinata, per riassemblare messaggi frammentati su più datagrammi;
- la segmentazione e riassemblaggio, che definisce le regole per frammentare un messaggio in pacchetti e ricomporli, ad esempio in corrispondenza dei “confini” tra sottoreti con differente lunghezza di pacchetto;
- il controllo di connessione, che provvede ad instaurare la connessione, eseguire l’instradamento, impegnare le risorse, supervisionare il controllo di flusso, abbattere la connessione al suo termine;
- il controllo di errore, che provvede a riscontrare le unità informative, a rilevare gli errori di trasmissione, a gestire le richieste di trasmissione;
- l’incapsulamento, che aggiunge ai pacchetti di dati da trasmettere le informazioni di protocollo come l’header, gli indirizzi, il controllo di parità...
Stratificazione
ISO-OSI↓
Per
aiutare nella schematizzazione delle interazioni tra le funzioni
illustrate, l’International Standard Organization (iso)
ha formalizzato un modello concettuale per sistemi di comunicazione
denominato Open System Interconnection (osi) [883] [883] In virtù dell’intreccio di
sigle, il modello di riferimento prende il nome (palindromo) di
modello ISO-OSI., che individua una relazione
gerarchica tra i protocolli. In particolare sono definiti sette strati
o livelli (layers) ognuno dei
quali raggruppa un insieme di funzioni affini. Gli strati più elevati
(4-7) sono indicati anche come strati di utente, in quanto
legati a funzioni relative ai soli apparati terminali; gli strati di
transito invece (1-3) riguardano funzioni che devono essere
presenti anche nei nodi intermedi.

Per terminare l’esempio, facciamo notare come in
ogni livello avvengano due tipi di colloqui (regolati da
altrettanti protocolli): uno è orizzontale, detto anche tra
pari (peer-to-peer), come è ad
esempio il contenuto del documento che spediamo, od i rapporti tra
corrispondenti locali (che nel caso di un sistema di comunicazione
corrisponde allo strato di collegamento, relativo ai protocolli tra
singole coppie di nodi di rete); il secondo tipo di colloquio avviene
invece in forma verticale, o tra utente e servizio, in
quanto per realizzare le funzioni di uno strato utente ci si
affida ad un servizio di comunicazione offerto dallo strato
inferiore (che a sua volta può avvalersi dei servizi degli altri strati
ancora inferiori) [884] [884] Il
modo di trasferimento è completamente definito dopo che sia stato
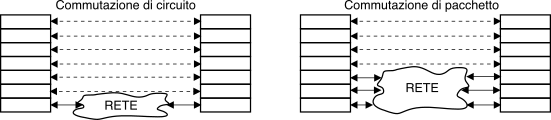
specificato in quale strato siano svolte le funzioni di commutazione
e multiplazione. In una rete a commutazione di circuito, queste sono
realizzate dallo strato fisico che, esaurita la fase di
instradamento ed impegno di risorse fisiche, collega in modo
trasparente sorgente e destinazione. Nella commutazione di
pacchetto, invece, le funzioni di multiplazione e commutazione
coinvolgono (per tutti i pacchetti del messaggio) tutti i nodi di
rete interessati; si dice pertanto che i protocolli di collegamento
e di rete devono essere terminati (nel senso di gestiti) da
tutti i nodi di rete.
 .
.
La modalità con cui un protocollo tra pari di
strato N affida i suoi dati ad un
servizio di strato N − 1, si
avvale (nella commutazione di pacchetto) della funzione di incapsulamento,
di cui viene data una interpretazione grafica alla figura seguente.
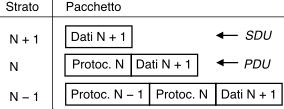
Quando uno strato affida il collegamento con un
suo pari allo strato inferiore, quest’ultimo può mascherare al superiore
la modalità con cui viene realizzato il trasferimento.
In particolare, se ci riferiamo all’interfaccia
tra gli strati di trasporto e di rete, lo strato di rete può realizzare
con il suo pari collegamenti con o senza connessione, mentre quello di
trasporto offre allo stesso tempo (ma in modo indipendente) agli strati
superiori un servizio con o senza connessione, dando luogo alle seguenti
4 possibilità:
| |
Servizio di trasporto | |
| Servizio di rete | Circuito Virtuale | Datagramma |
| Circuito Virtuale | SNA, X.25 | Insolito |
| Datagramma | Arpanet, TCP/IP | Decnet |
SNA (system network architecture) è una architettura proprietaria IBM, in cui il trasferimento avviene in modo ordinato, richiedendo al livello di trasporto un circuito virtuale, che è realizzato da una serie di canali virtuali tra i nodi di rete. La stessa architettura è adottata anche dall’X.25, che costituisce l’insieme di protocolli che descrivono il funzionamento di reti pubbliche a commutazione di pacchetto, presenti in tutto il mondo: quella italiana prende il nome di itapac.
Arpanet
è l’architettura di Internet, in cui sebbene lo strato di rete operi con
un principio di commutazione a datagramma, mediante il protocollo IP
(internet protocol), lo strato di
trasporto (TCP, transfer control
program) offre a quelli superiori un servizio con connessione,
attuato mediante circuiti virtuali, in modo da garantire il corretto
sequenziamento delle unità informative, ed offrire canali di
comunicazione formalmente simili ai files presenti localmente su disco.
Il mascheramento del servizio di rete interna a datagramma in un
servizio con connessione avviene a carico dello strato TCP di
trasporto presente nei nodi terminali, che appunto affronta il
riassemblaggio ordinato dei datagrammi ricevuti dallo strato di rete.
Decnet
è (o meglio era) l’architettura Digital, in cui il controllo di errore,
la sequenzializzazione, ed il controllo di flusso sono realizzati dal
livello di trasporto.
Soluzione insolita
non è praticata perché equivale a fornire alla rete pacchetti
disordinati, farli consegnare nello stesso identico disordine a
destinazione, dove poi sono riassemblati. Può avere un senso se la
comunicazione è sporadica, ma sempre per la stessa destinazione, nel
qual caso somiglia ad un circuito virtuale permanente.
Prec Sezione 17.4: Sistemi di
servizio orientati al ritardo Su Capitolo 17: Sistema di servizio,
teoria del trafficoe delle reti Capitolo
18: Reti a pacchetto Segue
 Nato più di 20 anni fa, un progetto di
Nato più di 20 anni fa, un progetto di