10.1 Codifica audio
Al §
4.3.1.1 abbiamo svolto una valutazione approssimata della distorsione introdotta dal processo di quantizzazione di segnale audio, ricavando che l’utilizzo di
M bit/campione si traduce in
SNRq(M)|dB ≃ 6 ⋅ M dB. Quindi, al §
4.3.2 si è mostrato come adottando una caratteristica di quantizzazione logaritmica anziché lineare ci si possa adattare meglio alla effettiva densità di probabilità del segnale vocale, rendendo inoltre
SNRq relativamente poco sensibile alla sua effettiva dinamica, dando luogo alla cosiddetta codifica
pcm con
legge A o
legge μ, standardizzata nel 1988 da
itu-t come G.711
, . Mentre questa costituisce un formato universale di scambio permettendo la compatibilità tra dispositivi e tecnologie, nel seguito sono state sviluppate diverse tecniche alternative, in grado di offrire la stessa (o migliore) qualità di ascolto con velocità di trasmissione contenute, non solo per segnali vocali in banda telefonica, ma anche per segnali a banda larga, musicali, e multicanale, di cui tentiamo ora una sommaria rassegna. 10.1.1 Codifica di forma d’onda
Questa classe di codificatori opera esclusivamente nel dominio del tempo, agendo campione per campione, e ottiene una qualità comparabile o superiore a quella del pcm sfruttando le caratteristiche di memoria presenti nel segnale, e/o adattando alcuni parametri di funzionamento alle caratteristiche tempo varianti del segnale.
10.1.1.1 DPCM o PCM Differenziale
La prima variazione rispetto al
pcm è stata quella di applicare il principio della codifica predittiva (pag.
1), semplicemente adottando il precedente campione di ingresso come
predizione di quello successivo.
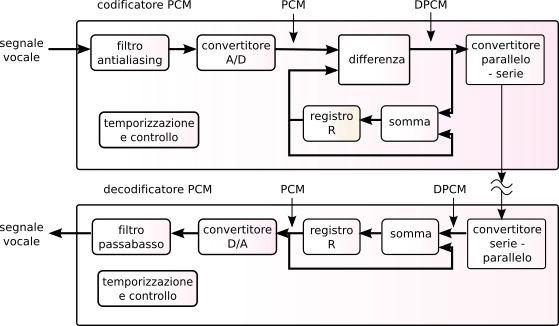
Il corrispondente schema di elaborazione è mostrato in
fig.
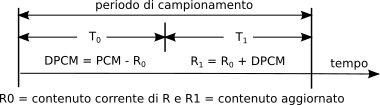
10.1, ed il suo funzionamento è suddiviso in due fasi come rappresentato a lato: nella prima (
T0) il codificatore sottrae il campione precedente (all’inizio nullo) all’attuale, e nella seconda (
T1) questa differenza è risommata al valore di differenza precedente (all’inizio nullo) in modo da ri-calcolare il valore attuale, e salvarlo nel registro di memoria
R. Il segnale differenza è caratterizzato da valori di ampiezza ridotti rispetto all’originale, e può essere codificato con 7 bit/campione, producendo ora una velocità di 56 kbps per ottenere un segnale di qualità telefonica. Il decodificatore si limita quindi a sommare alla differenza ricevuta il valore ricostruito del campione precedente, ed effettuare l’operazione di restituzione analogica. Osserviamo che il codificatore calcola il valore precedente mediante un circuito identico a quello presente al decodificatore, e per questo l’operazione è perfettamente invertibile.
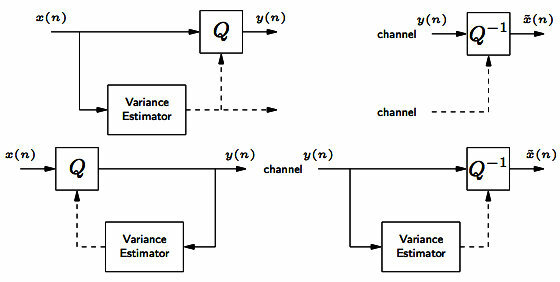
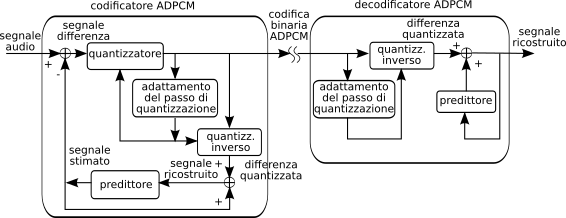
10.1.1.2 ADPCM o DPCM Adattivo
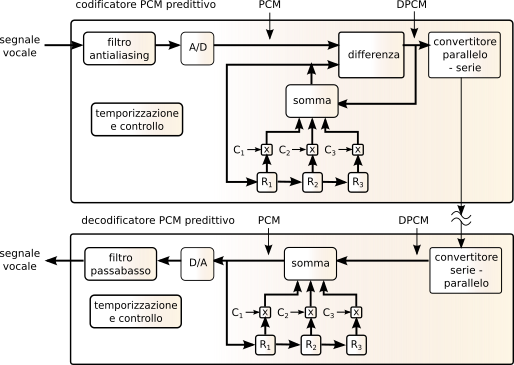
Questo metodo differisce dal precedente per due aspetti: da un lato il processo di predizione tiene conto di più di un campione passato e non di uno solo come nel
dpcm, come descritto in fig.
10.3
in cui è mostrato un predittore del terzo ordine che in pratica consiste in un filtro trasversale i cui coefficienti sono fissati in base alle caratteristiche statistiche medie del segnale vocale. Il secondo aspetto è che ora il quantizzatore
modifica nel tempo la propria dinamica di azione (da cui il termine
adattativo, o
adattivo) in base ad una stima della dinamica del segnale.
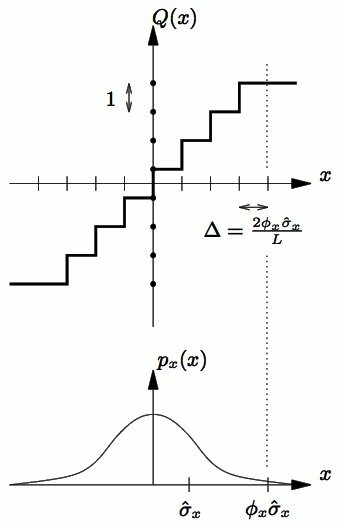
Nel lato sinistro della fig.
10.4 è mostrata una caratteristica di quantizzazione uniforme operante su di una dinamica di ingresso
φxσ̂x, con
φx > 1 scelto in modo da rendere trascurabile la probabilità che un valore di ingresso troppo elevato determini la saturazione del quantizzatore. Utilizzando una stima a breve termine della varianza
σ̂2x calcolata sugli ultimi campioni di segnale (a media nulla), ossia ad es. calcolando
σ̂2x(n) = 1N ∑Ni = 1x2(n − i), si possono rendere gli intervalli di decisione
Δ piccoli nelle fasi di segnale piccolo, in modo da mantenere l’SNR costante anche per segnali con ampiezze molto variabili. Inoltre, è possibile
omettere la trasmissione della stima di varianza se quest’ultima è calcolata in modalità
backward, ossia a partire dai valori
y(n) = Q[x(n)], dato che la stessa operazione è eseguibile in modo indipendente anche dal lato del decodificatore. La stima della varianza
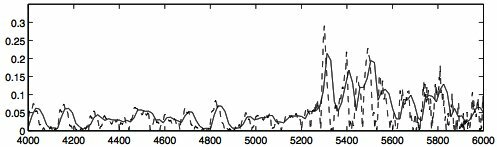
è ulteriormente semplificata se realizzata mediante una formula ricursiva, ossia
σ̂2x(n) = ασ̂2x(n − 1) + (1 − α)y2(n)
il cui risultato è mostrato in fig.
10.5, dove la linea tratteggiata rappresenta il valore istantaneo di
y2(n), mentre quella continua mostra i valori di σ̂2x(n) ottenuti in modo ricursivo.
La fig.
10.6 mostra infine i due estremi del codec
adpcm, che rimangono sincronizzati anche nel caso di saturazione del quantizzatore adattativo.
Il miglioramento della qualità ottenibile ha determinato la possibilità di ridurre il numero di bit (e di conseguenza di livelli) del quantizzatore a 5, 4, 3, 2 bit/campione, a cui corrispondono rispettivamente velocità di codifica di 40, 32, 24, 16 kbps. Questi sono i valori a cui si riferisce lo standard itu-t G.721, successivamente confluito nel G.726.
10.1.1.3 Codifica per sottobande
Anche la raccomandazione G.722 è basata sulla codifica
adpcm, ma applicata ad un segnale audio con banda più larga, riproducendo correttamente frequenze fino a 7 KHz. Ciò avviene dopo aver suddiviso le componenti frequenziali del segnale in due sottobande come mostrato in fig.
10.7, mediante una coppia di filtri passa-basso e passa-alto con frequenza di taglio comune a 3.5 KHz.
Il canale relativo alla semi banda superiore è campionato a frequenza di 16 kHz, mentre l’altro è praticamente equivalente al segnale in banda telefonica preso in esame fino ad ora. Per entrambi i canali è applicata la codifica adpcm, ma le rispettive velocità sono impostate in modo differente, dando più importanza alla componente di bassa frequenza, percettivamente più rilevante: ad esempio, si può scegliere di assegnare 16 kbps alle alte frequenze e 48 alle basse, ottenendo un totale di 64 kbps per una qualità risultante migliore del G.711, in quanto ora si opera su di un segnale a larga banda, con risultati idonei ad applicazioni come la videoconferenza.
Lo stesso schema di codifica per sottobande più adpcm è proposto anche dallo standard G.726, ma applicato ad un segnale a qualità telefonica, offrendo le velocità di 40, 32, 24 e 16 kbps.
10.1.2 Codifica basata su modello
I metodi fin qui discussi non tengono particolarmente conto della natura del segnale da codificare. Restringendo viceversa il campo al solo caso di segnale vocale, le conoscenze relative alla sua particolare modalità di produzione possono essere usate per ridurre le informazioni da trasmettere, costituite ora dai parametri che caratterizzano un suo modello di generazione. Essendo questo il dominio storico delle scienze linguistiche e fonetiche, svolgiamo una piccola digressione in tal senso.
10.1.2.1 Produzione del segnale vocale
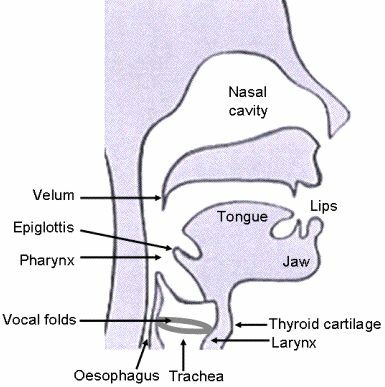
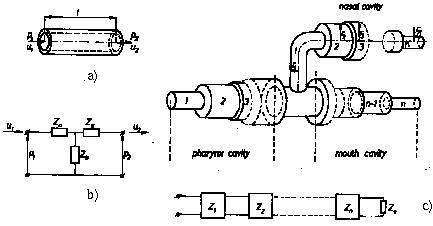
L’apparato fonatorio viene idealizzato per mezzo del cosiddetto
modello a tubi (vedi fig.
10.8),
in cui sia il
tratto vocale (compreso tra le corde vocali e le labbra) che il
tratto nasale (dal velo alle narici) sono pensati come una concatenazione di tubi di diversa sezione. Nei suoni vocalici la muscolatura della
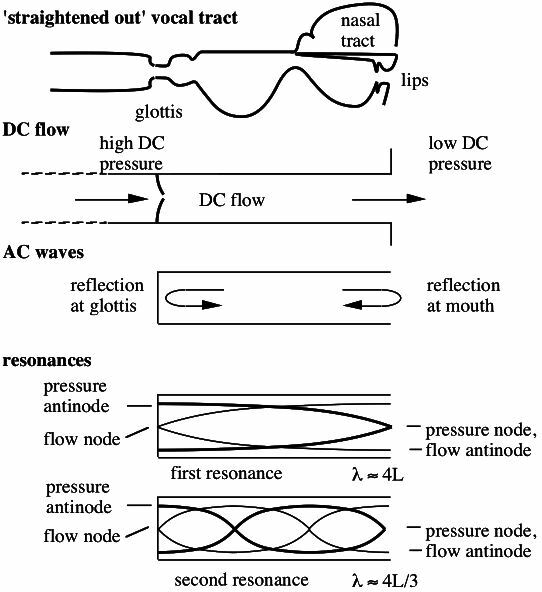
laringe determina la chiusura periodica delle
corde vocali, interrompendo il flusso d’aria che le attraversa, e dando origine ad un
segnale di eccitazione anch’esso periodico detto
onda glottale, la cui frequenza è detta
pitch; la differenza di area delle diverse sezioni del tratto vocale provoca un
disadattamento di impedenza acustica e la conseguente formazione di onde riflesse (vedi fig.
10.9),
che per lunghezze d’onda in relazione intera con la lunghezza del tratto vocale, determinano fenomeni di
onde stazionarie, ovvero di
risonanze, le cui frequenze sono indicate in fonetica come
formanti. Il verificarsi di tali risonanze genera un
effetto filtrante che modifica lo spettro dell’onda glottale, producendo così
il timbro corrispondente ai diversi suoni della lingua. Il tratto vocale termina quindi con l’apertura delle labbra, che nel modello a tubi corrisponde ad una
impedenza di radiazione che produce un effetto di derivata, e dunque
un’enfasi delle alte frequenze per lo spettro complessivo del parlato. Infine, il modello si assume valido anche per i suoni
fricativi, prodotti anziché mediante le corde vocali, mediante una occlusione che causa
turbolenza nel flusso d’aria.
Caratteristiche tempo-frequenza del segnale vocale
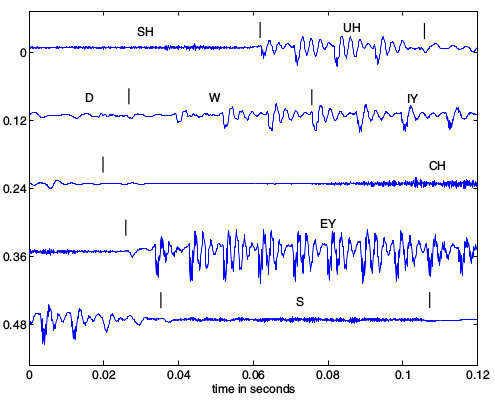
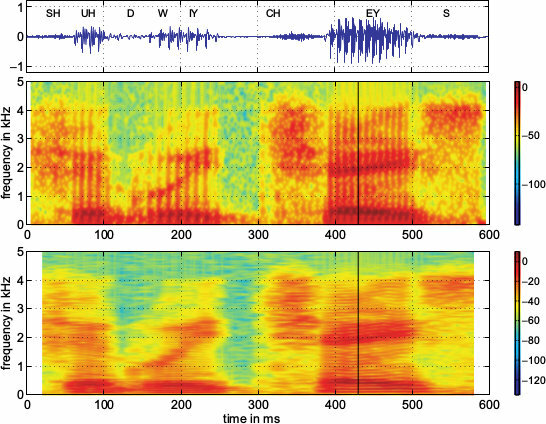
La parte sinistra di fig.
10.10
mostra la forma d’onda relativa alla frase inglese “should we chase?” (
dovremmo inseguire?) assieme alla relativa trascrizione fonetica, mettendone in luce il carattere quasi periodico in corrispondenza delle vocali e quello tipo rumore per le consonanti, nonché la diversa durata dei vari suoni, l’assenza di confini temporali precisi tra gli stessi, e la diminuzione del periodo di pitch a fine frase, corrispondente all’intonazione crescente tipica di una frase interrogativa. In particolare, notiamo come per i suoni vocalici i singoli periodi di pitch siano caratterizzati da una brusca discontinuità prodotta dall’onda glottale, seguita da oscillazioni smorzate legate alle risonanze del tratto vocale.
Il segnale viene quindi campionato a 10 KHz e suddiviso in
finestre di analisi, per le quali vengono calcolate delle
dft, la cui densità di energia in dB è riprodotta
in verticale mediante una scala cromatica come mostrato negli
spettrogrammi presenti al lato destro di fig.
10.10, che permettono di valutarne la variabilità temporale delle caratteristiche spettrali. Il differente aspetto dei due diagrammi è dovuto alla diversa lunghezza di finestra, pari rispettivamente a 10 e 40 msec per il grafico superiore ed inferiore. In entrambe le rappresentazioni sono ben evidenti le
traiettorie delle formanti, che evolvono in modo
continuo, coerentemente con la velocità di articolazione del parlante.
10.1.2.2 Codifica a predizione lineare - LPC
Il modello di produzione e le caratteristiche illustrate portano a formulare un processo di codifica basato sulla suddivisione del segnale vocale in intervalli (o finestre di analisi) di estensione tra i 10 ed i 30 msec, durante i quali il segnale può essere considerato praticamente stazionario, e su tali finestre condurre una
analisi (o stima) dei parametri del modello, che sono
- il tipo di eccitazione (periodica o caotica), la sua frequenza fondamentale (o pitch) se periodica, e la sua intensità;
- i parametri che caratterizzano l’effetto filtrante del tratto vocale.
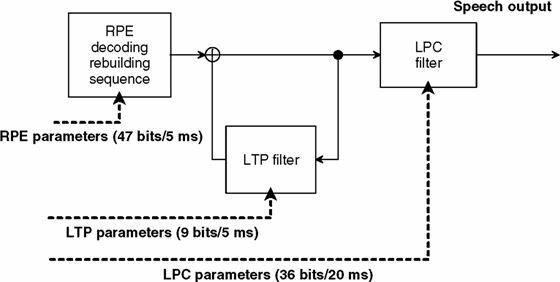
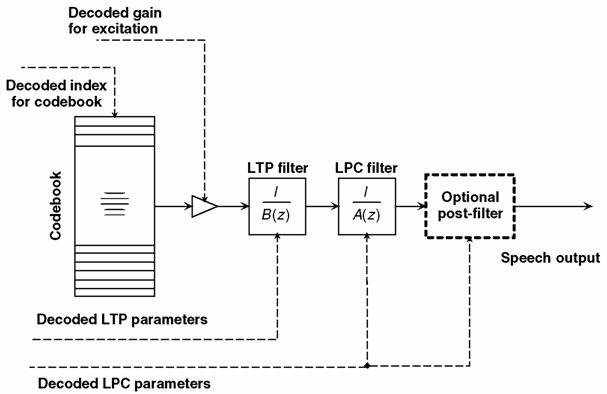
e quindi trasmettere questi valori, in modo che in ricezione sia possibile riprodurre un segnale simile all’originale mediante un decodificatore del tipo illustrato in fig.
10.11.
Il modello
a tubi (e quindi basato sulle risonanze) del tratto vocale illustrato in fig.
10.9 si presta a considerare un filtro
di sintesi di tipo numerico e
ricursivo o
iir (§
5.3.2.2) di ordine
p, che calcola il valore dei campioni di uscita
yn a partire da una combinazione lineare di
p campioni passati
ŷn = ∑pi = 1aiyn − i, a cui sommare un
errore di predizione en che rappresenta il processo di eccitazione, ovvero
Per ogni finestra di analisi i coefficienti
ai (o coefficienti
lpc del predittore
di ordine
p) si ottengono come quelli che rendono
minimo il valore atteso dell’errore quadratico
E{e2n} = E{(yn − ⎲⎳pi = 1 aiyn − i)2}
(ovvero, l’energia dell’errore), e sono individuati eguagliando a zero l’espressione delle derivate parziali di
E{e2n} rispetto ai coefficienti
aj. Scriviamo dunque
∂ ∂ajE{(yn − ⎲⎳pi = 1 aiyn − i)2} = 2E{(yn − ⎲⎳pi = 1 aiyn − i)yn − j} = 0
da cui si ottiene
Il valore atteso
E{yn − iyn − j} viene
stimato come quello della autocorrelazione discreta calcolata sui campioni di segnale delimitati dalla finestra di analisi corrente, ovvero
dove l’estremo superiore della sommatoria varia in modo da includere solo i campioni effettivamente presenti nella finestra. La
(10.265) permette di riscrivere
(10.264) come
Ryy(j) = ⎲⎳pi = 1 aiRyy(|i − j|)
che valutata per
j = 1, ⋯, p individua un sistema di
p equazioni in
p incognite
che può essere risolto nei termini dei coefficienti
ai mediante metodi particolarmente efficienti; ed i coefficienti utilizzati dal decodificatore per applicare la
(10.263).
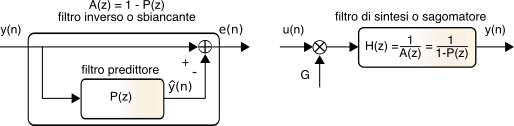
Il filtro autoregressivo che esegue il calcolo
ŷn = ∑pi = 1aiyn − i è indicato come
predittore, ed è associato ad un polinomio
P(z) = ∑pi = 1aiz−i; viceversa il filtro
fir che valuta l’errore di predizione (o
residuo)
en = yn − ∑pi = 1aiyn − i è indicato come
filtro inverso o
sbiancante, viene associato al polinomio
A(z) = 1 − P(z), ed è mostrato nel lato sinistro della fig.
10.12.
Indicando ora con
G ⋅ un una
codifica del residuo
en, il segnale di partenza può essere (quasi) ri-ottenuto come mostrato nella parte destra della fig.
10.12, ossia facendo passare
en attraverso il filtro
iir H(z) = 1A(z) = 11 − P(z).
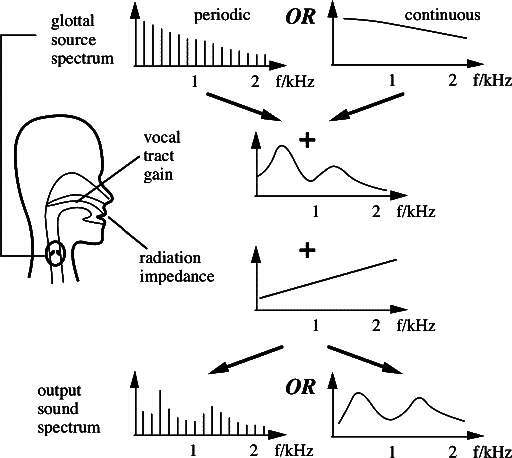
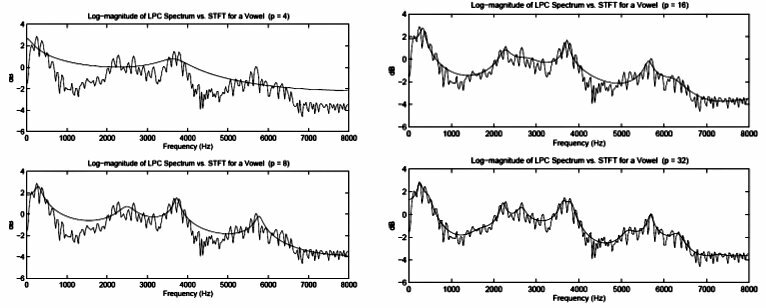
Dato che, in base a considerazioni che non svolgiamo,
en è caratterizzato da una densità spettrale
bianca,
|H(z)|2 (calcolato per
z = eiω) rappresenta una vera e propria
stima spettrale del segnale di partenza, come mostrato in fig.
10.13 per diversi valori di
p, verificando che per suoni vocalici si ottengono risultati accettabili già per valori di
p tra 8 e 14, mentre per le fricative l’ordine può essere ancora inferiore.
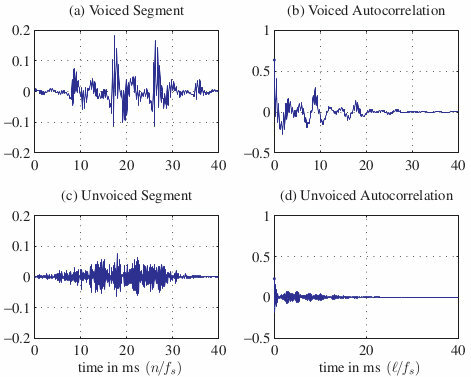
Stima del periodo di pitch
Resta ora da illustrare il modo di decidere se la finestra di analisi contenga un suono sordo o sonoro, e nel secondo caso, il suo periodo. Osserviamo che
in media la frequenza di pitch risulta pari a circa 120 e 210 Hz nel caso rispettivamente di voci maschili e femminili, con una estensione che varia approssimativamente da metà al doppio del pitch medio. La stima del periodo di pitch può essere realizzata a partire dalla funzione di autocorrelazione a breve termine
(10.265), mostrata nella colonna di destra della figura che segue,
a fianco delle finestre di segnale su cui è stata calcolata, per un suono vocalico (sopra) e fricativo (sotto). Come evidente, nel caso del suono vocalico l’autocorrelazione
presenta un primo picco a 9 msec ed un secondo a 18 msec, corrispondenti al periodo di pitch ed al suo doppio; viceversa nel caso del suono simile al rumore, non sono visibili picchi, come da aspettarsi nel caso di una segnale incorrelato. Pertanto, l’autocorrelazione può essere usata per indicare la presenza o meno di un suono vocalico, e nel caso affermativo, stimare il suo pitch.
Nella pratica per i suoni sordi si ottengono buoni risultati di sintesi usando come eccitazione un vero e proprio rumore bianco; d’altra parte, per i suoni sonori l’uso di forme d’onda impulsive con periodo pari al pitch stimato, sebbene capaci di produrre un bit rate riducibile fino a 2.4 kbps, non fornisce risultati particolarmente utilizzabili, producendo un voce piuttosto robotica. Per questo motivo, si sono sviluppate le tecniche seguenti.
10.1.2.3 Predizione lineare ad eccitazione residuale - RELP
Per ovviare alla sovra-semplificazione dello schema di sintesi riportato in fig.
10.11, dopo aver svolto l’analisi spettrale
lpc il residuo di predizione relativo alla finestra di analisi viene effettivamente calcolato, applicando poi allo stesso una tecnica di codifica di forma d’onda: questo modo di operare è indicato come codifica
relp (
Residual Excited LP).
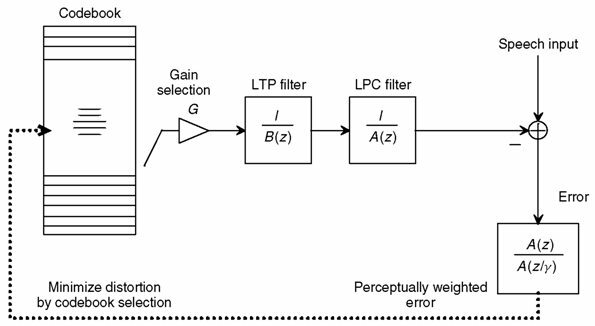
Analysis by synthesis
- ABS
Anziché
calcolare il residuo di predizione, codificarlo, e trasmetterlo in tale forma, la tecnica di
analisi via sintesi adotta una tecnica
ad anello chiuso, cercando di trovare quale segnale di eccitazione fornire al filtro di sintesi in modo che il risultato sia quanto più possibile simile al segnale originale (vedi fig.
10.15); i parametri del filtro di sintesi e della eccitazione sono quindi trasmessi al decoder. La funzione di minimizzazione opera dunque una vera e propria
ricerca tra i possibili segnali di eccitazione.
Sempre in fig.
10.15 si mostra come il processo di minimizzazione prenda in considerazione un segnale di errore ottenuto filtrando l’errore
effettivo mediante un filtro di
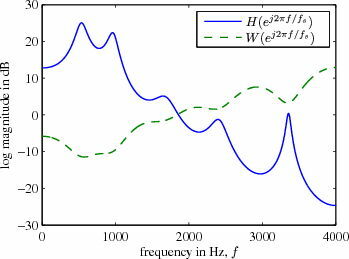
pesatura percettiva, il cui andamento frequenziale è sostanzialmente
reciproco rispetto a quello stimato del segnale (vedi fig.
10.16), in modo da attenuare la rilevanza dell’errore di predizione nelle regioni dove c’è più segnale ed esaltarla invece nelle regioni con meno segnale, sfruttando così il fenomeno percettivo noto come
mascheramento uditivo (vedi pag.
1). Anche se per questa via l’energia totale del rumore è maggiore, l’effetto soggettivo è migliore.
Multi pulse linear prediction - MPLP
Lo schema operativo suggerito dalla tecnica abs è stato inizialmente realizzato cercando di costruire la sequenza di eccitazione ottima (ossia in grado di minimizzare l’errore pesato percettivamente) come una sequenza di pochi impulsi sparsi, decidendone uno alla volta. Tale approccio prevede dunque di trovare l’ampiezza e posizione ottime per un unico primo impulso, quindi per un secondo (con il primo fisso), e così via, fino al numero di impulsi desiderati, tipicamente 4-5 ogni 5 msec, ottenuti suddividendo una finestra di 20 msec in quattro sotto-trame, ognuna con 40 campioni, se fc = 8000 Hz.
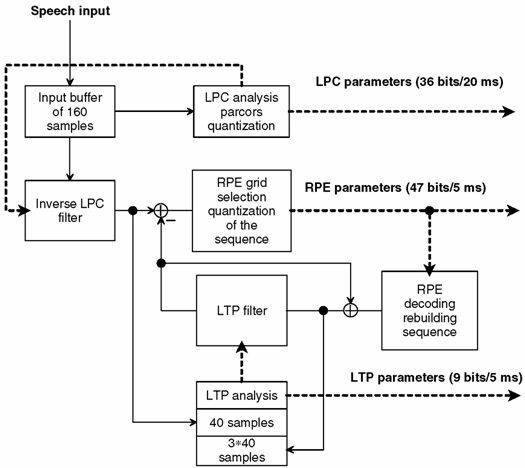
Regular pulse excitation with long-term prediction - RPE-LTP
o GSM 6.10
Il metodo mplp presentava una complessità proibitiva, ma ha dato luogo alla versione semplificata rpe-ltp usata inizialmente nella telefonia gsm per fornire una velocità di 13 kbps. In questo caso, dopo aver determinato la posizione del primo impulso nella sottofinestra ne sono piazzati altri 9, ad intervalli regolari (un campione si e tre no), in modo che l’ottimizzazione riguardi solo i valori delle ampiezze.
Rispetto allo schema di fig.
10.15 viene inoltre aggiunto un
predittore a lungo termine o
ltp, utilizzato per rimuovere dal segnale di eccitazione l’eventuale periodicità caratteristica dei suoni vocalici, e stimato a partire da sotto-finestre consecutive (vedi fig.
10.17). Il filtro
ltp in essenza consiste in un semplice ritardo pari al periodo di pitch
(e dunque
≫ p), ed il predittore
ltp relativo (vedi lo schema di decodifica)
ripropone in uscita una copia ritardata ed attenuata dell’uscita stessa. Il codificatore
gsm pertanto determina ritardo e attenuazione dell’
ltp in base all’analisi del residuo di predizione
lpc, e lo usa per reintrodurre la componente periodica nella sequenza
rpe di cui si sta valutando l’idoneità. Una volta che al residuo
lpc viene sottratta la componente predicibile per tramite del
ltp, ciò che rimane risulta effettivamente assimilabile ad un rumore, ed è indicato anche come
processo di innovazione.
10.1.2.4 Quantizzazione vettoriale dell’eccitazione
Dato che la codifica della sequenza di eccitazione impegna la maggior parte dei bit da trasmettere, si è fatta strada l’idea di... non codificarla affatto! Invece, viene realizzato un dizionario o
codebook di
possibili sequenze di eccitazione, e per ciascuna delle quali viene misurata
la distanza tra essa e la sequenza
vera. Ciò che viene trasmesso è quindi
l’indice della codeword di minima distanza rispetto alla sequenza di eccitazione, e l’intero procedimento prende il nome di
quantizzazione vettoriale.
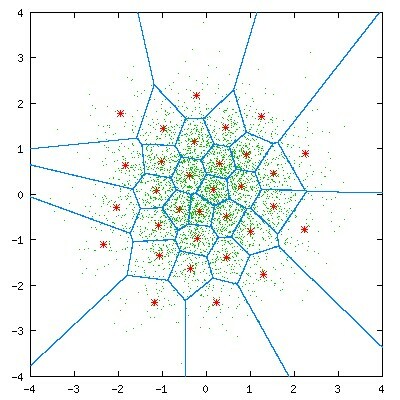
La costruzione del codebook è ottenuta
partizionando la distribuzione campionaria dei vettori in più regioni di decisione come quelle mostrate nell’esempio di fig.
10.18, in modo che ciascun vettore possa essere classificato come interno ad una di esse, e venire quindi rappresentato dal
centroide (i punti rossi) associato alla regione. I centroidi ed i confini di decisione sono determinati mediante un procedimento iterativo tale da minimizzare l’errore quadratico medio di rappresentazione.
I valori che descrivono le sequenze di eccitazione (vettori) associate ai centroidi del codebook sono noti anche al lato di ricezione, in modo che ogni particolare sequenza possa essere rappresentata, anziché da tutti i suoi campioni, dal solo indice della codeword del centroide più vicino: al solito, utilizzando M bit per rappresentare l’indice, il codebook sarà formato da 2M diverse codeword. Oltre al codebook utilizzato per rappresentare le sequenze di innovazione, la codifica del segnale vocale si può avvantaggiare anche di un secondo codebook, usato per approssimare il vettore dei possibili coefficienti spettrali.
10.1.2.5 Predizione lineare ad eccitazione codificata - CELP
La fig.
10.19 mostra lo schema realizzativo di un codificatore
celp, in cui sono evidenziati il filtro di predizione a lungo termine ed il filtro
lpc, stimati in modalità
ad anello aperto, ed il
filtro percettivo che fa in modo che la densità spettrale dell’errore di predizione sia concentrata nelle regioni dove è presente segnale.
Per ogni codeword di eccitazione selezionata dal codebook, e per il guadagno associato, viene calcolata l’energia dell’errore ottenuto, ed il risultato confrontato con
quello ottenibile mediante le altre codeword, finché non si trova la codeword che minimizza l’errore. Ovviamente questo modo di procedere è estremamente oneroso, ma si sono trovati metodi di ricerca più efficienti adottando tecniche di costruzione del codebook come combinazione di sequenze elementari, dando luogo alla famiglia dei codificatori
algebrici o
acelp.
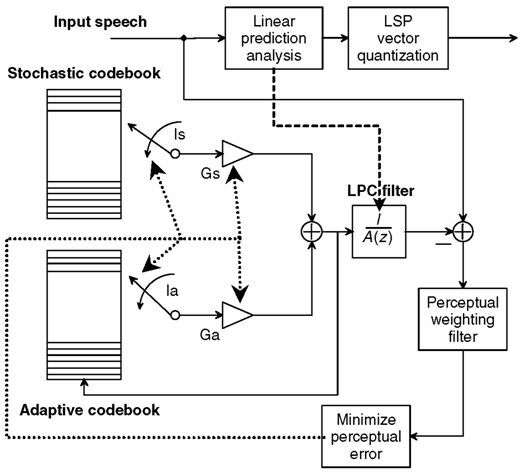
D’altra parte, anche l’identificazione del
ltp può essere ricondotta ad una ricerca ad anello chiuso, stavolta nell’ambito di un
codebook adattivo, costruito a partire dalla precedente sequenza di eccitazione ottima, replicata in forma traslata di un campione
alla volta, come illustrato in fig.
10.21, che mostra appunto l’uso della eccitazione per la trama precedente per popolare il codebook adattativo: da questo viene quindi individuata la codeword
Ia ed il guadagno
Ga ottimi, e quindi individuata la codeword di innovazione
Is e
Gs ottimi, riferiti ad un codebook detto
stocastico perché costituito da sequenze pseudo casuali. Infine, in fig.
10.21 viene mostrato come anche i coefficienti spettrali
lpc sono trasmessi mediante una codeword (
lsp o
line spectrum pair) derivata da un processo di quantizzazione vettoriale. Possiamo elencare i seguenti standard che adottano una tecnica di questo tipo:
- Federal Standard 1016 (4800-16000 bit/s) celp
- ITU-T 8-kbit/s G.729 cs-acelp (conjugate-structure algebraic celp);
- dual-rate multimedia ITU-T G.723.1 a 5.3 kbit/s con acelp e 6.3 kbit/s con mp-mlq (multi-pulse maximum likelihood quantization);
- ITU-T low-delay celp 16-kbit/s G.728 - usa finestre di analisi multo brevi e una predizione lineare all’indietro per conseguire un ritardo di 2 msec;
- ETSI enhanced full-rate efr-gsm e half-rate hr-gsm, con velocità di 12.2 e 5.6 kbps, così come i codec amr (adaptive multirate) e wb-amr, con velocità da 7.95 a 4.75 kbps;
- Speex - un insieme di codecs open source esenti da brevetti e liberamente utilizzabili, con velocità (a banda stretta) da 5,95 a 24,6 kbps, e da 5.75 a 42,4 kbps per segnali con banda di 16 kHz
10.1.3 Codifica psicoacustica
Mentre la codifica di forma d’onda (§
10.1.1) non fa assunzioni a riguardo della natura del segnale, i metodi esposti al §
10.1.2 sono tutti fortemente orientati a rappresentare segnali vocali. Viceversa, il gruppo di lavoro
mpeg di
iso si è dedicato ad individuare metodi di codifica idonei alla trasmissione di segnali multimediali di natura qualsiasi, come ad esempio brani musicali. Inoltre, i vincoli relativi al basso ritardo necessario ad assicurare un buon grado di interattività vengono meno, e si possono dunque intraprendere elaborazioni più complesse, e che richiedono un tempo maggiore. Infine, vengono trascurati rigidi vincoli sulla velocità risultante, accettando invece che questa
vari nel tempo in funzione del tipo di segnale da rappresentare.
Come vedremo tra breve, per queste tecniche si fa di nuovo uso di una codifica per sottobande, introdotta nella discussione dell’adpcm, tenendo però anche conto di caratteristiche molto importanti della percezione sonora, il cui sfruttamento è già stato illustrato nella discussione del filtro di pesatura percettiva, ma che ora hanno un impatto ancora maggiore sulla realizzazione del codificatore. I codificatori che fanno uso di queste caratteristiche sono l’MPEG layer 3 o mp3, il Dolby ac, e l’advanced audio coding o aac.
Sensibilità uditiva e mascheramento in frequenza
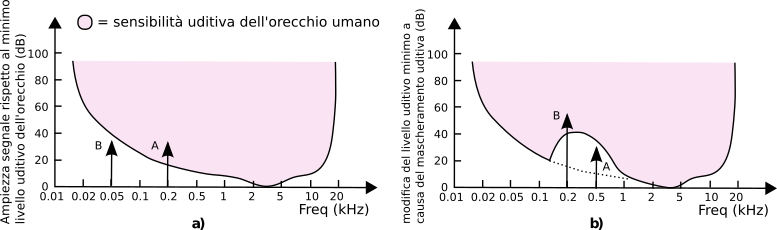
La fig.
10.22-a mostra la curva di sensibilità del sistema uditivo,
ovvero il livello di intensità minimo perché possa essere percepito un suono: come si vede, questo è molto variabile con la frequenza, per cui anche se il suono B (sinusoide o tono puro) ha la stessa intensità di A non può essere udito, mentre invece A si. Ma ad una analisi più approfondita, si scopre che la presenza di un suono in una determinata regione di frequenza ha l’effetto di modificare la curva di sensibilità per le frequenze vicine, di fatto
mascherando suoni a frequenze vicini che altrimenti avrebbero superato la soglia di sensibilità, come mostrato in fig.
10.22-b: la presenza del suono B rende A non più udibile.
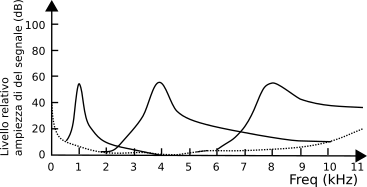
In realtà, l’estensione in frequenza per cui si verifica l’effetto di mascheramento dipende sia dalla frequenza del tono mascherante (come mostrato dalle curve in fig.
10.23
ottenute con toni a 1, 4 ed 8 kHz) che dalla sua intensità. In particolare, la banda delle frequenze mascherate viene detta
banda critica ed ha una estensione differente alle diverse frequenze: si trova che sotto i 500 Hz la banda critica ha una estensione di circa 100 Hz, mentre a frequenze superiori aumenta (circa) linearmente per multipli di 100 Hz. Ad esempio, un segnale ad 1 KHz (2x500) produce una banda critica di 200 Hz (2x100), mentre a 5 kHz (10x500) questa vale circa 1 kHz (10x100).
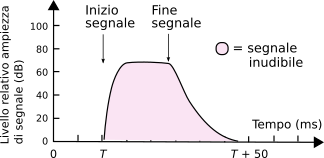
Il secondo effetto percettivo riguarda ancora una modifica alle curve di sensibilità, stavolta in modo
non selettivo in frequenza, ma che coinvolge tutte le frequenze: si verifica infatti che dopo aver udito un suono forte, per il tempo necessario all’estinzione del suono e che tipicamente dura qualche decina di millisecondi (vedi fig.
10.24), l’orecchio non è più in grado di percepire suoni con intensità minore a quello che si sta estinguendo.
Il gruppo di lavoro
mpeg di
iso ha definito uno standard di codifica audio basato su tre livelli di complessità (e potere di compressione) crescente, ed il terzo (o
mp3) è quello di gran lunga più popolare, anche grazie alla diffusione che ha avuto via Internet. Lo schema di funzionamento di principio è mostrato in fig.
10.25:
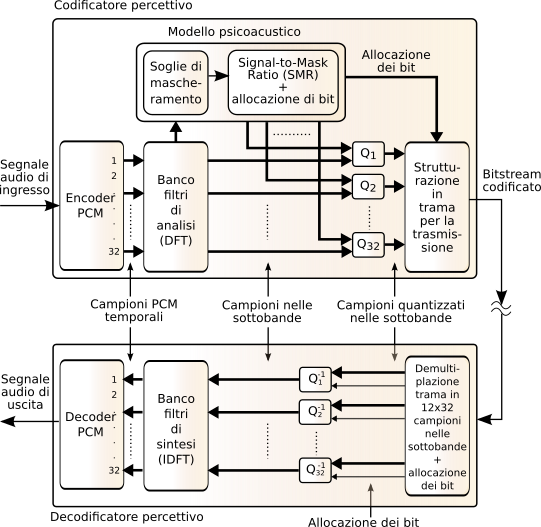
il segnale campionato in ingresso (a 32, 44.1 o 48 kHz) transita attraverso un
pcm encoder che esegue un filtraggio in 32 sottobande di eguale ampiezza, le cui uscite sono campionate a frequenza
1⁄32 di quella di ingresso. Ogni 384 campioni di ingresso (pari a 12 msec se
fc = 32 kHz) sono quindi prodotti
384 ⁄ 32 = 12 campioni per ogni sotto-banda, e per ognuna di esse è individuato il valore del campione più grande, che contribuisce sia ad impostare la dinamica del quantizzatore per quella banda, sia come parametro per il modello psicoacustico.
Il modello psicoacustico riceve le informazioni prodotte da un banco di filtri di analisi realizzati mediante una mdct, che produce una stima spettrale con risoluzione maggiore di quella del primo banco di filtri, su cui basare le valutazioni di mascheramento uditivo, che a loro volta determinano per ogni sottobanda l’indicazione di un signal to mask ratio (SMR), che a sua volta determina quanti bit utilizzare (e quindi quanti livelli) per la quantizzazione Q dei campioni relativi alle singole sottobande. Quelle contraddistinte da una maggiore sensibilità (ovvero nelle quali si percepiscono anche suoni deboli) saranno quantizzate con più accuratezza, e quindi con più bit e meno rumore; mentre le sottobande caratterizzate da una sensibilità inferiore possono essere quantizzate con meno bit, almeno finché l’SNR di quantizzazione si mantiene superiore all’SMR, dato che in tal caso il rumore è mascherato, e dunque non viene udito. Quindi, i 12 campioni delle 32 sottobande sono quantizzati tenendo conto sia della dinamica effettiva, che del numero di livelli in cui suddividere la dinamica. Infine, viene prodotta una struttura di trama che contiene, oltre ai campioni, anche le informazioni sulla effettiva allocazione dei bit.
Ad una futura edizione, una trattazione più approfondita.
Si citano dei riferimenti essenziali sulla codifica audio, da cui sono anche tratte alcune illustrazioni