17.2 Capacità di canale discreto
Le relazioni fin qui discusse permettono di valutare la perdita di informazione causata dai disturbi, ma dipendono sia dalle probabilità
in avanti p(yj ⁄ xi) che descrivono il comportamento del canale, sia da quelle
a priori p(xi), che invece attengono alle caratteristiche della sorgente. Vogliamo invece definire una grandezza che esprima esclusivamente l’attitudine (o
capacità) del canale a trasportare informazione, indipendentemente dalle caratteristiche della sorgente. Questo risultato può essere ottenuto variando le prob. a priori in tutti i modi possibili, fino a trovare il valore
che definisce la
capacità di canale per simbolo come
il massimo valore
dell’informazione mutua media, ottenuto in corrispondenza della migliore sorgente possibile. Il pedice
s sta per
simbolo, e serve a distinguere il valore ora definito da quello che esprime la massima
intensità di trasferimento dell’informazione espressa in bit/secondo, ottenibile una volta nota la frequenza
fs con cui sono trasmessi i simboli, fornendo per la capacità di canale il nuovo valore
L’importanza di questa quantità risiede nel
teorema fondamentale per canali rumorosi già anticipato più volte, che asserisce che per ogni canale discreto senza memoria di capacità
C
- esiste una tecnica di codifica che consente la trasmissione di informazione a velocità R e con probabilità di errore per simbolo pe piccola a piacere, purché risulti R < C;
- se è accettabile una probabilità di errore pe, si può raggiungere (con la miglior codifica possibile) una velocità R(pe) = C1 − Hb(pe) > C in cui Hb(pe) è l’entropia di una sorgente binaria (10.221);
- per qualsiasi valore di pe, non è possibile trasmettere informazione a velocità maggiore di R(pe).
Il teorema non suggerisce come individuare la tecnica di codifica, né fa distinzioni tra codifica di sorgente e di canale, ma indica le prestazioni limite ottenibili mediante la migliore tecnica possibile, in grado di ridurre a piacere la pe purché R < C, mettendoci al tempo stesso in guardia a non tentare operazioni impossibili. Da questo punto di vista, le prestazioni conseguibili adottando le tecniche di codifica note possono essere valutate confrontandole con quelle ideali predette dal teorema. Inoltre, dato che la capacità di canale è definita come massimo valore di I(X, Y) per la migliore p(x), qualora la statistica dei messaggi prodotti dal codificatore di sorgente differisca da quella ottima per il canale, l’effettiva informazione mutua media risulterà ridotta rispetto al valore della capacità, così come la massima velocità R.
Illustriamo l’applicazione di questi risultati con un paio di esempi.
17.2.1 Capacità di un canale L − ario non rumoroso
Consideriamo il caso mostrato in figura,
ovvero un canale che trasporta
senza errori simboli con
L = 2M livelli: in tal caso l’equivocazione
H(Y ⁄ X) è nulla, e la
(21.89) permette di scrivere
I(X, Y) = H(X), che è massima se
P(xi) = 1⁄L per tutti gli
i, risultando così
Cs = Hmax(X) = log2L = M bit/simbolo, e
C = fs ⋅ Cs = fs ⋅ M bit/secondo.
I simboli ad
L livelli sono ottenuti raggruppando
M dei bit prodotti da una codifica binaria a velocità
fb, risultando
fb ≥ R = Hx (vedi eq.
(10.224)) in funzione della ottimalità o meno del codificatore; pertanto, risulta
R ≤ fb = fs ⋅ M = C con l’uguaglianza valida nel caso in cui il codificatore riesca a rimuovere tutta la ridondanza dei messaggi della sorgente, conseguendo in tal caso il massimo trasferimento di informazione.
Al contrario, volendo realizzare una velocità
R > C, il codificatore di sorgente dovrebbe produrre codeword con lunghezze tali da violare la disuguaglianza di Kraft
(10.228), e quindi la regola del prefisso non sarebbe rispettata, causando in definitiva errori di decodifica anche in assenza di rumore!
17.2.2 Capacità del canale binario simmetrico
Esaminiamo l’effetto della presenza di rumore per questo caso particolare, per il quale a pag.
1 abbiamo valutato l’espressione dell’informazione mutua media, data dalla
(21.93), e pari a
I(X, Y) = Hb(pe + α − 2αpe) − Hb(pe)
in cui Hb(pe) dipende solo dalla probabilità di errore, mentre il termine Hb(pe + α − 2αpe) dipende anche dalla statistica di sorgente, e risulta massimizzato e pari ad 1 se pe + α − 2αpe = 12, come avviene per qualunque pe se α = 12, ossia per simboli equiprobabili. Pertanto la capacità del bsc risulta pari a
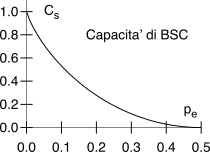
Cs = Hb(1⁄2) − Hb(pe) = 1 − Hb(pe)
il cui grafico è rappresentato alla figura a lato, evidenziando che Cs ≃ 1 bit/simbolo se pe ≃ 0, ma che poi decade rapidamente a zero se pe → 0.5. Quest’ultimo esempio in particolare ci conferma l’esigenza, in presenza di un canale rumoroso, di attuare tecniche di codifica di canale in grado di ridurre la probabilità di errore, in modo da poter sfruttare appieno la capacità che il canale presenta nel caso di pe ridotta, e di preferire tra queste le tecniche che vi riescono mantenendo al minimo la quantità dei bit aggiuntivi, dato che altrimenti come noto aumenta la banda occupata dal segnale dati.